
Spark平台下综合属性权重离群点挖掘算法研究*
2019-09-03 07:22刘建华
计算机与数字工程 2019年8期
马 晶 刘建华
(1.西安邮电大学 西安 710061)(2.西安邮电大学信息中心 西安 710121)
1 引言
现有的入侵检测系统存在许多不足[1],当前面临的主要问题:IDS主动防御能力不足、高速网络环境的性能差[2]。将数据挖掘中离群点检测方法运用到入侵检测中可一定程度改善现状。离群点检测是用来确定小部分数据对象与剩余的大部分数据明显不同或者不一致的问题[3]。离群点检测除了可应用在入侵检测系统中外,也被广泛应用于医疗处理、信用卡诈骗、保险诈骗和内幕交易[4]、工业损毁检测、图像处理、传感器/视频网络监视[5]。
目前,很多离群点挖掘算法被应用于入侵检测,其中基于K-means、DBSCAN的离群点挖掘算法中聚类个数k、阈值的选取和基于Apriori的离群点挖掘算法k频繁项集的选取直接影响到离群点的产生,需要经过大量的实验找出合适的k值和阈值;传统的LOF算法[6]未能考虑数据对象属性的权重问题;主观赋权法在根据属性本身含义确定权重方面具有优势,但客观性较差;而客观赋权法在不考虑属性实际含义的情况下,确定权重具有优势,但不能体现决策者对不同属性的重视程度,有时会出现确定的权重与属性的实际重要程度相悖的情况;文献[7]提出基于的HLOF算法只考虑属性的客观权值,未考虑其主观权值,不能有效地挖掘出离群点。
然而,随着网络数据的爆炸式增长,使用一个CPU节点来进行计算,很难胜任对这些海量数据的分析任务。当今行之有效的解决方案则是在云计算的分布式方法的帮助下增强计算资源的能力,利用通过网络连接的多个节点来共同承担对计算资源需求量较高的复杂计算[2]。目前Hadoop和Spark是两个主流的分布式平台,相比 MapReduce[8],Spark速度快,开发简单,并且能同时兼顾批处理和实时数据分析[9],其中Spark streaming是Spark计算框架中来做实时流处理的模块。因为入侵检测系统的实时性要求,所以,选择Spark平台来做算法的并行化。目前在国内外,已经有很多公司在实际生产环境中广泛使用Spark,比如国外的谷歌、亚马逊,易贝、雅虎等公司和国内的淘宝、百度、华为、优酷、土豆等公司[10]。因此,本文提出综合权重离群点挖掘(Comprehensive attribute weight outliermining,CAWOM)算法,并将其在Spark云计算平台对其并行化来解决以上问题。
2 CAWOM算法
CAWOM算法首先根据层次分析法和均方差赋权法计算出数据对象属性的综合权重,得到数据的属性加权距离,进而求出数据对象的偏离系数和数据集的平均偏离系数,然后对二者进行比较,最终找出离群点。
做如下规定,数据集D={X1,X2,X3,…,Xm}表示m个待检测的数据,其中每个对象Xi由k个属性构成,可表示为 Xi=(Xi1,Xi2,Xi3,…,Xik),每个对象 Xi各个属性的综合权重为(CW1,CW2,CW3,…,CWk)。
2.1 综合权重
为了能够兼顾每个独立网络环境的特殊性,使用综合权值法来对属性赋权。利用AHP和均方差法计算出各属性的主观权值和客观权值,然后采用“乘法”集成法构造综合权值,进而能够综合、全面地考虑属性对离群系数的影响。
AHP计算属性主观权重:层次分析模型见图1,其中,属性权重为目标层,n种攻击方式为准则层,k个属性为方案层,通过各层次单排序权向量计算层次总排序,得出各个属性的权值。具体步骤:根据准则层中各个攻击方式的发生频率构造判断(成对比较)矩阵A,然后计算A的最大特征值λmax1及其相对应的归一化特征向量ω(2),λmax用来计算A的一致性指标(n为准则层因素个数);将准则层中的n个因素作为方案层各个属性的对比标准,构造n个k×k成对比较矩阵B,计算每个矩阵的最大特征值λi及其归一化特征向量ωi,得 出 其 层 次 单 排 序 权 向 量 ω(3),,比较矩阵的一致性的判断与准则层相同;根据层次单排序计算层次总排序,得出 k个属性的权值。
均方差法计算属性客观权重:计算各个属性集(X1i,X2i,X3i,…,Xmi),0<i≤k的标准差si,属性的客观权重公式:
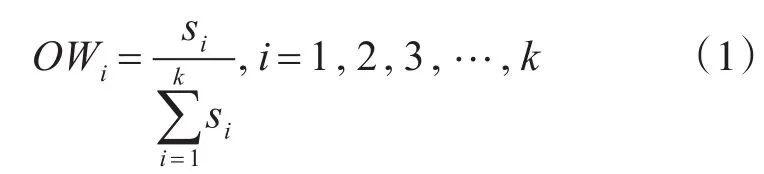
采用“乘法”集成法构造属性的综合权值。综合权值公式:
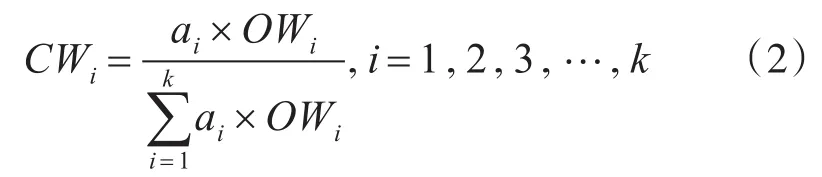
2.2 偏离系数
根据属性的综合权值构造数据对象Xp,Xq的加权属性距离公式为
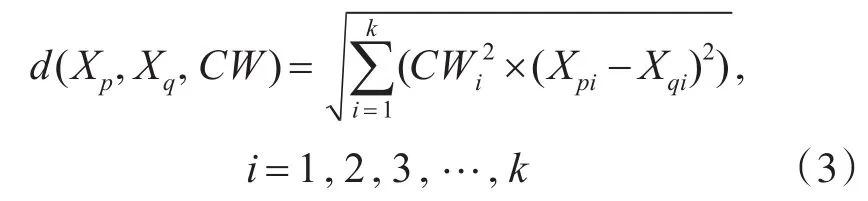
数据对象Xp的加权属性距离公式:

偏离系数(Outlier Factor,OF),OF(Xi)计算公式:

平均偏离系数AOF(D)计算公式:

2.3 算法执行过程
根据综合权重公式,得到各个属性的综合权值,然后计算数据集D中每个数据对象Xi的偏离系数OF(Xi)和平均偏离系数AOF(D),若OF(Xi)>AOF(D),则Xi为数据集D的离群数据,即离群点。具体算法如下:
输入:对象集D={X1,X2,X3,…,Xm}为待挖掘的数据集,属性重要程度参数()。
输出:对象集中的离群点。
算法过程如下:
根据AHP算法确定每个属性的主观权重ai;
根据式(1)计算属性的客观权重OWi;
根据式(2)计算综合权重CWi;
根据式(4)计算每个对象的加权属性距离N d(Xi,CW);
根据式(5)计算每个对象的偏离系数OF(Xi);
根据式(6)计算数据集D的平均偏离系数AOF(D),将OF(Xi)>AOF(D)的对象作为离群点输出。
3 Spark Stream ing
Spark是一套开源的、基于内存的,可运行在分布式集群上的并行计算框架[11~12]。Spark的一切都基于Spark的输入—RDD。RDD可由外部文件存储系统HDFS、HBase等中的数据集创建。Spark平台扩展了5个主要的函数库,Spark SQL、Spark Streaming、MLlib、GraphX和SparkR。
Spark Streaming[13]属于核心 Spark API的扩展,支持实时数据流的可扩展、高吞吐、容错的流处理。DStream(离散数据流)是Spark Streaming的基本抽象,由一组时间序列上连续的RDD来表示,可看作一个RDDS序列。Spark Streaming是将实时数据流根据固定的时间间隔划分成DStream存储在RDDs中,然后从DStream的转换操作生成对RDDs的转换操作,执行产生的中间结果可以存储在内存中以进行迭代操作。图2是基于DStream实现的Spark Streaming模型。
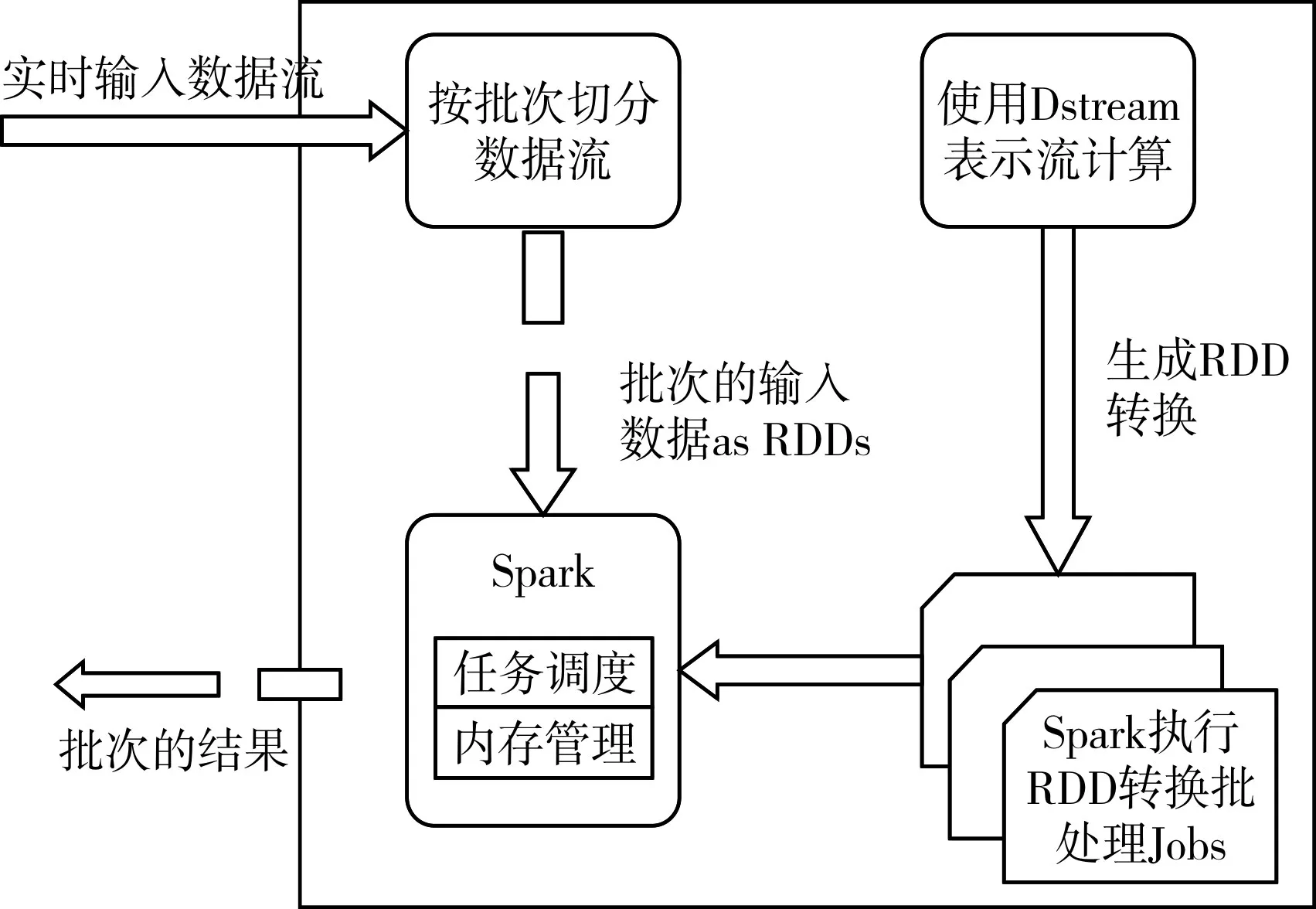
图2 基于DStream实现的Spark Streaming模型
4 Spark平台并行化CAWOM算法
4.1 S-CAWOM算法
S-CAWOM算法是CAWOM算法在Spark平台的实现。算法首先将数据按照1s的时间间隔分配到各个子节点,在各个子节点上根据CAWOM算法计算对象的离群系数OF(Xi)及数据集Di的平均离群系数AOF(Di);将各个子节点的离群点汇总,比较 OF(Xi)与数据集D的平均偏离系数AOF(D)(AOF(D)为各个子节点的AOF(Di)的平均值),找出离群点。图3是Spark平台下算法的并行化流程图。

图3 并行算法流程图
S-CAWOM算法的执行过程:
1)集群从分布式文件系统HDFS上读取数据,以1秒为时间间隔,生成DStream;
2)通过flatMap()方法将数据格式化为向量;
3)通过map()方法将根据CAWOM算法计算出每个节点的OF(Xi)与之前节点向量连接组成新的向量;
4)通过reduce()方法计算各个集群的离群系数 AOFi,然后通过filter()、union()方法得出初始离群点集O';
5)通过reduce()方法得到平均离群系数AOF,然后通过filter()方法得出离群点集O。
4.2 算法伪代码
Input:存放数据对象集地址HDFS_path,Spark集群地址master_address,属性重要程度值向量P(pi),0<i≤k,其中k为属性维数。

5 实验结果与分析
5.1 实验环境
在2台主机上安装Red Hat Linux7.2操作系统,在每台主机上分别创建3台虚拟机。将主机1作为Master节点,主机2和其余6个虚拟机作为Slave节点,每个节点的配置信息均为Internet Core i7 2.7GHz CPU,2GB内存,50GB硬盘。采用CDH平台集成搭建Spark集群。
实验数据采用KDD CUP99数据集,主要包含DoS、Probe、U2R和R2L 4种攻击。数据集为CVS格式,大小约为708MB,包含490万个连接,每个连接占一行,包含38个属性特征[14]。其中的类别型特征属性采用One-hot编码处理,Protocal-type的处理如表1,其余的类别型属性参考Protocal-type的处理。对于连续型属性参考文献[15]中的Imp-Chi2算法处理。

表1 Protecal-type处理表
5.2 实验方法及结果分析
在计算主观权重时,选取KDD CUP99 10%数据集中的攻击比例作为AHP模型准则层的参考。在spark平台将存储在分布式文件系统HDFS上的数据集按照S-CAWOM算法进行离群检测,找出其离群点集,算法进行性能评价时,选取检测率、误检率和算法执行时间3个性能指标与文献[16]中的ACPO、EOS算法进行比较,表2为检测性能对比表。

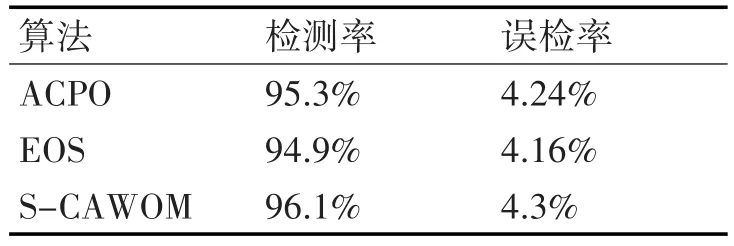
表2 检测率对比表
由表2可以看出,S-CAWOM算法的检测效率高于ACPO和EOS算法,但误检率稍高于ACPO和EOS算法。
为了验证算法的执行效率,在KDD CUP99数据集抽取10000、20000、50000、100000条链接进行验证,比较三种算法的算法运行时间。图4为三种算法分别在10000、20000、50000、100000条链接的运行时间折线图。
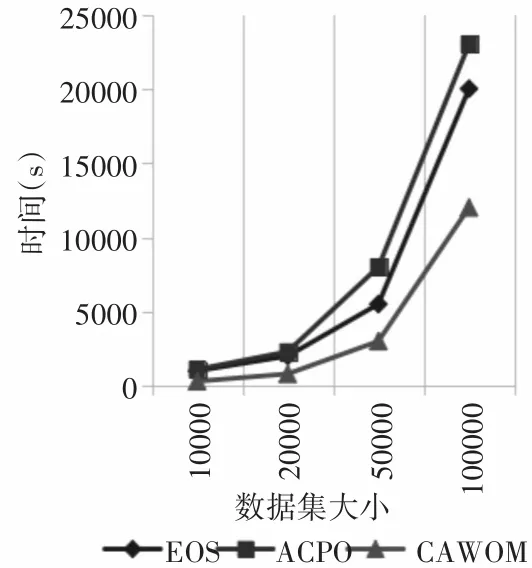
图4 算法运行时间
根据图4可发现,在当数据集在变化时,S-CAWOM算法的运行时间都是最少的。从整个趋势来看,当数据集较小时,各算法的运行时间相差较小,当数据集逐渐增大时,各算法执行时间增长较快,效率减小。
6 结语
本文研究Spark平台下综合属性权重离群点挖掘的问题,由于很多研究都未考虑属性的综合权重,只是从客观属性单方面进行研究,使得离群点的检测效率不高。本文在Spark Streaming框架的基础上,提出了综合属性权重离群点挖掘算法S-CAWOM。实验证明,该算法的执行效率高,检测性能良好。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
心理学报(2022年5期)2022-05-16
计算技术与自动化(2022年1期)2022-04-15
当代陕西(2020年17期)2020-10-28
意林(2019年11期)2019-06-30
人大建设(2018年5期)2018-08-16
诗选刊(2018年7期)2018-07-09
证券市场红周刊(2018年3期)2018-05-14
阅读(中年级)(2016年4期)2016-11-19
科技视界(2016年1期)2016-03-30
