
基于特征补偿的单目标跟踪算法
2020-04-23 05:43曹丽娟胡媛媛
计算机工程与设计 2020年4期
白 扬,曹丽娟,胡媛媛,杨 云,2+
(1.云南大学 国家示范性软件学院,云南 昆明 650504;2.云南大学 昆明市数据科学与智能计算重点实验室,云南 昆明 650504)
0 引 言
目前,主流的目标跟踪算法有两大框架:基于相关滤波的跟踪算法,在速度上有绝对的优势,但往往选用一些单一的、低层的手工特征,不能够应对复杂场景的任务,鲁棒性很差;而基于卷积神经网络的跟踪算法,虽然有很高的精度和鲁棒性,但是庞大的网络限制了速度的实时性。另外,采用无差别地更新模版,一旦出现光照变化、形变、遮挡、出视野等等影响因素,将学习到大量的背景信息。
这些算法多数属于是短期跟踪(short-term tracking),主要是在跟踪目标的精度上下文章,在丢失目标之后很难够重新找回,鲁棒性较差,这其实并不能够很好地应用在现实场景中。要做到能够良好应用到现实场景中,还是要把切入点放在长期跟踪(long-term tracking)上,提升算法鲁棒性和速度。因此提出一种特征补偿的模型,规避两种框架的缺陷,充分发挥各自的优势,尽可能地向实际应用靠拢。通过实例验证其有效性,并同一些先进的算法进行对比。
1 研究背景
单目标跟踪,是在视频的第一帧中对跟踪目标的位置和尺寸用矩形框进行人工标注,然后在视频的后续帧中,同样用矩形框紧跟住这个人工标注的物体。与之相似目标检测,是在静态图像或者动态视频中整帧范围内进行扫描和搜寻目标,概括得讲,目标检测关注的是定位和分类。而目标跟踪,关注的是如何实时地锁定某人或物体,它并不在意自己跟踪的是什么。目标跟踪的一个核心的问题是,在一个不断改变的视频场景(例如:遮挡、出视野、形变、光照变化、尺度变化、背景相似等)中,如何精确又高效地检测并且定位到目标[1]。跟踪算法主要分为生成式方法和判别式方法两大类别。生成式方法运用生成模型描述目标的表观特征,之后通过搜索候选目标来最小化重构误差,找到和模型最匹配的区域。生成式方法中最核心的问题是目标的表征方法,比较有代表性的算法有稀疏表征(sparse representation),密度估计(density estimation)和增量子空间学习(incremental subspace learning)等。生成式方法着眼于对目标本身的刻画,忽略背景信息,早期的研究工作,通过经典的数学模型难以准确的把握目标的动态表征信息,因此,在目标自身变化剧烈或者被遮挡时容易产生漂移。相反,判别式方法的目的是建立一个能够从背景中辨别出目标的分类器模型。这一类型的算法通常是基于多示例学习(multiple instance)、P-N learning、online boosting、结构化输出支持向量机(structured output SVM)、集成学习[2-5]等。判别式方法的分类器模型学习过程中用到了背景信息,这样分类器能专注区分前景和背景,因此,判别式方法的跟踪算法普遍优于生成式方法,也逐渐成为这一领域的主流。
信号处理中,有一个概念——相关性,用来描述两个因素之间的联系。Bolme等将相关滤波应用在跟踪领域,提出了一种最小输出平方和误差(MOSSE)的快速相关滤波跟踪算法。作者将时域的相关操作进行傅里叶变换后,转换为频域的乘积操作,大大地提升了计算速度。由于相关滤波在目标跟踪领域的计算效率和良好的表现,近年来,备受关注,出现了大量基于相关滤波的跟踪算法。Hen-riques 等出了CSK算法,采用了循环移位的方法进行密集采样,并利用核函数将低维线性不可分的模型映射到高维空间,以此来提高相关滤波器的性能。KCF[6]在原作CSK的基础上进行了改进,将原始单通道灰度特征替换扩展为多通道的方向梯度直方图(histogram of oriented gra-dients,HOG)特征,依靠快速傅立叶变换和fHOG,在扩展特征通道的同时,速度上依然存在优势。CN[7]则是用多通道颜色特征Color Name去扩张CSK,将RGB的3通道图像映射为11个颜色通道。SAMF[8]将HOG特征和CN特征结合,并加入尺度缩放。DSST[9]则是将目标的平移和尺度缩放,看作两个独立的任务,分别建立平移相关滤波器和尺度相关滤波器。虽然这些算法都有较快的速度,并且一部分特定的视频场景中有较好的表现,但是单一的、低级的特征,在应对一些复杂的视频场景时,仍然存在较大的缺陷。
深度学习之所以能够在Imagenet[10]大放异彩,是因为有海量的数据供网络学习。但是在跟踪问题里,训练数据缺失,仅仅将第一帧的图像作为训练的样本是远远不够的。现有的很多训练好的网络主要针对的任务是目标检测、分类、分割等,网络结构一般都很大,因为它们要分出很多类别的目标。而在跟踪问题中,一个网络只需要分两类:目标和背景,并不需要这么大的网络,这样只会增加计算负担,影响实时性。端到端网络结构的跟踪算法MDNet[11],利用视频跟踪的数据对分类模型VGG-M network[12]网络结构的权重进行微调(fine-tuning)。它们在所得跟踪目标中,虽然类别不同,但是其之间存在着共性,是能够通过网络学习到的。从策略上扩充了网络的训练数据。另一类基于孪生网络结构(siamese network)的跟踪算法[13-17],只需要卷积层分别提取出模版帧和当前帧的高层语义特征,再进行相关操作。虽然孪生网络的跟踪算法,在精度和鲁棒性方面都具有出色的表现,但是庞大的网络结构,依然限制了速度的发挥空间。
针对上述问题,提出了一种特征补偿的跟踪算法。该算法引入一个简单的逻辑回归分类器,作为切换特征的标志。将颜色直方图、方向梯度直方图两种特征结合的相关滤波跟踪器应用在简单的视频场景中,以保证较高的速度。一旦分类器判断前者不再可靠,便切换拥有高层卷积语义特征的孪生网络结构的跟踪器,以保证跟踪精度和鲁棒性。并根据分类器的得分,有选择的对相关滤波的跟踪器的模版进行更新,减少累计误差的影响,避免模版被污染造成目标的丢失,进一步提高模型的鲁棒性。
2 算法描述
2.1 颜色直方图特征模型分支
由于本算法考虑的是应用更广泛的单目标跟踪任务的情景,也就是需要在目标跟踪任务开始之前,用人工标注的方式以矩形框选出所要跟踪的目标,并裁剪出候选区域带有背景信息的目标子图像,然后模型才会根据所选目标及其背景所具备的特性,进行区分,完成后续跟踪任务。因此,在这样情景下,无论是基于何种特征,模型都会通过视频第一帧选出的目标框内的图像,按照模型各自的策略生成一个初始的特征模版用以匹配后续帧图像的候选区域,从而预测出目标的位置和大小。


图1 前景掩膜与背景掩膜
ρ(A)=N(A)/|A|
(1)
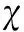
(2)
(3)

图2 后验像素直方图与响应
在线跟踪的过程中,视频中的场景随时都在发生或微妙或剧烈的变化,对于颜色直方图特征而言,光照变化、运动模糊等干扰因素的影响尤其严重。因此为了较好的适应视频场景中存在的这些变化,在每次完成一帧的跟踪任务的同时,需要对直方图模版的权重βt进行更新,也就是对前景和背景的像素比例ρ更新
ρt(O)=(1-ηhist)ρt-1(O)+ηhistρ′t(O)
ρt(B)=(1-ηhist)ρt-1(B)+ηhistρ′t(B)
(4)
其中,ρ′t表示当前帧,通过式(1)计算得到的像素比例;ρt-1表示前一帧的像素比例;ηhist是一个值固定的学习权重。从式(4)不难看出,学习权重越大,越能学习到更多当前帧的信息,适应颜色表征变化剧烈的场景。但是,权重越大模版也越容易学习到背景信息,加快误差的累积,通过分析直方图特征在光照变化(如图3上半部分所示)、背景颜色相似(如图3下半部分所示)这两类场景中的表现可以看出,仅仅对直方图特征的模版更新,已经远不能满足此类场景跟踪任务的需求。

图3 光照变化与背景颜色相似下的响应
2.2 方向梯度直方图特征模型分支
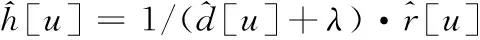
(5)

图4 方向梯度直方图与响应
(6)
在频域中用*表示共轭,⊙表示元素乘法。
fhog(x;h)=∑u∈Th[u]Tφx[u]
(7)
视频中场景存在各种各样的变化,方向梯度直方图同样也会因为目标发生变化,而造成干扰,尤其物体形变造成的影响较大。显然,由起始帧构建一个固定的模版,来完成有所帧的跟踪任务并不是一种有效的方式。因此,为了能适应这种变化,提高模型的鲁棒性,需要在完成每一帧跟踪任务的同时,对模版进行更新
(8)
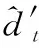

图5 目标形变的响应
2.3 特征融合
颜色直方图特征在场景中存在光照变化、画面模糊等干扰因素的时候,对模型的影响较大,而方向梯度直方图特征在目标有形变、快速运动等干扰因素的时候,对模型的影响较大。所以将两种特征融合,可以在一定程度上减少这些因素的干扰,提高跟踪模型精度和鲁棒性,使其在跟踪任务中,能够预测出目标更为准确的位置和大小,且并不容易丢失目标。这里用一个线性函数融合两种特征的响应
f(x)=γhistfhist(x)+γhogfhog(x)
(9)
其中,γhist和γhog是两个固定的权重,fhist和fhog分别从式(7)、式(3)中计算得到。最后融合得到响应的f(x),其最大值所对应的点的坐标即为目标的中心坐标。
2.4 分类器与神经网络跟踪器
虽然将两种特征进行融合之后,能够在大部分场景中表现出良好的效果,但是,由于累计误差的存在,随着跟踪任务的推进,容易漂移,丢失目标。另外,对于一部分如背景相似、遮挡、出视野等较为复杂的视频场景,仍然有较大的性能提升的空间。因此,可以加入其它更鲁棒、效果更好的神经网络结构的跟踪器来提高模型的性能。考虑到神经网络运行速度较慢,目前一般的硬件设备不能满足实时性的要求,一种有效权衡的方法就是在前两种特征融合的模型不能很好完成当前帧的跟踪任务时,切换神经网络的跟踪器,才能最大限度发挥模型的性能。然而,应对这样的需求最关键,也是最难的点就是让特征融合模型知道什么时候需要切换神经网络结构的跟踪器。通过分析f、fhist、fhog这3个响应值在不同场景下的变化情况可以得出结论,在目标发生较大形变或者有遮挡等情况下,f、fhog均出现较大波动,因此可以通过这两个值训练一个分类器作为切换跟踪器的标识。
为了保证在引入分类器同时不会对核心算法的速度造成太大影响,选用一个简单快速的逻辑回归分类器
(10)
2.4.1 数据预处理
在这里,为了完成式(10)分类器的训练工作,选择OBT2015[1]目标跟踪数据集和ILSVRC(large scale visual recognition challenge)目标检测数据集的部分视频序列作为生成训练数据的原始样本。将这批视频序列经过特征融合的模型,输出供分类器训练测试的数据集并保存。这是一个二分类任务,令数据集的输入X=[max(fhog),max(f)], 类标y为0或1的整数,0表示模型的跟踪框已经偏离了目标,1表示没有偏离目标。但是仅仅这样得到的数据集,存在不平衡、标注不准确的问题。
数据不平衡:模型中存在模版在线更新的机制,虽然能这对算法的鲁棒性有一定的提升,但也是累计误差的根源,一旦发生漂移,将很难再次找回目标,这也就会在生成数据集的过程中,产生大量的负样本(偏离目标)。这些负样本不但影响了数据的平衡性,甚至有一部分学习了大量背景信息的噪点。这样的数据训练得到的分类器,分类精度将大大降低。使用两种方式生成数据以减小影响:
(1)视频序列均有人工标注信息(ground truth),在生成数据的时候,借此控制模版更新的条件。当预测目标偏移真实目标的时候,停止更新模版,避免学习到背景信息,降低误差,减少噪点。
(2)不做预测,每一帧都完全使用ground truth,生成的样本全为正样本(未偏离目标)。
标注不准确:物体遮挡、出视野这两种场景比较特殊,即便是预测结果和ground truth偏差不大,但是,模型同样会学习到背景信息,响应值同样会出现很大的波动。因此,在这样的情况下,对此二类场景,不管目标偏离与否,类标y都应重新标注为0,以此提升数据的可靠性。
2.4.2 神经网络跟踪器
这里选择的神经网络跟踪器是DaSiamRPN[19],它结合了目标检测的思想和结构区域建议网络[20](region proposal networks,RPN)。传统孪生网络结构的跟踪算法采用宽高等比例尺度缩放,这种方式在宽高比例发生剧烈变化时,精度会大大下降,并且对于有在线更新策略的模型,将学习到更多的背景信息,加快误差累积。而RPN网络能更加准确地拟合目标形变之后的尺寸,提高了跟踪的精度和鲁棒性,同时没有了多尺度检测,速度有显著提升。
前面提到过,在线跟踪的阶段需要用式(4)、式(8)分别对颜色直方图模版和方向梯度直方图模版进行更新,来适应视频中场景的变化。同样地,在切换DaSiamRPN跟踪器完成当前帧的跟踪任务之后,仍然需要用这两个公式进行更新操作。但是因为DaSiamRPN也存在跟踪失败的情况,所以只在当前帧预测出的目标置信度较高才对模版更新,避免学习到错误的信息。至此,才进行下一帧的跟踪任务,直至完成所有视频帧。至于DaSiamRPN的模版,因为经过其卷积层得到的特征已经足够优秀,如果在这一部分仍沿用在线更新模版的策略,不仅大大降低算法的速度,甚至可能因为前面特征融合的模型预测得到一个错误的结果,使得DaSiamRPN的模版受到污染,降低整个算法的鲁棒性。
至此,介绍完所有模型分支,就可以构建如图6所示的算法结构。起始帧分别建立颜色直方图、方向梯度直方图、DaSiamRPN跟踪器三者的模版,跟踪的预测阶段,分别提取颜色直方图特征和方向梯度直方图特征与其对应的模版进行匹配,得到两个响应图,进行加权求和后得到融合的响应图。分类器判断响应值是否可靠,如果可靠,则预测得到目标,并选择高置信度响应值对应的帧,将颜色直方图和方向梯度直方图的模版更新;如果不可靠,切换DaSiamRPN跟踪器,预测得到目标,同样选择高置信度响应值对应的帧,将颜色直方图和方向梯度直方图的模版更新。期间,DaSiamRPN的模版不做任何更新操作。
3 实验及结果分析
为了评估本算法的性能,选择VOT(visual object tracking)竞赛的评价方法、数据集、评价系统进行本次实验,所有结果均由官方提供的工具包得到,以保证公平的比较。其中包括VOT2016[21]、VOT2017[22]两个数据集,每个数据集都包含60个视频序列,涉及了遮挡、光照变化、目标移动、尺度变化、相机移动、出视野等属性,在一个视频序列中可能出现多种上述属性,这样可以对模型进行更精准的评价。算法用Python实现并使用了PyTorch库,运行在Intel Core i7-6700,8G RAM,NVIDIA GeForce GT 730的主机上,基准数据集速度可以达到30FPS。

图6 算法的结构
VOT中有两套评价标准,Baseline和Unsupervised。下面分别就这两个标准的实验结果进行分析:
(1)Baseline
VOT官方考虑到大部分跟踪算法不能完全预测出视频序列中所有帧的目标,甚至在一开始便丢失目标,导致最终评价系统只利用了序列中很少的一部分,造成浪费。因此,为了能精确的对算法测评,尽可能利用所有视频序列,加入了重置机制。当检测到败时(预测目标和ground truth的重叠率为0),系统将会在5帧后对算法重新初始化。算法的性能指标分别用正确率(accuracy,A)、鲁棒性(robustness,R)和平均重叠率(expected average overlap,EAO)来衡量。
使用最新版本的VOT toolkit来评估算法性能,并由官方提供的基准数据中,选择7个表现比较突出的跟踪算法和该算法(FCtracker)进行比较,得到表1中,各个算法在VOT2016、VOT2017两个数据集对应的正确率、鲁棒性、平均重叠率等指标的分数。

表1 基准数据集上的性能
主流的排名体系中,多以平均重叠率的分值作为算法的最终排名。如图7所示,可以清晰地看出各个算法的性能排名(越靠近右上角,性能越好)。在VOT2016中,该算法以0.3288的平均重叠率排名第二,位于ECO之后。正确率排在第一位,为0.5688,相比第二的ECO算法提升了6.6%;鲁棒性排在第二位,为18.5103,虽然低于ECO,但是仍比第三的Staple的提升了22%。而VOT2017中,以0.2624的平均重叠率排在第三。正确率依旧第一,为0.5317,相比平均重叠率第一的DeepCSRDCF算法提升了将近10%;鲁棒性同样远高于排名靠后的算法。从表中可以看出,虽然该算法,在两个数据集中的排名稍有落后,但是在评分前三的3个算法中速度最快,是ECO算法的10倍,是DeepCSRDCF算法的8倍。
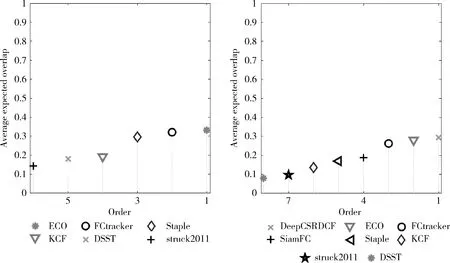
图7 VOT2016和VOT2017的平均重叠率排名
(2)Unsupervised
这种评价标准虽然不是主流,但是因为没有重置机制,所以能够更加客观更加真实地反映现实场景中跟踪情况。它的性能指标只有曲线下面积(area under curve,AUC)一项,见表2。
以上可以看出,该算法在VOT2016基准数据中以0.4944的AUC评分位列第一,比排在第二的ECO算法提升了4.1%;VOT2017中,同样以0.4187的AUC的评分排在第一,比ECO提升了5.1%。且在排名前三的算法中,速度最快。可以通过图8的曲线直观地看出,不同重叠率的阈值下,正确率的变化情况。

表2 无监督的性能比较
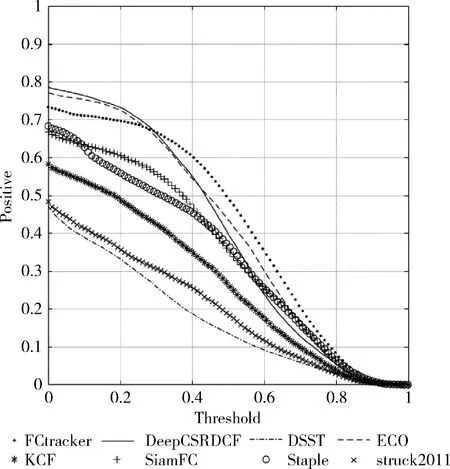
图8 不同阈值下无监督重叠率曲线
分类器的数据集中存在不平衡,正样本少的问题,手工调整,明显不是最佳的处理方式。针对不平衡数据的半监督学习算法[23-25],在复杂数据集中可获得较好的学习效果,在未来的工作中,可以考虑采用此类高级机器学习算法来辅助和完善模型的训练。
4 结束语
提出了一种基于特征补偿的模型,详细介绍了设计思路和模型的构建过程。简单的场景使用简单快速的特征,复杂场景使用鲁棒的特征,以此,来权衡相关滤波结构的跟踪算法长时间跟踪容易丢失目标,神经网络结构的跟踪算法速度慢耗费资源的问题,向实际应用靠拢。在基准数据上有突出的表现,尤其是贴近现实场景的无监督这种评测标准。但是,仍存在一些简单的情景误判,使用复杂的特征,且速度还有很大的提升空间。
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
太阳能(2022年3期)2022-03-29
太阳能(2020年3期)2020-04-08
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
当代工人·精品C(2019年2期)2019-05-10
摄影之友(影像视觉)(2018年12期)2019-01-28
计算机应用与软件(2017年7期)2017-08-12
初中生世界·八年级(2017年3期)2017-03-24
项目管理技术(2016年12期)2016-06-15
