
一种基于压缩矩阵的高效关联规则挖掘算法∗
2019-11-29 05:14潘俊辉王浩畅
计算机与数字工程 2019年11期
潘俊辉 张 强 王 辉 王浩畅
(东北石油大学 大庆 163318)
1 引言
数据挖掘(Data Mining)是指从大量的数据中挖掘出有价值的、潜在有用的、最终可理解的模式或规律等知识的非平凡过程[1],它是一门涉及范围十分广泛的学科技术,通过它能过解决许多生活中的问题[2]。而关联规则是数据挖掘中的一个重要领域,指的是在大量数据中挖掘出数据项之间潜在的有趣的关联,目前关联规则已经被广泛的应用在众多领域,如智能推荐、搜索引擎等。关联规则最早是通过对市场的购物篮问题进行分析由Agrawal在1993 年首先提出来[3~4],之后诸多的学者对关联规则挖掘进行了大量的研究。实现关联规则挖掘的经典算法称为Apriori算法,该算法主要通过对事务数据库中的事务进行不断地扫描来发现所有的频繁项集,该算法的优点是通俗易懂,操作实现简单;缺点是在处理大项集时,算法的计算量非常大,导致算法效率明显下降[5]。因此,如何降低算法的效率是Apriori算法目前面临的最大的问题,也是当前关联规则挖掘算法研究的热点。
Park 等[6]学者提出了基于hash 的改进方法,该方法通过简化2-项集的产生过程进行改进;Savaser 等[7]学者提出了基于分片的并行改进方法,该方法通过分片提高算法的并行效果;基于采样的方法是通过从完整的事务数据库选择它的子集作为样本进行关联规则的挖掘,然后将子集的结果作为完整数据库的结果[8];基于矩阵的Apriori算法则通过把事务数据库表示成布尔矩阵的形式完成对关联规则的挖掘,它也是Apriori 的一种改进,但这种方法在实现时易产生过多无用元素,浪费较多的内存空间。本文针对基于矩阵的Apriori 算法所存在的不足,在此基础上提出了一种基于压缩矩阵的高效关联规则挖掘方法CMEAR 算法(Compressed Matrix Efficient Association Rules Algorithm)。该方法通过对矩阵的压缩,改进矩阵的存储方式及对项目集进行排序等多种方式实现关联规则的挖掘,改进后的方法不但节省了存储空间,同时也使算法的效率得以提高,最后通过实验将改进后的方法与传统Apriori 算法以及基于矩阵的Apriori 算法进行了对比分析,实验结果表明基于压缩矩阵的高效关联规则挖掘方法在算法的性能上更优。
2 关联规则及基于矩阵的Apriori算法
2.1 关联规则
设 I={i1,i2,…,im} 是 一 个 项 的 集 合,记D={t1,t2,…,tn}为事务T 的集合,对应每一个事务有唯一的标识,记作TID,这里事务T 是项的集合,并且T ⊆I 。设X 是一个I 中项的集合,如果X ⊆T ,那么称事务T 包含X 。
关联规则是指X ⇒Y 的这种蕴涵式,其中X ⊂I,Y ⊂I ,并且X ∩Y=φ。关联规则中有两个重要的概念,分别是支持度和置信度,而关联规则最终的目的就是从事务数据库中找出支持度和置信度都大于用户设定的最小支持度和最小置信度的关联规则[3],其中支持度是指事务集中包含X 和Y的事务数与所有事务数之比,即Supp(X ⇒Y)=P(X ∪Y),而置信度是指包含X 和Y 的事务数与包含X 的交易数之比,即Conf(X ⇒Y)=P(X|Y)。
2.2 基于矩阵的Apriori算法
该算法是对传统算法Apriori的一种改进,主要是通过使用矩阵将其融入到Apriori算法中,即把要处理的事务数据库以矩阵的形式进行表示。下面分步骤简要给出基于矩阵的Apriori 算法的实现过程。
Step 1:首先把事务数据库转换成布尔矩阵,布尔矩阵中的行表示事务数据库中的每一项,而列表示事务数据库中每一条事务[9];计算布尔矩阵中每一行1 的个数,该数量即是每一项的支持度。如果该值不小于设定的最小支持度,就构成了频繁1-项集;
Step 2:将比较得到的k-项集(k ≥1)进行连接操作,从而产生候选的k+1项集,然后对候选k+1项集进行剪枝操作[10];
Step 3:扫描并计算布尔矩阵中行向量的内积以得到对应项的支持度大小[9],如果设定的最小支持度小于计算得到的支持度,就得到了k-项集。
由于是通过将事务数据库转换成布尔矩阵之后进行扫描,因此基于矩阵的Apriori算法会减少扫描的次数,另外在挖掘过程中是通过扫描行并做与运算进行计算的,相对传统的Apriori算法而言也会提高计算速度。但该算法在挖掘过程中也存在一些不足,主要是在连接时会产生过多的候选集,导致占用空间内存较多,使得该算法在生成候选集这一方面并没有比Apriori算法有明显的提高,反而易产生较多的候选集。
3 基于压缩矩阵的高效关联规则挖掘算法CMEAR
针对基于矩阵的Apriori算法所存在的缺点,本文在此基础上进行了一定的改进,提出了一种基于压缩矩阵的高效关联规则挖掘算法CMEAR(Compressed Matrix Efficient Association Rules Algorithm),该算法主要通过改进矩阵的存储方式,对矩阵进行压缩以及对项目集进行排序三个方面进行了改进。下面对具体的改进过程分别进行详细的介绍,最后给出CMEAR算法的具体实现流程。
3.1 改进矩阵的存储方式
针对基于矩阵的Apriori 算法易在连接时产生过多的候选集,导致占用空间内存较多的不足,可以对矩阵的存储方式进行改进。实现的具体方法为:在算法实现过程中增加一个数组A,让它来存储布尔矩阵中每列中1 的数量。之所以加入该数组的原因是因为在获得事务长度时可以不用再扫描整个布尔矩阵,通过该数组A 就可以取出事务的长度,从而可以减少扫描的时间,加快对矩阵的压缩,同时节省了空间。
3.2 矩阵的压缩
对矩阵进行压缩主要是为了改进基于矩阵的Apriori算法在连接时所产生的无用事务,矩阵的压缩包括行压缩和列压缩两个方面。对于矩阵行的压缩,首先扫描布尔矩阵,然后通过文献[11~12]给出的定理和推论,将一个子集不能和它相邻的项集连接就可以删除这个项集所对应的行向量,修改新增数组A,最后剩下的行向量可按照顺序组成新的矩阵,从而实现矩阵行的压缩。对于矩阵列的压缩要在矩阵的行压缩之后进行,当对矩阵的行压缩后,再对数组A 进行一次扫描,然后根据文献[13~14]的定理和推论,将矩阵中对应值不大于1 的列向量进行删除,进一步实现矩阵的压缩,从而得到一个变得更小的新的矩阵。
3.3 项目集排序
基于矩阵的Apriori 算法在进行连接时易产生较多的候选集,因此为了减少它的数量,改进了项目集的排序方式。在改进的过程中根据文献[15]中所提出的推论实现对矩阵的排序,具体实现方法为:先找到所有的频繁1 项集,然后把矩阵中行向量不是频繁集的删除掉,然后对矩阵中频繁1 项集的行向量对应的支持度大小进行增序排列,排列之后会得到一个新的矩阵。随着算法迭代的逐步进行,每一步都会对项目集进行排序,那么算法执行的时间也会逐渐的减少[16]。
3.4 算法实现具体步骤
对基于矩阵的Apriori 算法进行了如上述的几点改进之后,下面就来介绍一下基于压缩矩阵的高效关联规则挖掘算法CMEAR 的具体实现过程,图1给出了该算法的流程图。
Step 1:设置最小支持度minsup,令k=1。初始化数组A,该数组用于存储布尔矩阵中每列1 的数量。
Step 2:将要处理的事务数据库D 转换为与其对应的布尔矩阵M。
Step 3:扫描布尔矩阵M,计算出矩阵中每个行向量的支持度大小,即每行1 的个数。比较每个行向量的支持度与最小支持度的大小关系,然后删除小于最小支持度minsup 的那些行向量,而将大于minsup 的行向量所对应的频繁项则组合得到频繁1 项集L1,同时根据L1中各项支持度的大小进行排序得到一个新的初始矩阵M1。
Step 4:将矩阵M1的行行之间按照顺序分别进行向量的内积运算,运算之后将计算结果不小于最小支持度minsup 的那些行向量组成频繁2 项集L2,同时又得到一个新矩阵M2。同时对那些不小于最小支持度的行向量按位累加到数组A中,令k=2。
当k 的值大于等于2 时将按照如下的Step 5、Step 6、Step 7循环进行操作。
Step 5:扫描矩阵Mk,删除Lk中不能和其相邻的项集进行连接操作的那些行向量,然后将数组A 的值进行修改,最后对删除之后保留下的那些行向量顺序排列并组合得到一个新矩阵Mk。
Step 6:扫描数组A,删除数组A 中所有其值小于1 的列向量,然后将保留下的列向量顺序排列得到一个新的矩阵Mk。
Step 7:清空数组A。然后将Mk中的可以相互连接的那些项集分别进行内积运算,不小于minsup的行向量组成频繁k+1项集Lk+1,并得到新矩阵Mk+1,同时对那些不小于minsup 的行向量按位累加到数组A 中。接着判断得到的新矩阵Mk+1的行数和k+2之间的大小关系,如果不小于k+2,那么将k值加1,继续执行循环,否则跳出循环,算法自动结束。
4 实验及结果分析
本文对关联规则的传统算法Apriori、基于矩阵的Apriori 算法和基于压缩矩阵的高效关联规则挖掘算法CMEAR进行了实验和实验结果的对比分析。实验中采用两组数据进行对比,第一组采用不同的支持度进行分析,第二组则采用具有不同条数的事务数据库。表1 和表2 分别给出了对比分析结果。其中支持度的单位为百分比(%),事务数据库的单位为条,运行时间以秒(s)为单位。
由表1可见,无论哪一种算法,随着支持度的增加,运行时间都在逐渐的减少,但从表中可以明显地看出CMEAR算法所用时间远远小于另外两种算法,特别优于传统的Apriori 算法,并且支持度越小,算法在时间上的差别越明显。
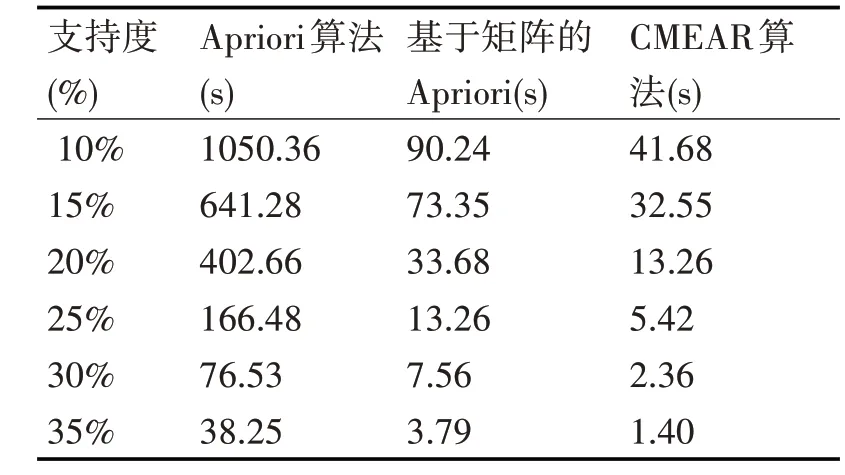
表1 同一事务数据库设置不同支持度的实验对比分析结果
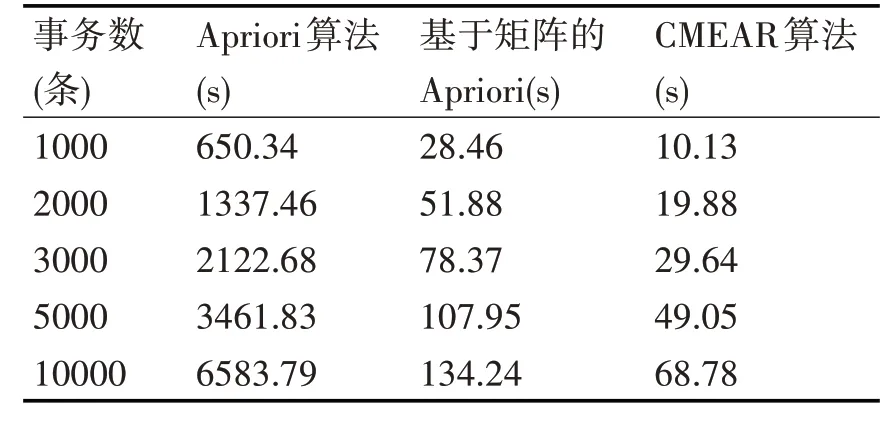
表2 不同条数的事务数据库实验对比分析结果
由表2 可见,对于不同的事务条数,CMEAR 算法在运行时间上同样远远小于另外两种算法,而且随着事务条数的增加,虽然CMEAR 算法运行时间也在增加,但其增加幅度较另外两种算法,特别是传统的Apriori算法而言更加趋于平缓。
5 结语
针对关联规则挖掘的改进算法基于矩阵的Apriori算法,文中通过分析给出了该方法的不足之处,在该算法的基础上提出了一种基于压缩矩阵的高效关联规则挖掘方法CMEAR,介绍了该方法的具体改进的措施和实现过程,最后通过实验对三种方法的效率进行了对比分析,实验结果均表明CMEAR算法在时间性能上更优。
猜你喜欢
少儿画王(7-10)(2022年6期)2022-07-18
电脑报(2022年13期)2022-04-12
电脑报(2020年24期)2020-07-15
启迪与智慧·下旬刊(2019年4期)2019-09-10
电脑爱好者(2017年22期)2017-12-04
意林·少年版(2016年17期)2016-10-21
初中生之友·中旬刊(2015年4期)2015-06-10
