
基于改进的Random Subspace的客户投诉分类方法
2020-07-06 13:35杨颖,王珺,王刚
计算机工程与应用 2020年13期
杨 颖,王 珺 ,王 刚
1.合肥工业大学 管理学院,合肥 230009
2.过程优化与智能决策教育部重点实验室,合肥 230009
1 引言
随着电信业的飞速发展,运营商所提供的终端服务越来越丰富,客户对服务质量的要求也逐步增高,从而导致了客户投诉量的不断增大[1]。运营商需对每条客户投诉进行处理,而处理投诉中最重要的一步则是对投诉原因进行定位。快速准确地找到投诉原因后才能及时给出有效的解决方案。投诉原因定位是一个典型的分类问题。采用传统的人工分析的方式进行客户投诉处理人力成本高[1],处理效率低下且存在较高的误判率[2]。而投诉处理的结果和及时性都对客户满意度有着重要影响[3]。为了准确定位投诉原因,需对客户投诉中大量的通讯状态和投诉文本构成的高维数据进行处理。高维数据的处理已经成为一个重要的问题[4]。因此,寻找一种面向高维数据的有效分类方法处理客户投诉非常重要。
随着机器学习技术的不断发展,集成学习方法在高维数据分类问题中得到了广泛的应用[5-6]。集成学习方法主要有两类:(1)基于数据划分的方法,比如Bagging与Boosting 等;(2)基于特征划分的方法,比如Random Subspace等[7]。基于集成学习方法进行高维数据分类的主要思想是通过生成多个特征子集,在特征子集中生成多个基分类器,最终合成多个基分类器的结果为最终的分类结果。因此集成学习能够灵活地应对高维数据问题[8],并且集成学习方法通过其集成策略,合成了不同基分类器所提供的互补的信息,准确率往往优于单个分类器效果[9-12]。在客户投诉文本包含大量特征的情况下,可能存在特征的冗余或是不相关等问题,在原特征空间中构建的分类器往往没有在特征子集中构建的分类器效果好[13-14],所以Random Subspace 相比于其他集成方法更加适用于高维的客户投诉分类问题。
在集成学习方法中,不同基分类器的选择与不同的集成策略均会对分类结果有着重要的影响[15]。在基分类器的选择上,决策树(Decision Tree,DT),支持向量机(Support Vector Machine,SVM),K-近邻(K-Nearest Neighbor,KNN)等均是具有代表性的常用分类器[16]。在集成策略的选择上,应用最广泛的则是主投票法[17]和加权融合法。但是主投票法对不同的基分类器不加区分,无法有效利用不同分类器所提供的互补信息。加权融合法通常使用基分类器的准确度作为权重来区分不同分类器进行结果合成[18]。但由于权重可来源于不同角度,仅使用准确度作为权重进行融合的有效性不强。并且在较为复杂的分类问题中,由于所能获取特征的有限性,基分类器产生的结果往往是不确定的,而主投票法与加权融合法均缺乏此类不确定信息融合的能力。证据推理方法具有较好的不确定信息融合能力,并被运用到多分类器融合中[11]。然而证据推理方法忽略了多个分类器结果之间可能存在的信息冲突。当基分类器的结果完全冲突时,集成分类的结果可能会变差。
为有效提高客户投诉的分类准确性,本文提出一种基于改进的Random Subspace 的客户投诉方法。该方法综合考虑电信客户投诉中的文本特征和通讯状态特征,借鉴集成学习中的Random Subspace方法解决高维数据问题。由于SVM已经在投诉领域得到了广泛的应用并被证明具有较好的分类性能[2,19],使用SVM为所提方法中的基分类器。同时,为了弥补当前集成策略的不足,提出一种基于证据推理规则的集成策略对Random Subspace 方法进行改进。证据推理规则是基于证据理论所提出的一种同时考虑证据的权重与可靠性的可用于不确定信息融合的有效框架[20]。使用证据推理规则融合基分类器结果时将不同基分类器的分类结果视为证据,将其分类准确率视为证据可靠性和初始权重,并通过训练模型获取证据的最优权重,从而有效应对不同分类器结果之间的冲突以及结果的不确定性,提升集成学习模型的性能。最后,采用某电信公司的历史投诉工单对所提方法进行了验证并与其他方法进行了比较。结果显示,相比于其他集成学习方法,如Bagging和 Adaboost、Random Subspace 的分类性能更强,验证了Random Subspace在高维数据分类中的有效性;相比于其他基分类器,如DT和KNN,使用SVM作为基分类器能够提供更好的分类效果,验证了SVM 在客户投诉分类领域的适用性;而相比于传统的集成策略,如主投票法与加权融合法,证据推理规则对多分类器的融合更加有效,验证了本文所提的以证据推理规则为一种新的集成策略对Random Subspace 方法改进的有效性。即通过在真实投诉工单数据上的实验,所提方法的有效性得到了验证。
2 改进的客户投诉集成分类方法
为有效处理客户投诉问题,本文提出一种基于改进的Random Subspace 的客户投诉分类方法。该方法主要分为两部分:第一部分为特征提取;第二部分为模型构建。在特征提取部分,从业务支持系统中获取投诉相对应的通讯状态特征,从投诉描述中提取相对应的文本特征并进行选择,共同构成客户投诉分类的原数据集。在模型构建部分,通过随机采样,对原数据集中的特征进行随机抽取,生成多个特征子集,并在特征子集中生成SVM 基分类器对客户投诉进行分类,最后使用证据推理规则对多个SVM 基分类器中的输出结果进行合成,得到最终分类结果。该方法结构图如图1所示。
2.1 特征提取
在客户投诉分类问题中,来自业务支持系统中的通讯状态数据和来自投诉工单中的客户投诉描述文本数据均能反映客户投诉的原因。业务支持系统对电信网络的运行状态进行了实时监控,来自业务支持系统中的通讯状态特征能够反映客户投诉时的基站状况,通讯信号等客观状态,而客户投诉工单中的投诉描述文本则直接反映了客户投诉的动机。综合通讯状态特征与客户投诉描述文本特征两类信息能够更准确地揭示客户投诉的原因。
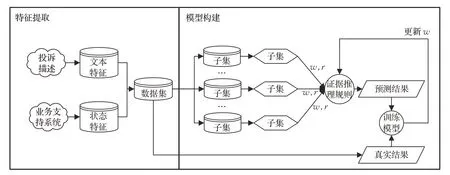
图1 方法结构图
通讯状态特征可直接从业务支持系统中获取,而投诉描述则需要进行文本特征的提取。在本文中,使用向量空间模型表示文本特征。首先使用词袋模型提取文本特征,然后采用TF-IDF 方法进行特征加权。因此可从投诉描述文本中提取出一系列文本特征,并以TF-IDF值表示文本特征值。由于初始文本特征中有一些与投诉原因无关的特征,因此需进行特征筛选。使用信息增益来进行特征筛选,公式如下:
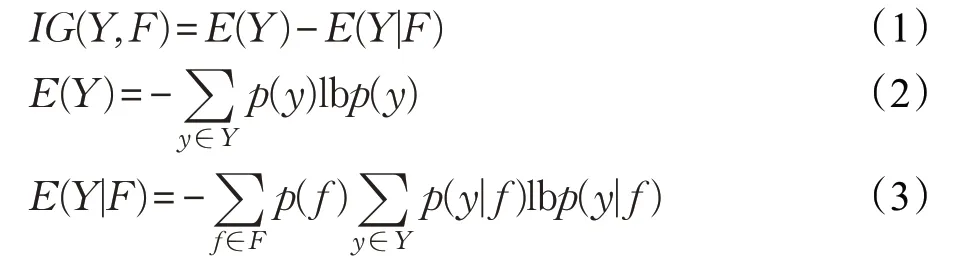
其中,IG(Y,F)表示各特征的信息增益值,Y为分类结果,y∈Y为所有结果中的某一类结果,F为特征,f∈F为某一特征,E(Y)为结果Y的熵值,E(Y|F)为加入特征F之后结果Y的熵值,p(y)为结果y的边际密度函数,p(y|f)为加入特征f后y的边际密度函数。
状态特征,文本特征与分类结果共同构成电信客户投诉分类问题中的原数据集D={(x1,y1),(x2,y2),…,(xn,yn)}。
2.2 模型构建
本文基于改进的Random Subspace 构建客户投诉分类模型。该模型采用Random Subspace 应对电信客户投诉数据中的高维问题,并通过证据推理规则合成多个特征子空间中的SVM 基分类器所提供的分类结果,从而能够有效利用分类结果之间的互补性,提高分类的准确率。电信客户投诉分类模型的构建主要分为三部分:第一部分是特征子空间,第二部分是基分类器,第三部分是集成策略。
2.2.1 特征子空间
为了应对高维客户投诉数据中的特征冗余或是不相关等问题,模型构建的第一步则是特征子空间的生成。本文根据参数r与参数S对原数据集D={(x1,y1),(x2,y2),…,(xn,yn)}中的特征进行随机采样,从而生成多个维度较低的数据子集。其中参数r代表在构造子空间时抽取的特征数量占原特征空间中所有特征数量的比例,参数S代表所构造的随机子空间的数量。即,通过特征的随机采样共构造出S个特征子空间,每个特征子空间中的特征数量占原特征空间中特征数量的比例为r。
2.2.2 基分类器
支持向量机是一种基于结构风险最小化原理的机器学习方法并在客户投诉领域得到了广泛的应用,因此本文选用SVM 进行基分类器的构造。SVM 方法的原理是在样本空间中寻找到一个最优超平面将不同类别的样本进行划分。客户投诉分类中首先需将原始的输入空间映射到新的特征空间中,然后寻找最优分类超平面对投诉数据进行分类。
使用SVM寻找最优分类超平面问题可以转化为以下目标函数的求解问题:

其中,w为法向量,决定了超平面的方向,C为惩罚系数,ξi为非负松弛因子,b为位移项,决定了超平面与原点之间的距离,ϕ(x)为一个非线性隐函数,它将输入空间映射到一个高维空间中。
将上述问题转化为其对偶问题:

在问题的求解过程中,需要计算ϕ(xi)Tϕ(xj),即xi和xj映射后的内积运算。此内积运算可通过原输入空间中的核函数k(xi,xj)=ϕ(xi)Tϕ(xj)来计算,从而得到最终的决策函数:
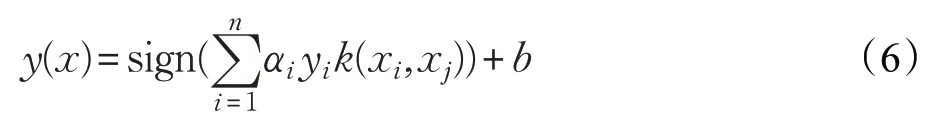
其中,αi和b均为常实数,且αk>0,k(xi,xj)核函数采用径向基核函数,公式如下:
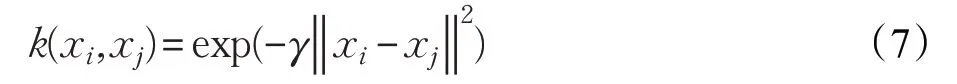
2.2.3集成策略
为弥补现有集成策略的不足,本文采用证据推理规则为一种新的集成策略来合成不同基分类器产生的结果。证据推理规则是由Yang等[20]基于证据理论所提出的一种考虑证据的权重与可靠性的可用于不确定信息融合的有效框架。使用证据推理规则融合基分类器结果时将不同基分类器的分类结果视为证据,将其分类准确率视为证据可靠性和初始权重,并通过优化得到最优权重,最终对分类器产生的结果进行融合。
首先,将所有分类结果{y1,y2,…,yN}视为一组相互排斥且可以构成一个完备集的辨识框架,用Θ表示。表示Θ的幂集yN-1},Θ} ,由基分类器s所产生的结果可转换为如下证据:
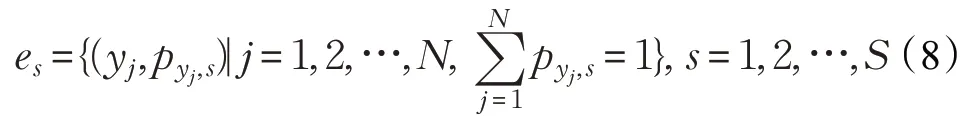
其中es表示从第s个基分类器中所得出的分类结果所转化的证据,pyj,s为该分类器的分类结果取yj的概率。
在证据推理规则中,为了避免基分类器结果信息的冲突性,同时考虑证据的权重和证据的可靠性进行信息融合。因此,综合考虑证据权重w 与证据可靠性r 的定义一个信度分布函数如下:

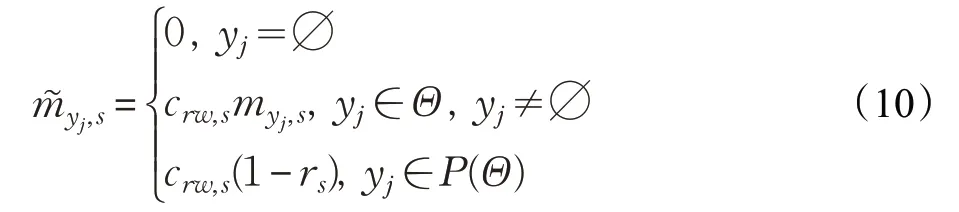
其次,使用证据推理规则对S个基分类器所提供的是S条证据e1,e2,…,eS进行融合,可得到这S条证据联合支持yj的信度函数定义如下:
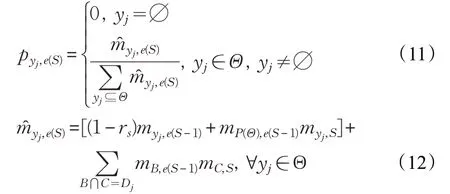
经过证据推理规则,基分类器融合后的结果为{(yj,pyj,e(S)),j=1,2,…,N},模型的最终分类结果则为最大的pyj,e(S)值所对应的类别。
最后,对基分类器的权重进行优化。在证据推理规则中,证据的可靠性代表了提供证据信息源的固有属性,而证据的权重则是与其他证据相比的重要性[20]。使用证据推理进行多分类器融合时,证据可靠性可来源于基分类器的准确率。而证据的初始权重与可靠性相同,均取决于基分类器的准确率。但仅将基分类器的准确率作为证据的权重存在片面性,无法有效的利用不同基分类器所提供结果之间的互补性。因此,本文将基分类器的准确率作为初始权重,并通过缩小真实分类结果与模型合成的分类结果之间的差距构建训练模型得到最优权重。训练模型如下:
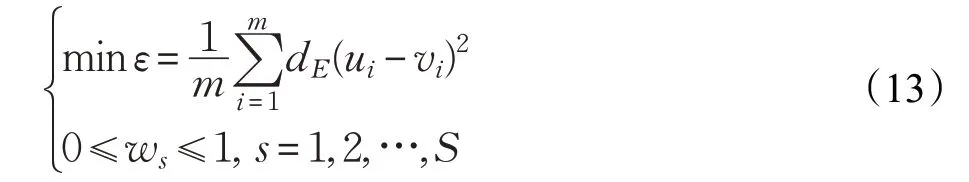
其中,m为训练集中的数据量。ui为真实分类结果的分布,vi为基分类器结果合成后在不同类别上的概率分布。以二分类为例,若真实分类为y1,模型合成结果为,则ui为(1,0)。vi为。
dE(ui-vi)为ui与vi之间的欧式距离。ws为基分类器的权重。当目标函数ε最小化时,所有权重达到最优。
3 实验设计
3.1 数据描述及评价指标
为了验证本文所提方法的有效性,使用来自某电信公司技术支持部门的真实投诉工单进行实验,共计1 433条。其中由质量原因导致的投诉共有801条,由客户原因导致的投诉共有632 条。投诉工单中包括投诉号码,投诉时间和投诉地点等客户信息以及客户投诉描述文本。根据投诉工单中的投诉号码,投诉时间和地点等客户信息,从业务支持系统中提取出6个对投诉分类有重要影响的通讯状态特征,分别是:干扰区域、热点区域、热点时段、基站状况、弱信号区域和手机制式匹配。干扰区域用来判断该投诉地点是否有干扰信号源,热点区域用来判断该投诉地点是否属于人口密集区域,热点时段用来判断该时段是否属于人口密集分布时段,基站状况用来判断该投诉地点的移动终端所使用的基站是否正常工作,弱信号地区用来判断投诉是否来自信号较弱的地区,手机制式匹配用来判断该投诉手机所采用的制式与当地网络的最佳制式是否匹配。而客户投诉描述可直接从工单中提取,描述示例如表1所示。

表1 客户投诉描述示例
分类问题中常用的指标为分类准确率(Accuracy)、查准率(Precision)、查全率(Recall)和F-measure 值。计算公式如下:
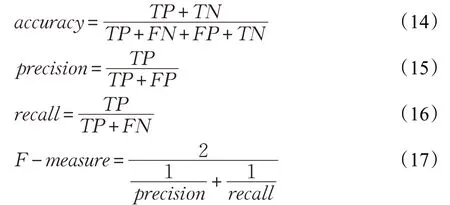
其中,TP为被正确地划分为正类的样本数,FP为被错误地划分为正类的样本数,FN为被错误地划分为负类的样本数,TN为被正确地划分为负类的样本数。Accuracy则表示所有预测正确的样本占总样本的比例,precision 表示被正确预测为正类的样本占所有被预测为正类样本的比例,recall 为被正确预测为正类的样本占实际为正类样本的比例,F-measure为precision与recall的调和均值。本文使用这4个指标对客户投诉分类方法的性能进行评估。
3.2 实验过程及结果
为了降低实验结果的偶然性,使用十折交叉验证的方式进行实验。在十折交叉验证中,首先将数据集分成10份,然后轮流将其中9份作为训练数据,1份作为测试数据进行实验。在实验中,首先使用TF-IDF 方法对投诉文本进行特征提取并通过信息增益选取信息增益值前50的文本特征与状态特征共同构成客户投诉分类的原始特征空间。接着使用随机采样的方法,对特征进行抽取,构造特征子空间。在特征子空间的构造过程中,子空间数量参数S取15,子空间抽取的特征数量占所有特征数量的比例(即参数r)分别取0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9。在各特征子空间中,使用SVM基分类器对客户投诉进行分类。最终使用证据推理规则合成多个SVM 基分类器中的分类结果,并通过训练优化各分类器的权重,从而得到最终的分类结果。
为了进一步验证本文所提方法的有效性,进行了三组对比实验。首先,为了验证所提方法相对于其他集成学习方法在处理高维数据时的有效性,将其与Bagging和Adaboost方法进行了对比。接着,为了验证所提方法中选用SVM 为基分类器的合理性,选用DT,KNN 作为基分类器进行对比实验,分别称为RS-DT和RS-KNN方法,即分别采用DT和KNN在随机生成的子空间中构造基分类器对客户投诉进行分类,并通过证据推理规则将多个分类器中的结果合成,得到最终分类结果。最后为了验证本文所提的使用证据推理规则为一种新的集成策略的有效性,将其与主投票法以及加权融合法这两个常用的集成策略进行了对比,分别称为RS-MV 和RS-WAF方法。使用RS-MV进行结果合成时不考虑不同的SVM 基分类器的差异,分类器分别对分类结果进行投票,票数最多的类别为最终的分类结果。RS-WAF则考虑不同SVM 基分类器的差异性,以分类器的准确率为权重,对其所投的票数进行加权,加权后票数最多的类别为最终的分类结果。所有对比实验均采用相同的数据集及特征提取方式进行十折交叉验证对比结果如表2所示。
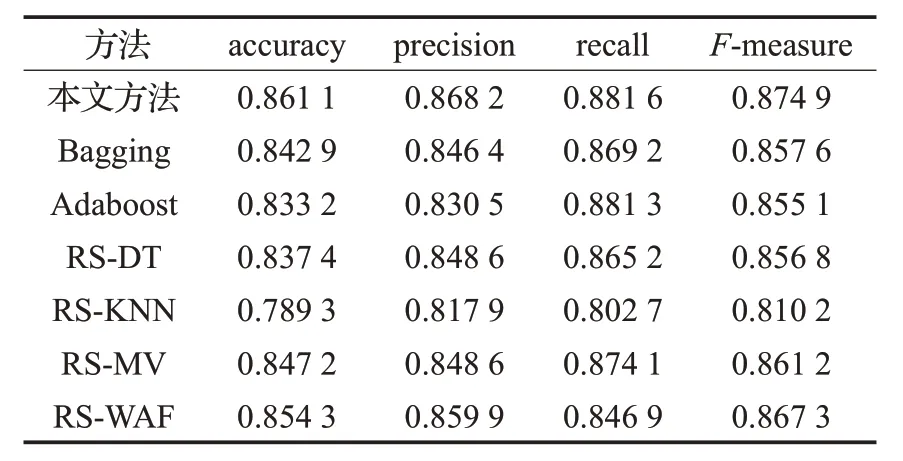
表2 不同方法对比结果
观察表2,可以看出本文所提方法表现良好,在accuracy、precision、recall 以及F-measure 指标上分别取到了 0.861 1,0.868 2,0.881 6 和0.874 9,相比于集成学习方法Bagging和Adaboost,其分类效果最佳。Bagging方法注重的是对样本的抽取,Adaboost方法更加关注于样本权值,它们在特征维度没有过多的处理,在面临高维数据时,它们预测性能弱于Random Subspace。因此,它们的预测准确率低于所提方法。相比于RS-DT和RS-KNN,本文方法在Accuracy,precision,recall 以及F-measure 这4 个指标上均取得了更高的值,具有更好的分类效果。即在Random Subspace 方法下,相比于DT与KNN,使用SVM作为基分类器对客户投诉进行分类更加准确。并且本文方法优于RS-MV 和RS-WAF,RS-WAF优于RS-MV,即本文所提的证据推理规则在集成效果上优于主投票法和加权融合法,加权融合法优于主投票法。加权融合法在主投票的基础上,考虑了不同基分类器的差异性,使得分类准确的基分类器有着更大的权重,从而使得模型准确率相对于主投票法得到了提升。证据推理规则考虑了分类器提供的结果自身的可靠性以及分类器之间的最优权重,并且具有对不确定信息的融合能力,从而使得模型的准确率高于主投票法与加权融合法,即证据推理规则作为一种新的集成策略可有效改进Random Subspace。多组对比实验共同验证了本文所提的基于改进的Random Subspace 的客户投诉分类方法的有效性。
3.3 敏感性分析
Random Subspace 方法中一个重要的参数是每个特征子空间中的特征数量占特征空间中特征数量的比例r,不同的参数r对模型精度的影响非常大。在所提方法及对比方法中,分别选取了0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9为参数r的值对客户投诉进行分类。不同r值所对应的模型的分类准确率值如图2所示。
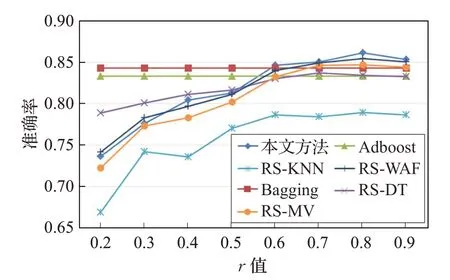
图2 不同r 值的分类结果
观察图2,本文方法、RS-DT、RS-KNN、RS-MV、RSWAF分别在r取0.8、0.7、0.8、0.8、0.8处取得良好的分类精度0.861 1、0.837 4、0.789 3、0.847 2、0.854 3。r值从0.2 到0.9 时,分类准确率一直处于不断增大的趋势,最终趋于平稳,与以往研究趋势相符。
4 结束语
随着电信业的发展,客户投诉量迅速上升并且存在大量的通讯状态数据与投诉文本数据,依靠传统的人工分析方式人力成本高,效率低下且存在较高的误判率。为了高效准确地处理高维的投诉数据,本文提出了一种基于改进的Random Subspace 的客户投诉分类方法。该方法综合考虑客户投诉过程中的通讯状态数据与投诉描述文本数据,采用基于特征划分的集成学习方法Random Subspace 为基础,并以SVM 为基分类器,证据推理规则为一种新的集成策略对投诉进行分类。使用某电信公司的历史投诉工单对所提方法进行了验证。结果显示,相比于其他集成学习方法,如Bagging和Adaboost,本文方法具有更好的分类效果,相比于其他基分类器,如DT和KNN,本文方法中使用的SVM具有更佳的分类性能,相比于传统的集成策略,如主投票法和加权融合法,所提方法中使用的证据推理规则具有更优的融合效果。综合来看,本文所提的基于改进的Random Subspace的客户投诉方法可有效对投诉原因进行分类,从而提高客户投诉处理效率。在进一步的研究中,一方面,需要在更多的数据集下对所提方法进行验证,另一方面,在构造特征子空间时,可采用更加合理的构造方式使得特征提取更优从而增强模型分类性能。
猜你喜欢
数学杂志(2022年4期)2022-09-27
电子技术与软件工程(2017年14期)2017-09-08
世界知识画报·艺术视界(2017年7期)2017-07-27
计算机应用(2017年4期)2017-06-27
自动化学报(2017年11期)2017-04-04
红土地(2016年3期)2017-01-15
幼儿智力世界(2016年6期)2016-05-14
小雪花·初中高分作文(2015年10期)2015-10-24
语文知识(2015年11期)2015-02-28
航天返回与遥感(2014年5期)2014-07-31
