
基于GeoHash与聚类的共享单车动态回收点设置方法研究
2020-01-16 09:55张志清李亚伟ZHANGZhiqingLIYaweiDONGJing
物流科技 2019年12期
张志清,李亚伟,董 静 ZHANG Zhiqing,LI Yawei,DONG Jing
(1.武汉科技大学 恒大管理学院,湖北 武汉 430065;2.武汉科技大学 服务科学与工程研究中心,湖北 武汉 430065)
近年来,随着共享单车投入数量的逐年增多,也产生了大量损坏车辆,如果不能及时处理,在造成资源浪费的同时也会导致一定的经济损失,因此,如何获取损坏车辆的相关信息并进行及时处理,是相关企业良好运营的关键所在。对共享单车而言,由于其创新型无桩停放特性导致车辆停放位置是无序和分散的,因此,共享单车的故障车辆更难回收处理。有学者从多个视角对共享单车的运营进行了研究,主要集中在单车投放站点的选址[1]、单车系统的调度与优化策略[2-4]、停车点最佳投放量决策模型[5]等,但对如何高效处理故障单车方面的研究相对较少,因此本文提出动态回收点概念,在对骑行数据进行分析处理的基础上,采用GeoHash与聚类方法对共享单车动态回收点设置方法,为共享单车的管理提供了新的思路,具有一定的理论和实际意义。
1 共享单车骑行数据处理分析
1.1 原始数据处理
本研究中的样本数据取自2017摩拜杯算法挑战赛,共包含3 214 096条出行记录。由于原始数据经过GeoHash算法编码,所以需要对数据进行解码处理。根据GeoHash算法的编码规则,设计解码算法流程如图1所示。
用Java语言编写程序实现GeoHash解码算法,经检验,算法运行效果良好,可以实现上述GeoHash解码算法,解码后的部分数据如表1所示。

表1 解码后部分数据表

图1 GeoHash编码的解码算法流程图
1.2 空间分布特征分析
根据GeoHash解码算法得到的经纬度数据,生成各个共享单车的空间分布数据,利用ArcGIS软件形成.shp格式的点文件;然后通过ArcGIS渔网生成工具箱,生成北京市200*200米的网格数据形成.shp格式的面文件,将共享单车的O(Origin) 点、D(Destination)点空间位置数据聚合到网格中,将网格上的O点、D点数据通过核密度热力图的形式进行展示,图2为北京市摩拜单车2017年5月10日至2017年5月24日骑行数据的O、D点热力图。
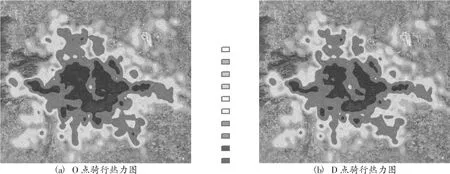
图2 摩拜单车骑行热力图
图中热力强度等级由无色、绿色系、黄色系、橙色、深红、黑色表示并依次增强。为了更加直观、细致的了解各地区、站点共享单车的使用强度,在热力图分析的基础上,通过对骑行区域进行网格划分来量化显示单车使用强度,其中每个网格设定为800*800米。以D点骑行数据为例,在ArcGIS软件中计算每个网格区域的日平均骑行量,如图3所示。

图3 摩拜单车D点日均骑行量图示

图4 北京局部地区摩拜单车日均骑行量显示图
在有单车使用数据的区域,最低日平均骑行量为0.66667次,最高日平均骑行量为1 376.333374次,据此划分了5种颜色所代表的日平均骑行量等级,圆圈内数字表示该区域的日均骑行量。其中绿色圆点表示该区域单车日均使用200次以内;蓝色表示该区域单车日均使用200~400次;黄色表示该区域单车日均使用400~600次;粉色表示该区域单车日均使用600~800次;红色表示该区域单车日均使用800~1 376.333374次。取局部区域进行共享单车空间分布点更加细致的分析。局部日均骑行量如图4所示。
图4中三个红色圆点所在区域为北京大红门服装商贸城到百荣世贸商城的一片商贸区域和东铁营村这一集中住宅区,并且这三处均离地铁站点较近;并且由图4可知,图中红、粉、黄三色所代表的最高强度单车使用区域有其共同特征,这些区域多在地铁站点周边,且所在区域多为办公楼、商场、娱乐场所、住宅区,这些区域均有较多且稳定的骑行需求。
综上所述,通过对骑行终点数据的空间分布分析,可以基本了解到北京摩拜单车的使用情况,包括单车使用的热点区域分布特征以及各地区日均使用量数据,可为后续的逆向物流网络规划提供参考依据。
1.3 单车回收点聚类分析
本文利用北京摩拜的骑行终点数据,通过K-means聚类分析形成一定范围的骑行终点区域作为回收需求区域,并将回收需求区域中的聚类中心点作为回收点,便于后续逆向物流网络构建。K-means算法是基于无监督学习提出的聚类算法,算法描述如下:
输入:训练样本V={v1,v2,v3,…,vn};k:聚类个数;
输出:C={c1,c2,c3,…,ck}。
步骤1:在数据集中随机挑选k个对象作为初始聚类中心c1,c2,c3,…,ck。
步骤2:计算数据集中每个对象到聚类中心的位置,选取最小距离分配到聚类中,其中V={v1,v2,v3,…,vn};j=1,2,3,…,k。
步骤3:将每个聚类中的所有对象的均值作为新的聚类中心,如式(1)所示:

nj为第j类中对象的个数,j=1,2,3,…,k。
步骤4:当各个簇的聚类中心不在发生变化,聚类准则函数如式(2)所示:

收敛,则算法结束,到步骤5;否则返回步骤2继续迭代。
步骤5:输出聚类结果。
K-means算法优点是可以处理大数据集,并且聚类速度较快,有较好的拓展性,K-means算法是相对可伸缩的和高效率的,因为它的计算复杂度为O(nkt),其中n为对象个数,k为聚类个数,t为迭代次数,通常有t≤n,k≤n,因此它的复杂度通常也用O(n)表示。
本文取经纬度坐标点(116.345771,39.981975)和(116.400532,39.955543)作为该矩形区域对角线上两点,在样本骑行数据中截取出D点在此范围内的数据,共获得70 480条骑行数据,该区域面积约为4.5km*2km。在此区域根据骑行数据建立D点热力图,如图5所示。
利用Matlab进行编程实现K-means聚类算法,并在Intel Core i5-5600U CPU@2.50GHz处理器PC上运行,设置算法参数,利用基本的K-means算法进行求解,运行4min得到聚类结果。经检验,该聚类算法具有很强的可操作性,结果可用于后续规划模型。计算过程中,基本的K-means算法的误差平方和的收敛图如图6所示。

图5 聚类区域D点热力图

图6 K-means算法误差平方和的收敛图
可以看到:聚类的误差平方和在12个聚类点之后趋于稳定,说明算法收敛。并且在选择算法k值时也可参考聚类区域热力图辅助分析,结合聚类区域热力强度高的区域个数作为现实参考因素合理配置k值。本文结合热力图分析和上述收敛图结果,选取12个聚类点。算法得到的聚类中心的经纬度坐标如表2所示。
在ArcGIS软件中将上述聚类点显示于聚类区域热力图上,如图7所示。

表2 K-means算法聚类点坐标

图7 聚类点结合热力图综合显示图
图中黑色棋子即为聚类中心点所在位置,可以看出,聚类中心整体分布情况与共享单车骑行热力图中的热点区域吻合度较高,比较符合共享单车运营的实际情况,证明该方法的有效性。
2 结论
在考虑骑行分布特征和现实回收状况的前提下,对共享单车回收处理的逆向物流网络规划方法进行了研究, 基于GeoHash算法对原始数据进行解码处理, 在此基础上,对骑行大数据进行空间分布特征分析, 然后通过聚类分析方法,对所取研究范围内的骑行数据进行聚类分析,得到回收服务区的回收点分布及每个回收点的位置信息。在分析共享单车骑行空间分布特征的基础上,提出了利用K-means聚类对共享单车回收点进行聚类分析的方法。该方法可以有效地计算骑行需求区域,即为单车回收需求区域,并将聚类点作为单车回收点。这一关键步骤为后续的共享单车回收逆向物流路径规划研究奠定了坚实的基础。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
英语文摘(2021年4期)2021-07-22
中国外汇(2019年19期)2019-11-26
现代临床医学(2019年4期)2019-09-10
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
中国自行车(2018年9期)2018-10-13
21世纪商业评论(2018年5期)2018-05-24
中学历史教学(2017年12期)2018-01-19
新高考(英语进阶)(2017年12期)2017-02-26
