
基于Scrapy的新闻网页数据抓取设计
2020-06-10 07:41秦亚红普措才仁
电子技术与软件工程 2020年4期
秦亚红 普措才仁
(西北民族大学数学与计算机科学学院 甘肃省兰州市 730030)
中国新闻网每日及时发布新闻资讯、新闻事件动向,其中蕴含的数据信息量不言而喻[1]。加之近年来,研究人员不断地对新闻数据进行研究,文献[2]采用网络爬虫、中文分词、向量空间模型、文本聚类等技术设计自动采集新闻并能聚类的系统;本文则使用网络爬虫技术抓取中国网文化专题下的热点新闻数据。
1 网络爬虫
网络爬虫根据实现的技术和系统大致分为通用网络爬虫、主题网络爬虫、增量式网络爬虫和深层网络爬虫[3]。Scrapy是一个为提取网页中结构化数据而设计的爬虫框架,通过Scrapy框架可以快速搭建一个简易的网站数据爬取程序,并根据自身需要对其进行修改,以满足数据抓取需求。其框架内各组件工作原理如图1所示。
由图1可以看出Scrapy框架的工作原理以及各组件之间的协作。组件中的数据流为:Scrapy Engine(以下简写为SE)从Spiders中获取初始url并请求Schedule调度,在获得要爬取的url时,通过Downloader Middlewares(以下简写为DM)转发给Downloader,生成页面响应后返回给SE,此时SE将收到的响应通过Spider Middlewares发送给Spider,Spider处理页面响应并将爬取到的Item数据以及新的url请求返送给SE,SE将Item数据传送到Item Pipeline,url请求交给Schedule,如此循环往复,直至Schedule中没有满足条件的url请求,程序停止。
2 网页结构分析
爬取任何一个网站前都需对网页结构进行分析,找出目标数据在网页元素中的位置、新闻详情页链接变化规律、网页数据开始抓取区域等。现对相关网页结构分析如图2。
图2中显示新闻网页内容主要分布在div class=”main2”下的left_box和right_box元素中。在爬取时,根据网页中所需目标模块,进行链接过滤,以免爬取不必要目标模块中的新闻数据。
点击进入hot_list区域中任意链接进行新闻详情页面结构分析如图3。
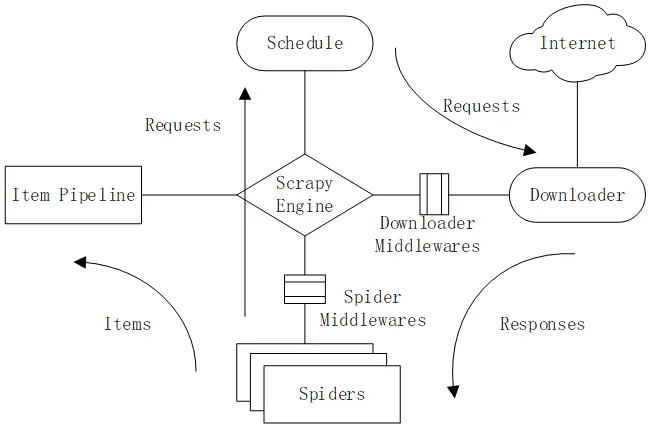
图1:Scrapy框架工作原理

图2:新闻列表页面结构
由图3可分析新闻详情页面网页结构:新闻标题在网页元素中的位置为div class=”left_box”中的h1标签中;新闻内容所在位置为div class=”center_box”中的p标签中。使用xpath helper工具(Chrome浏览器插件)定位列表页热点新闻区域与详情页中新闻标题、内容等数据在网页元素中的位置,程序中使用xpath语句提取新闻标题与内容数据。

图3:新闻详情页面结构
3 新闻数据爬取
Scrapy使用Twisted这个异步网络库来处理网络通讯,结构清晰,并且包含了各种中间件接口[4]。Scrapy框架进行数据抓取工作主要在Spider.py中实现:给定初始url,通过rule规则进入特定url进行自定义目标数据抓取工作。Spider.py伪代码如图4所示。
框架中主要模块文件Spider.py完成需编辑、修改相关模块如:Pipeline.py文件,连接MySQL数据库,使用SQL语句将Item中所传递的数据字段插入到数据表中;settings.py中设置下载延迟、修改ROBOTSTXT_OBEY为false等。此外,编写程序启动文件start.py,避免调试程序时输入命令行。

图4
4 实验结果
部分实验数据如图5所示。
5 总结
以上实验阐述了中国新闻网文化专题页面数据抓取的分析、实现以及存储方法,并成功抓取到目标数据,为新闻数据获取提供有效、可行的方法。
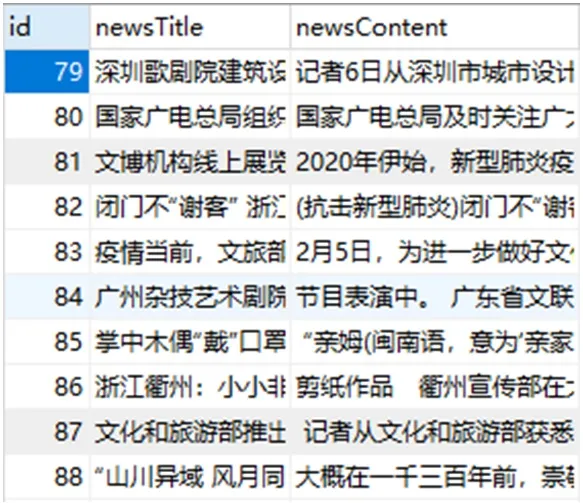
图5:部分实验数据
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
活力(2019年22期)2019-03-16
活力(2019年22期)2019-03-16
电子制作(2018年10期)2018-08-04
电子测试(2018年1期)2018-04-18
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
喜剧世界(2016年9期)2016-08-24
电子测试(2015年18期)2016-01-14
