
基于多尺度卷积核特征提取算法的手写数字识别研究
2019-11-11 07:36陈德强
韶关学院学报 2019年9期
陈德强,潘 峰,李 伟
(贵州民族大学 数据科学与信息工程学院,贵州 贵阳550025)
字符识别最早可追溯到1929年德国科学家Dausheck提出光学字符识别的概念而得了专利权[1].1933年美国科学家Handel也获得了字符识别相关专利权[2].在1945年出现了首个字符识别工具[3].在这一时期技术还不够成熟,主要是对单个独立的规范手写字符或印刷体标准字符采用模板匹配的方法进行识别.到20世纪60年代初,第一代商用OCR[4]系统已开始出现,涌现了一些能对部分字型的字符进行识别的字符识别系统.到20世纪80年代初,我国开始对手写汉字识别技术进行研究[5].手写字符识别技术[6-8]经过近半个世纪的漫长发展后,随着计算机的诞生与迅速发展,图像处理技术与模式识别技术得到了有效的结合,并设计出了高精准的字符识别算法,与此同时也不断涌现字符识别软件产品.手写数字识别也在此时出现,并在多种行业中得到了应用,也是当前模式识别领域的重要研究热点.面对各种来自不同行业和不同需求的手写字体,其自由而随意的字体识别是一件具有挑战的课题,手写数字的多变性和书写的不确定性表明使用传统识别方法的困难.机器学习是处理大数据的重要技术,在手写体识别方面有许多成熟、有效的算法.特征的选择与提取是手写数字识别的首要工作,它对分类器的识别效率至关重要.
1 样本预处理
图像数字字符由于笔画粗细、字符大小不统一,图像背景中存在杂质、以及噪声等等与数字字符无关的信息,都会对图像数字字符识别影响极大,为了提高图像数字字符识别率,首先要对样本集进行数据预处理,去掉无用信息,提高真实有用数据的纯度,增强有效数据的可检测性,简化图像数字字符数据,从而达到提高字符识别的鲁棒性和可靠性.
预处理中简化图像数字字符数据可以采取将彩色图片转换为灰度图,将所有样本图片转换为二值图[6].图片灰度化方法有分量法、平均值法、最大值法、加权平均法等,各个灰度化方法的公式分别如下:
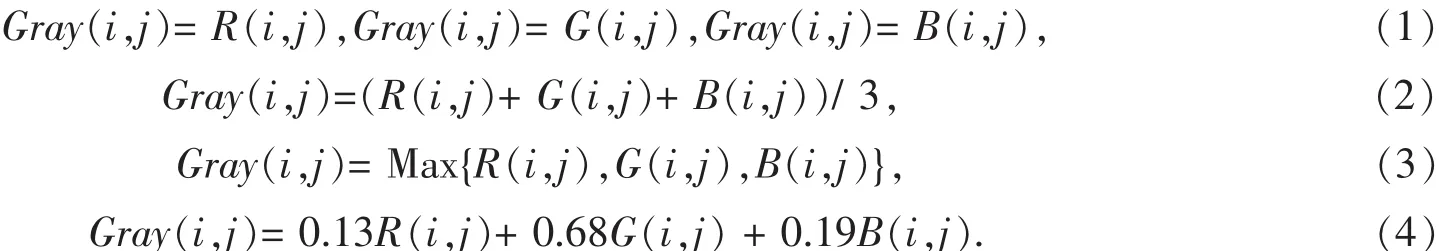
其中式(1)中 Gray(i,j)为转换后的灰度图像在(i,j)处的灰度值.R(i,j)、G(i,j)、B(i,j)分别是 RGB 彩色图像中3通道红、绿、蓝3原色在(i,j)处的值;式(4)根据人眼对不同颜色的敏感程度和其它指标及测试效果,调整3个分量权值,进行加权平均得到比较理想的灰度图.
图像清除噪声影响的方法通常有低通滤波法、平滑滤波法、中值滤波法、微分滤波法、邻域平均法、小波变换等等,通过这些方法可以达到清除或减小噪声的干扰影响;使用阈值分割法可清除图像杂质干扰识别.
图像尺寸调整有很多方法,如双线性内插法、双立方插值法(Bicubic interpolation)、最近邻插值法、像素关系重采样法等.双立方插值能得到最精确、效果最好的插补图形,是一种比双线性内插更为复杂的插值方法,通过此方法得到的图像边缘比双线性插值更加平滑,计算式为:

图像细化方法很多,较实用且使用最多的为Zhang提出的并行快速细化算法[2],见图1.设P1是一个像素点,在二值图中为1,表示图片中一个白点,P2~P9为其邻域点.邻域满足下列步骤一或步骤二中所有条件时,表明该点属于图片的边界点,可以删除,即置为0.

图1 像素点P1及邻域图

图2 细化算法效果
步骤一条件:
(1)2≤N(P1),其中 N(P1)是指 P1 点的非零邻点的个数;(2)A(P1)变换,A(P1)是 P1 邻域点的值按照P2~P9 的顺序由 1 变为 0 的次数;(3)P2×P4×P6;(4)P2×P6×P8.
步骤二条件的前两个条件同步骤一相同,条件(3)为,条件(4)为.重复以上两个步骤,按照图像像素粗细度决定迭代次数,达到细化效果.图2为数字5通过细化算法后的效果图.
2 样本特征的提取与选择
卷积神经网络(CNN)是仿造动物的视觉神经机制,具有深度结构的前馈神经网络,因具有共享权值、稀疏连接、降采样、局部感知域等特点,非常适用于图像处理,对图像的放缩、旋转、平移等处理适用性很强[9].增加多尺度卷积核的CNN提取图像多尺度特征信息,可以减小过拟合现象,进一步提高分类精度,又由权值共享,网络的训练难度可得到很大程度的降低,且不影响学习能力,这就能在保证分类精度的情况下保证系统的运行效率[10].
笔者样本特征的提取与选择使用多种不同尺度的卷积核即权值矩阵,得到若干组不同尺度的特征数据文件,将所有特征数据文件进行归一化处理.使用MATLAB提取训练集样本和测试集特征,多尺度卷积核神经网络结构见图3.
图3中输入的手写数字5为经过预处理后的图形,通过构建7×7、5×5和3×3三个尺度卷积核提取输入样本的多尺度特征信息,即卷积处理,使用16种不同权值分别进行特征映射,得到卷积层C1层中的3组特征图.卷积层C1经过BatchNormalization(批归一化BN)算法处理,可提高CNN拟合能力和收敛速度.
对融合后的14×14特征图经过5×5卷积后得到10×10个不同位置,即得到C3的10×10特征图,对C3按照感知域为2×2的降采样操作,可分割为5×5个小矩形,对每个包含四个像素的矩形求均值并分配一个权值,即得到池化层S4,池化后的图像是原图像的四分之一,达到降维目的,由C3中一个特征图对应一个权值,故S4中也应是48个降采样图.S4再经过5×5卷积后每一个特征图就变为一个点,C5就是由48个这样的点组合而成.最后通过归一化指数函数(SoftMax函数)处理后输出.
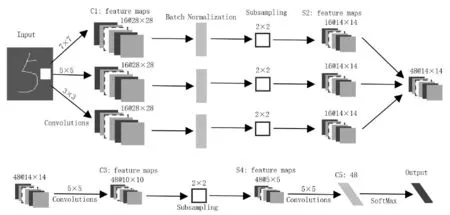
图3 多尺度卷积核神经网络结构图
3 测试环境的设计及实验结果
K近邻算法(KNN,K-nearest neighbor algorithm)是一种数据挖掘分类技术,一种无需训练时间、非参数、又高效简单的算法,一种适用处理分类和回归任务的方法,在模式识别的各个领域中应用较广[11].KNN基本原理是:在特征空间中寻找k个与测试样本距离最小的训练样本,这k个训练样本多数属于某个类,则该测试样本就分于此类中.即把这个测试样本用它最接近的k个邻居中数量优势的类来代表.
设计构建KNN分类器,使用Java语言编写KNN分类器程序,利用重载方法设计多个特征选择不同的方法,测试分类效果[12-14].并设计随机子特征选择算法、统计特征权重优先选择算法以及多个分类器集成方法测试分类效果,通过不断演化比较,将分类精度高的特征选择和特征提取算法作为最终结果.
实验测试数据集采用Mnist手写数字图像数据库,数据集包含测试数据集和训练数据集两部分,其中测试集手写数字图像样本10 000个,训练集手写数字图像样本60 000个,样本图像数字包括缩放、旋转、扭曲、剪裁等变化,测试数据种类多、数量大、较齐全能够真实地反应测试结果.
训练过程:每一个训练样本为一幅28×28像素的图片,按照各设计环节要求设定相关参数(详见前1、2节内容介绍)并编写处理程序;运行程序生成数字0到9训练样本;运行归一化处理程序生成数字0到9的归一化处理后的训练样本;把10类归一化处理后的训练样本数据文件合并为1个训练集文件allTr400.txt.
测试过程:同训练过程一样编写好相关环节的程序,即MATLAB和Java处理、识别程序;运行程序生成数字0到9测试样本;运行归一化处理程序生成数字0到9的归一化处理后的测试样本,数据文件为steSet400_j.txt,j=0、1…9;运行识别程序MainKNN0803.java文件,K值分别取1、3、5时的各类实验测试结果见图4.对10类样本在K值为1、3、5的识别实验测试情况统计,统计情况见表1.
从图4实验测试结果可知,该算法实验的运行处理时间为25~32 s间(运行环境为i3-7130U处理器笔记本电脑);从表1的实验测试情况统计表可知该算法实验的识别准确率都较高,最高可达99.74%,当选取最佳K值时最低识别准确率也有94.02%.与传统算法比较,运行处理时间有所缩短,且准确识别率提高了1~3个百分点.

图4 实验测试结果图
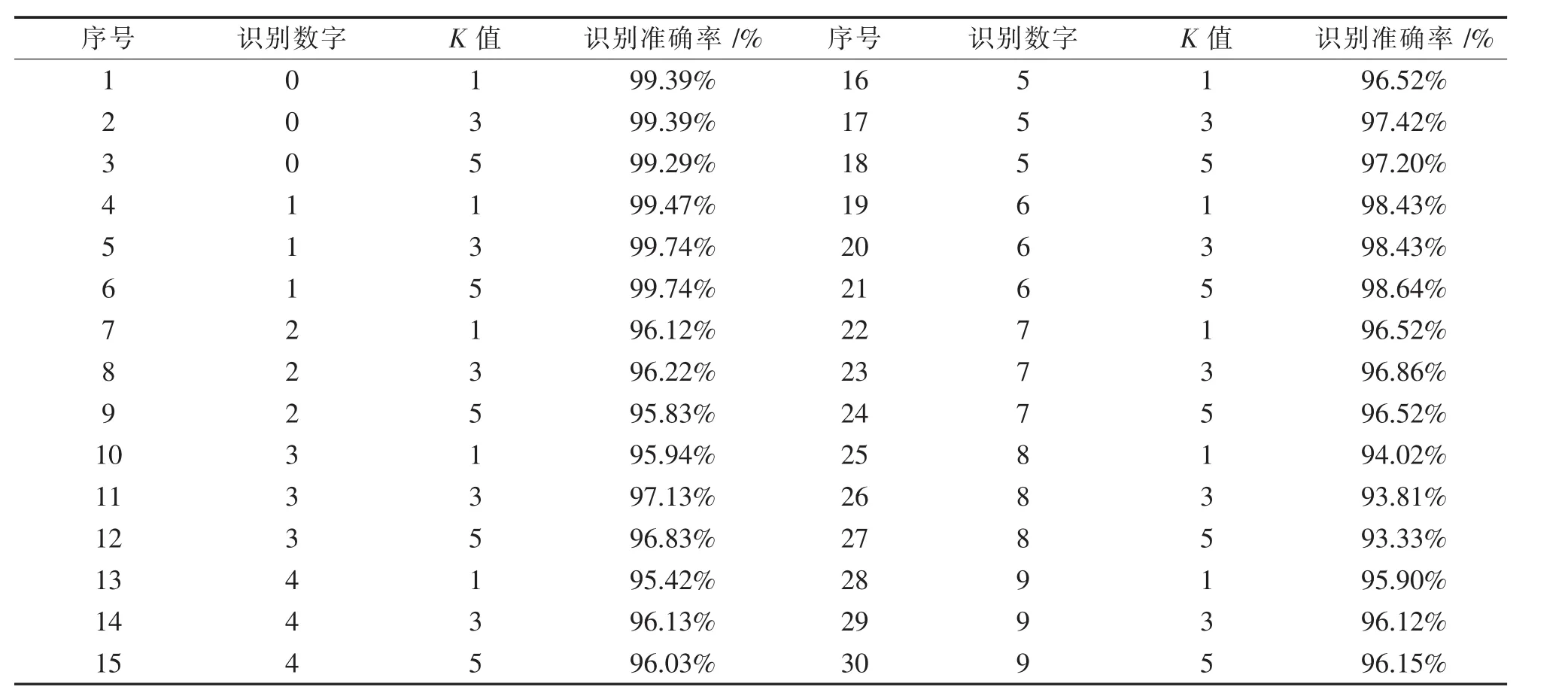
表1 实验测试情况
4 结语
研究在于为图像分类、识别提供一种通用的解决方案,同时为手写数字识别提供一种高效的、切实可行的并行计算模型,使用简单MATLAB、Java语言程序工具而无需复杂的计算环境,通过Mnist手写数字图像数据集进行实验,测试得到的数字图像识别效果较好.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
故事作文·低年级(2021年12期)2021-12-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
作文成功之路·小学版(2020年7期)2020-08-24
江苏通信(2018年4期)2018-12-04
电子制作(2018年18期)2018-11-14
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
科学与财富(2016年28期)2016-10-14
