
基于用户特征和链接关系的Louvain算法研究*
2019-09-03 07:22薛龙龙
计算机与数字工程 2019年8期
胡 健 薛龙龙
(北方工业大学 北京 100144)
1 引言
社区存在于人类社会所构成的各种网络中,如社区可以是科学家合作网络中处于同一个研究领域的研究群组、引文网络中处于同一个课题的论文、社交网络中具备相似爱好的兴趣团体等[1]。在网络科学文献中,网络社区检测问题一直受众多学者的广泛研究[2]。随着微博、微信等社交网络的蓬勃发展,社交数据呈爆炸式的增长,挖掘和分析社交网络结构对于了解和预测社交网络中的关联关系具有重要意义[3~6]。社区内部的成员相对于外部的成员是紧密联系的。一种流行且快速的社区检测方法是基于模块度函数优化的。Newman和Girvan共同提出了模块度函数。随后,Newman提出通过优化模块化函数来检测社区的思想[2]。Louvain算法是一种基于模块度函数优化的算法,有易于理解、非监督、计算快速的优点且能够发现层次性的社区结构[7],因此Louvain社区发现算法受到多数研究者的青睐。
在研究Louvain社区发现算法时候,多数研究者未考虑边的实际权值及有向边对社区发现结果的影响。本文从社交网络中用户的特征及链接关系可以进一步改善Louvain社区发现算法的结果[8~9]出发,提出一种基于用户的特征及链接关系的混合AHP层次分析法、PageRank算法思想及Louvain算法的社区发现策略APL。该策略将网络中用户的特征及链接关系进行混合分析。首先利用AHP层次分析法对提取出的用户特征进行权重划分,然后计算各个用户的初始影响力并利用PageRank思想计算用户的最终影响力,再根据用户的最终影响力扩散计算网络中各边的权值,最后,运用Louvain社区发现方法对初始化后的带权网络进行社区划分。本文所提出的方法能进一步改善社区发现的结果,使结果更符合实际。
2 相关工作
由于大型网络数据集的可用性日益增加以及网络对日常生活的影响,近年来,学者们对快速社区发现算法的研究产生很大兴趣。关于社交网络中的社区检测问题,相关的社区发现算法主要分为分裂的算法和凝聚的算法[5]。分裂的算法检测社区间链接并将其从网络中移除。凝聚的算法递归地合并相似的节点或社区。两类算法的优化目标都是基于最大化目标函数[7]。
典型的分裂算法是GN(Girvan-Newman)算法[10]。GN算法是一种基于边介数的分裂算法。其基本思想是不断去除网络中边介数最大的边,最终将网络划分为多个社区。GN算法不需要预先设定社区数量,但是由于边介数的计算较耗时,其算法时间复杂度较高。典型的凝聚算法是Louvain算法[7]。Louvain算法是一种层次贪心算法,被公认为是运行最快的非重叠社区发现算法之一。吴祖峰等提出了一种改进的Louvain社区划分算法[11],它通过对叶节点进行剪枝来降低算法的运行时间,其改进的算法没有提升社区划分准确度。基于Louvain算法的有向图社区发现算法[12]能够有效地发现大规模有向网络中的社区结构。使用多级细化策略改进的Louvain算法[13],其通过在原社区网络多次执行本地移动的启发式方式来确保通过节点之间的移动无法进一步优化算法的模块度,这种策略可能需要多次的迭代。Ludo Waltmana and Nees Jan van Eck提出的智能本地移动算法[2],其通过对本地移动启发式方法产生的社区构建子网,在对各个子网应用本地移动启发式方法,使得算法无法通过社区分割和节点集移动来进一步提高Louvain算法的模块度,这种策略可能需要多次的迭代。李雷、闫光辉等提出了基于孤立节点分离策略的改进Louvain算法[14],该算法在每次迭代中将输入网络的孤立节点提前分离出去,只令其中的连通节点实际参与迭代过程,并在存储社区发现结果时将孤立节点和非孤立节点分开存储,其进一步提高了Louvain算法的效率。A.Meligy等提出一种改进社区发现结果预处理策略[8],其根据节点的中间度核心性和边的中间度核心性计算节点间边的实际距离,从而改善社区发现算法的结果,其缺点是节点的中间度核心性和边的中间度核心性的计算非常复杂和耗时。
在社交网络中,用户的影响力可以用于评估用户间的实际距离,据此可以进一步优化Louvain社区发现的结果[8]。尹红军提出一种个性化PageR-ank算法,使结果偏向于偏好的节点[5],然而,此方法需要维护n个节点偏好向量,内存耗费大且计算复杂。Tunkelang等利用Twitter用户节点之间的关注关系,构造了一张基于链接关系的有向图,并且利用PageRank模型实现了Twitter用户的影响力排序[15]。本文主要根据用户特征来计算用户的影响力,进而计算用户间的距离。
综上分析,多数研究者在研究Louvain社区发现算法时,侧重考虑Louvain社区发现算法的效率,且其研究大都基于无向图,而未考虑网络中边的实际权值及其有向边对社区发现结果的影响。现实生活中的网络大都是有向的且其数据量很大,在算法准确度达到一定标准后,研究实际数据对算法的影响则更有意义。因此,本文基于真实微博数据集构建有向网络图并且根据用户的特征及链接关系迭代计算用户间边的真实权值,然后运用Louvain算法进行社区检测,最终获得更具实际意义的社区发现结果。
3 基于用户特征和链接关系的社区发现
3.1 用户初始影响力计算
用户初始影响力主要根据用户的特征,如微博中用户的粉丝数、微博被转发数量、微博被评论数量等,来计算。由于用户的各个特征所占的比重是不同的,因此,本文采用AHP层次分析法[16]进行特征权重的确定,层次分析法(Analytic Hierarchy Process,AHP)是在20世纪70年代由美国运筹学家A.L.Saaty提出的,这是一种定性与定量相结合的决策分析方法[16],其可以通过两两元素进行重要性的比较从而确定权重,方法更为严谨。本文提出的用户初始影响力计算公式如下:

3.2 基于链接关系的用户最终影响力计算
社交网络中用户间的链接关系非常符合PageRank的核心思想。为了综合考虑社交网络中用户之间的相互链接关系,本文首先根据用户的特征计算用户的初始影响力,然后根据PageRank算法思想计算用户的最终影响力,从而得出更为准确的用户影响力值。
本文提出的计算用户最终影响力的步骤如下:
1)从社交网络的所有用户集合U中,选取一个初始用户Ui,作为影响力扩散计算的起点,并将用户Ui添加到集合A中(A中记录的是已进行过影响力扩散的用户);
2)利用式(2)计算用户的最终影响力:

其中R(x)表示x的最终影响力值,B(x)表示所有关注x的用户,N(j)表示j用户关注的人数,常数C为加权系数,用户缩放用户的最终影响力值;
3)从集合U中选取一个新的没有进行过最终影响力计算的用户,将其加入集合A中,重复上述步骤,直到所有的用户都进行了最终影响力值的计算,则算法结束。
3.3 Louvain社区发现算法
Louvain是基于模块度的社区发现算法,其优化的目标是最大化整个图的模块度。算法主要分为三个步骤:首先将每个节点初始化为一个小的社区;然后,不断遍历网络中的所有节点,将其从原来的社区中取出,计算该点加入到各个社区产生的模块度增量,如果该模块度增量大于零,则从这些大于零的模块度增量所对应的簇中选出对应模块增量最大的簇,将该点与之合并,重复上述过程,直到网络中所有节点所属的社区不再发生变化,停止迭代;最后,将网络图进行约简,把一个社区内的所有节点抽象成一个节点,新节点之间的权值就是原社区之间的权值,重复前两个阶段的过程,直到簇间不再发生合并为止。
3.3.1 模块度
模块度是Louvain算法用来评估一个社区网络划分好坏的度量方法,它的物理含义是社区内节点的连边数与随机情况下的边数之差,它的取值范围是[-1/2,1),一般以Q=0.3作为网络有明显社区结构的度量,Q值越接近1,说明发现的社区质量越高。
其定义如下:

其中,Aij表示节点i和节点j之间边的权重,网络不是带权图时,所有边的权重初始化为1;表示所有与节点i相连的边的权重之和;ci表示节点i所属的社区;表示网络中所有边的权重之和。
3.3.2 模块度增量
Louvain算法根据节点的模块度增量来判断是否将其加入另外一个社区。Louvain算法能够产生层次性的社区结构,其中计算耗时较多的是最底一层的社区划分,节点按社区压缩后,将大大缩小边和节点数目,并且计算节点i分配到其邻居j所在社区时的模块度的变化只与节点i、j的社区有关,与其他社区无关,因此计算很快。把节点i分配到邻居节点j所在的社区c时模块度变化为

其中Ki,in是社区c内节点与节点i的边权重之和,注意:Ki,in是对应边权重加起来再乘以2。ΔQ分两部分,前面部分表示把节点i加入到社区c后的模块度,后一部分是节点i作为一个独立社区和社区c的模块度。
3.4 本文提出的APL社区发现方法的步骤
1)根据AHP层次分析法及用户初始影响力计算公式(1)来计算用户i的初始影响力值initPRi;
2)根据3.2节介绍的用户影响力计算步骤及initPRi来计算用户i的最终影响力值lastPRi;
3)根据上一步骤求出的lastPRi,求社交网络中节点间边的权值,公式如下:
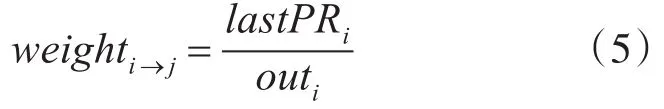
其中weighti→j为节点i到节点j的有向边的权值,outi为节点i的出度;
4)经过前三步后,可以得到带有实际意义边权值的社交网络矩阵W,然后利用3.3节介绍的Louvain算法进行迭代计算,最终将得到符合实际的社区发现结果。
4 实验与分析
实验所用到目标数据集来自数据堂公开的可用于学术研究的某微博数据集,其包含63641个微博用户信息,1391718条用户关注关系,84168条用户的微博信息、27759条微博转发关系。为了便于展示,本文从1391718条用户关注关系中按数据分区方式提取出6万条边来研究和分析。
4.1 微博用户特征提取及权重计算
本文仅从微博数据集提取出粉丝数、评论数、转发数、获赞数、微博数这5个用户特征。根据这5个特征构建的AHP对比矩阵如表1。
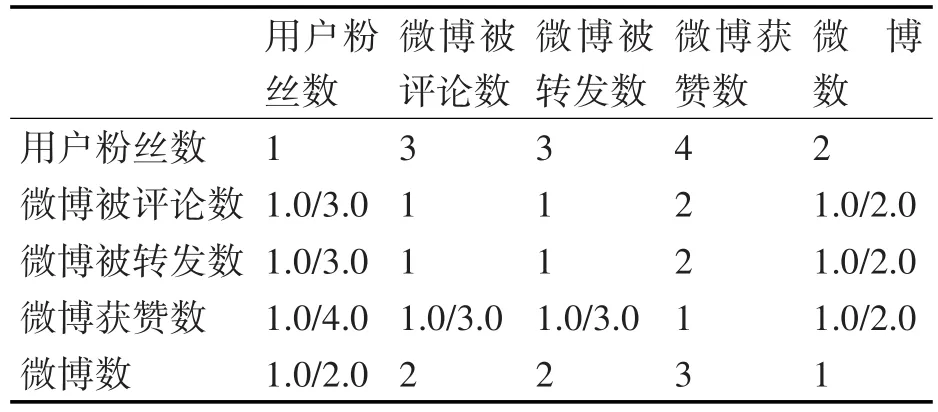
表1 AHP对比矩阵
经AHP层次分析法计算得到这五个特征的权重依次为0.4036,0.1368,0.1368,0.0782,0.2446。
4.2 用户最终影响力的结果与分析
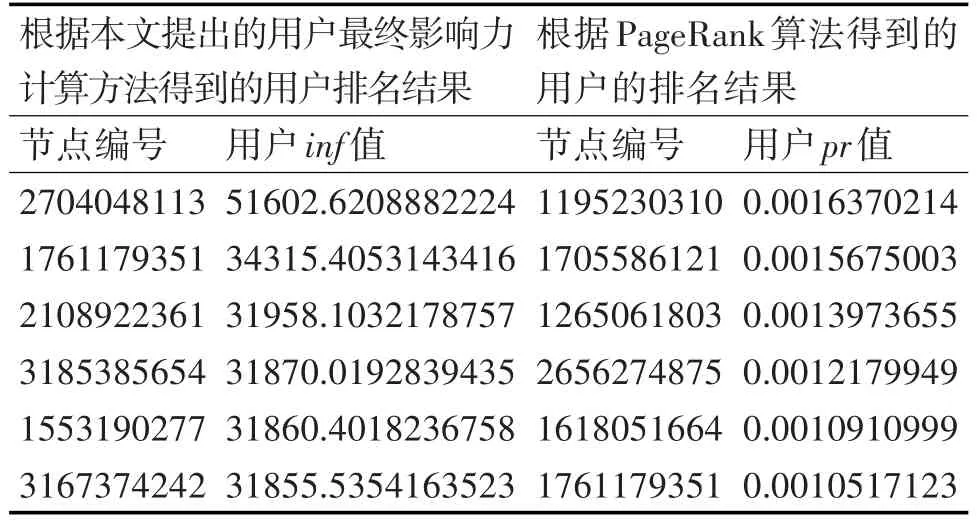
表2 本文提出的用户影响力计算方法和PageRank算法的结果对比
说明:表中的结果皆按照用户影响力逆排序,且取部分结果。
通过对用户影响力两种计算方法结果的对比,可得出如下的结论:
1)若仅考虑用户间的链接关系,则节点编号为1195230310用户为最有影响力的用户,若综合考虑用户的特征,则节点编号为2704048113的用户为最有影响力的用户,即排名更偏向于有影响力的用户;
2)多数inf值很大用户都不在pr值最大的几个用户中,而inf值排名第二的1761179351用户,排在pr值排名的第6位,从两种算法总的输出结果分析得出,inf值大的用户在pr值排名中越靠前;
3)由于微博特征数据是基于整个微博网络的,而微博用户间的链接关系仅仅取了6万条,因此,1)和2)中的部分排名差异现象是正常的。
4.3 社区发现结果与分析
使用APL(混合AHP、PageRank思想及Louvain)社区发现方法和原Louvain算法分别对上文提到的微博数据集进行分析,来验证本文提出的社区发现方法APL的有效性。

表3 本文提出的社区发现方法APL和原Louvain社区发现的结果对比

图1 未改进Louvian社区发现结果

图2 APL社区发现结果

图3 和图1对应的社区成员数占比
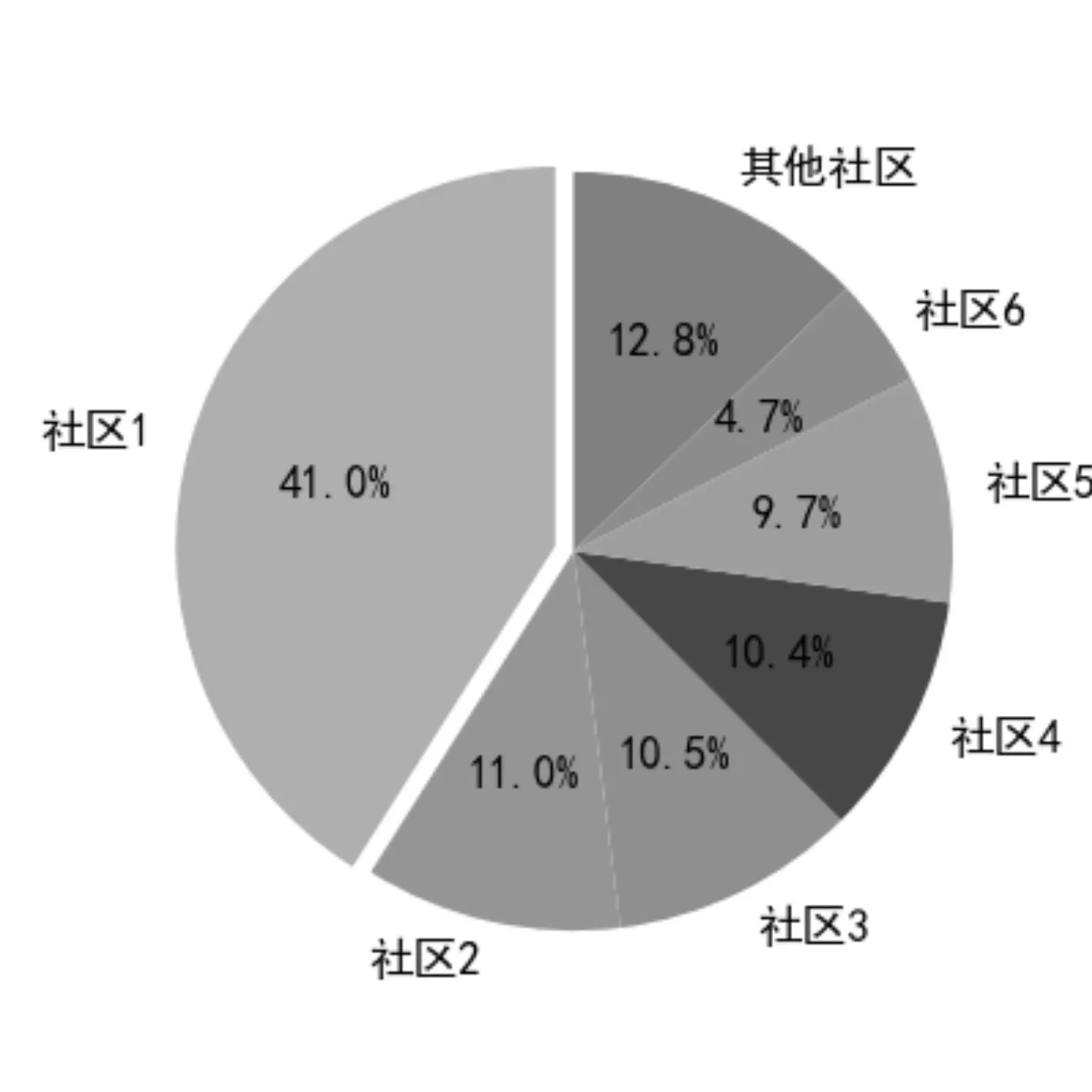
图4 和图2对应的社区成员数占比
通过对表3及四张图的对比分析,可得到如下的结论:
1)从表3的输出结果可知,本文提出的APL社区发现方法将社区模块度从原来的0.2625提高的0.3197;
2)从图1和图2可知,本文提出的社区发现方法和原方法挖掘到的关键人物是一致的,如用户1195230310、1705586121、1265061803;
3)从图3和图4可知,两种方法都检测到6个主要的社区,只是社区人数占比不同,这和分块选择的6万条数据相符合;
4)综上分析及模块度越大则社区发现结果越好的原理,因此本文提出社区发现方法是有效的。
5 结语
通过对微博数据中用户的特征及其链接关系的分析,本文提出一种融合AHP层次分析法、PageRank算法思想和Louvain算法的社区发现方法,此方法在用户链接关系的基础上结合了用户的特征,进一步改善了社区发现的结果。虽然,可以通过Betweenness Centrality的概念先计算节点的中心度和边的中心度,最后求出节点间边的距离[4],然而,此方法计算量很大且计算复杂,而本文提出的计算用户间距离的过程简单,能大大减少时间复杂度。为了研究的便利,本文仅从上文提到的微博数据集提取出粉丝数、评论数、转发数、获赞数、微博数这5个用户特征,实际应用中,可以提取出更多的用户特征以进一步优化社区发现的结果。
猜你喜欢
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
计算机应用与软件(2021年10期)2021-10-15
金桥(2021年3期)2021-05-21
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
第一财经(2020年4期)2020-04-14
火力与指挥控制(2020年1期)2020-03-27
文苑(2018年17期)2018-11-09
NBA特刊(2018年14期)2018-08-13
