
基于纹理特征的维吾尔文离线手写签名鉴别
2020-04-24 03:07张淑婧麦合甫热提吾尔尼沙买买提朱亚俐库尔班吾布力
计算机工程与设计 2020年3期
张淑婧,麦合甫热提,吾尔尼沙·买买提,朱亚俐,库尔班·吾布力+
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046; 2.新疆大学 教务处,新疆 乌鲁木齐 830046)
0 引 言
手写签名鉴别通过不同的获取方式分为两种:在线手写签名鉴别和离线手写签名鉴别。离线手写签名中只存在签名的静态特征,鉴别难度较大。通过不断的研究,常见语种的离线签名鉴别已趋近完善,取得良好的实验结果,而针对维吾尔文签名的研究仍处于发展阶段。
Muhammad Sharif等[1]使用遗传算法对签名的特征进行选择,使用SVM分类器进行分类鉴别,在CEDAR和GPDS拉丁文数据库上得到最终AER分别为4.17%和5.42%。Elias N.Zois等[2]对网格特征编码并进行模板匹配,该方法在GPDS数据库上可得到EER为9.42%。Guerbai等[3]使用单类SVM进行不依赖于书写者的签名鉴别实验,在CEDAR数据库中结果AER为5.60%。Hafemann等[4]提出使用卷积神经网络进行签名鉴别的方法,运用支持向量机进行分类鉴别,在CEDAR数据库中得到约为4.63%的等错误率。在维吾尔文签名识别和鉴别的研究中,库尔班·吾布力等[5-8]于2014-2018年通过对签名图像提取改进的方向特征、灰度共生矩等特征,采用不同的分类算法进行签名识别和鉴别。吐尔逊姑丽·阿布都瓦依提[5]开始对维吾尔文离线手写签名鉴别进行研究。在文献[6]中采用密度特征和KNN分类器,得到识别准确率达96%。
本文中采用多尺度块局部二值模式以及改进的分块局部相位量化算法对签名进行特征提取,并使用随机森林算法对维吾尔文签名进行分类鉴别,对得到的实验结果进行分析。
1 离线手写签名鉴别
离线手写签名鉴别问题的研究,是生物识别研究中的一个研究领域,也是模式识别领域的一个研究方向。作为模式识别中的一个研究方向,与大多数模式识别问题一样,离线手写前面分为4个步骤,分别为数据采集、预处理、特征提取、训练及测试。其流程如图1所示。
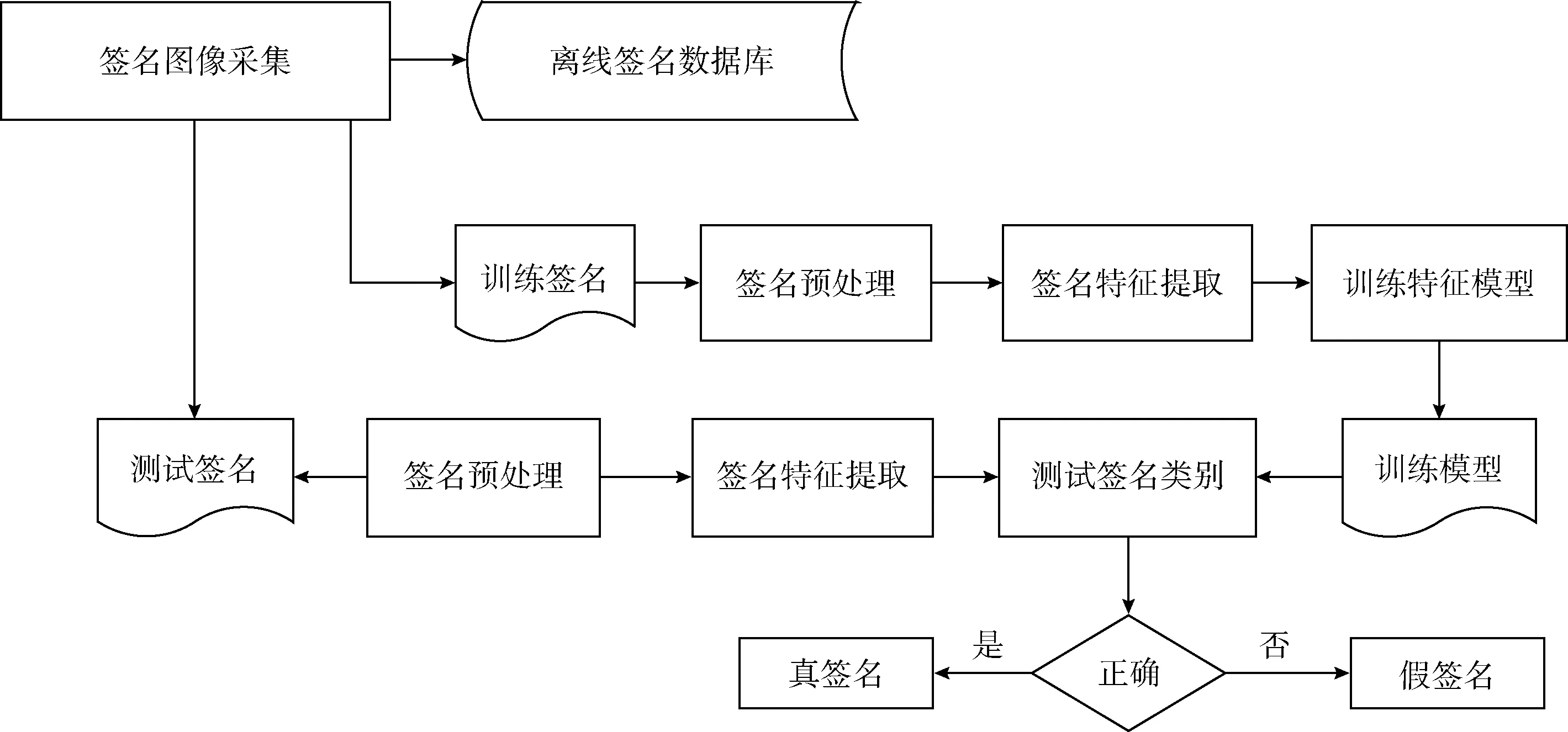
图1 离线手写签名鉴别流程
数据采集:本文使用维吾尔文离线签名数据库,此数据库中采集了870个维吾尔族人的签名。每人书写21个真签名,简单伪造签名21个,熟练伪造签名21个,共17 400个签名样本。从中选择18人的真假签名作为本实验的签名样本进行实验。同时,使用拉丁文签名数据库CEDAR进行签名鉴别实验。
预处理:为了更好保留签名图像的差异化信息,在对图像进行特征提取之前需要对其进行处理。本文中首先对图像进行大小归一化,将签名图像大小归一为384×96像素。此后,使用加权平均法进行灰度化处理,用OTSU算法对签名图像进行二值化处理,并使用双边滤波对图像进行去噪。这样能够更好保存图像的内部信息以及边缘信息。预处理图像如图2所示。

图2 预处理签名图像
特征提取:特征提取是签名鉴别过程中重要的一环,只有从签名中提取到能够表示签名者身份的特征才能继续进行鉴别。本文采用由Shengcai Lia等提出的多尺度块局部二值算子与局部相位量化特征进行串联融合,形成本文用于实验的特征向量。
训练及测试:首先将训练签名样本从特征提出中所提取出的特征向量进行训练,形成训练模型,再通过训练模型进行分类测试,得出测试签名是否为真签名。本文中采用随机森林算法对签名进行分类鉴别。
2 特征提取
2.1 局部二值模式
局部二值模式(local binary pattern,LBP)[9],是一种主要对图像纹理特征进行描述的特征算子,其具有灰度不变性及旋转不变性等特性。通过多年来对该算子的不断发展与改进,现已被广泛应用于图像分类,图像检索等领域。
2.1.1 基本LBP算子
LBP算法以邻域为窗口,提取图像的局部纹理。选取邻域大小为3×3的窗口,将窗口内中心点gc的灰度值作为中心阈值,将其周围8个点g0,…,g7的像素与其比较,若邻域灰度值大于gc灰度值,则该点记为1,反之记为0。以该邻域内以左上角点为起点,按顺时针方向可得到一个八位二进制数,求取该二进制数的十进制表示方法,即为该点LBP值,求取方法如图3所示。
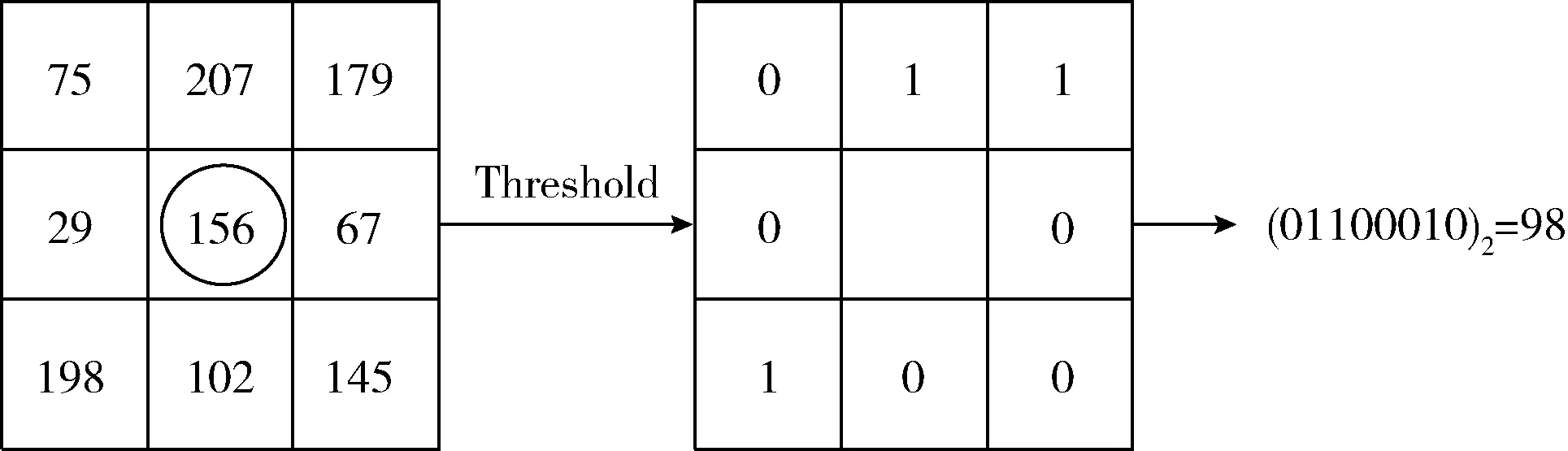
图3 基本LBP算子生成过程
2.1.2 多尺度块局部二值模式
多尺度块局部二值模式(multiscale block local binary pattern,MB-LBP)是由Shengcai Lia等提出的一种LBP的改进算法[10]。该算法将进行灰度值的比较时,没有采取原始LBP算法中的将像素灰度值进行比较,而是将对图像子区域内像素的平均灰度值作为子区域灰度值进行比较。如图4所示。
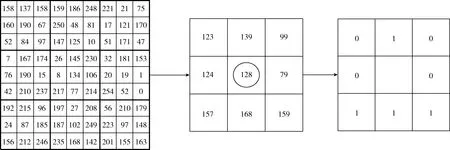
图4 MB-LBP算子生成过程
图4为一个9×9的MB-LBP算子生成过程。9×9的图像块划分为9个大小为3×3的小块,求取每个3×3小块的灰度平均值,得到3×3的灰度矩阵,其余提取MB-LBP算子与原始LBP算子过程一样。当采用3×3的MB-LBP算子时,则相当于一个基本3×3LBP算子。求取小区域平均灰度值时,可以采取求和区域表或积分图像的方法。本文采取积分图像的方法,以方便快捷的计算灰度平均值标量。因此,MB-LBP算子的提取速度同样较快,仅稍慢于基本3×3算子提取速度。不同分块规模时MB-LBP滤波图像如图5所示。

图5 MB-LBP滤波后签名图像
由图5可以看出,不同规模MB-LBP滤波的图像有较大区别。随意在进行实验时,应选择合适的规模。本文中选取9×9的MB-LBP算子进行实验。提取MB-LBP算子的进行训练鉴别时,还需要提取其直方图,形成MB-LBP直方图特征。
2.2 局部相位量化
局部相位量化(local phase quantization,LPQ)是由Ojansivu等[11]提出的一种局部描述符,在图像的频域空间处理空间模糊纹理特征,其具有良好的模糊不变性和灰度不变性。LPQ算法的提出者指出,该算法仅使用图像的相位信息作为图像特征,具有较强的鲁棒性,该算法目前别广泛应用于人脸识别领域中。在数字图像处理领域中,空间模糊图像I(x) 是通过对图像强度f(x) 和点扩展函数h(x) 进行卷积得到的,公式如下
I(x)=f(x)×h(x)
(1)
在图像频域内,上式可用式(2)
J(u)=F(u)×H(u)
(2)
该式为式(2)在频域内的乘积形式。其中,J(u)、F(u) 和H(u) 分别为I(x)、f(x) 和h(x) 的离散傅里叶变换。由于局部相位量化算法仅讨论图像相位,则考虑到J(u)、F(u) 和H(u) 的相位信息,则可有公式
∠J(u)=∠F(u)×∠H(u)
(3)
当点扩展函数h(x) 中心对称时,其傅里叶变换H(u) 一直为实数。当H(u) 不小于0时,相位信息∠H(u) 为0;当H(u) 小于0时, ∠H(u) 值为π。
在LPQ算法中,通过计算短时离散傅里叶变换,计算图像中M×M大小的领域Nx内每个像素位置的图像f(x), 公式如下所示
F(u,x)=∑f(x-y)e-2πjuT
(4)
式中:u为频率。图像的行列的卷积计算可以分开进行,在本算法中,以对图像先行后列的方式做一维卷积计算。计算局部傅里叶系数时,采用的4个频率点如下所示
u1=[a,0]T,u2=[0,a]T,u3=[a,a]T,u4=[a,-a]T,
(5)
其中,a是足够小的数,且使H(u)>0。 则有
Fx=[F(u1,x),F(u2,x),F(u3,x),F(u4,x)]
(6)
为使LPQ算子方便表示和计算,需将它们进行进一步的量化。通过对Fx中每一分量的实部和虚部的符号对傅里叶系数的相位信息进行标记,公式如下
(7)
向量K(x)=[Re{F(x)},Im{F(x)}] 的第j个部分由kj表示。此时qj通过二进制编码的方法,被量化为LPQ特征值,计算方法如下所示
(8)
LPQ算法提取特征过程如图6所示。
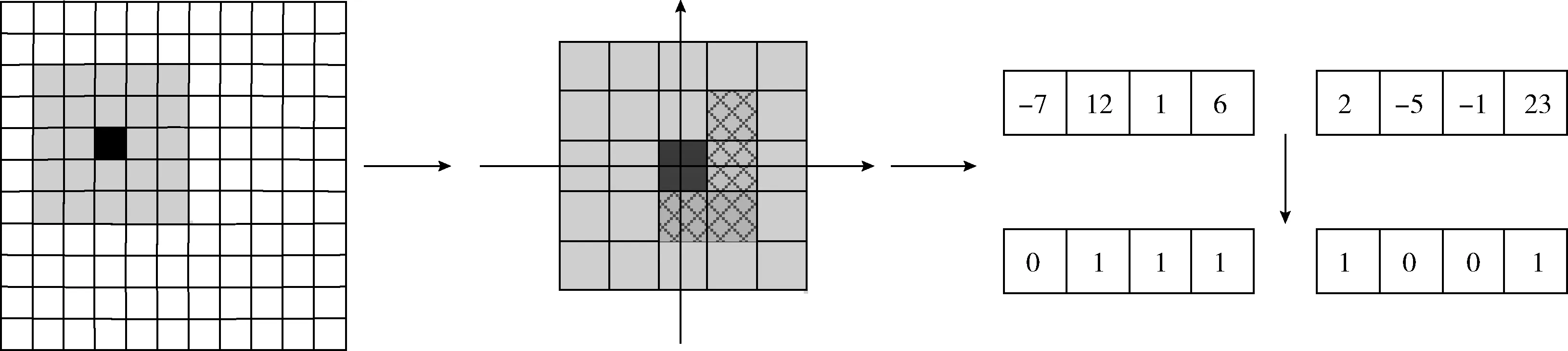
图6 LPQ提取特征过程
3 随机森林
随机森林(random forest,RF)算法由2001年被提出,该算法是一种基于决策树的机器学习算法[12]。其利用对多个树进行训练并预测的分类算法,通过生成多个决策树和投票的方法对多特征数据进行分类,具有较高的计算效率和准确率。现阶段,随机森林别广泛应用于生态、经济、图像识别中。
该算法的基本单元为决策树,采用Bagging集成思想,随机选取不同的训练特征子集构建不同的决策树,根据所有构建出的决策树的分类结果通过投票的方法确定最终分类。随机森林具有样本集的随机性和特征的随机性这两个主要特性。所以,随机森林算法具有良好的泛化能力,快速处理上千维的特征数据,且不会产生过拟合现象。
随机森林算法作为一种基于决策树的分类算法,主要包括以下几个步骤:
步骤1 从原始样本集D中采用Bootstrap 重抽样的方法有放回地形成k个样本子集Dk;
步骤2 设原始样本中包含a个属性,从每一个样本中选择属性a中的m个特征值,建立决策树;
步骤3 重复上述过程,建立n个决策树,并在每个节点位置将小于维度格式的维度向量作为该节点的分类标准;
步骤4 对获得的分类结果进行误差测试,采用多数投票确定最优分类结果。
图7为随机森林算法的生成过程。

图7 随机森林分类流程
4 实 验
4.1 数据库与实验环境
本文中数据库采用由本地收集的维吾尔文签名数据库和国际公开的拉丁文手写签名数据库CEDAR。维吾尔文签名数据库中,包含30人维吾尔文手写签名图像,其中每人包括20个真签名,20个简单伪造签名,20个熟练伪造签名,合计1800个签名图像。CEDAR数据库中,包含55人拉丁文签名,每人包括24个真实签名图像和24个伪造签名图像,共2640个签名图像。在进行离线手写签名鉴别时,从两个数据库中每人的真签名和伪造签名中分别选取12个签名图像进行训练,总共每人选取24个签名用于训练,其余签名图像用于测试。则对于维吾尔文手写签名鉴别实验而言,总共720个图像用于训练,1080个图像用于测试;对于CEDAR拉丁文数据库而言,共1320个图像用于训练,1320个图像用于测试。本文中,对两种不同数据库随机选取签名图像进行10组实验,求取实验结果平均值作为该组实验的结果。
本文中所有实验均在64位Windows7的环境下进行,其CPU为i5 4460,3.20 Hz,内存为4 GB,具体程序通过使用Visual Studio 2012与Matlab2016b混合编程调试。
4.2 参数设置与评价标准
本文在使用随机森林算法中,单棵树最大深度为10,节点分裂最小样本数为2,决策树最大棵数为3000棵树,其中树中每个节点随机选取特征15个,从而寻求最佳分裂。
在进行离线维吾尔文手写签名鉴别时,使用错误拒绝率(false rejection rate,FRR)与错误接受率(false accep-tance rate,FAR)对签名鉴别的结果进行评价。FRR代表在鉴别过程中将真签名误认为伪造签名的错误率,而FAR代表将伪造签名误认为真签名时的错误率。为了更好的对签名鉴别结果的综合能力进行评价,引入总正确率(ove-rall right rate,ORR)进行评价。FRR、FAR、ORR这3种评价标准计算公式如下所示
(9)
(10)
(11)
4.3 基于MB-LBP的签名鉴别实验
本文在提取MB-LBP直方图特征时,采用分块的方式,这样的处理可以更好提取不同部位签名特点,并进行比较。防止因为不同签名提取的MB-LBP滤波图像相似而带来的误差。本文主要通过从图像宽度进行等分的方式对MB-LBP图像进行分块,将每一个小图像块的MB-LBP直方图进行串联融合,形成256×k维的特征向量。该分块特征记为MB-LBPk,其中,k即为等分后图像区域块数。本文实验中,k取1,2,3,4,6,8等6个值(均可对图像宽度384进行整除)。实验结果见表1。

表1 基于MB-LBPk的维吾尔文签名鉴别实验结果
表1中数据为使用MB-LBP算法提取特征,在维吾尔文签名图像数据库进行实验的结果。在不分块的情况下,通过分类鉴别得到FRR为4.87%,FAR为7.71%的结果。当切分块数为4时,可以得到本组实验中的最好结果,其FRR为3.54%,FAR为5.54%,ORR为95.46%,分别比未分块时的鉴别结果提高了1.33%、2.71%和1.75%。使用MB-LBP算法提取的特征在CEDAR数据库中的实验结果见表2。
表2中对CEDAR数据库进行实验的结果与表1中相似的是,当图像不进行分块特征提取时,其鉴别结果低于分块后的鉴别结果。当k=1时,ORR为95.67%。对图像提取分块MB-LBPk时,在k=2的情况下,FRR、FAR、ORR分别为3.88%、3.65%、96.23%。
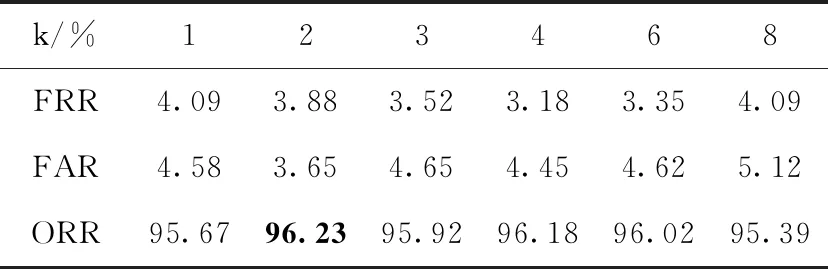
表2 基于MB-LBPk的CEDAR数据库签名鉴别实验结果
表1与表2中结果对比,CEDAR数据库中总正确率低于维吾尔文签名鉴别总正确率,且得到最佳结果的分块特征MB-LBPk的k值也不相同。造成这种情况发生的主要原因是,不同语言的文字书写结构不同,因此造成鉴别结果的差异。从表1和表2中,可以看出采用对图像分块后提取特征的方法可以有效提高签名的鉴别率。
4.4 基于LPQ的签名鉴别实验
与基于MB-LBP的签名鉴别类似,基于局部相位量化的签名鉴别实验中也加入了分块的思想,该分块后的LPQ算法记为LPQk。分块的块数k=1,2,3,4,6,8, 与MB-LBPk相同。该算法实验结果见表3。

表3 基于LPQk的维吾尔文签名鉴别实验结果
表3中为通过LPQk算法提取维吾尔文签名特征后的鉴别实验结果。由表中结果可得知,分块块数k=4时,有最佳结果。此时,FRR为3.38%,FAR为5.29%,ORR为95.67%。未分块k=1时,实验结果FRR为5.08%,FAR为6.35%,ORR为94.29%。可以得知,当k=4时的实验结果FRR、FAR和ORR分别比未分块时提高1.70%、1.06%、1.38%。表4为使用LPQk特征对CEDAR数据库进行实验的鉴别结果。

表4 基于LPQk的CEDAR数据库签名鉴别实验结果
使用LPQk算法提取CEDAR数据库中签名特征鉴别后的结果见表4。在k=1的情况下,得到的总正确率ORR为96.04%。当k=4时,该方法在CEDAR拉丁文数据库上实验可以得到最佳结果,FRR为3.05%,FAR为3.85%,总正确率为96.55%。而在k=8,鉴别结果最差为95.98%,比实验所得到的最高总正确率低0.57%。
表3与表4中的数据相比,最差实验结果均不出现在未切分前的鉴别实验中。造成该结果的原因可能是由于维吾尔文、拉丁文的姓名间相似度较高,若不能将签名图像的特异部分进行分块,造成特征向量相似,则签名鉴别结果较差。所以,在使用LPQk算法进行签名鉴别实验时,分块数k会极大影响签名鉴别的总正确率。
4.5 基于MB-LBP与LPQ融合的签名鉴别实验
在对提取MB-LBP和LPQ两种特征的签名分别进行实验后,由表1~表4中数据可以看出,两种方法在维吾尔文签名数据库和CEDAR签名数据库中均获得良好实验结果。由此可以看出,两种特征提取算法皆可以提取出有效的纹理特征。在两种特征分别提取特征进行实验的基础上,对MB-LBPk和LPQk进行并联融合,形成256×k×2维的高维特征向量(融合时,两种算法k值取相同值)。采用随机森林算法对高维特征向量进行训练分类。实验结果见表5、表6。

表5 基于MB-LBPk和LPQk的维吾尔文 签名鉴别实验结果
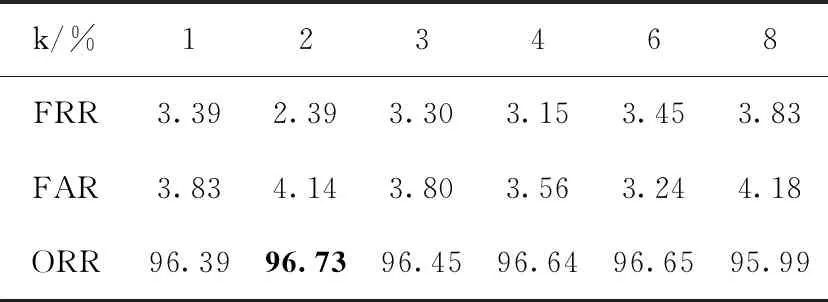
表6 基于MB-LBPk和LPQk的CEDAR数据库 签名鉴别实验结果
表5中数据即为MB-LBPk和LPQk融合特征提取算法在维吾尔文签名数据库中进行实验的结果。当k=4时,签名鉴别结果最好,总正确率为96.36%。比单独使用MB-LBPk和LPQk算法提取特征时的总正确率提升0.89%和0.68%。对未分块时融合后特征向量进行鉴别时总正确率为94.75%,比k=4时ORR低1.60%。
表6为融合特征在CEDAR数据库中的拉丁文手写签名上进行实验的结果。与维吾尔文签名鉴别实验结果不同的是该组实验的最优结果是在k=2时。此时,CEDAR数据库离线手写签名鉴别的FRR为2.39%,FAR为4.14%,ORR为96.73%。比融合前MB-LBPk和LPQk特征的签名鉴别总正确率分别提高0.50%和0.18%。较好提升了CEDAR中拉丁文签名鉴别结果。当k=1未分块时的ORR为96.39%,比融合后的最佳结果低0.34%。
由表1~表6中数据可知,MB-LBP和LPQ的特征提取方法,能够有效提取签名图像的特征信息,并通过随机森林分类器可以得到良好的签名鉴别结果。分块后的MB-LBP和LPQ对图像信息更加敏感,可以使维吾尔文签名和拉丁文签名的鉴别结果得到一定的提升。最后通过特征融合的方法,把MB-LBPk和LPQk串联融合形成高维特征向量,在两个不同文种签名图像库中进行鉴别实验,得到的总正确率分别为96.35%和96.73%。
4.6 实验对比
为了更好探究本文所提出的离线手写签名鉴别方法,将本文中所得到的实验结果与已有的实验结果进行对比。维吾尔文签名数据库结果对比和CEDAR数据库结果对比见表7、表8。
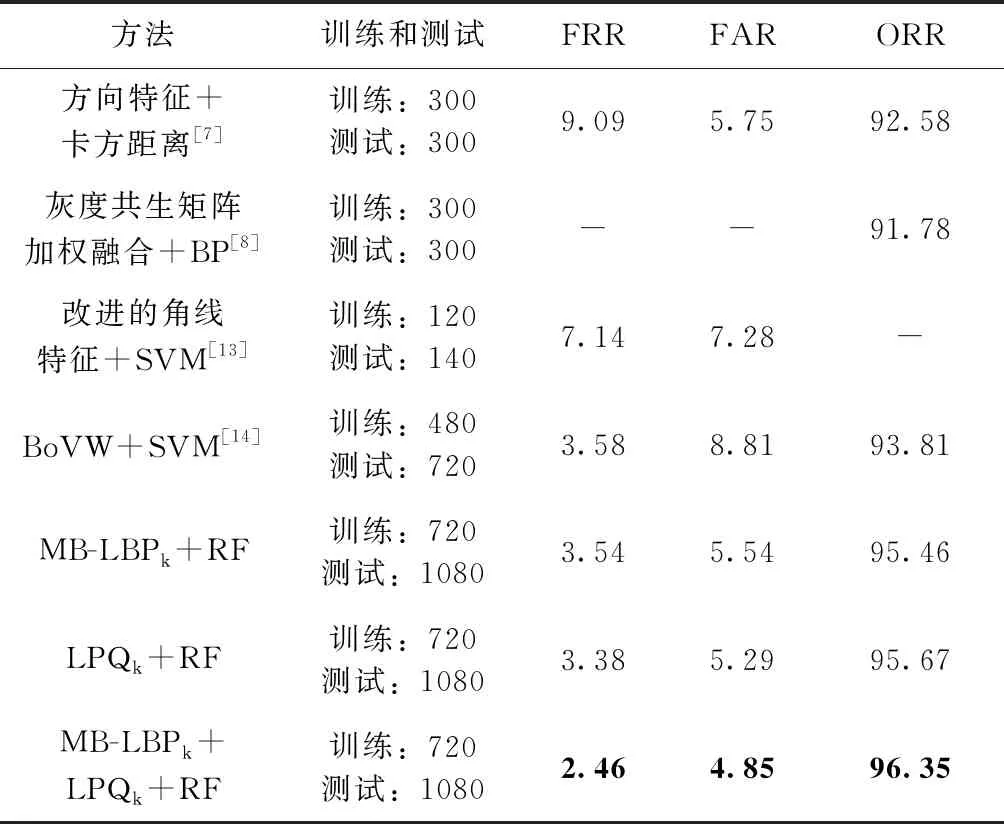
表7 维吾尔文手写签名鉴别结果对比/%
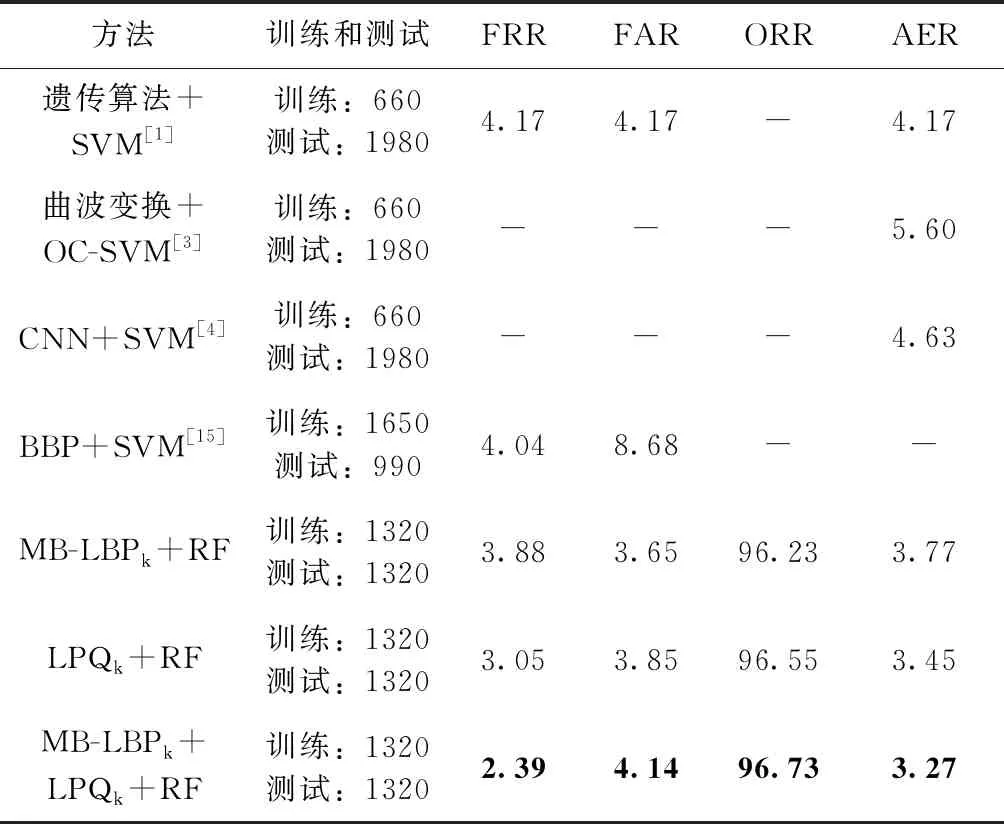
表8 CEDAR数据库手写签名鉴别结果对比/%
通过与已有的实验结果进行对比,由表7可以看出,本文方法在对维吾尔文离线手写签名进行鉴别时,在扩大了实验数据量的情况下,结果仍高于已有实验结果。本文方法比2018年提出的视觉词袋模型特征(BoVW)和SVM分类器进行鉴别的结果FRR、FAR、ORR分别提高了1.12%、3.96%、2.54%[14]。可以看出,该方法比文献[14]中方法的FAR有大幅度提升,所以其总正确率也同样提升。从表8中的数据看出,本文方法在CEDAR拉丁文数据库中也有良好的实验结果,其结果高于文献结果1%以上。说明本文提出方法在对于维吾尔文离线手写签名鉴别和拉丁文CEDAR数据签名鉴别中是有效的。
5 结束语
本文中提出了基于MB-LBP和LPQ融合的维吾尔文离线手写签名鉴别,并且该方法中使用随机森林进行分类鉴别。该方法在包含30人签名(20真签名/每人,20简单伪造签名/每人,20熟练伪造签名/每人)的维吾尔文手写签名数据库和包含55人(24真签名/每人,24伪造签名/每人)CEDAR拉丁文签名数据库中进行实验,得到的总正确率分别为96.35%和96.73%,均高于已有实验结果。因此,MB-LBP和LPQ可以有效提取签名图像特征,且随机森林算法能够高效的处理高维特征向量进行分类鉴别。在今后的研究工作中,将本文中两种算法继续进行网格化分块实验,并使用多种分类器进行鉴别实验对比。尝试使用深度学习算法对签名图像进行训练测试,提高签名的总正确率。
猜你喜欢
房地产导刊(2022年4期)2022-04-19
故事作文·低年级(2021年12期)2021-12-21
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
防爆电机(2021年4期)2021-07-28
铁道通信信号(2020年6期)2020-09-21
作文成功之路·小学版(2020年7期)2020-08-24
山东农业工程学院学报(2020年12期)2020-03-19
铁道通信信号(2019年3期)2019-04-25
电子制作(2018年18期)2018-11-14
中成药(2018年2期)2018-05-09
