
TransRD: 一种不对等特征的知识图谱嵌入表示模型
2019-11-18 08:04朱艳丽杨小平张志宇
中文信息学报 2019年11期
朱艳丽,杨小平,王 良,张志宇
(1. 中国人民大学 信息学院 北京 100872;2. 河南科技学院 信息工程学院,河南 新乡 453003)
0 引言
实际应用中,研究人员发现虽然现有知识图谱是由大量的事实三元组组成,但仍存在不完备性问题,进而引发对大规模知识图谱自动补全方面的大量研究[1-4]。本文旨在提供一种新的知识图谱表示方法,对具有不对等特征的知识图谱中的实体和关系进行建模,获得其更精确的表示,提高知识图谱补全性能。在研究中,我们发现现有知识图谱,尤其是领域知识图谱在语义、链接结构和关系两端头尾实体数量上存在很大差异[5-6],即知识图谱中的头尾实体具有不对等特征。现有的知识图谱表示方法,包括TransR[7],虽然有良好的知识表达能力,但对具有不对等特征的知识图谱中实体和关系建模仍存在以下两大缺陷。
缺陷一知识图谱中实体和关系建模时,没有考虑其在语义、局部链接结构和关系两端的实体数量三个方面存在的不对等特征,平等对待头尾实体并以同样的方式将它们嵌入到关系空间中。具体来说: ①头尾实体的语义不对等,大多数头尾实体来自不同的语义空间; ②头尾实体的局部链接结构不对等,同一关系两端的头尾实体的入度或出度可能不同,影响其所涵盖的语义及其在知识图谱中出现的次数; ③关系两端的头尾实体数量不对等,一些关系链接许多头(尾)实体和很少的尾(头)实体,如关系-syntax-ns#type,其每个头节点对应平均尾节点个数是1.4,而每个尾节点对应平均头节点的个数是1 642。
缺陷二每个关系单独配置一个投影矩阵,不同关系的嵌入是独自学习的,没有对关系之间的相关性进行建模,导致知识共享困难,泛化能力差。具体来说,知识图谱中不同的关系可连接到一个共同的实体,关系之间显然存在一定程度的相关性。逻辑相关或相似的关系由于彼此之间相关性强,关系之间存在共同信息[8]。但采用TransR建模方式,这些关系可能被投影在不同的空间,难以共享关系之间的共同信息。在训练过程中只有包含足够三元组关系才能学到较好的嵌入,而包含极少三元组的关系的投影矩阵只能得到极少次数的更新,难以学到较好的嵌入,导致泛化能力差[9]。
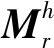
1 相关工作
近年来,研究人员已经提出许多知识图谱补全方法,概括起来可分为两大类[12]: 第一类是基于符号和逻辑的表示方法。采用这种表示方式,知识图谱是符号化的,并具有逻辑性,因此数值化的机器学习方法和技术均不能应用到知识图谱上;第二类是知识图谱嵌入表示方法。该方法在保留原始知识图谱特定属性的同时,将实体和关系映射到低维向量空间中,使得一大批高效的数值化计算和推理方法得以适用,在链接预测和关系抽取等多个任务中都显示出其有效性。与第一类方法相比,第二类方法更容易计算语义相关性,是目前进行知识图谱补全的主流方法,具有很好的泛化能力。鉴于上述优点,研究人员提出了若干知识图谱表示模型,包括平移距离模型和语义匹配模型两大类[13]。其中,平移距离模型采用基于距离的评分函数,典型代表有TransE[1]及其扩展模型、高斯嵌入模型KG2E[14]和结构嵌入模型SE[15]等。而语义匹配模型则使用基于相似度的评分函数,代表性工作有双线性模型RESCAL[2]及其扩展模型、语义匹配能量模型SME[16]和神经张量网络模型NTN[3]等。
本文主要考虑平移距离模型的知识图谱表示方法,利用正负例元组之间基于边际的损失函数将实体向量和关系向量关联起来,并优化该损失函数,当达到优化目标时,就可以学得知识图谱中每个实体的向量和关系的向量,从而更好地应用于大规模知识图谱补全中[17]。TransE是其中最具有代表性的方法,在取得较好的预测表现的同时,保持足够的简洁性和高效性。但由于忽略实体的语义在不同的关系下可能不一样,TransE在处理自反、一对多、多对一和多对多等复杂关系时存在局限性,不能良好地区分具有复杂关系的实体。为解决上述缺陷,TransR最先将实体嵌入到关系相关的空间中,将实体和关系放置在不同的空间中,然后在投影空间中对平移属性进行建模。典型的模型还有TransD[18]、STransE[10]和ITransF[9]等。
2 头尾实体不对等性分析
以实验所用的知识图谱WN18、FB15K和 MPBC_20为例,分析其在语义、局部链接结构和关系两端的实体数量三个方面存在的不对等特征。
2.1 头尾实体的语义不对等
知识图谱中的知识通常用三元组
2.2 头尾实体的局部知识结构不对等
知识图谱是有向图,头尾实体的局部知识结构不对等指的是关系两端节点的入度或出度不同。图1所示MPBC_20训练集中前10 000个三元组头尾节点的入度和出度的统计信息,其中图(a)和(b)分别显示的是头尾节点的入度和出度信息,椭圆形以内的点具有相同的入度(出度)值。只有当三元组在图(a)和(b)都落到椭圆区域内,才能称其头尾实体的局部知识结构对等。从图中可清楚地看到,具有不对等的特征的三元组在训练集中占有很大比例。因此,该知识图谱头尾实体的局部链接结构具有不对等特征,而这种特征影响实体所涵盖的语义及其在知识图谱中学习时出现的次数。

图1 MPBC_20训练集中前10000个三元组头尾节点的入度和出度的统计信息
2.3 关系两端的头尾实体数量不对等
以基准知识图谱FB15K和WN18为例,从统计角度分析知识图谱的关系两端的实体数量不对等。对于知识图谱的每一种关系,首先统计①每个头实体对应尾实体的平均数量(记为tph)和②每个尾实体对应头实体的平均数量(记为hpt)两方面信息。然后计算出这两方面数值的均值(mean)和标准偏差(standard deviation,STDEV),用于衡量知识图谱的不对等程度及其变化情况。其中,均值表示整个知识图谱中每个头(尾)节点平均有多少尾(头)节点相应,而标准偏差反映出关系两端节点的不对等映射程度的变化情况。直观上看,均值越大,知识图谱不对等程度越高,而标准偏差值越大,则知识图谱不对等程度变化范围越大。表1列出实验所用数据集上头(尾)节点平均对应尾(头)节点的相关统计信息。
表1中WN18数据集的tph 的均值为4.0,而hpt的均值为4.1,这说明WN18数据集从整体上关系两端的实体数量是不对等的。标准偏差值6.0和6.2则表明不对等程度在不同的关系中存在较大的差异。与WN18信息对比后,我们发现FB15K数据集中tph和hpt的值分别为7.8和16.5,高于WN18中的相应值,说明该数据集的关系两端的实体数量不对等程度较WN18高。另外,其hpt和tph的标准偏差值相当大,表明不对等程度在该数据集的不同关系中存在相当大的差异。而MPBC_20中尾实体对应的平均头实体数量是头实体对应的平均尾实体数量的39.5倍,表明MPBC_20数据集中关系两端的实体数量不对等程度非常高。其hpt标准偏差的值高达375.2,表明从尾部实体到头部实体的不对等程度在不同的关系中差异非常大。
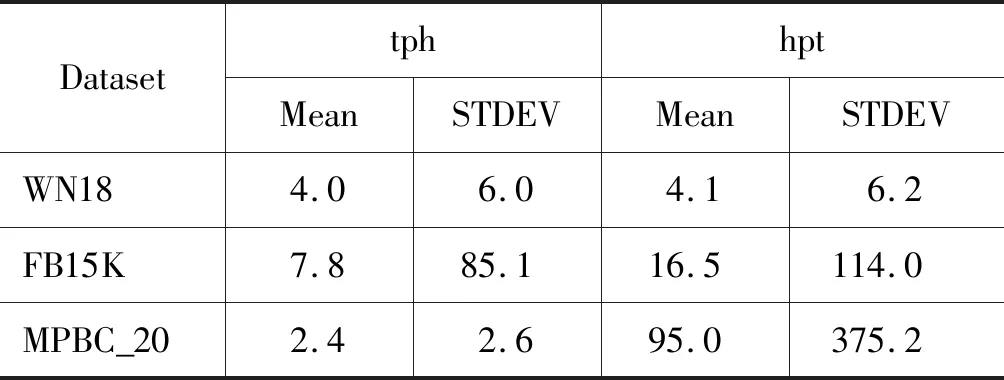
表1 数据集中关系两端节点数量的统计信息
上述统计分析结果表明,实验中用到的三个知识图谱均存在不同程度的不对等问题,尤其在领域知识图谱中该问题更为严重。具体地,以MPBC_20为例,头实体对应的尾实体的数量远远小于尾实体对应的头实体数量,这意味着在学习的过程中,尾实体这边的实体出现频繁,头实体这边的实体出现次数少,所以两者不能同等对待。我们应该在建模中分别对待它们,以便学习到合理的实体和关系嵌入。
3 TransRD知识表示方法
针对TransR模型的两大缺陷,TransRD模型分别采用头尾实体不对等投影和建模关系相关性方法来加以解决。
3.1 头尾实体不对等投影方法
TransRD模型将头尾实体与其相应的投影矩阵关联起来,根据不对等程度和变化情况自适应地动态调整参数和设置投影矩阵的秩。具体地,首先,对头尾实体采用不同的投影矩阵,使其可以来自不同的语义空间,从而避免现有模型中语义空间上的同质性假设,实现从语义上对头尾节点进行区分;其次,根据不对等特征采用ADADELTA算法自适应地实现学习,使得频繁实体具有较大的学习率,这样一来不会出现因为训练时间过长而过拟合现象。而不频繁实体则设置较小的学习率,使其有充分的学习时间,也不会出现欠拟合现象;最后,根据知识图谱中头尾实体的数量不对等程度确定相应投影矩阵的秩。例如,对于知识图谱MPBC_20,由于每个尾实体对应的头实体数量非常大,我们应该对头实体这端采用低秩投影矩阵。对于尾部实体这端可直接使用满秩的投影矩阵,因为相对头实体而言,尾实体的数量相当小。
3.2 建模关系相关性
TransR模型采用不对等投影方法后,由于每个关系单独配置一个投影矩阵,忽略其内在相关性,仍存在参数过多和知识共享困难问题,其他典型的关系投影方法TransD[18]和 STransE[10]也存在同样的问题。上述问题主要是由于忽略关系的内在相关性造成的,导致逻辑相关或相似的关系可能被投影在不同的空间,难以共享这些关系之间存在的共同信息,使得稀有关系在训练中只能得到极少次数的更新,泛化能力差。因此,我们的方法通过建模关系的内在相关性来改善上述问题,鼓励在同一组关系的投影矩阵中共享公共信息,减轻了数据稀疏问题。根据关系对之间的相关程度,对关系按语义进行分组,采用语义相似关系使用同一对投影矩阵的方式来提高知识表示的性能。
3.2.1 关系之间存在相关性
将TransE模型学习出的关系向量组成嵌入关系矩阵R∈Rd×Nr,其中,Nr是关系的数量,d是嵌入空间的维度。采用皮尔逊相关系数(PCC)来证明知识图谱中关系之间存在相关性。具体地,首先根据嵌入关系矩阵R来计算每个关系对的PCC值,得到一个对称矩阵,记为P,其任意元素Pij的值表示第i个关系和第j个关系构成的关系对的相关度,该矩阵的对角线的值通常为1;其次,统计出PCC值超过给定阈值的相关关系所占的百分比。扫描矩阵P所有列,对于每一列,如果该列除对角线元素以外的任一元素的值大于等于给定阈值,相关关系的数量加1;最后,我们得到如图2所示的结果。其中,PCC值如果在区间[0.2,0.4)表示弱相关,在[0.4,0.6)表示中度相关,而在[0.6,1.0]则表示强相关。从图中可看出,本文实验所用的三个数据集WN18、FB15K和MPBC_20中,至少有70%的关系强于弱相关,约50%的关系强于中度相关,还有约20%的关系彼此之间具有很强的相关性。以上结果充分证明这三个数据集中关系之间存在相关性。
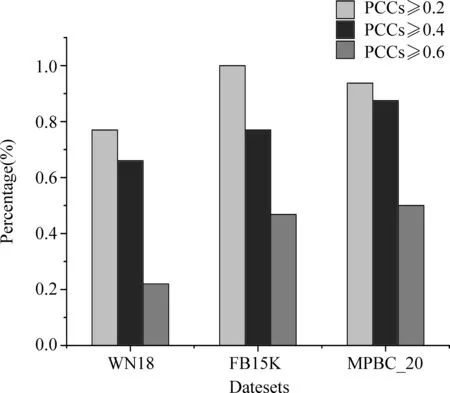
图2 数据集中强于弱相关、中度相关和强相关的相关关系所占比例
3.2.2 按相关性分组建模
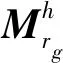
3.3 TransRD模型
3.3.1 模型
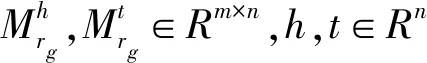
评分函数如式(3)所示。
fr(h,t)=-||hp+r-tp||L1/L2
(3)
其中r∈Rm,正确三元组的分数可能会更高,而损坏三元组的分数可能会更低。实验中,我们约束‖h‖2≤1,‖r‖2≤1,‖t‖2≤1,‖hp‖2≤1,‖tp‖2≤1。
3.3.2 训练目标
我们将下面的基于边际的评分函数定义为训练目标,如式(4)所示。
(4)
其中[x]+≜max(0,x),γ是边界参数,Δ是由正确三元组构成的训练集,而Δ′={(h′,r,t)|h′∈ε,(h′,r,t)∉Δ}∪{(h,r,t′)|t′∈ε,(h,r,t′)∉Δ} 是由损坏三元组构成的集合。采用TransH[20]中的采样策略替换头实体或尾实体。具体模型训练时,采用经典的随机梯度下降SGD(stochastic gradient descent)法来优化上述目标函数。
3.3.3 算法实现
为了加快收敛速度,避免过拟合,我们使用TransE模型训练出的实体向量和关系向量进行初始化。使用的转换矩阵是对称矩阵,并用单位矩阵进行初始化。SGD使用全局学习率更新所有参数,不考虑数据特征。但是,从前面的分析可以看出,不频繁的实体需要更长的学习时间,而频繁的实体需要更短的学习时间。因此,我们采用了一种称为ADADELTA自适应的梯度下降方法进行梯度更新。ADADELTA 使用 RMS ofE[g2]t和E[Δx2]t-1来更新参数,如式(5)所示。
(5)
在公式(5)中,分子RMS[Δx]t-1量值滞后于分母1个时间单位. 其中之前的平方梯度和参数更新如式(6)、式(7)所示。
其中,ε是常量,ρ为衰减常数。TransRD实施细节详见算法1。

算法1 Learning TransRD

13: if‖ep‖2>1,ep=hp,tp,hp′ort′pthen14: ep←ep/‖ep‖215: endif16: endfor17: for t=1:Tdo18: computegt19: E[g2]t←ρE[g2]t-1+(1-ρ)gt20: Δxt=-RMS[Δx]t-1RMS[g]tgt21: E[Δx2]t=ρE[Δx2]t-1+(1-ρ)Δx2t22: xt=xt-1+Δxt23: endfor24:endloop
4 实验与结果
4.1 数据集构建
为了评估链接预测的效果,我们首先使用TransR[7]使用的WN18(Wordnet)和FB15K(Freebase)数据集进行实验,并使用与TransR相同的方法分割训练集、验证集和测试集。还使用不对等特征显著的领域知识图谱 MPBC_20来验证所提方法的有效性。该数据集有175 624个实体,20个关系,以及811 785个三元组。我们按8∶1∶1的比例生成训练集、验证集和测试集,训练集有649 439个三元组,验证集有81 603个三元组,测试集有80 743个三元组。在MPBC_20中,我们发现有实体出现在验证集和测试集中,但没有出现在训练集中,这类实体称为空实体。在验证集和测试集中,分别有7 910(9.7%)和7 915(9.8%)个三元组包含上述实体。由于本文模型不能像NTN模型[3]那样从训练出的词向量中获得实体的向量表示,需去除验证集和测试集中包含空实体的三元组。三个数据集的信息如表2所示。
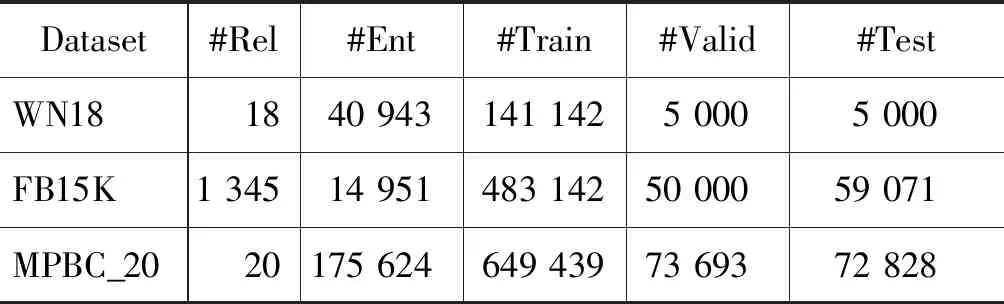
表2 实验所用数据集的统计信息
4.2 采样策略
为了减少产生错误三元组的机会,我们采用TransH[20]首先提出的方法替换头或尾实体生成损坏三元组。具体来说,在关系r的所有三元组中,我们首先得到两个统计量: ①每个头实体对应尾实体的平均数量tph; ②每个尾实体对应头实体的平均数量hpt。然后定义一个参数为p的伯努利分布,如式(8)所示。
(8)
给定关系r的一个黄金三元组(h,r,t),我们用概率1-p替换头实体来生成损坏三元组,用概率p替换尾实体来生成损坏三元组。
4.3 评价准则与实现
4.3.1 评价准则
与TransR[7]类似,采用黄金三元组的平均排序得分(记为Mean Rank)和黄金三元组排序不大于10的比例(记为Hits@10)作为评估准则。在本文中,我们报告“过滤”结果,即将“干扰”的损坏三元组从训练集、验证集和测试集中去除,然后得到正确实体的排名。我们报告每个模型的Mean Rank和Hits@10值。Mean Rank值越低或Hits@10值越高,准确性越高。
4.3.2 实施细节
在WN18和FB15K上,本文参考TransR[7]的实验结果。训练TransRD时,使用ADADELTA算法进行优化,选择边界值γ为{1,2,3,4,4.5,5,5.5,6,6.5,7,8},实体和关系向量的维度n和m为 {20,50,100},块大小B为{100,120,200,480,1 400,4 800},延迟率ρ为{0.8,0.85,0.90,0.95,0.99}和常量ε为{1E-2,1E-4,1E-6,1E-8}。用“unif.”表示传统的等概率替代头实体或者尾实体的方法,用 “bern.” 表示使用伯努利抽样策略的方法,即用不同的概率来代替头实体或者尾实体。
最优参数由验证集确定。采用等概率采样时,最优参数配置如下: 在WN18上,ρ=0.95,ε=1E-6,γ=6,m=n=100,B=100; 在FB15K上,ρ=0.90,ε=1E-4,γ=1,m=n=50,B=4 800; 在MPBC_20上,ρ=0.99,ε=1E-8,γ=6,m=n=100,B=200。采用伯努利采样时,最优参数配置如下: 在WN18上,ρ=0.85,ε=1E-8,γ=6.5,m=n=100,B=200; 在FB15K上,ρ=0.99,ε=1E-8,γ=1,m=n=100,B=480; 在MPBC_20上ρ=0.90,ε=1E-6,γ=5.5,m=n=100,B=100。对于这三个数据集,本实验将所有的训练三元组迭代2 000次。
4.4 链接预测
链接预测是对一个黄金三元组(h,r,t)缺失的h或t进行预测,我们将去掉头或尾实体,然后依次用集合中的所有实体替换本文测试集中的每个三元组。我们首先计算这些损坏三元组的得分,然后按降序排列它们,最终记录正确实体的排名。该任务强调的是正确实体的排名,而不是只找到最好的一个实体。
4.4.1 基于WN18和FB15K数据集的链接预测实验
在WN18和FB15K上的实验结果如表3所示,实验的最优值进行加粗以突出显示。从表3我们可以得出以下结论: ①在WN18上,TransRD模型相比于其他模型达到最好的性能,Mean Rank指标和Hits@10指标的效果远优于其他模型(包括TransR、STransE和ITransF),说明我们将头尾实体分开投影和建模关系的内在相关性相结合是成功的; ②在FB15K上,TransRD模型性能与STransE的结果接近,但在Hits@10指标上低于ITransF。这可能是由于TransRD在对关系按语义进行分组时所使用的初始化向量是从TransE模型得到的向量,而数据集FB15K上关系类型有1 365种,某些关系类型的三元组数量过少,不能有效识别相似关系,难以确定合适关系分组数量; ③在WN18和FB15K上,与TransR相比,TransRD模型将Mean Rank值最多降低了31,而hit @10的准确率至少提高了3.3%,该结果证明TransRD建模时考虑知识图谱的不对等特征能减少其在链接预测中的负面影响。同时,与STransE比较,TransRD同样取得一定的进步,这表明建模关系的内在相关性方法的有效性; ④与等概率采样相比,伯努利采样可以减少错误三元组的产生。
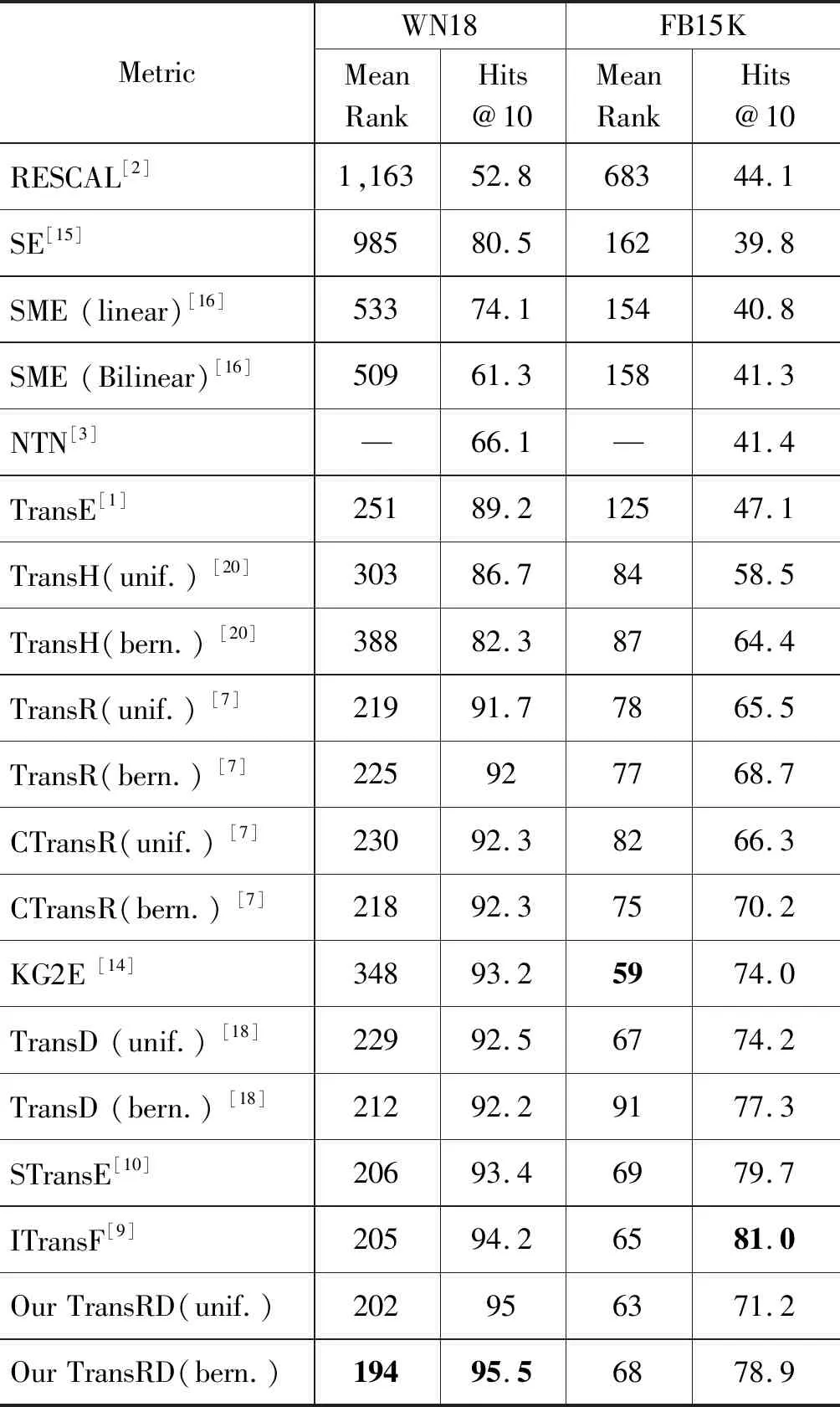
表3 WN18和 FB15K 数据集上链接预测计算结果
为了进一步验证上面的结论,深入挖掘分析FB15K上不同关系不同映射类型的相应结果,具体数值如表4所示。从表4可以看出,对于1-to-N和N-to-1关系类别,TransRD的表现优于TransR/ CTransR等模型。这表明分别映射头尾实体有助于建模复杂的关系。
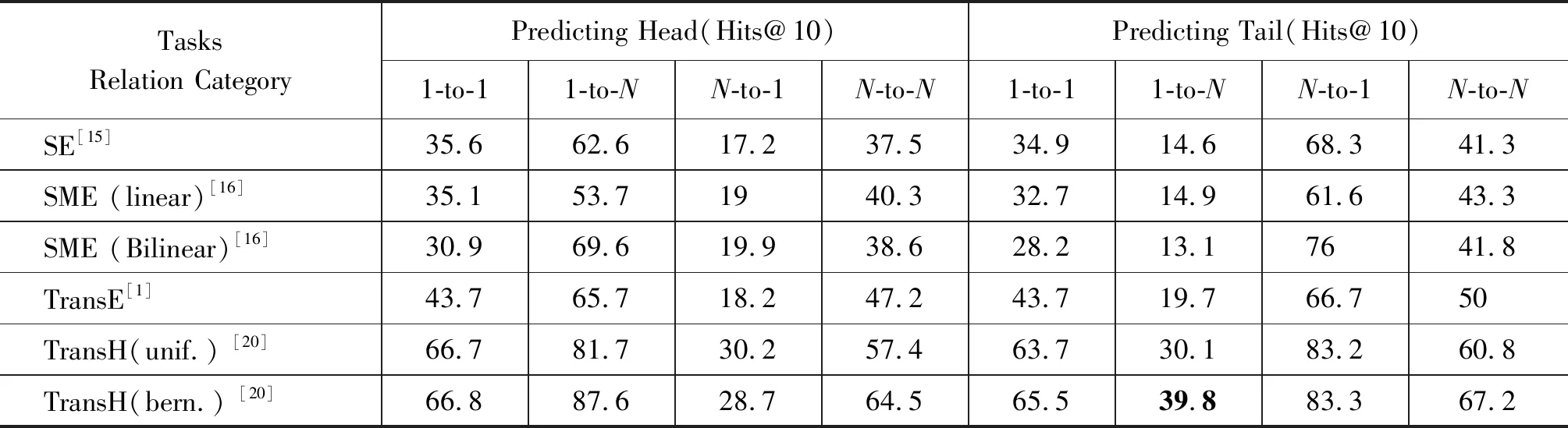
表4 FB15K 数据集基于关系类型的计算结果
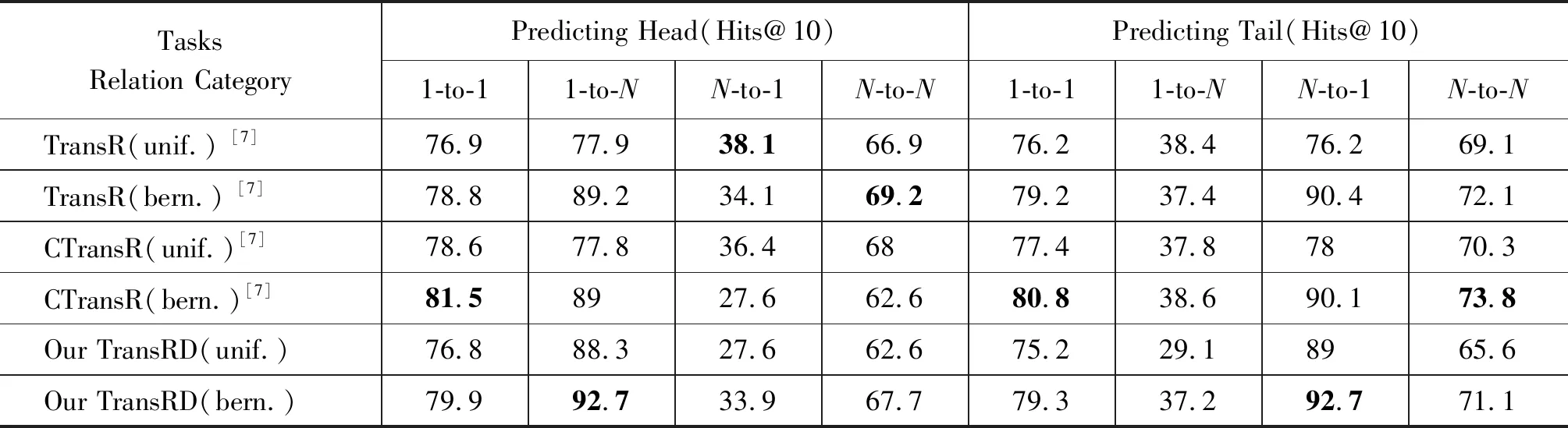
续表
4.4.2 基于MPBC_20数据集的链接预测实验
TransRD模型与基准模型TransE、TransH和TransR在MPBC_20上的链接预测实验结果如图3所示。从图3中我们可以看出: ①在Hits@10指标上,TransRD模型显著优于其他基准模型,这个结果表明TransRD模型能获得具有不对等特征的知识图谱的实体和关系更精确表示,而TransE、TransH和TransR在该任务中取得较为接近的结果; ②TransRD的Mean Rank值低于TransR,这说明采用分别映射头尾实体并语义相似关系使用相同的转换矩阵对方法的有效性。
表5给出在MPBC_20上不同关系不同映射类型的相应结果。从表5中可以看出,在N-to-1和N-to-N两种关系类型上,TransRD的性能优于TransR等模型。这也说明TransRD对实体和关系的嵌入更加合理。而TransR和TransRD都不能很好地处理1-to-N关系。这可能由于在该数据集中此类关系的三元组仅占5%,使得模型在训练过程中只能接触非常少的三元组,导致性能不佳。
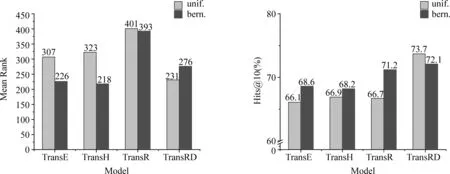
图3 MPBC_20数据集上链接预测对比结果

TasksRelation CategoryPredicting Head(Hits@10)Predicting Tail(Hits@10)1-to-11-to-NN-to-1N-to-N1-to-11-to-NN-to-1N-to-NTransE(unif.) [1]62.621.761.747.463.133.575.155.8TransE(bern.) [1]63.224.737.948.863.432.581.154.5TransH(unif.) [20]58.724.362.447.959.139.376.456.1TransH(bern.)[20]60.622.342.648.761.336.880.953.8TransR(unif.) [7]59.223.248.648.360.337.271.561.3TransR(bern.) [7]61.224.955.350.562.341.081.360.3Our TransRD(unif.)62.822.358.449.363.237.778.562.4Our TransRD(bern.)61.121.430.451.162.038.582.159.9
4.5 不对等性度量
通过前面的分析,我们发现知识图谱中的三元组中的头尾实体在语义、局部链接结构和数量上具有不对等特征。为了让这种不对等特征不影响模型的准确性,使得模型更容易训练,我们对TransR模型进行改进。头尾实体采用不同的投影矩阵,并自适应地调整参数,所得到的模型称为STransR。为了验证该方法更适应具有不对等特征的知识图谱嵌入表示,将基准模型TransR和改进的模型STransR在三个数据集上训练,采用实体预测作为实验载体,度量指标使用Hits@10和Mean Rank,其结果如图4和图5所示。
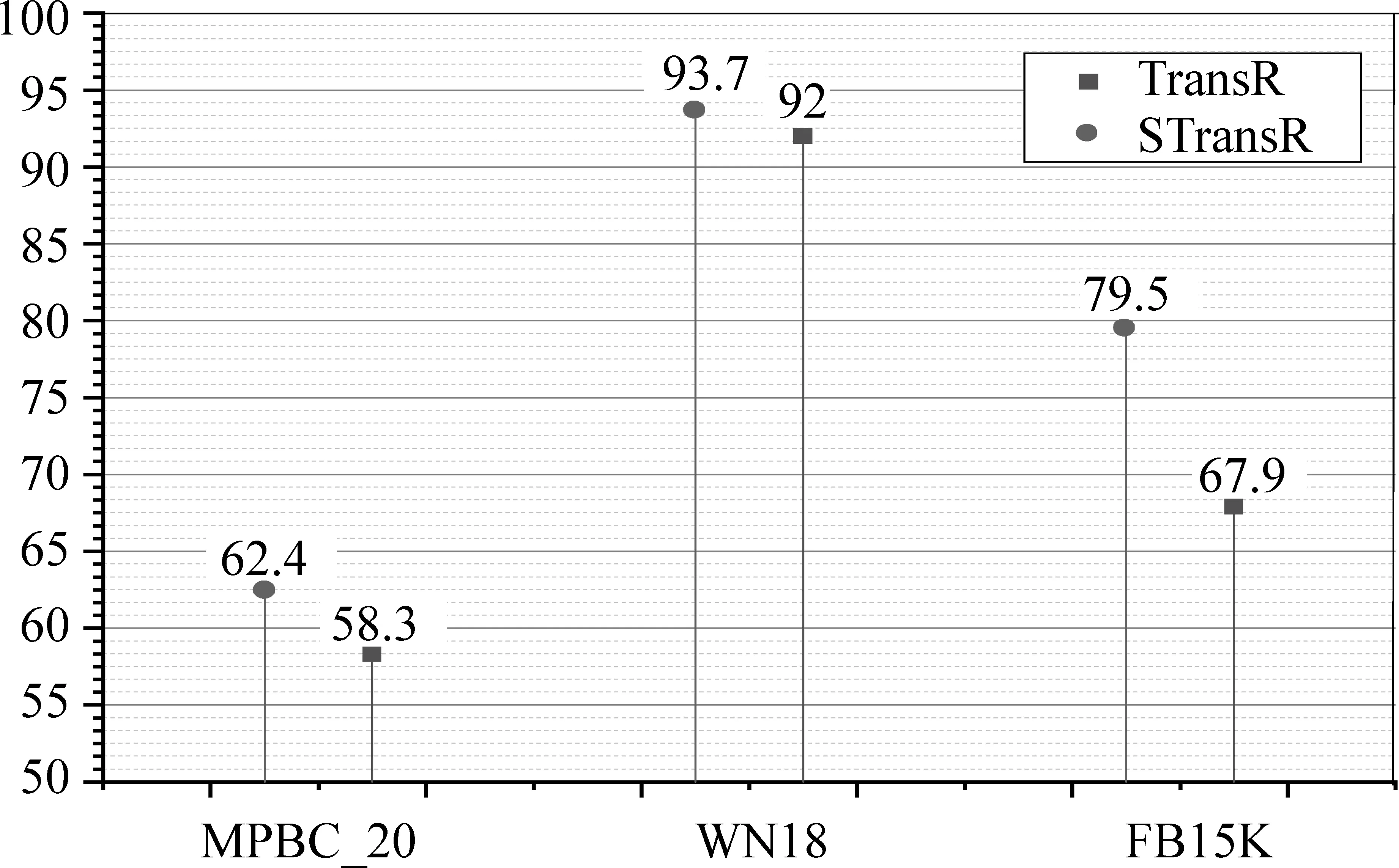
图4 头尾实体采用不同的投影矩阵和自适应算法的实体预测Hits@10值(%)

图5 头尾实体采用不同的投影矩阵和自适应算法的实体预测Mean Rank值
从图4我们可以看出,在Hits@10指标上,模型中头尾实体采用不同的投影矩阵和自适应算法训练最少比使用相同的投影矩阵和SGD提升1.7%。在最好的数据集FB15K上可以提高11.6%,不对等程度显著的数据集的表示效果提升得更为明显。这也验证了该方法的有效性。
同样,图5的Mean Rank值也充分说明了这一点。每个数据集在使用头尾实体采用不同的投影矩阵和自适应算法都会比采用相同投影矩阵和SGD有一定改善。不对等程度越高的知识图谱降低效果越明显,其中在数据集FB15K上降低了38.5。这主要是由于TransR采用矩阵映射,参数较多,再加上数据的不对等程度较高,且变化范围较大,而ADADELTA算法可以随着时间的推移动态调整参数,使得小梯度具有较大的学习率,不频繁实体就有了充分的学习时间。
5 结论
针对TransR模型在对具有不对等特征的知识图谱中实体和关系建模时存在两大缺陷: 一是假定头尾实体来自同一语义空间,忽略其在链接结构和数量上的不对等;二是每个关系单独配置一个投影矩阵,忽略其内在联系,导致知识共享困难,存在泛化能力差的问题。本文主要提出一种改进的不对等知识图表示方法TransRD来解决上述两个缺陷。TransRD通过对头尾实体采用不对等投影矩阵的方法,避免语义空间的同质性假设,表征出头尾实体不对等特征,并通过建模关系的内在相关性来改善上述问题;将TransE学习到的嵌入关系矩阵进行PCC相关性分析,根据相关性分析的结果,将关系按语义相似性进行分组。采用每组关系使用同一对投影矩阵的方式来共享公共信息,学习出实体和关系更好的嵌入,解决泛化能力差的问题。我们在WN8、FB15K和MPBC_20数据集上对TransRD进行链接预测实验,实验结果表明,采取头尾不对称投影是解决问题的关键。
在未来工作中,我们计划扩展TransRD,以类似于PTransW[21]的方式利用知识图谱中的关系路径信息来进一步提高模型表示能力,并加入关系类型的语义信息进行改进。此外,我们还将探讨如何对实体-属性关系单独建模,以提高模型处理一对多关系的能力,此类关系大多由真实知识图谱中的属性组成。
猜你喜欢
军事文摘(2022年8期)2022-05-25
山西大学学报(自然科学版)(2021年1期)2021-04-21
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
毛纺科技(2020年2期)2020-03-16
五邑大学学报(自然科学版)(2019年3期)2019-09-06
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
计算机技术与发展(2018年12期)2018-12-20
作文与考试·初中版(2018年6期)2018-03-03
婚姻与家庭·性情读本(2017年1期)2017-02-16
