
改进biLSTM网络的短文本分类方法
2020-04-24 03:08李文慧张英俊潘理虎
计算机工程与设计 2020年3期
李文慧,张英俊,潘理虎
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
短文本自身信息少、特征表示高维稀疏、语义分布不明显、无序性、噪音严重等给信息抽取造成了一定的困扰[1],并且目前的文本分类模型缺乏稳健性、泛化能力差、易受干扰[2]。
继图像处理之后深度学习在自然语言处理(NLP)领域掀起了热潮[3]。深度学习更深层次的表达文本信息,无需先验知识,在训练过程中不仅容纳海量数据还集特征提取和性能评价于一体,有极大优越性。
深度学习中表现良好的文本分类模型——长短期记忆网络(long short-term memory,LSTM)[4],LSTM是循环神经网络(recurrent neural network,RNN)中的一种,适合处理信息传播过程中间隔和延迟相对较长的信息,提取重要特征,LSTM在RNN的基础上增加了神经元中控制信息出入有记忆功能的处理器——门(gate)机制,解决长短距离依赖的问题;常见的LSTM文本分类模型有多种,YL Ji等[5]提出将RNN和CNN(卷积神经网络)相结合的短文本分类模型,解决传统人工神经网络(ANN)在短文本语料集上分类效果不佳的问题;F Li等[6]提出基于低成本序列特征的双向长短期记忆递归神经网络,学习实体及其上下文的表示,并使用它们对关系进行分类,解决关系分类问题;张冲[7]提出基于注意力机制的双向LSTM模型,利用LSTM长短距离依赖的优势降低文本向量提取过程中语义消失和特征冗余;谢金宝等[8]提出多元特征融合的文本分类模型,由3个通路(CNN、LSTM、Attention)组成提取不同层级的特征,增强模型的辨别力。
1 相关工作
深度学习模型,包括卷积神经网络、循环神经网络,即使性能表现优越,但缺乏对噪音示例正确分类的能力,特别是当噪音被控制在人类无法察觉的范围内时,对噪声样本的辨别力不从心,模型的过拟合严重,泛化能力不够;通常的解决办法有:
(1)使用不同种类的正则化方法简化模型,排除模型记忆训练数据导致泛化能力差的原因;
(2)结合多重神经网络提高泛化能力;
(3)均化或者加入更多噪声样本应付敌对数据;
(4)从数据、算法性能上优化。
对抗训练[9]由Goodfellow提出,在深度学习模型训练方面扮演者一个很重要的角色,作为正则化方式之一,不但优化了模型的分类性能(提升准确率),防止过拟合产生敌对样本,还通过产生错误分类反攻模型让错误样本加入训练过程中,提升对敌抗样本的防备能力,使之拥有更好的泛化能力和鲁棒性,并且模型的分类准确率的预测值在添加对抗性噪音前后尽可能变化范围不大。
本文在双向LSTM的基础上结合对抗训练和注意力机制构造一种神经网络模型(bi-LSTM based on adversarial training and attention,Ad-Attention-biLSTM);首先,利用双向LSTM更加丰富的表达上下文信息,每个词被embedding之后经过时间序列学习长远距离深层次的文本信息并提取特征;其次,利用注意力机制[10]计算词级别的特征重要程度,为其分配不同的权重,增强具有类别区分能力特征词的表达,弱化冗余特征对文本分类的影响;然后,通过损失函数在LSTM输入层词向量上做很小的扰动,验证扰动对短文本分类效果的影响;在数据集DBpedia上利用本文提出的方法进行实验,与短文本分类模型Attention-LSTM、Attention-biLSTM、CNN、CNN-lSTM、Word2vec的相比,从分类准确率、损失率方面进行分析,本文构建的模型在鲁棒性、稳健性、抗干扰性等方面表现较好。
2 短文本分类模型
基于对抗训练和注意力机制的bi-LSTM文本分类模型如图1所示。
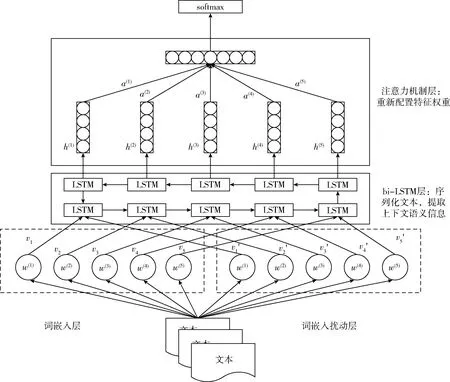
图1 基于对抗训练和注意力机制的Bi-LSTM文本分类模型
2.1 输入层
现有的神经网络深度学习模型不稳定,看似不可察觉的输入错误可能导致模型受到影响,现实情境中如果发生错误分类代价将不可估量,比如邮件过滤系统,错误地对攻击性邮件进行分类;我们希望通过一些方法来计算得到对抗样本,对数据集进行小而故意的最坏情况的扰动形成新的输入,使其参与到训练过程中来提升模型的性能,进而提升模型对抵抗样本的防御能力,受扰动的输入导致模型输出一个高置信度的错误答案,这表明对抗性示例暴露了深度学习模型的盲点,在高维空间中,深度学习模型缺乏抵抗对抗扰动的能力容易导致错误分类,浅层的softmax回归模型也容易受到对抗性例子的影响,通过设计更强大的优化方法来成功地训练出深层的模型,可以减少敌对样本对模型的影响。
对抗训练是一种正则化的方法用于提高分类模型的鲁棒性。Ian J. Goodfellow等[11]认为神经网络易受对抗性扰动的主要原因是它们的线性特性,在MNIST图像数据集增加扰动进行对抗训练,减少了数据集上最大输出网络的测试错误;Takeru Miyato等[9]把对抗训练应用于半监督化的文本分类中,并引入虚拟训练,实验结果表明词嵌入质量提高,而且模型不太容易过拟合;张一珂等[12]把对抗训练应用于增强语言模型的数据,通过设计辅助的卷积神经网络(CNN)识别生成数据的真假,该方法克服了传统的缺陷,降低了错误判别特征的错误率。
文本中词汇的表示方式一般为离散形式的,包括词独热和向量表示,每个文本中T个词汇的序列表示为{w(t)|t=1,…,T}, 其对应的类别为y,定义词向量(word embeddings)矩阵V∈R(K+1)×D, 其中K是词汇表中的词汇数;输入层分为两部分:普通的词向量嵌入层和经过扰动后的词向量嵌入层,扰动后的输入层如图2所示,普通输入层中vk是第i单词的嵌入,为了将离散词汇输入转变为连续的向量,扰动输入层用正则化嵌入vk′来替换嵌入vk,定义为
(1)
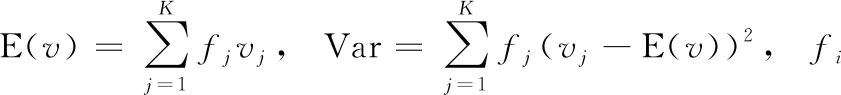
图2 输入层扰动模型
在模型输入扰动层词嵌入部分vk′做调节,把扰动radv添加到词嵌入,然后将扰动后的输入重新喂给模型(biLSTM-Attention),其中radv是通过L2正则化约束和神经网络中的反向传播梯度下降函数求得
(2)
(3)
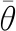
2.2 Bi-LSTM层
在文本分类任务中,每个特征词存在序列关系且其表达受上下文不同距离特征词的影响。双向长短时记忆时间递归神经网络(Bi-LSTM)每个序列向前和向后分别是两个LSTM层,弥补了LSTM缺乏下文语义信息的不足,每个LSTM层均对应着一个输出层,双向结构提供给输出层输入序列中每个时刻完整的过去和未来的上下文信息,门机制决定信息的传输,能够学习到对当前信息重要依赖的信息,遗忘门决定丢弃哪些对分类不重要的信息,输入门确定哪些信息需要更新,输出门决定输出哪些信息;其中遗忘门信息更新如式(4)所示,激活函数δ使用sigmoid
ft=δ(Wf·X+bf)
(4)
输入门信息更新如式(5)所示
it=δ(Wi·X+bi)
(5)
输出门信息更新如式(6)所示
ot=δ(Wo·X+bo)
(6)
单元状态信息更新如式(7)所示
ct=ft⊙ct-1+it⊙tanh(Wc·X+bc)
(7)
t时刻隐层状态信息更新如式(8)所示
h(t)=ot⊙tanh(ct)
(8)
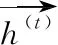
2.3 注意力机制层
在短文本分类过程中,传统的方法直接把Bi-LSTM层每个时刻对应的更新输出向量求和取平均值,这样就默认为每个特征词汇对于区分文本类别有相同的贡献程度,然而短文本特征向量表示高维稀疏,存在大量噪音和冗余特征,直接求和取平均值容易导致分类精度不高,所以我们更期望冗余或者不重要的特征词权重占比更小,而拥有强的类别区分能力的特征词权重占比更大;近年来注意力机制(Attention)被应用在自然语言处理中,类似于人脑注意力分配机制,通过视觉快速扫视眼前所见景象,聚焦需要重点关注的目标景象,然后对这一目标景象摄入大量的时间及注意力,以得到更多和目标景象相关的细节信息,进而抵触其它无用信息,人类注意力机制在很大程度上提高了视觉范围内信息加工的准确性和效率;在自然于然处理文本分类中借鉴注意力机制,对目前任务贡献量不同的区域划分不同的比例权重,目的是从大量的信息中筛选出对分类更至关重要的信息,每个时刻的输出向量可以理解为这个时刻的输入词在上下文的语境中对当前任务的一个贡献,如图3所示是注意力机制编码模型,注意力机制分配权重的形式如式(9)、式(10)所示
ut=tanh(Wwh(t)+bw)
(9)
(10)
s=∑ta(t)ut
(11)
其中,h(t)是注意力机制层经过Bi-LSTM层语义编码得到的输入,ut、Ww、bw是注意力机制层的参数,a(t)是h(t)对应特征词对区分文本类别贡献程度的评分权重,s是输出向量的加权值。
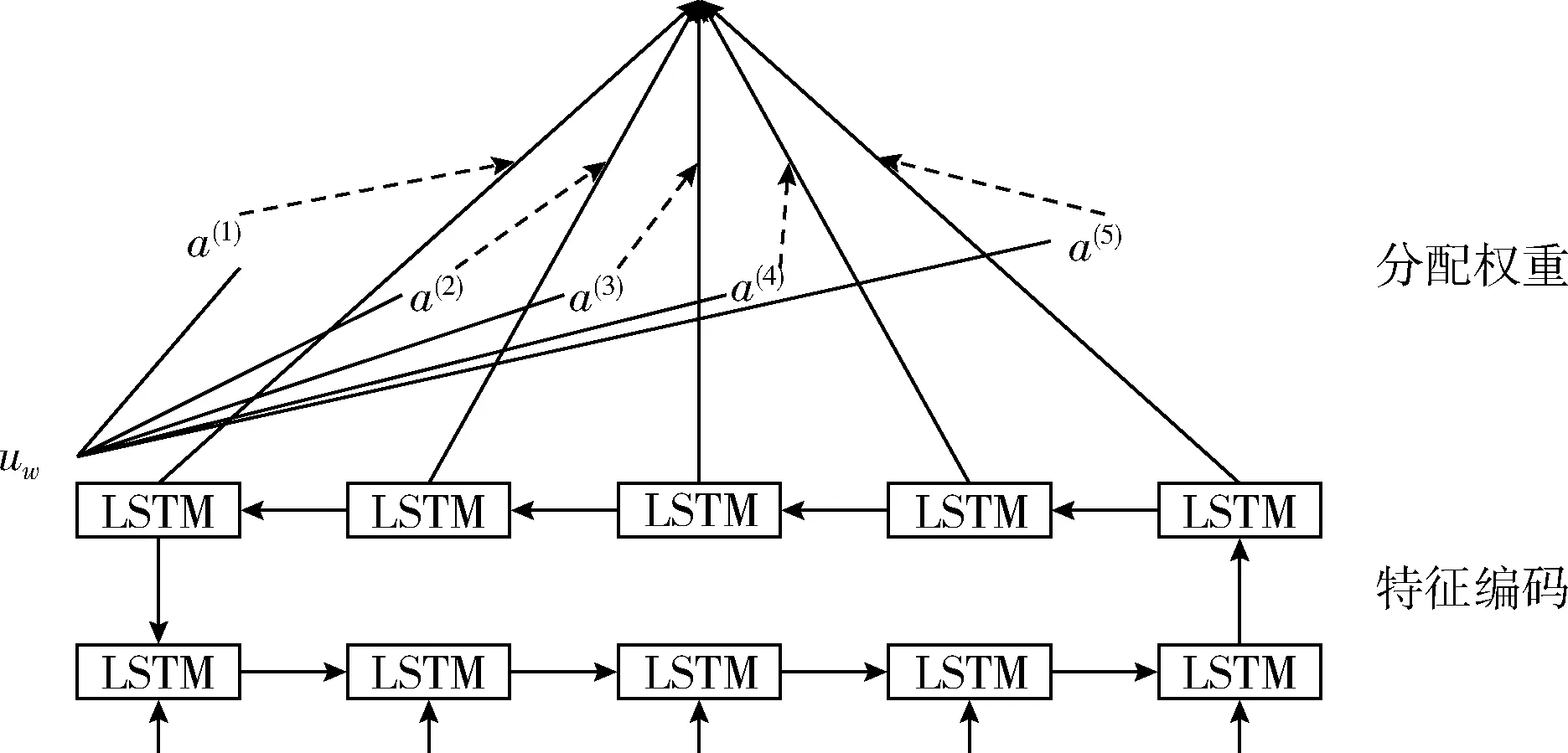
图3 基于注意力机制编码模型
2.4 模型优化层
将输入层的两部分分别喂给模型进行训练,经由biLSTM层和注意力机制层后,通过softmax层计算模型的交叉熵损失函数loss如式(12)~式(14)所示
(12)
(13)
(14)
其中,loss1是输入层没有扰动时模型的损失函数,lossadv是嵌入层扰动后模型的损失函数,把loss1和lossadv取平均值计算总loss,然后经过函数对loss进行优化,使其达到最小。
3 实验设置
3.1 实验数据设置与处理
本文文本分类使用的语料来自于维基百科的DBpedia数据集,有56万数据训练集,7万测试集,共15个类别,设置文本长度不超过100个单词,每个文本由结构化的3部分组成包括文本类别、标题、内容,由于是英文语料无需分词处理,对其去停用词处理。
3.2 实验环境设置
实验环境为python 3.5、64位,使用tensorflow框架,CPU处理器。
3.3 实验参数设置
通过预先训练好的biLSTM语言模型初始化词向量嵌入矩阵和模型权重,正向和反向的LSTM均具有512个隐藏单元,两个单向的LSTM共享词嵌入,其它超参数和单向LSTM相同,在数据集上单词嵌入维度256,带有1024个候选样本的softmax损失函数进行训练,优化函数使用AdamOptimizer,批量大小为256,初始学习率为0.001,每步训练的学习率为0.9999指数衰减因子,训练了 100 000 步,除了词嵌入外,所有参数都采用范数为1.0的梯度裁剪,为了正则化语言模型,在嵌入层的词嵌入部分中应用了参数为0.5的信息丢失率,在目标y的softmax层和biLSTM+Attention的最终输出之间,添加了一个隐藏层,维度是128,隐藏层的激活函数使用ReLU。
3.4 实验结果分析
把本文提出的方法(Ad-Attention-biLSTM)和注意力机制的长短时记忆网络(Attention-LSTM)、注意力机制的双向长短时记忆网络(Attention-biLSTM)在DBpedia数据集上进行实验,两个对比实验的超参数与本文模型参数相同。每次训练测试集取1%,训练集分别取总训练集的1%、2%、3%、4%、5%、6%、7%、8%、9%、10%,不同百分比下训练集数据量见表1。

表1 训练集数据量比例
(1)不同数据量对模型分类准确性的影响
训练集数据量分别是5600、28 000、56 000下模型(Ad-Attention-biLSTM、Attention-biLSTM、Attention-LSTM)的分类准确率变化如图4~图6所示。
从图4~图6中可以看出,当训练集数据从1%-10%变化的过程中,本文提出的方法准确率较高,且都在80%-96%之间,波动范围不大,当epoch大于5时,准确率均在90%以上,模型表现较好;而模型(Attention-biLSTM)的准确率变化范围在10%-95%之间,变化幅度较大,只有在epoch等于10时,模型的分类性能才较好,仅次于(Ad-Attention-biLSTM);模型(Attention-LSTM)的表现较差,准确率波动范围较大在5%-90%之间,训练集数据量为5600时准确率随epoch变化不明显且很低在5%以下,只有达到一定数据量56 000时随着epoch改变分类性能才有所提升;这是因为模型(Attention-LSTM)虽然实现了文本序列化,并融入注意力机制用不同的权重大小区分文本特征,但由于单向的LSTM只有下文语义信息,缺乏上文语义信息,当训练数据量较少时,文本向量特征表示高维稀疏,模型学习能力差,为了提升模型学习能力,把单向LSTM转变为双向LSTM即模型(Attention-biLSTM)时,准确率有了一定程度上得到改善,不仅学习到了不同距离的上下文语义依赖关系,模型的稳定性得到加强,但是以上两个模型在训练数据集较小的情况下文本特征冗余对分类性能仍有一定的影响,可能会导致分类错误,当在训练过程中对输入层词嵌入部分加入扰动进行对抗训练后,模型趋于稳定,在3个数据集下的准确率均较高;在不同训练集数据量下模型预测的分类准确率见表2,本文提出的方法分类准确率在不同训练集下均在90%以上,优于其它两种基本方法及模型CNN、CNN-LSTM、Word2vec。
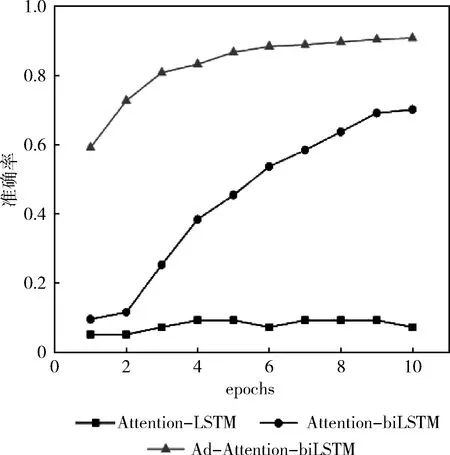
图4 数据量为5600
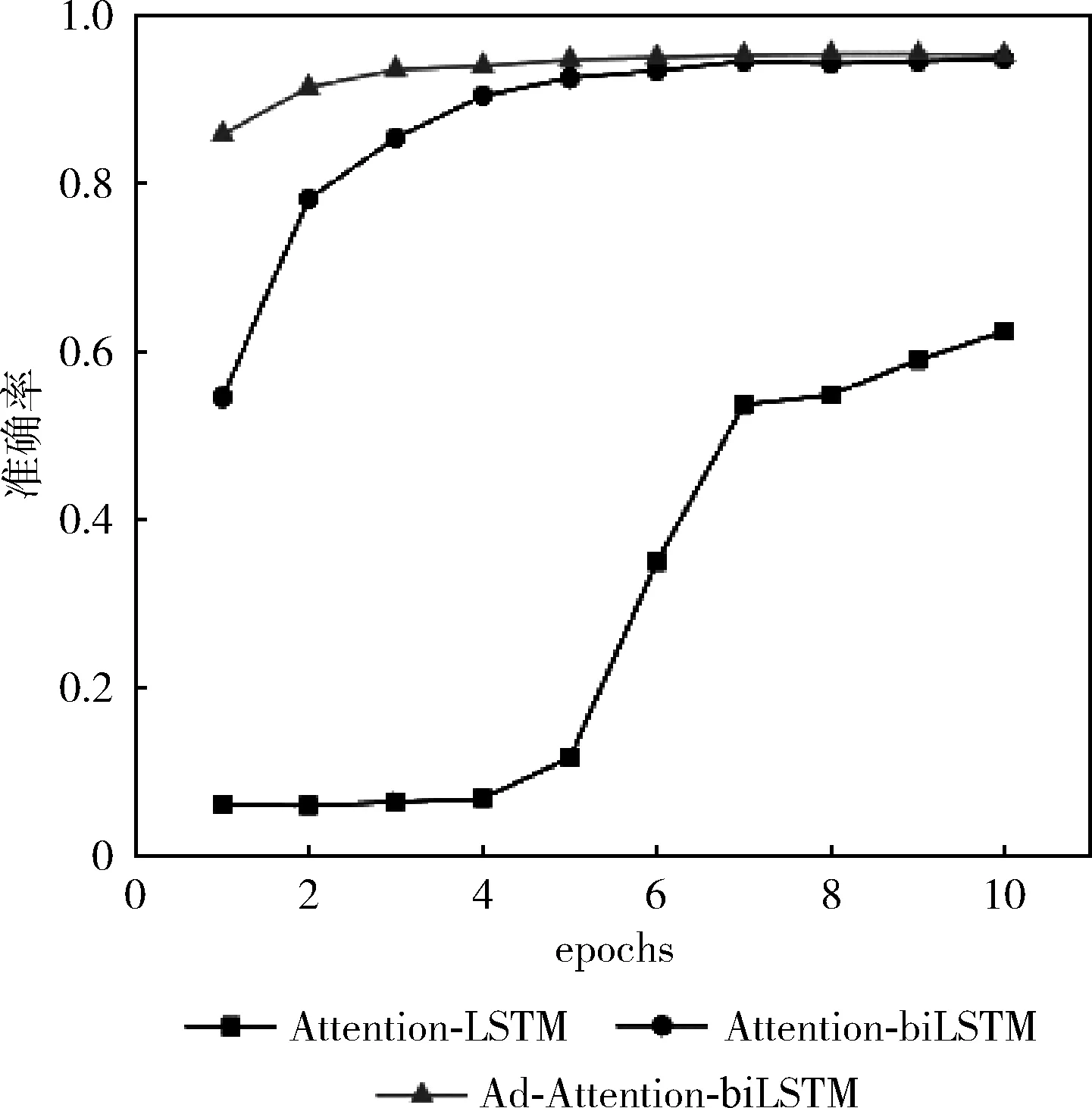
图5 数据量为28 000
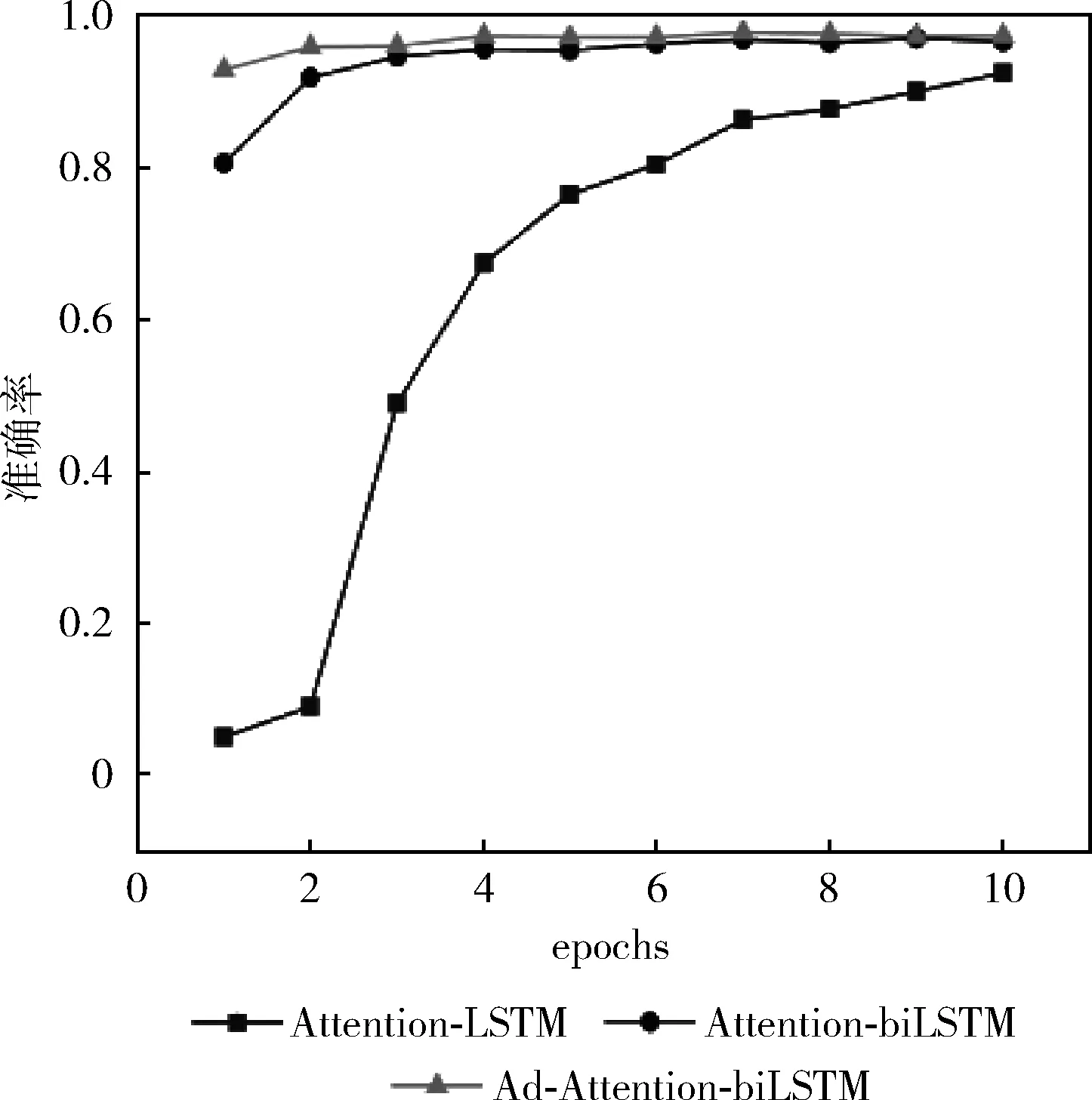
图6 数据量为56 000
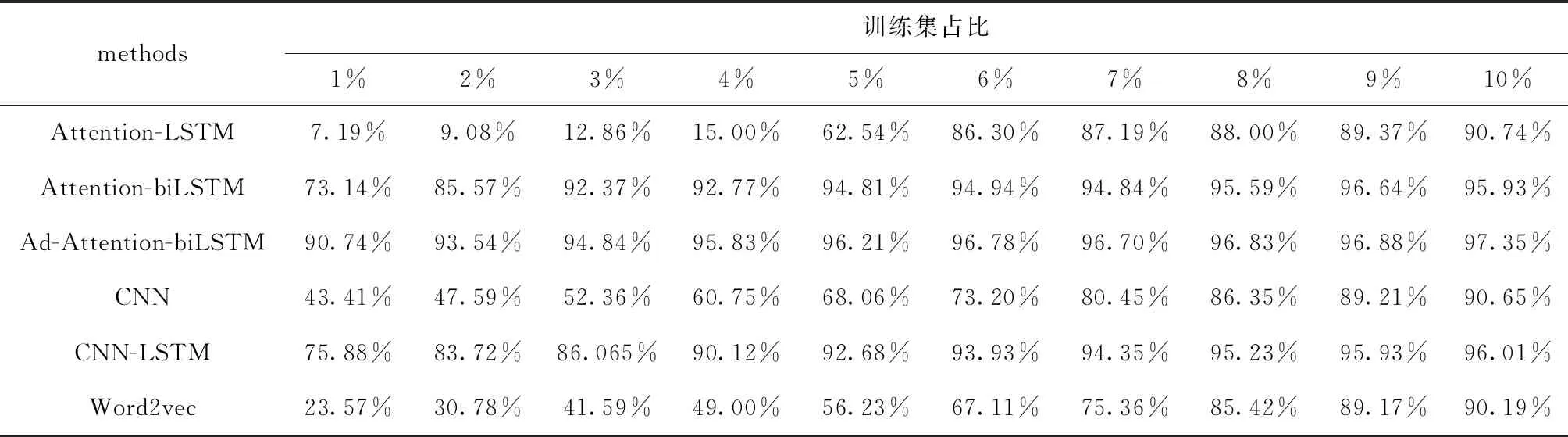
表2 分类预测准确率随训练集数据量的变化
(2)不同训练集数据量对模型收敛性的分析
本文通过计算扰动radv,添加到连续的词向量上得到新的词嵌入,模型接收新的词嵌入,得到扰动后的损失函数值lossadv,通过和原来的loss相加求平均值并优化,训练集数据量分别是5600、28 000、56 000时和模型(Attention-biLSTM、Attention-LSTM)的损失函数值变化对比如图7~图9 所示,当训练集数据量是5600时,Attention-LSTM的loss值变化较小随着epoch的变化最终稳定在0.20左右,Attention-biLSTM的loss值虽然一直处于下降趋势,epoch等于10时为0.15,但仍然很大,而本文提出的模型loss很小一直处于下降趋势;当训练集数据量是 28 000 时,Attention-LSTM的loss值没有太大变化,Attention-biLSTM的loss值变化明显,epoch等于10时为0.03,但是仍然高于本文提出的方法;当训练集数据量是56 000时,模型(Attention-biLSTM、Attention-LSTM)的loss下滑趋势明显且趋于稳定,最终Attention-LSTM的loss值在0.04左右,Attention-LSTM的loss值在0.02左右,而本文优化后的loss值最终越来越小趋于0;这是由于词嵌入部分加入对抗训练即正则化的方式,提高了词向量的质量,避免过拟合,添加扰动后会导致原来特征类别区分度改变,导致分类错误,计算的lossadv很大,但是lossadv的部分是不参与梯度计算的,模型参数W和b的改变对lossadv没有影响,模型会通过改变词向量权重来降低loss优化模型,提升鲁棒性。
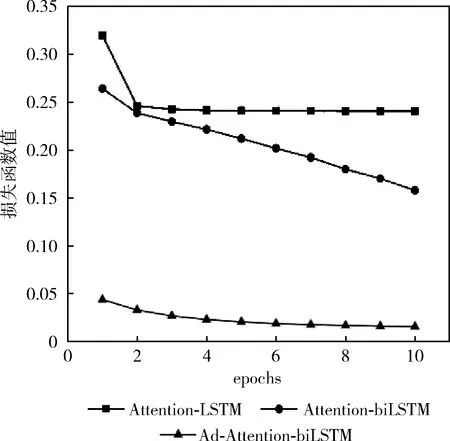
图7 数据量为5600
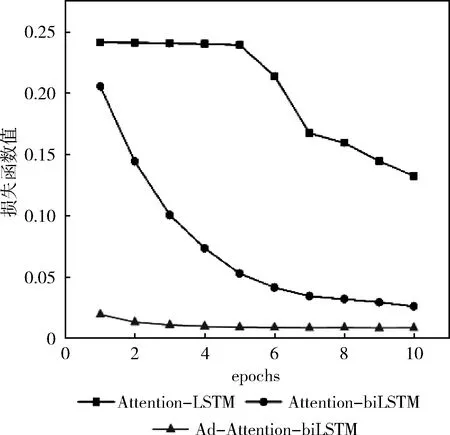
图8 数据量为28 000
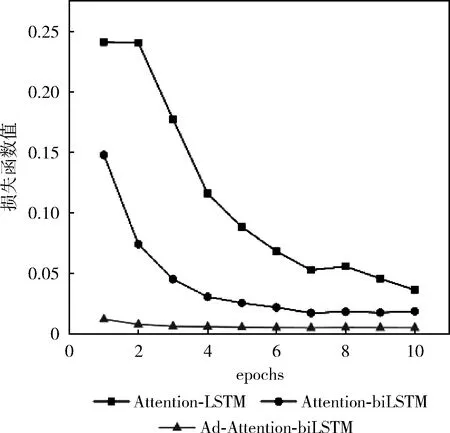
图9 数据量为56 000
4 结束语
本文提出了一种多层次的文本分类模型(Ad-Attention-biLSTM),在实验中,我们发现对抗性训练在文本分类任务的序列模型中不仅具有良好的正则化性能,还提高了词嵌入的质量,经过扰动后的样本参与到训练过程中,提升模型对扰动的防御能力,具有更好的泛化能力,在少量数据集上成功高效地训练了网络模型,有学者在训练过程中将随机噪声添加到输入层和隐藏层,为了防止过拟合,而本文提出的方法优于随机扰动的方法,但是仍然有不足之处。
本文只是在单一数据集DBpedia上验证了方法的有效性,后续研究考虑在不同的数据集上做实验;由于加入了词嵌入扰动层,准确率和损失值loss得到优化的同时,训练时间略高于其它方法。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
小雪花·成长指南(2022年1期)2022-04-09
数学物理学报(2021年4期)2021-08-30
北京航空航天大学学报(2021年7期)2021-08-13
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
数学物理学报(2019年4期)2019-10-10
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
