
一种冲突证据合成的汽车故障树诊断方法
2019-11-30 03:47刘冰清龙昭灯苟荣非
汽车电器 2019年11期
刘冰清,甘 霖,王 强,龙昭灯,苟荣非
(重庆长安汽车股份有限公司 长安汽车工程研究院,重庆 401120)
1 引言
为了能快速发现汽车运行过程中的电子控制系统故障,当今汽车电子控制系统都设计了车载故障诊断系统,该系统通过传感器、执行器配合软件程序对车辆运行状态进行监控。当自诊断系统发现某个传感器、控制开关或执行器发生故障时,电控单元会将监测到的故障内容以故障码的形式存储到随机存储器中,利用专用的解码仪可将故障代码读出。这些故障证据能够为汽车检测与维修提供重要依据[1]。
由于汽车的各电控系统之间通过网络进行互联,汽车网络节点的原发故障会存在多条潜在的传播途径,使故障通过网络传递到其它节点上;同时网络节点功能单元很多,各单元之间相互依存和相互影响,致使故障原因和故障现象的对应关系难以准确判断[2]。这种电控节点之间的相关性,以及检测设备的局限性和知识表达的不精确,导致出现的故障码具有较强的不确定性,通过故障码进行故障诊断的过程实际是不确定性求最优解的过程。现阶段通常采用一种“部分穷举”的方式来确定故障,随着汽车行业的发展,电控原件的增加带来的海量“大数据”导致穷举法难以实现,而且采取清除历史故障码仅保留持续故障码将丢失大量的有用信息。为有效减少故障排查的工作量,保持诊断结果的置信度和准确率,应采用有效的信息融合方法对数据进行处理。现有诊断数据融合方法主要有基于经典神经网络的信息融合方法与基于贝叶斯网络的信息融合方法[3-4],基于经典神经网络的信息融合方法能够在建立网络系统精确模型的情况下,得到令人满意的诊断结果,但是对于关键信息缺失、样本量小时,诊断精度与准确度将会降低。
故障码的储存机制是将所有发生过的故障都记录下来,对于汽车行驶过程中受到外界信号干扰或者汽车的振动导致某信号暂时性丢失,电控系统依然会将这样的故障代码储存下来,这样偶发性的故障代码在进行数据融合时会使融合结果与真实情况出现差异,最终导致诊断结果错误。针对上述问题,本文提出一种针对汽车故障码冲突数据的融合方法,首先将源故障频度归一化作为传递权重,并与基本信任分配函数相互结合;然后提出证据之间距离的概念,并利用其对多故障证据进行聚类,最后将聚类结果进行D-S合成规则融合,得出最终诊断结果。
2 基于故障树的故障诊断方法
故障树分析 (FTA)是由上往下的演绎式失效分析法,利用布林逻辑组合低阶事件,分析系统中不希望出现的状态。设故障树 (FT)中有n个底事件x1,x2…xn,部分底事件的集合记为C∈{xi…xj},当集合中底事件发生,顶事件必然发生,则称C为故障树的割集。若C为割集,且去掉其中一个底事件后C不为割集,则称C为最小割集。故障树分析法的主要目的在于找出导致顶事件发生的所有可能的故障模式,即寻找故障树的全部最小割集[5]。
基于故障树诊断的故障源处在树的最底层,故障传播方向为自下而上即从底事件→中间事件→顶事件。故障源传递时由权值ω标识下层事件到上层事件的重要度占比,由于故障树分析 (FTA)是与潜在失效模式与后果分析 (FMEA)相结合进行建立,在FMEA中下层因子到上层事件采用风险顺序数 (RPN)对其进行潜在失效风险评估,而风险顺序数包含了严重度 (S),频度 (O),探测度 (D)三方面信息,主要在设计阶段发现潜在失效模式[6]。而故障树分析主要用于发现底层事件发生的概率,而频度 (O)更能反映故障发生的概率,因此本文推荐使用频度 (O)计算故障源,传递时权值ω能够更为真实地反映实际情况。频度 (O)为[0,10]的取值,因此在一个完备故障树建立后需对其进行归一化处理。汽车冷却风扇故障树见图1。
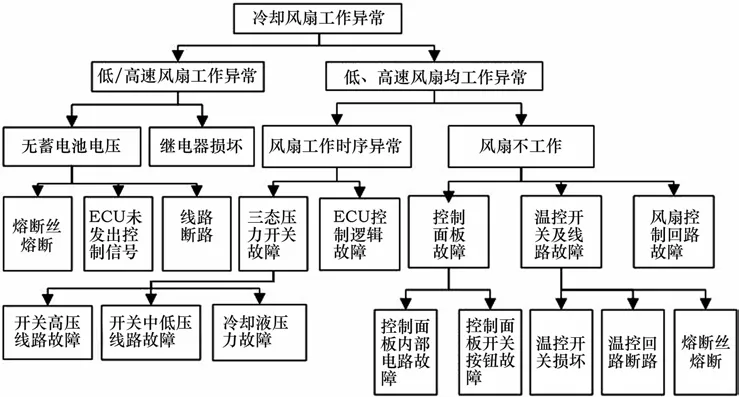
图1 汽车冷却风扇故障树
3 基于贝叶斯网络信息融合的故障诊断

式中m(A)称为事件A的基本信任分配函数,表征证据对A的支持程度。
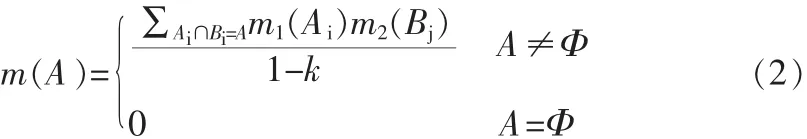
针对于汽车某系统的故障树,在建立FMEA过程中,要求故障因子包含所有可能出现的情况,因此其底事件即是一个完备的集合,底层事件与故障证据之间可采用集值映射表征其关系,如图2。其割集作为故障证据E指向完备集合的幂集,而故障源传递时权值ω即为该割集的信任分配函数,即ω=m(C)。
在汽车发生故障时,多个故障证据被采集,可采用D-S合成规则对证据进行合成得到权重最大的割集,从而对故障进行判定。
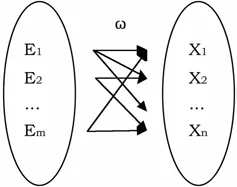
图2 证据与故障的映射关系
4 冲突故障融合诊断方法
由于汽车作为一个多传感器系统,采集到的故障证据存在偶发性和不确定性,因此众多故障诊断证据中会出现冲突性证据,如采用D-S证据理论对冲突证据进行融合,融合结果将偏离真实情况,例如:当出现4组证据E1、E2、E3、E4,对割集A、B、C信任分配函数值见表1。

表1 信任分配函数值
采用D-S证据理论合成可得出m(A)=m(C)=0,m(B)=0.1,根据权值判断原则,认为B为最终判断结果,其对应的底事件为故障发生的原因。尽管大多数证据证明A为真因,但由于某个证据否定了A,最终合成结果也否定了A。然而结合案例的事件情况,A事件为本次故障的真因,证据E2为偶然事件。
分析其原因,是由于D-S合成规则中,k是反映证据之间冲突程度的系数,当出现高冲突的证据,进行正则化处理将会导致与直觉相悖的结果,纵然如此许多学者认为D-S合成规则本身没有错,在高度冲突时应该首先对冲突证据进行预处理,然后再使用D-S合成规则。Murphy提出了一种修改模型而不变D-S合成规则的方法[7],首先将证据的基本概率指派进行平均,之后再用D-S合成规则合成n-1次。在Murphy的基础上,Jousselme等人提出了证据间距离函数[8],对于其证据间相似度和支持度他并没有给出具体算法。王肖霞等提出了一种基于证据间相似系数的冲突证据合成方法[9],利用证据之间的距离作为证据的相似度,然后求出各证据被其它证据所支持的程度,对支持度归一化后可得到各证据的可信度,并将可信度作为证据的权重,对证据加权平均后再利用D-S合成规则。该方法有效地处理冲突证据的合成,而且收敛速度较快,对于单个故障发生时确定故障原因比较准确,但对于汽车诊断,多个故障同时发生的情况时常出现,各故障对应的证据相互冲突,该算法最终合成结果无法有效指向任一故障。因此,提出了一种多证据聚类的冲突证据处理算法。
证据之间的距离是用来衡量证据之间相互冲突程度的函数,假定识别框架下的两个证据E1和E2,其相应的基本信任分配函数为m1和m2,焦元分别为Ai和Bj,则证据E1和E2间的距离可以表示为:
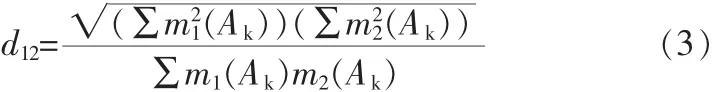
式中Ak=Ai∪Bj,证据之间的距离用来描述两证据之间的冲突程度,其值越大则两证据之间的冲突程度越高。在计算出所有证据之间距离后,并计算所有距离的均值;然后将证据1作为第一个聚类中心,所有与证据1距离小于距离均值的证据归为一类,其余证据中选取一个作为新的聚类中心,并进行均值聚类,再后通过判断聚类准则函数是否收敛,若收敛,则算法结束。最后对聚类结果进行D-S证据推理,得到与类别数相同个源故障,再逐一进行排查。
如下例子中,3个源故障A、B、C对应E1到E77组故障(表2)。
若直接采用D-S证据合成,则判断B为真,若采用Murphy等人提出的算法,3组源故障权重相似,若采用本文算法则将证据E1、E2、E3聚为一类,E4、E5、E6、E7为一类,类别1中C为故障源,类别2中A为故障源。可见本文算法更适用于多冲突数据的故障诊断。
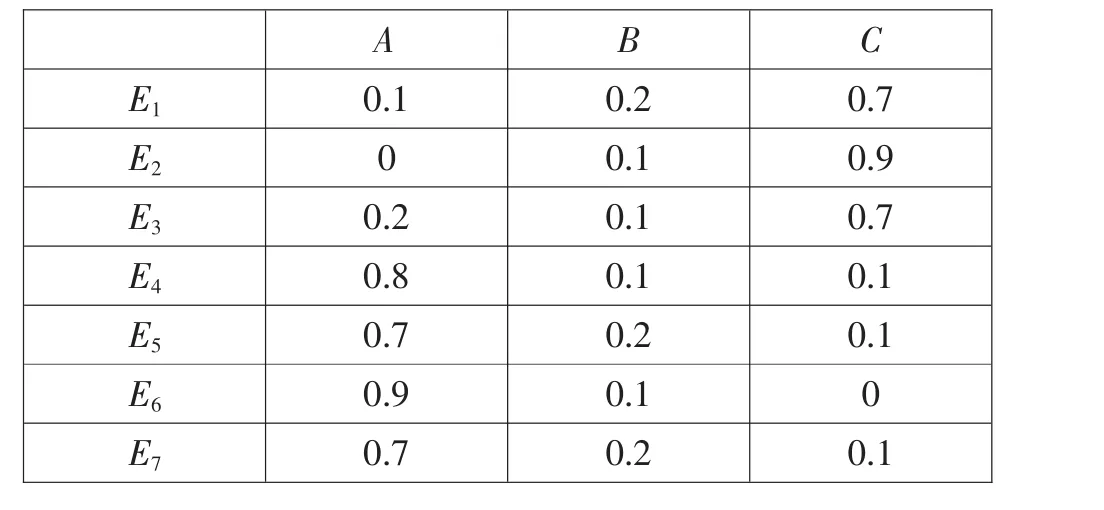
表2 3个源故障A、B、C对应7组故障
5 结论
本文将潜在风险评估中故障频度归一化作为下层源故障到上层目标现象的传递权重,并将其与证据合成中基本信任分配函数相结合,有效地将证据融合运用到汽车故障树诊断中;然后根据实际情况中多故障同时出现的现象,提出了一种多证据聚类的冲突证据处理算法,有效地处理了多证据冲突的合成,提高了合成结果的可靠性与合理性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
汽车实用技术(2022年16期)2022-08-31
舰船科学技术(2022年11期)2022-07-15
汽车实用技术(2022年9期)2022-05-20
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
幼儿智力世界(2016年6期)2016-05-14
祝你幸福·知心(2016年3期)2016-03-29
小雪花·初中高分作文(2015年10期)2015-10-24
