
机器学习情感分析方法改进研究
2020-06-01 05:14李鼎
西安航空学院学报 2020年1期
李 鼎
(西安航空学院 人事处,西安 710077)
0 引言
随着互联网的飞速发展,尤其是自媒体(如微博、论坛、贴吧、社区等)的出现,改变了传统媒体一枝独秀的局面。传统媒体是通过广播形式向用户单方向传播信息,而现代互联网媒体时代,人们不仅是信息的被动消费者,更多的则是信息的生产者,人们主动参与网络互动,比如就某一话题发表自己的观点,参与时事讨论等。随着网民数量的急剧攀升,随之而来的是海量数据的产生。能够快速地从网络海量信息中提取出网民的情感倾向,及时掌握网民对某一事件的态度和看法,已经成为重要的研究课题。
现今的网络数据来源多样,我们可以通过诸如新浪微博、大秦论坛、百度贴吧等主流社交媒体获得针对特定话题的语料信息,并对其进行整理分析,从中得到有用的信息加以利用。然而,现存的情感分析技术存在着这样或那样的缺点,基于文本的情感分析方法往往对于特殊场景的判断不准确;基于机器学习的情感分析方法往往需要大量丰富的数据集,准确率难以得到保证。
本文基于这样的现实背景,研究了一种提高情感分类准确率的方法,使情感分析的结果更加准确。
1 情感分析方法研究
1.1 基于正向、负向和中性的情感词典情感分析方法研究
采用五组不同的数据文本进行实验,数据来源于新浪微博、大秦论坛等知名微博和论坛,每组1000条数据。经过程序自动运行结果和手工标注不同数据组的结果进行比较,对于不同数据组,使用基于情感词典[1]的情感分析方法进行情感分析[2-3]得到的结果准确率如图1所示。
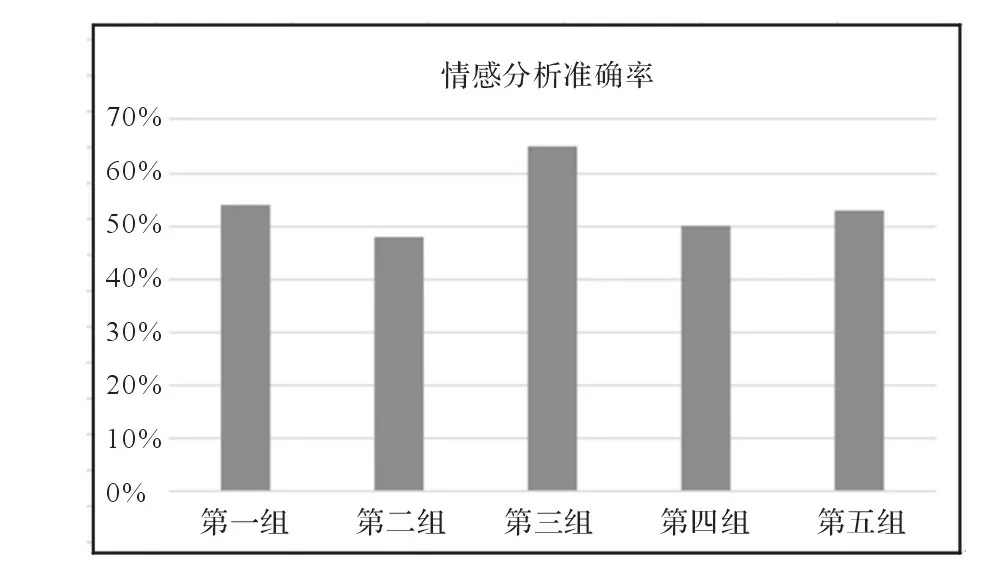
图1不同数据组情感分析准确率表示
由图1可以看出,第一组、第二组、第四组和第五组的实验准确率都在50%左右,而第三组的准确率却高出了很多,达到了65%。第三组数据是从网上下载的评论集中抽取的数据,而其他数据都是爬虫抓取的网络数据。本文基于情感词典的情感分析算法,采用切词后对于得到的词组进行关键字匹配,并结合词性权重分配的方法实现,究其原因应该是网络评论集合中的评论句式不像爬虫抓取的网络数据那么杂乱无章,用到的评论词倾向性比较明显,大部分评论句式符合情感算法中考虑到的情况,所以准确率相对提高了很多。然而对于网络爬虫抓取到的普通数据,往往杂乱无章,用户的遣词用句并不是特别严谨准确,所以很多句子并不满足情感算法设计的句子结构,因此准确率较低。从结果来看,使用本文实现的基于情感词典的情感分析算法对于网络爬虫抓取到的数据进行分析,准确率较低,需要进一步改进。因此考虑到使用情感词典构建相关数据集的情感特征,并结合机器学习算法作为分类器进行情感分类,看能否提高分析准确率。
1.2 基于正向、负向和中性的机器学习情感分析方法的研究
在基于机器学习的情感分析方法研究中,选择研究KNN[4-6]和SVM[7-9]情感分析方法,实验采用数据集包含且大于1-1数据集,并进行初步的人工筛选[10-11]。筛选过程包括以下方面。
(1)过滤掉其中噪音较大的文档。这里的噪音指的是句子中含有太多二义词,或者文档中有太多词语的含义上下文相关。由于噪音过大会导致分类准确率下降严重,故在此选择中去除这部分文档。
(2)剔除其中字数极少的文档。文档中的字数过少,比如只有一个字,这会导致对其通过向量空间模型后,向量表示中绝大部分维度的值为零,引起向量稀疏的问题,导致分类的准确率下降。
(3)再进行人工标注文档类别,要求标注的质量必须较高,即人工判定的准确率要较高,以免引起过大的人工误差。
最后,在实验中,通过TF-IDF等文本向量化方法对标注过后的文档进行向量空间建模,得出表示文档的文档向量。实验中得到文档向量如图2所示。

图2实验文档的向量空间模型表示
需要说明的是,由于篇幅有限,且为了将文档向量表现清楚,实验中过滤掉了向量计算中后面所有维值为零的那些维度,图2中就展示了这种处理。然而在实际计算中,必须将所有向量统一维度,以方便后续计算处理,不够维度的需补上在前期处理中故意略去的零值。
从不同训练数据集和不同训练数据量两方面进行基于机器学习的情感分析方法研究,因为训练数据对于机器学习方法影响较大,首先研究不同训练数据量下KNN和SVM情感分析方法的准确率,实验选择同一组数据集进行准确率检测。如图3所示。
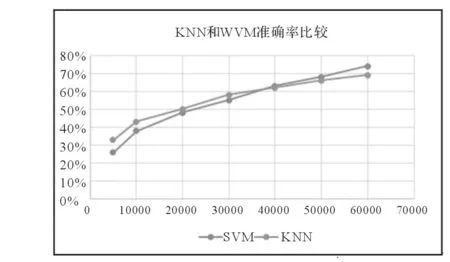
图3不同训练数据量KNN和SVM情感分类准确率
由图3可以看出,随着训练数据量的增大,KNN和SVM的准确率都有明显提高。在数据量小于10000时,KNN的准确率稍好于SVM,且在数据量较小时,KNN的比较速度相对较快,效率更高。但随着训练数据量的增加,SVM的准确率提升更明显。在训练数据量达到40000时,两者准确率几乎一样;而在训练数据量到达50000时,SVM的准确率明显高于KNN。由此得出结论:从准确率和效率两方面综合考虑,在训练数据量小于10000时,KNN效果明显好于SVM;在训练数据量大于50000时,SVM的效果明显好于KNN。训练数据量在10000到50000,两者准确率相差不大,随着训练数据量增大,SVM准确率稳步提高,而KNN准确率提高的速度逐渐变缓。在此提出可将KNN和SVM的结果做线性结合看能否提高准确率,而且随着训练数据的增加,SVM占的比重应该逐渐增大。
其次,使用不同的数据集来进行情感分析算法的准确率检测。在此使用50000条训练数据得出的KNN和SVM情感分析方法对五组数据进行倾向性分析,并检测其准确率,如图4所示。
由图4可以看出,使用SVM方法对不同数据组进行情感分析,准确率在64%到70%之间,平均在68%左右,比较稳定。使用KNN方法对不同数据组进行情感分析,准确率在62%到百分之69%之间,平均在65%左右,也比较稳定。说明机器学习方法在本文不同数据集上的情感分类准确率较为稳定。
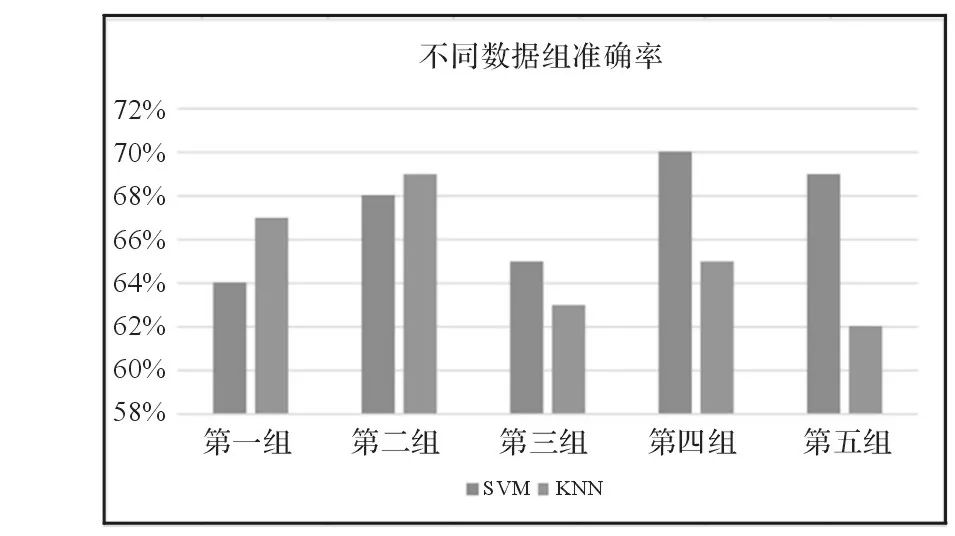
图4不同数据组情感分析准确率表示
2 改进方法研究
使用情感词典进行文本的情感分析,其主要特点是对文本的情感分析直接作用在了词语的倾向性上,粒度细,分析精准,但同时也受到了自然语言处理技术的限制,尤其是受到汉语中某些词语的意思上下文影响较大的困扰,比如在一句话中某个词语所表达的意思可能到另一句话中却完全相反,这就增大了这种分析方法的误差和难度。因此,总体来说,基于情感词典的情感分析效果一般。然而汉语的句式变化多样,很难把各种句式的表现形式都做出相应的情感分析方法[12]。因此,对于符合基本句式的句子使用情感词典分析方法,对于不符合基本句式的句子则使用机器学习情感分析方法,最终使用情感词典与机器学习相结合的方法得出文本的情感倾向。
在机器学习方法的研究[13]中,KNN算法是一种无监督的机器学习方法,具有领域无关性的特点,这对于跨领域的数据分类是个很好优势,然而其只是单纯依靠向量间的相似程度进行分类,没有统计信息,而且初始化簇中心采用随机的方式很容易造成误差,这就导致KNN分类算法的准确率不是很高。而SVM需要进行模型训练,是一种有监督的机器学习方法,具有统计特性,且具备领域相关性,但对于未在训练文本中出现的特征难以纳入训练后的模型文件,也就是说其预测准确率十分依赖于训练样本,训练样本的质量和覆盖率会很大程度上影响到SVM的预测准确率,因此会出现预测不准的问题。由此可见,单纯使用一种机器学习方法分析难以得到十分高的准确率,将KNN和SVM两种方法相结合是一种提高情感分析准确率的可选方案。
KNN基本没有训练时间,采用一个新的样本记住就可以了。但预测时间却可能需要很久。如果一路上记了100万个样本,那就要和100万个样本算距离,再排序出前K个最近的样本,即使用堆排序或者其他改进过的排序算法,只在乎前k个顺序不再往下排序,也还是需要k*log(n)数量级的排序运算,特别是预测大量样本之后的样例。
SVM训练时间相对久一些,不过是在可接受的时间内。预测时需要对所有训练样本做核函数运算,虽然不能在很短的时间内计算出结果,但计算时间也在可接受范围内。另外,由于核函数的存在,有足够量的大数据,预测精度会稍高一些。
基于以上的实验研究,本文通过研究各种情感分析方法的优缺点,使用情感词典方法以及KNN和SVM相结合的方式进行情感分类,结合两者的优点,摒弃各自的缺点,将两者优化使用,以期提高情感分类的准确率。然而这就涉及到两者之间的加权方法,本文采用以下公式来计算两者加权后的文本情感标签。计算公式如下:
EEE=σE1+(1-σ)E2
(1)
式中,E表示文档的分类后加权值;E1表示基于SVM算法得到的分类标签;E2表示基于KNN算法得到的分类标签;σ表示加权系数。
通过以上分析,确定了结合KNN和SVM的加权公式,然而,公式中的参数加权因子 的取值还未知,结合上一节对情感分析算法准确率的研究,并且考虑到KNN以及SVM的优缺点,采用分段线性结合的方法改进情感分类方法。当训练数据量小于10000条时σ取0,即使用KNN的方法进行情感分类,因为KNN基本没有训练时间,采用一个新的样本记住就可以了,数据量较小时预测也会较快。而SVM在数据量较小时准确率较低,而且训练时间相对久一些。当数据量大于50000条时σ取1,即使用SVM的方法进行情感分类,因为数据量较大时,使用SVM方法的准确率会稍高一些,而且预测时间会比使用KNN方法快。当数据量在10000到50000之间,σ取(n-10000)/50000,这里n为训练数据量,即随着数据量的增加,SVM方法的比重逐渐增大,KNN方法的比重逐渐减小。
公式(1)通过对KNN和SVM各自得出的分类标签进行加权计算,结合两个方法判断出最终的结果分类,得出分类后的加权值E是一个小数,还无法判断最终结果分类标签,这就需要进行下一步处理。
计算得出分类后的标签值E后,由于E是小数,于是本文采用二次处理,再次根据公式(2)计算每个情感类别的类别标签和E的一纬欧式距离:
Distance(i)=||Labeli,E| |=|Labeli-E| (2)
Distancemin=mini(Distance(i) (3)
式中,Distance(i) 表示类别标签与加权后标签的距离;Labeli表示情感类别标签;E表示KNN和SVM分类结果加权后的标签值。
得出Distance(i)后,由于结果必然为正数,这时我们可以采用比较Distance(i)与每个类别标签距离的相对大小来进行类别指定,即如果算出的Distance(i)是所有E与类别标签距离中的最小值,则将结果标签赋值为i。本文根据公式(3)得到最小距离的类别标签作为文档的情感分类标签,因为在这些距离中一定存在最小值,因此结果分类标签必然是唯一的。
3 改进后的情感分析方法准确率
经过程序自动运行结果和手工标注的结果进行比较,得出不同训练数量不同的方法准确率变化,如图5所示。
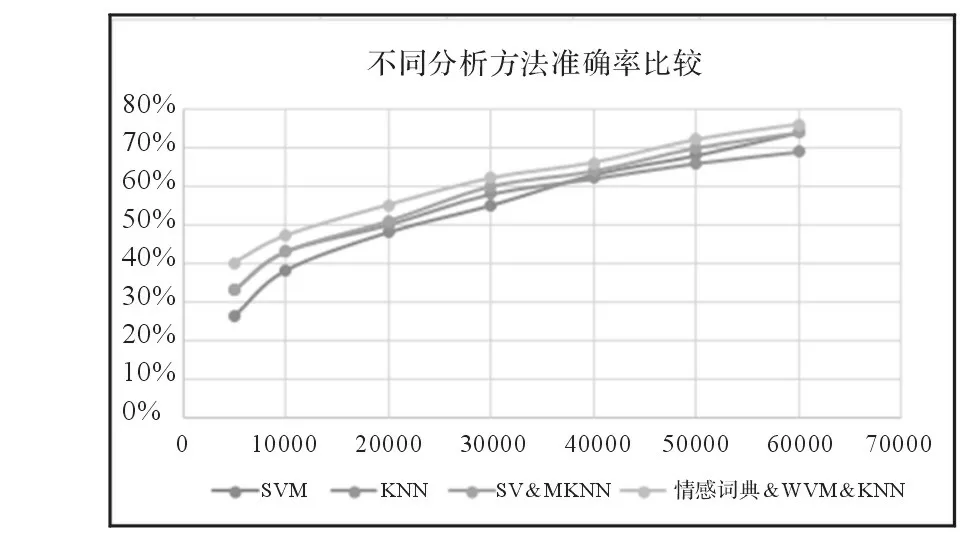
图5分类准确率变化图
显然,由图5可以看出,在训练数据量较少时,机器学习方法的准确率较低,而情感词典的方法可以适当弥补机器学习方法准确率较低的问题,提高准确率。而随着训练数据量的增加,其准确率得到相应提升,在训练数据量在10000到50000之间时,将SVM和KNN方法线性结合,相比于单独使用KNN或者SVM方法,提高了机器学习方法准确率3-4个百分点。同时结合基于情感词典的情感分析方法,相比于单独使用KNN或者SVM方法准确率提高了5-6个百分点。当数据量到达50000时,SVM的准确率达到了较好的效果,同时与基于情感词典的方法相结合,相比于单独使用KNN或者SVM方法准确率仍提高2个百分点。实验结果表明,使用情感词典以及SVM和KNN加权方式比单独使用SVM和KNN方法得到的准确率有一定提升。
4 改进前后对比
实验表明,本实验较单独使用领域无关性的KNN分类器所得到的准确率平均提升达到4个百分点,提升效果明显。
实验表明,本实验的分类准确率较单独使用SVM进行训练预测的分类准确率平均提升为3个百分点。
综上所述,本文提出的结合情感词典以及SVM和KNN加权方式来进行情感分类的方式是有效的,在分类准确率方面,比单独使用SVM和KNN提升效果明显。
结合实验结果,笔者对本文提出的结合情感词典以及SVM和KNN加权方式的改进方法使准确率得以提升的理论原因进行分析,本文认为准确率提升的理由有以下方面。
(1)由于SVM是基于统计学习理论的分类方法,在预测前必须进行模型的训练。然而,对于未在训练样本中出现的特征便在训练结束后的模型中没有体现。当进行预测时,如果出现模型中未出现的特征时,很大概率上会出现预测失败,这就是单独使用SVM时准确率得不到提高的一个重要原因。而KNN没有训练过程,不依赖已经有的统计信息,恰好弥补了SVM的缺点。
(2)由于KNN是单纯依赖文档向量间的相似度距离来进行文档的分类,并且在做初始化簇心时采用随机算法来进行指定,这直接导致了分类结果的无法预测和准确率的低下。而SVM没有随机化的过程,恰好弥补了KNN的部分缺点。
(3)在本文提出的加权公式中,可以通过加权系数的变化进而调整SVM和KNN在分类方面的贡献率,因此可以通过实验获得比较理想的加权系数,得到最好的分类效果,并且将SVM和KNN相结合提高分类的准确率。
(4)由于汉语句式的特殊性,能够满足情感词典情感分析算法的简单句式,因此通过情感词典算法分析出的情感值会比较准确,所以,采用情感词典、KNN和SVM三者结合进行情感分类的方法,可以使情感分析的准确率明显提高。
5 结语
本文通过对采用情感词典的情感分析方法以及基于机器学习的情感分析方法的情感分析准确率的研究,发现使用传统情感分析方法准确率较低,分析其可能存在的原因后提出了结合情感词典、KNN和SVM来进行情感分类的方法,并提出KNN和SVM两者的加权公式,然后对改进的方法通过大量实验来检测其效果。实验结果表明,改进后的情感分析方法相比于单独使用KNN或者SVM方法准确率提高5%,因此通过情感词典以及SVMT和KNN加权方式相结合的方式来提高情感分析的准确率是可行的。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
分析化学(2019年3期)2019-03-30
软件导刊(2018年3期)2018-03-26
