
基于深层声学特征的端到端语音分离①
2019-10-18 06:40李娟娟李子晋
计算机系统应用 2019年10期
李娟娟,王 丹,李子晋
1(复旦大学 计算机科学技术学院,上海 201203)2(盲信号处理国家级重点实验室,上海 200434)3(中国音乐学院 音乐科技系,北京 100101)
语音作为一项最为便捷的交流工具,实现了人类社会高效快速的信息交换,成为人类文明的一个重要助力.然而在现实环境中,感兴趣的语音信号通常会被其他声源干扰,严重损害了语音的可懂度,降低了语音交互的性能.为了解决以上问题,语音分离是最为关键的技术之一.
语音分离是指从多个说话人的混合语音中分离得到想要的语音数据,源于著名的“鸡尾酒会问题”[1],主要是研究如何能够从混合的语音信号中同时得到目标和干扰语音信号,它在语音识别、残疾人助听领域具有广泛的应用.本文主要探究两个说话人混合的情况.图1是语音分离技术的示意图,图中左边的两张语谱图分别是两个说话人的语音的语谱图,经过混合后得到中间的混合语音的语谱图,而经过语音分离以后得到的是右边分离出的语音的语谱图.从图1可以看出,由于不同的说话人的语音的发音特性有差异和说话内容、语速等不同,以及语音信号这种时变信号本身具有一定的短时平稳特性,从而使得语音分离具有可行性[2].

图1 语音分离技术示意图
语音分离作为一个重要的研究领域,几十年来,受到国内外研究者的广泛关注和重视.近年来,监督性语音分离技术取得了重要的研究进展,特别是深度学习的应用,极大地促进了语音分离的发展.在基于深度神经网络的语音分离算法中,特征提取是至关重要的步骤.傅里叶变换域特征是最常用的语音分离特征,Xu[3]、Huang[4]、Weninger[5]等使用傅里叶幅度谱或者傅里叶对数幅度谱作为语音分离的输入特征.Wang等在文献[6]中总结了Gammatone滤波变换域特征,并且利用Group Lasso的特征选择方法得到AMS+RASTAPLP+MFCC的特征组合.Chen等在文献[7]中提取的多分辨率特征MRCG具有明显的优势,逐渐取代了组合特征成为语音分离中最常用的特征之一.然而以上这些传统声学特征的提取需要经一系列复杂的操作,会造成语音能量损失以及长时间延迟.
近年来,端到端的方法已经用于语音识别、语音合成和语音增强等语音任务中,并在这些任务中取得了较优的效果.Luo等人在文献[8]中首次提出了基于非负矩阵分解思想的端到端语音分离,并取得了较优的效果.为了进一步说明端到端的方法在语音分离这一方向的可行性,本文提出以语音信号的原始波形作为深度神经网络的输入,通过网络模型来学习语音信号的更深层次的深层声学特征,实现端到端的语音分离.
1 基于传统声学特征的语音分离
语音分离旨在分离混合语音信号中的信号,这个过程能够很自然地表达成一个监督性学习问题[3-5].一个典型的监督性语音分离系统通常通过监督性学习算法,例如深度神经网络,学习一个从混合语音的传统声学特征到分离目标的映射函数[9].算法1为基于传统声学特征的语音分离算法.

算法1.基于传统声学特征的语音分离算法1)时频分解,通过信号处理的方法将输入的时域信号分解成二维的时频信号表示;2)特征提取,提取帧级别或者时频单元级别的听觉特征(短时傅里叶变换谱或者短时傅里叶功率谱等);3)模型训练,利用大量的输入输出训练对通过机器学习算法学习一个从混合语音特征到分离目标(理想二值掩蔽或者理想比例掩蔽等)的映射函数;4)波形合成,利用估计的分离目标以及混合信号,通过逆变换(逆傅里叶变换或者逆听觉滤波)获得目标语音的波形信号.
在提取传统声学特征时,先要进行时频分解,一般都是将时域信号通过短时离散傅里叶变换(Short-time Fourier Transform,STFT)、离散余弦变换(Discrete Cosine Transform,DCT)或者通过一些听觉滤波器组(如Gammatone滤波器组)得到二维的时频域表示.在这个过程中产生了两个问题.一是忽略了在提取特征的过程中造成语音的高频部分以及相位信息的损失,以及在变换过程中可能会引入虚假的信息,从而对语音分离的性能造成影响.二是由于变换域中的有效语音分离对高频分辨率的需求,导致相对较大的时间窗口长度,对于语音通常超过32毫秒[3,10-12],音乐分离超过90毫秒[13].因为系统的最小延迟受STFT时间窗的长度限制,所以当需要非常短的延迟时,这限制了此类系统的使用,例如电信系统或可听设备这类实时性系统.克服这些问题的一种自然方法是直接建模时域中的信号.有研究结果表明,语音原始波形相比基于傅里叶变换的梅尔倒谱系数等特征,在某些研究领域具有更好的语音性能[14].所以本文选择以语音信号的原始波形作为深度神经网络的输入,通过网络模型来学习语音信号深层次的深层声学特征(Deep Acoustic Feature,DAF),实现端到端的语音分离.
2 基于深层声学特征的端到端语音分离
图2是基于深层声学特征的端到端语音分离算法的整体流程,主要分为4个部分:(1)信号预处理,对混合信号的原始波形进行分段及规整.(2)深层声学特征提取,提取时域信号的DAF作为分离模型的输入.(3)分离模型,训练分离模型得到各个信号的特征掩蔽值.(4)信号重建,利用得到的信号的特征掩蔽值及混合信号的DAF,通过信号重建得到各个分离信号的时域波形.

图2 算法整体流程
2.1 信号预处理
数据预处理在许多机器学习算法中起着很重要的作用,如果输入的特征向量在整个训练集上均值接近零,那么模型的收敛速度会很快.语音信号的预处理模块包括两部分,分段、规整.
首先将混合信号分成K段,每段长度为L,再对每段使用单元L2规整,Xk是分段后的信号,规整方式如下:

单元L2规整即可以削弱时不变信道的影响,还能减少加性噪声的影响,同时时域信号被缩放到相似的动态范围内,使得后续模型的学习过程也能取得较好的效果.
2.2 深层特征提取
在基于深度神经网络的语音分离算法中,语音分离任务能够被表达成一个学习问题,对于深度学习问题,特征提取是至关重要的步骤.提取好的特征能够极大地提高语音分离的性能[15].
针对传统声学特征提取方法需要经过傅里叶变换、离散余弦变换等操作,提取复杂特征作为输入,会造成能量损失的问题,本文选择以语音信号的原始波形作为深度神经网络的输入,通过网络模型来学习语音信号深层次的声学特征,DAF提取过程如图3所示.

图3 DAF提取过程
在DAF的提取过程中,参考语言建模[16]中的门限卷积方法,在第二层全连接层后引入门限机制如下:

其中,ReLU为线性整流函数,σ为Sigmoid激活函数,⊙表示逐元素乘积操作.引入门限机制可以控制模型中的信息流动,帮助模型的神经元之间有更加复杂的联系.相比于语音建模中的门限卷积,本文中使用全连接代替卷积操作,虽然使用卷积操作能减少训练参数从而缩短训练时间,但是使用全连接操作能减少语音损失的能量,提取的特征也能更多地挖掘深层次的声学特征,提升语音分离的性能.
2.3 分离模型
双向长短时记忆网络(Bi-derectional Long Short Term Memory,BiLSTM)结构能够有效抓住音频数据中的长时依赖,对语音建模非常有效[17,18].本文中,分离网络由4层深度BiLSTM后面接着一个全连接层构成,在第二层隐藏层的输出与第四层隐藏层的输出之间增加了跳跃连接[19],改善了多层网络反向传播的梯度消散问题,提升网络性能.
网络的输入是混合信号的DAF,网络的输出是各个信号的掩蔽值.已有研究证明在语音分离任务中把掩蔽值(mask)作为分离目标能显著地提高语音分离的可懂度和感知质量.其中,最常使用的分离目标之一为理想比例掩蔽(Ideal Ratio Mask,IRM)[20].基于IRM的定义,本文中使用的信号的掩蔽值,特征比例掩蔽(Feature Ratio Mask,FRM)的定义如下:

使用掩蔽值作为分离模型的输出比使用特征DAF的效果更好.全连接层的激活函数为Softmax函数.为了加速训练进程及维持训练过程中的稳定性,对分离网络的输入即混合信号的DAF要进行层级归一化.
2.4 信号重建
将混合信号的DAF逐元素乘以各个信号的FRM,经过一层全连接层后.得到规整的目标信号的时域波形,最后通过逆规整和整合,重建各个信号的时域信号.
2.5 损失函数
网络模型的最终输出是估计的干净信号的时域波形,由于模型效果的重要评价指标之一是尺度不变信噪比(Scale-invariant Source-to-noise Ratio,SI-SNR)[8],所以在这里不使用估计语音的时域波形和干净的时域波形的均方误差,而是基于SI-SNR来设计损失函数.SI-SNR的定义如下:
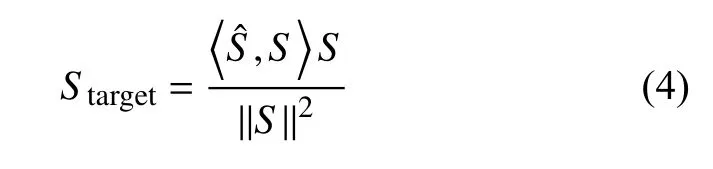

3 实验结果和分析
3.1 实验配置
华尔街日报语料库(Wall Street Journal,WSJ0)是语音分离任务常用的数据集[11-13],每条语音大约在5 s左右.混合语音由随机选取WSJ0训练集si_tr_s中的任意两个说话人,以随机选取的0-5 dB信噪比混合而成,最终形成30个小时的训练集和10小时的验证集.测试集使用WSJ0的si_dt_05和si_et_05的未知说话人以相同的混合方式产生,最终生成5小时的测试集.
实验中所使用的语音波形文件具有8 kHz的采样频率.分段时的长度L=40 (5 ms),每段之间有50%的重叠,提取的DAF长度为500.深度BiLSTM采用4层隐藏层,每层隐藏层的结点是500,在第二层隐藏层的输出与第四层隐藏层的输出之间有跳跃连接,最后一层全连接层的结点数为1000,使用Softmax激活函数.在训练过程中,使用随机初始化的网络,采用的最小批训练方法中每个最小批的训练集包含128个样本.初始的学习率设置为1e-3,当验证集上的损失在连续3个迭代次数(epoch)没有降低时,就将学习率设置为当前学习率的一半.当验证集上的损失在连续10个epoch都没有降低时停止训练.选用Adam优化函数,Adam优化器的超参数具有很好的解释性,通常无需调整或仅需很少的微调,适用于大规模数据及参数的场景.
3.2 评价指标
本实验中采用的评价指标为BSS-EVAL指标.BSSEVAL工具箱通常用来评估模型的分离性能,它是由Vincent 等人在 2006年提出的语音分离指标[21],并开源的语音分离评估工具箱,广泛被研究者用于语音分离评价中.根据 BSS-EVAL 指标,语音分离评估使用3个定量值分别是,信噪干扰比(Source to Interference Ratio,SIR),信噪伪影比(Source to Artifact Ratio,SAR)和信噪失真比(Source to Distortion Ratio,SDR).3个值均是越高越好.其中,SDR计算分离声音中存在多少总失真,SDR值越高表示语音分离系统整体上的失真越小,语音分离系统性能越好.SIR直接比较非目标声源噪音与目标声音的分离程度.SAR是指在语音分离过程中引入的人工误差,SAR值越高,表明引入误差对语音分离系统影响越小.
3.3 实验结果和分析
(1)基于DAF的语音分离算法的效果
表1为所提的基于DAF的语音分离算法在测试集(3000条语音)上的分离语音的平均SDR、SIR及SAR值,分别为11.60、22.58和12.38.从客观评价指标来看,本文所提出的语音分离算法在测试集上的有效性.

表1 测试集平均SDR、SIR、SAR值
图4是本文所提语音分离算法在测试集(3000条语音)上的SDR值(每条混合语音分离出来的两条语音的SDR值取平均)的分布.其中分离后语音的SDR值大于10的有75%,分离效果很好,语音质量清晰可懂.SDR值在5到10范围内的有8%,分离效果较好,语音不够清晰,但是可懂.SDR值在0到5范围内的有10%,分离效果一般,不明显.SDR值<0的有7%,分离效果差,分离前与分离后没有差别.经观察分析,这7%的混合语音,混合的两个不同的说话人基本是同性别并且发音特性较为相似,导致分离算法在这部分数据上处理效果不好.

图4 测试集上SDR值分布
图5分别是混合语音、分离语音1和2的DAF的可视图.从图中可以看出,DAF中有一条条的类似于频谱图中的“声纹”的东西,并且不同的说话人对应的“声纹”的位置不同,说明深度网络确实可以从语音的时域信号中学习到不同说话人的声音特性并且能做出相应的区分.

图5 语音DAF的可视图
图6是所提语音分离算法的一个效果示例,每张小图的上方是语音信号的原始波形,下方是其对应的语谱图.图中左边的两张小图分别是测试集中的两个说话人的语音,以0.27 dB的信噪比经过混合后得到中间的混合语音,右边是分离出的两个说话人语音,分离后的SDR值分别为14.20和12.39.无论是从客观评价指标SDR,还是从主观地比较分离前后的语音原始波形和语谱图,均能看出所提出语音分离算法的有效性.

图6 一个语音分离效果示例
(2)不同声学特征的效果对比
在这一部分实验中,为了探究本文使用的深层声学特征的有效性,与语音分离任务中最常用的传统声学特征,经过STFT变换的257维对数功率谱特征(Log Power Spectrum,LPS)做对比.同时为了验证DAF中使用的门限机制的有效性,与单独使用ReLU、Sigmoid激活函数做对比,其他实验配置与3.1小节的配置相同.
表2为使用不同声学特征的测试集上的平均SDR、SIR和SAR值.使用门限机制DAF、单独使用ReLU评价指标比使用LPS特征高,说明使用网络去学习语音信号深层特征比使用传统基于STFT的特征有效.而单独使用Sigmoid的深层特征比使用LPS评价指标低,说明了提取深层特征中选取恰当激活函数的重要性,选取不当会导致没有传统特征效果好.另外,使用DAF特征比使用单独ReLU和单独使用Sigmoid的评价指标高,说明本文所提出的深度声学特征中使用门限机制的有效性.

表2 不同声学特征的测试集平均SDR、SIR、SAR值
(3)不同分离网络的效果对比
在这一部分实验中,为了验证分离网络中使用的BiLSTM的双向的有效性,使用普通LSTM(非双向)与之做对比.深度LSTM网络有4层隐藏层,每层隐藏层的结点为1000.其他实验配置与3.1小节的配置相同.
表3为使用不同分离网络(BiLSTM vs 普通LSTM)在测试集上的平均SDR、SIR和SAR值.使用BiLSTM比使用普通LSTM的分离网络的SDR值高了5左右.因为普通LSTM在时序上处理序列没有考虑未来的上下文信息,忽略了未来时刻的影响.而使用BiLSTM看到未来信息对当前时刻的影响,更适用于本算法中的分离网络.

表3 不同分离网络的测试集平均SDR、SIR、SAR值
(4)不同损失函数的效果对比
在本实验中采用了1/SI-SNR的损失函数,其他最常用的损失函数是直接基于时域信号的最小均方差(Minimum Mean Squared Error,MMSE)损失函数,直接优化估计语音与干净语音的时域信号差.该损失函数定义如下:

表4为使用不同损失函数(1/SI-SNRvs MMSE)在测试集上的平均SDR、SIR和SAR值.使用基于SI-SNR的损失函数比使用MMSE的SDR值高了4左右.因为SI-SNR本身就是评价语音分离效果的重要指标,SI-SNR越高则语音质量越高,相对于直接优化语音原始波形的损失,使用基于SI-SNR的损失函数更适用于本算法的模型优化.

表4 不同损失函数的测试集平均SDR、SIR、SAR值
(5)不同语音分离算法的效果对比
在这一部分实验中,为了探究所提算法在语音分离任务上的性能优劣,使用目前四种具有代表性的语音分离算法与之做对比,分别为深度聚类(Deep Clustering,DC)语音分离算法[10],置换不变性(Permutation Invariant Training,PIT)语音分离算法[11]、时域语音分离算法Tasnet[8]和在音乐分离任务上表现很好的多任务Chimera模型[13].这四种方法中有基于时域的方法,也有基于频域的方法.在测试集上的测试结果如表5所示.这可以发现,本文所提出的算法的在语音分离任务上的有效性.

表5 不同语音分离算法的测试集平均SDR值
(6)时间延迟
在这部分实验中,为了探究基于传统声学特征的分离算法和本文所提算法的时间延迟,选用最常用的STFT特征与之做对比,实验结果如表6所示.算法延迟T等于建模所需的时域波形时间T1、特征提取所需的时间T2、分离网络的时间T3和波形重建的时间T4的和.实验中保证分离网络的结构相同,即T3相同,T4与T2成正比.所以实际的时间延迟由T1和T2决定.实验所使用的GPU为GTX1070.在8 kHz的采样率下,提取STFT特征时,每帧的采样点数最少为256,对应时域波形为32 ms.本文对5 ms的时域波形进行建模,通过模型对5 ms提取DAF特征的时间为0.002 ms.5.002 ms远小于32 ms,本文所提算法能极大地降低时间延迟.

表6 时间延迟实验(单位:ms)
4 总结与展望
本文提出了基于深层声学特征的语音分离算法,该算法通过网络模型来学习语音信号的更深层次的深层声学特征,实现端到端的语音分离.在实验部分,选取了SDR、SIR和SAR作为客观评价指标在WSJ0数据集上进行了一系列对比实验.结果表明,本文提出的深层声学特征在语音分离任务中的有效性,提出的算法提升了语音分离的性能.并且本文对5 ms的时域波形进行建模,极大地降低了时间延迟.但是测试集中仍然有7%的数据分离效果不好,对于这部分发音特性较为相似的语音分离任务,是今后的研究重点.
猜你喜欢
电声技术(2022年7期)2022-09-23
电子技术与软件工程(2022年6期)2022-07-07
雷达学报(2022年2期)2022-04-30
雷达学报(2022年2期)2022-04-30
科技视界(2020年24期)2020-08-26
家庭影院技术(2020年5期)2020-08-24
科技视界(2020年22期)2020-08-14
家庭影院技术(2020年6期)2020-07-27
汽车与驾驶维修(维修版)(2020年2期)2020-03-20
宇航计测技术(2019年1期)2019-03-25
