
基于典型样本的卷积神经网络技术
2020-04-24 08:55李晓莉李晓光
计算机工程与设计 2020年4期
李晓莉,韩 鹏,李晓光
(辽宁大学 信息学院,辽宁 沈阳 110036)
0 引 言
卷积神经网络(convolutional neural networks,CNN),是当前图像分类的主流技术之一。目前,基于CNN的图像分类常采用多尺寸Pooling提取不同级别特征,或将底层特征和高层特征结合方式,提高分类质量。然而,训练样本中包含大量非关键区分特征,甚至噪音。现有的CNN训练方法并未对关键特征和非关键特征加以区分。如果把含有这些部分的特征向量直接交由分类器,就需要大量训练样本才能将这些不重要部分的权重降低,网络泛化能力才会提高,分类准确率才会达到预期值。
本文提出一种利用典型样本指导修正CNN训练的卷积神经网络模型TSBCNN。同传统的CNN不同,TSBCNN不再直接采用所有训练样本,而是利用典型样本选取算法从训练集中选择一部分有“代表性”的样本,其包含了类别下的典型特征。TSBCNN利用典型样本训练“经验修正网络”(HNN)。HNN的作用类似于大脑皮层中上层反馈神经对前馈神经进行关联、比较的过程。当采用普通样本进行训练时,TSBCNN利用HNN强化和修正CNN特征向量,其修正过程可以理解为对原特征向量进行局部强化操作,将具有更高区分能力的特征强化保留,弱化区分能力差的特征,进而达到利用少量训练获得关键特征,加快模型训练收敛的同时防止模型过拟合。CNN和TSBCNN的训练过程如图1所示。

图1 CNN和TSBCNN训练过程
本文主要贡献在于:①提出一种典型样本指导修正下的卷积神经网络模型。给出了神经网络模型结构以及训练方法;②提出一种典型样本选取算法,用以获得HNN训练集;③在MNIST数据集上的实验结果表明TSBCNN具有更好的训练效果。
1 相关工作
特征在机器学习中起到至关重要的作用,仅仅单纯依靠增加特征数量未必会带来网络性能的提升。一旦网络参数庞大,数据量未能达到足够规模,就会导致学习不充分,无法确保对关键特征有效选择,并且无关冗余特征还会产生过拟合等问题。为了减少这种不利影响,需要进行有效特征选择,以往研究普遍关注网络最后的分类性能,对特征筛选这一重要环节的控制往往相对较少。Lu HY等[1]提出了卷积神经网络增强特征选择模型,利用一些特征评价方法来确定哪些特征更为重要,有效增强了神经网络的特征选择能力并验证了该模型的有效性。Li H等[2]通过在图像的显著度探测问题中,将底层特征作为全连接层后高层特征的补充一起合并到神经网络中,有效地提高了网络对图像中显著物探测的准确率。高低层特征融合可以在一定程度上增强特征的代表性,但融合特征中仍然涵盖了大量无用、冗余特征部分。Alexey Dosovitskiy等[4]提出学习通用特征,对随机采样的“种子”图像块的各种变换形成每个代理类来得到通用特征。通用特征不等于关键特征,对网络训练速度并未起到提升效果。在监督学习中,Cross-entropy loss和Softmax并没有促进网络学习类内更具有辨识性的特征的功能,Weiyang Liu等[7]提出了一个广义的L-Softmax loss,促进了对类内紧凑、类间可分离性特征的学习,实验结果表明通过L-Softmax深度学习的特征更具辨识力,同时对4个基准数据集有很好的实验效果。可见,关键重要特征对图像分类效果有非常重要的作用,因此合理利用这点是有效提升网络性能的一种重要途径。
样本在特征提取阶段中占有非常重要地位,训练样本是否具有代表性,决定了网络的学习效果。Huang等[10]提出了一种选取典型样本与新增样本结合学习的增量方法,利用初始训练样本集训练得到一个初始模型,然后根据后验概率对样本排序,再利用不同规则在各类中选取少量典型样本。Duan等[11]针对包含少量样本数据集情况,采用数据增强变换来扩充样本范围以提高网络识别准确率和鲁棒性。可见,对样本的合理有效利用可以在训练少量样本的基础上最大程度地学习到关键区分特征。
2 TSBCNN卷积神经网络
我们认为,CNN训练中的过拟合、训练收敛慢等问题的主要原因之一是在每次权值调整中,调整量只与网络输出误差有关。大量的神经科学研究结果表明,大脑皮层存在大量的前馈连接和反馈连接,大脑皮层中每个区域都在不断在上层的反馈信号和下层的前馈信号间进行比较,也就是说大脑皮层不断进行历史经验信息(反馈)与当前感知信息(前馈)的对比,两者的交集就是我们所感知的事物。
在人工神经网络在训练过程中,如果能够利用历史经验来指导修正训练过程,根据数据特征区分能力大小,有选择的训练,将能够降低模型过拟性,并提高训练效率。如图2所示,MNIST数据集同类数据具有共同重要特征,如图中圈中区域对于数据区分起到主要作用,而非圈中区域作用较低。目前研究工作中的训练方法,视数据每个部分同等重要,仅通过误差传导来调整权值。如果在训练时更关注主要特征的学习,则可以大幅降低网络的过拟,并提高训练效率。

图2 数字5及对应强化部分
基于该思想,本文提出一种基于典型样本的卷积神经网络TSBCNN。在CNN的基础上,TSBCNN平行增加了一个前馈输出修正网络,这里称为经验修正网络HNN,经验网络的输出为“强化因子”。通过选取少量的典型样本训练经验网络,以获得训练数据的典型先验特征。在CNN训练中,利用强化因子,对前馈输出进行局部强化处理,并根据强化后的CNN输出误差来调整CNN前馈层。TSBCNN的网络结构如图3所示,包括两个部分:卷积神经网络CNN以及经验修正网络HNN。HNN输出Ya对CNN输出Y0进行强化,强化函数为按位乘积,即Y*=Y0⊙Ya; 对强化输出Y*利用Softmax进行分类,分类向量为Yout。

图3 TSBCNN结构
TSBCNN所涉及的公式如下,公式符号描述见表1
Y0=CNN(X)
(1)
Ya=HNN(Xa)
(2)
Y*=Y0⊙Ya
(3)
(4)
(5)

表1 符号描述
3 TSBCNN训练
TSBCNN训练分为两个部分:①选取典型训练样本TS,利用梯度下降法训练HNN;②对全体训练样本,固定HNN,训练CNN。在选取典型训练样本时,TSBCNN采用了像素频度分布直方图来刻画数据特征分布,并设计了一个样本相似度函数用以度量样本与典型样本基于特征分布的相似程度。TSBCNN典型样本选取过程如下:
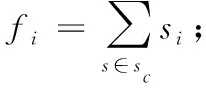
(2)令Hist’为Hist中频度最大的n′像素位置频度集合,其中n′=θ*n,θ为自定义截断阈值参数。这里将Hist’作为典型样本的特征表达;
(3)对类c中训练样本s∈sc, 计算s与Hist’的相似度Sim公式定义如下
(6)
对于给定的相似度阈值参数η, 当Sim(s,Hist’)>η时,将样本s归为类c的典型样本TS。
(4)选取典型样本数量过少不利于HNN学习关键特征,影响后续强化因子的准确性;选取过多会增加网络训练总时长。从实验角度建议典型样本数不要超过全量样本的35%左右。
4 实验与分析
4.1 选取数据集与实验过程参数设置
本文采用MNIST数据集和HWDB1.1数据集作为实验数据集。MNIST训练集共60 000个样本,其中包含55 000行的训练集和5000行的验证集。测试集共10 000个样本。HWDB1.1中文手写数据集,包括汉字分类3755种,实验选用其中最常用的50个汉字作为实验对象。数据集概况见表2。在MNIST数据集上选取典型样本过程中,“0”标签像素频度直方图Hist如图4所示,横轴表示部分像素位置,纵轴表示图像二值化累计频度值。通过两个阈值参数:截断阈值参数θ、相似度阈值参数η,并根据式(6)得到该类下所有典型样本。
实验分析了TSBCNN在MNIST数据集和HWDB数据集上运行效果,比对TSBCNN与常规CNN准确率以及损失函数的效果差异。

表2 数据集概况
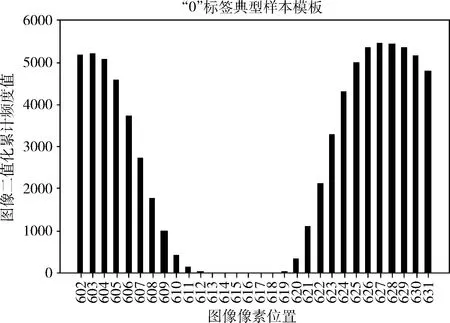
图4 “0”标签样本部分像素频度分布直方图
4.2 实验结果与分析
4.2.1 MNIST实验结果与分析
TSBCNN与CNN准确率对比如图5所示,典型样本数过少会造成HNN经验网络对关键特征学习不足,影响强化因子准确性,导致收敛过程波动较为明显,后续 TSBCNN 准确率也不会太高。随着典型样本数增加,可以更好地学习关键特征,网络收敛速度明显加快并且波动很小,准确率不断提高。当典型样本数达到2000时,网络在训练18次左右时,TSBCNN准确率已达到预期值,网络收敛速度远高于传统CNN。TSBCNN与CNN损失函数对比如图6所示,最终损失函数收敛速度也明显高于CNN。MNIST数据集的特点是分类少(10类),样本多(每类约6000左右),同标签下样本区别性不大,样本关联性较强,因此随着典型样本数的增加,可以更好捕获样本的“典型性”。

图5 MNIST上准确率对比

图6 MNIST上损失函数对比
4.2.2 HWDB实验结果与分析
TSBCNN与CNN准确率对比如图7所示,随着典型样本数增加,网络收敛速度加快并且准确率不断提高。与此同时,TSBCNN与CNN损失函数对比如图8所示,随着典型样本数增加,损失函数值不断降低。HWDB数据集的特点是分类多(50类),样本少(每类约240左右),恰巧与MNIST截然相反。由图7、图8可以看出,随着典型样本数的增加,虽然网络准确率得以提高,损失函数值呈下降趋势,但是二者却未能达到预期值。原因在于汉字手写数据集HWDB分类多,样本少,区别性很大且关联性不强的数据集,TSBCNN的效果不会高出传统CNN太多。因此,针对这种类型的数据集可以考虑是否采用TSBCNN 网络。

图7 HWDB上准确率对比

图8 HWDB上损失函数对比
5 结束语
本文主要针对传统CNN提取样本特征时会包含大量非关键区分特征使得训练存在模型过拟合、训练收敛慢等问题,提出利用少量典型样本来指导修正CNN训练的卷积网络TSBCNN,目的是让CNN在训练过程中主要学习关键特征,进而提高网络训练收敛速度并在一定程度上起到减少过拟合作用。在MNIST数据集和HWDB数据集上的对比实验结果表明,对于数据集中同一类别下样本较多且样本之间差异性不大的数据集,TSBCNN网络有很好的提升效果。对样本相对较少且样本个体差异比较大的数据,提升效果并不明显。未来将进一步研究如何在样本关联性不强、样本差异性大情况下,提高网络训练效率以及准确率。
猜你喜欢
小学生作文(低年级适用)(2022年10期)2022-10-31
甘蔗糖业(2022年2期)2022-05-22
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
湖南林业科技(2021年3期)2021-12-02
现代临床医学(2021年1期)2021-01-26
科技创新与应用(2020年6期)2020-02-29
北京理工大学学报(2016年6期)2016-11-22
系统工程与电子技术(2016年7期)2016-08-21
中国农业信息(2013年10期)2013-09-05
中国医药指南(2013年16期)2013-07-07
