
基于深度学习的卫星图像识别分类方法①
2019-10-18 06:40方浩文施华君
计算机系统应用 2019年10期
方浩文,施华君
(中国电子科技集团公司第三十二研究所,上海 201808)
卫星遥感图像经过处理后得到的卫星图像包含了大量的信息,具有数据量大和数据类型复杂多样的特点.传统的目标检测识别方法难以适应海量数据,依赖人工标注,非常耗时耗力,且强烈依赖于专业知识和数据本身的特征[1].而近年来非常活跃的深度学习[2-4]则提供了非常有效的特征提取框架,使得其在卫星遥感图像的识别和分类中也具有很好的效果.本文采用了深度学习网络中的卷积神经网络(CNN),这是一种能从大量数据中自动学习目标特征的模型,并且已成为目标检测与识别领域的研究热点[5-10].
基于CNN的目标检测算法的基本流程为特征提取网络、区域建议生成、感兴趣区域分类.采用卷积神经网络作为特征提取网络,对检测算法的检测性能具有显著影响.通常采用的卷积神经网络有AlexNet[11],ZF[12],VGGNet[13],GoogleNet[14],ResNet[15]等,这些网络通过逐步加深网络来提高性能.本文采用了Keras框架及其中的VGGNet神经网络模型并取得了良好的效果.
目前,已有基于深度学习技术的卫星图像分类识别应用,如俞汝劼等使用了YOLO算法[16]与图像分割进行了卫星图像中航空器的识别[17],保证了算法精度与实时性.又如D.Duarte等利用了对偶连接和加宽卷积的CNN来进行卫星图像中建筑物损毁分类[18],提升了一定的分类准确度.
卫星图像包含了天气因素,如雾天、多云等.这些天气因素会影响地物特征的识别,同时也可以作为天气特征进行识别.何恺明在2009年提出了暗通道除雾算法[19],指出没有雾的图像其像素点在至少一个颜色通道上具有很低的强度,所以可以根据这个先验和雾图像模型来判断图像中雾的厚度并还原出一个没有雾的图像.由于所有图像都具有天气特征,所以意识到此算法可以利用在卫星图像识别分类方面后,本文使用的方法便利用了此除雾算法进行图像预处理作为改进.
正则化是一种为了避免过拟合而常用的方法,岭回归正则化即L2范数正则化[20],通过对模型系数的L2范数进行惩罚,来达到在拟合数据的同时使模型权重尽可能小的目的.本文采用此方法进行了最后标签之间相关性的处理.
第1部分简要介绍深度学习VGGNet网络模型、Keras框架和F2Score评测指标;第2部分介绍了识别分类方法的设计及展示系统的框架,在数据预处理小节介绍了如何利用上述除雾算法等技巧进行数据增强,随后介绍了基于VGGNet模型的训练和预测的流程,说明了如何使用上述正则化方法利用标签的相关性进行预测,最后一小节介绍了基于Django的在线识别分类展示系统的框架设计及搭建方法;第3部分介绍实验的设计和细节,并将实验结果进行对比来得出结论,最后说明本方法的下一步研究方向.
1 深度学习网络模型及框架概述
1.1 VGGNet
VGGNet[13]是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起开发的深度卷积神经网络.VGGNet探索了卷积神经网络的深度及性能之间的关系,通过反复堆叠3×3的小型卷积核和2×2的最大池化层,VGGNet成功构筑了16~19层深的卷积神经网络(如图1所示).VGGNet相比之前的网络结构,错误率大幅下降,并取得了ILSVRC2014比赛分类项目的第二名和定位项目的第一名.同时具有很好的拓展性,迁移到其他图片数据上的泛化性非常好.

图1 VGGNet各级别网络结构图
VGGNet拥有5段卷积,每一段内有2~3个卷积层,同时每段尾部会连接一个最大池化层来缩小图片尺寸.每段内的卷积核数量一样,越靠后的段的卷积和数量越多:64-128-256-512-512.其中经常出现多个完全一样的3×3的卷积层堆叠在一起的情况,是因为3个串联的3×3卷积层效果相当于1个7×7的卷积层,参数比后者少45%,且3个3×3的卷积层拥有比1个7×7卷积层更多的非线性变换,使得CNN对特征的学习能力更强[21].
1.2 Keras框架
Keras[22]是一个用Python编写的高级神经网络API,它能够以Tensorflow,CNTK或者Theano作为后端运行,具有用户友好、模块化、以拓展性和基于Python实现的特点,同时支持卷积神经网络和循环神经网络以及两者的结合,能够在CPU和GPU上无缝运行.
1.3 F2-Score
F-Score[23]是一个为了平衡准确率和召回率的较为全面评价的一个分类指标.当对一个样本集合(包括正样本和负样本)进行分类时,会出现以下几种情况:
TruePositive:把本来是正样本的分类成正样本;
FalsePositive:把本来是负样本的分类成正样本;
FalseNegative:本来是正样本的分类成负样本;
TrueNegative:本来是负样本的分类成负样本.
对准确率(Precision)和召回率(Recall)的定义如下:

F-Score的定义如下:

所以F2-Score即当β=2时的F-Score,即召回率比准确率重要一倍.
2 除雾算法与正则化介绍
2.1 除雾算法
何恺明提出了一种非常简单而有效的去雾算法[19],可以同来还原图像的颜色和能见度.与之前的方法不同,他把注意力放到了无雾图像的统计特征上.他发现,在无雾图像中,每一个局部区域都很有可能会有阴影,或者是纯颜色的东西,又或者是黑色的东西.因此,每一个局部区域都很有可能有至少一个颜色通道会有很低的值.他把这个统计规律叫做暗通道先验.直观来说,暗通道先验认为每一个局部区域都总有一些很暗的东西.由于雾总是灰白色的,因此一旦图像受到雾的影响,那么这些本来应该很暗的东西就会变得灰白.不仅如此,根据物理上雾的形成公式,还能根据这些东西的灰白程度来判断雾的浓度.
给暗通道先验一个数学定义,对于任意的输入图像J,其暗通道可以用下式表达:

式中,Jc表示彩色图像的每个通道,Ω(x)表示以像素X为中心的一个窗口.
暗通道先验的理论指出:

在文献[15]中,统计了5000多幅图像的特征,基本符合暗通道先验,因此可以认为是一条定理.接着进行数学推导来解决最终问题.
在计算机视觉和计算机图形中,下述方程描述的雾图形成模型被广泛应用:

其中,I(x)为已有待去雾图像,J(x)为恢复成无雾的图像,A为全球大气光成分,t(x)为透射率.
将式(3)做变形:

式中,c为RGB三通道.
假设在每一个窗口内透射率t(x)为常数,定义其为(x),且A已知,对式(4)两边求两次最小值运算,得到:

根据暗通道先验理论式(1),可推导出:

将式(6)带入式(4),得到:

这就是透射率的预估值.
在实际情况下,即使天气晴朗,空气中也存在一定颗粒,看远处物体还是能感觉到雾的影响,所以需要保留一定程度的雾,可以通过在式(7)中引入一个[0,1]之间的因子ω ,则式(7)修正为:

以上运算均基于全球大气光A已知,实际可以在有雾图像中获取该值,步骤为:
(1)从暗通道图中按照亮度的大小提取前1%的像素;
(2)在这些位置中,在原始有雾图像I中寻找对应的具有最高亮度的点的值,作为A值.
当投射度t的值很小时,会导致J的值偏大,从而使得图像整体向白场过度,因此一般可设置一阈值T0,当t值小于T0时,令t=T0.

最终的恢复公式如下:在意识到可以利用除雾算法作为在有雾图像的地物特征识别的改进后,本方法在预处理阶段对图像进行了除雾处理,效果如图2.

图2 图像除雾算法使用前后对比
可以看到地物特征明显更为显著,更有利于对地物特征进行识别,之后将通过实验证明除雾算法的有效性.
2.2 正则化
有监督机器学习主要问题即在规则化参数的同时最小化误差,最小化误差为了模型能很好拟合训练数据,而规则化参数是为了防止模型过拟合训练数据.如果参数太多,会导致模型复杂度上升,导致过拟合.于是正则化的作用有:
(1)约束参数,降低模型复杂度;
(2)规则项的使用还可以约束我们的模型的特性.这样就可以将人对这个模型的先验知识融入到模型的学习当中,强行地让学习到的模型具有人想要的特性,例如稀疏、低秩、平滑等等.
一般来说,监督学习可以看成最小化如下目标函数:

其中,求和部分第一项L(yi,f(xi;ω))为误差平方和,第二项 λ Ω(ω)为惩罚项,为了使模型尽量简单,我们需要通过规则化函数 Ω (ω)来对参数 ω 进行约束.然而Ω(ω)的不同取得的效果也不同,主要常见的 Ω (ω)有L0,L1和L2范数.
L0范数指向量中非0的元素的个数.如果用L0范数来规则化一个参数矩阵ω的话,就是希望ω的大部分元素都是0.L1范数是指向量中各个元素绝对值之和,也称Lasso回归正则化.
L1范数为L0范数的最优凸近似,L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用.参数稀疏可以实现对特征的自动选择,会学习筛选掉信息量不够的特征,且会让模型更容易解释.在本数据集中,因为大量特征具有相关性,如天气特征中,有晴朗标签则不会有云、雾天气标签,河流常出现在雨林旁边,道路常在住房和农业处出现.故不适合使用更有利于处理稀疏特征数据的L1范数.
L2范数又称岭回归正则化,是指先对向量中各元素进行求平方和,然后再求平方根.通过让L2范数的规则项||ω||2最小,可以使得ω的每个元素都接近于0.
L2范数可以使参数变小,从而使得模型更简单,因此不仅可以防止过拟合,还可以让优化求解变得稳定与快速[24].岭回归正则化在本数据集中表现良好,精度更高且更好适应与拟合.故本方法采用了添加岭回归正则化层来进行特征之间相关性的处理.
3 基于深度学习的识别分类与展示
3.1 数据预处理
因为卫星数据数量庞大,会有许多诸如云、雾等天气因素干扰使得我们无法看清地物特征,此时可以使用图像除雾算法使得类似路、水、农田等标签更明显,从而能够得到更好的地物特征.本文对训练数据进行了除雾算法操作(图3),同时保留原有数据进行对比.由于进行了去雾处理,所以针对其中包含云、雾等标签的图像会降低特征,下一节会讲述如何处理这个问题.
其次在训练数据时还需要通过变换图像大小来进行输入,然后通过数种数据增强方法进行随机变换,从而增加了训练数据集大小,并可以更好地防止过拟合以及增强模型的鲁棒性.
3.2 模型训练
因为使用了除雾算法可能会导致某些标签变换过大,本方法采用了对每个标签进行单独训练模型的方式(图4),即使用除雾后和未除雾的原始训练集进行每个标签的单独训练,得到了每个标签在不同训练集上的准确率.由于一张图中可能会含有数个标签,于是选择每个标签在验证集上表现更好的使用的训练集训练出的模型,将标签进行整合,从而减少除雾算法带来的负面效果.例如,除雾后训练出没有雾标签的图像在未除雾时训练出有雾标签,则说明此图像有雾标签的准确度更高,在验证集上验证结果也是如此.
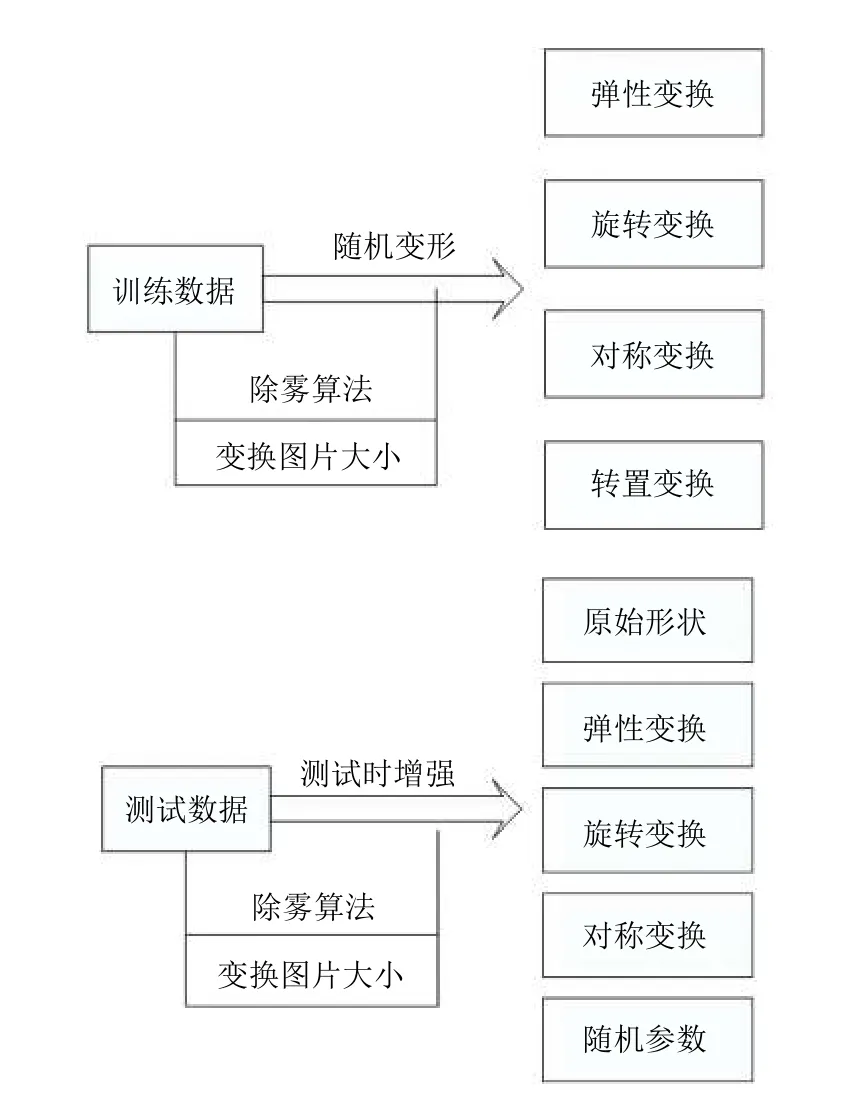
图3 数据预处理流程

图4 训练模型及预测流程
训练时采用了3种损失(loss)函数,其中F2Loss是一种结合了准确率和召回率的评估指标,其召回率比准确率重要一倍.所以在训练模型时不仅仅需要训练预测标签的概率,还需要选择一个合适的阈值,使得当概率大于阈值时,判断有此标签,否则没有.本文对F2-Loss函数进行了改进,使得训练时更注重于改进每个标签的召回率,从而更符合F2-Score的评判标准.结果是对某些如全云、农业等标签效果明显.
3.3 预测
许多标签有着相关性,比如晴朗和有云、全云和有雾就不可能同时出现,而住房和农业同时出现的情况更多,即利用相关性可以更好地改进模型进行预测.所以在本文提出的方法里,采用了以下方法:先用VGGNet训练出所有标签的单独概率,依前方法整合得到模型,随后添加一个岭回归正则化层,以便在给定所有其他标签的情况下重新校准每个标签的概率.相当于在进行特定标签的最终预测时,又添加了一个输入为所有标签的VGGNet预测的单独的特定标签岭回归模型.这样一来就利用了各标签之间的相关性来提升了模型的鲁棒性,且减少了因为数据集相关性而导致的过拟合现象.并且本文做了没有添加岭回归正则化层的对比实验.
3.4 展示系统搭建
为了能够更好地展现本方法的结果,并建立在线上传识别图像并展示的系统,使用Django搭建了一个在线展示系统(图5).

图5 展示系统设计流程
Django是一个用Python语言编写的开源Web开发框架,鼓励快速开发,并遵循模型-视图-控制器(MVC)设计.功能完善,要素齐全,具有强大的数据库访问组件、灵活的统一资源定位符(URL)映射、丰富的模板语言,安全性和可拓展性都非常优秀.
展示系统具有以下功能:批量上传、等待动画、批量预测和带标签展示.
批量上传后将新上传的图片分别保存至展示图片保存路径和新上传图片保存路径,并对新上传的图片进行预测并得到标签,于此同时,前端界面显示等待动画.得到标签后对展示图片进行标签添加,将展示图片保存至数据库,并删除新上传图片.这一步是为了每次上传后只用预测新上传的图片,而展示图片均已添加过标签,直接放入展示图片页面即可,相比每次都要进行全部图片预测大大提高了速度.上述操作进行完毕后等待动画结束并进入展示图片页面.
4 实验结果与分析
为了验证本文提出的基于深度学习的识别分类方法,对实验设计如下.
4.1 准备工作
数据来源于Planet和其合作伙伴SCCON在太阳同步轨道(SSO)和国际空间站(ISS)轨道上的4波段卫星的地球全帧分析场景图片,并用Crowd Flower平台以及柏林和洛杉矶的标注团队进行标注,共分为全云(Cloudy),局部有云(Partly Cloudy),有雾(Haze),清晰(Clear)等4个天气标签;原始森林(Primary),水(Water),居住 (Habitation),农业 (Agriculture),道路(Road),种植 (Cultivation),裸地 (Bare Ground)等 7个常见地物标签;刀耕火种(Slash and Burn),选择性砍伐(Selective logging),开花 (Blooming),常规采煤(Conventional Mining),矿业采煤 (Artisinal Mining),吹倒(Blow Down)等6个不常见地物标签.总共17个标签,40 479张有标注的图片.
4.2 实验阶段
在训练数据经过随机变换后以8∶2的比例随机分成训练集和验证集,并进行标签映射,将训练集中有云、雾的图片进行了除雾处理,并保留原始数据进行对照实验.对所有图片进行红绿蓝(RGB)转换,去除各维度均值.均值来自于ImageNet数据集统计,ImageNet含有近1400多万张图片,涵盖2万多个类别,去除均值更有利于图像训练.随后进行大小裁剪使得符合VGGNet输入,并加载Keras框架中的VGGNet-16模型.
加载模型完成后进行批标准化.批标准化是近年来深度学习领域的重要成果,可以使得在深度神经网络训练过程中每一层神经网络的输入保持相同分布.随着网络深度的加深和训练过程的进行,深层神经网络在做非线性变换前的激活输入值会逐渐发生偏移和变动,整体分布逐渐往非线性函数的取之区间的上下限两端靠近,导致反向传播时低层神经网络的梯度消失,从而会使得神经网络收敛越来越慢.而批标准化可以通过一定的手段,将每层神经网络任意神经元的输入值分布变成均值为0方差为1的正态分布,避免梯度消失问题.
在卷积层和全连接层之间使用扁平函数,使得多维输入变成一维,大大减少参数使用量,避免过拟合现象.
优化器选择自适应矩估计,初始学习率lr为0.0001,采用当评价指标不再提升时减少学习率的策略,减少因子factor为0.1,每次学习率将以lr*factor的形式减少.因为当学习停滞时,减少2倍到10倍的学学率常常能获得较好的效果.当3个循环后评价指标都不再改善后将停止训练.
激活函数选择LeakyReLU,是ReLU激活函数的特殊版本,当不激活时,LeakyReLU仍然会有非零输出,从而获得一个小的梯度,避免ReLU可能出现的神经元“死亡”现象.
最后在预测前进行了添加岭回归正则化层、添加Lasso回归正则化层和不添加的对照实验.
4.3 实验结果
本节通过对照实验对除雾算法和岭回归正则化层的效果进行了验证,具体如图6、图7和图8.

图6 除雾前后部分标签验证集F2-Score

图7 除雾前后总体F2-Score

图8 添加正则化层前后总体F2-Score
由图6和图7可以看出,除雾算法增强了部分标签(如water和bare_ground)的F2-Score,但同时也降低了其他的标签(如haze和clear)的F2-Score.然而这点降低可以通过为每个标签选择更好的模型,并整合这些模型来解决.总体来说除雾算法提高了整体的F2-Score,效果明显.
由图8可以看出,相比于不添加和添加Lasso回归正则化层,添加岭回归正则化层可以改善整体预测效果,对提高识别准确率有帮助,证明了添加岭回归正则化层的作用.
根据表1可以看出,大部分标签的F2-Score可以达到90%以上,表现出良好的检测效果,但有部分标签F2-Score甚至不到50%.根据分析论证后得到以下影响分类精度的因素:
(1)数据集的大小.本方法采用的数据集总量达四万余张图片,总体数据集大小足够进行训练,故天气标签及常见地物标签经过训练后得到良好的结果,而不常见的地物标签只有区区数百张图片,数据集过小,故无法很好地提取特征进行训练,从而得到的结果不如人意.但这些标签总数不多,对总体的F2-Score影响并不大.
(2)人工标注时的误差.由于本方法采用的数据集需要人工标注,而人工标注时由于每个人对标签的判断不尽相同,且同一个人也可能会对标签的判断前后不一,从而会出现标注误差.这属于不可避免的影响因素,对每个需要有标注数据集的实验均会有影响.
(3)地物标签的交叉.由于本数据集含有的部分标签具有相互交叉的特点,如:农业与种植、常规采煤与矿业采煤等,故会在训练时会影响特征的提取,从而会影响预测时标签的分类.

表1 各标签原始F2-Score
本方法在不断地微调后得到的F2-Score为92.832%,证明本方法针对卫星遥感图像取得了良好的检测效果,准确地挖掘到了数据特征,可以作为卫星图像识别分类系统的算法.于是本文利用此方法进行展示系统服务器搭建,部分效果如图9所示.

图9 卫星图像识别分类系统(部分)
5 结束语
本文提出了利用除雾算法与岭回归正则化的基于深度学习网络模型VGG的卫星图像识别分类方法,针对卫星遥感图像的特点,分析了卷积神经网络的原理和框架结构,使用深度学习的方法进行了识别和分类.通过一系列的数据增强方法和调整,得到了合理优化的卷积神经网络.最后将方法应用于在线识别分类展示系统.实验结果表明本文方法能够准确对卫星图片进行识别分类,从而证明其有效性.如何进一步提高准确率和减少模型规模是下一步的研究方向.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
波谱学杂志(2022年1期)2022-03-15
华南师范大学学报(自然科学版)(2021年5期)2021-11-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国校外教育(下旬)(2017年8期)2017-10-30
神州·上旬刊(2017年9期)2017-10-15
