
基于深度Q网络的水面无人艇路径规划算法
2020-10-20 05:43随博文黄志坚姜宝祥郑欢温家一
上海海事大学学报 2020年3期
随博文 黄志坚 姜宝祥 郑欢 温家一

摘要:为实现水面无人艇(unmanned surface vessel, USV)在未知环境下的自主避障航行,提出一种基于深度Q网络的USV避障路径规划算法。该算法将深度学习应用到Q学习算法中,利用深度神经网络估计Q函数,有效解决传统Q学习算法在复杂水域环境的路径规划中容易产生维数灾难的问题。通过训练模型可有效地建立感知(输入)与决策(输出)之间的映射关系。依据此映射关系,USV在每个决策周期选择Q值最大的动作执行,从而能够成功避开障碍物并规划出最优路线。仿真结果表明,在迭代训练8 000次时,平均损失函数能够较好地收敛,这证明USV有效学习到了如何避开障碍物并规划出最优路线。该方法是一种不依赖模型的端到端路径规划算法。
关键词:水面无人艇(USV); 自主避障; 路径规划; 深度Q网络; 卷积神经网络; 强化学习
中图分类号: U675.73
文献标志码:A
Path planning algorithm for unmanned surface vessels
based on deep Q network
SUI Bowen, HUANG Zhijian, JIANG Baoxiang, ZHENG Huan, WEN Jiayi
(Merchant Marine College, Shanghai Maritime University, Shanghai 201306, China)
Abstract:
In order to realize the autonomous obstacle avoidance navigation of unmanned surface vessels (USVs) in unknown environment, a USV obstacle avoidance path planning algorithm based on the deep Q network is proposed. In this algorithm, the deep learning is applied to the Q-learning algorithm, and the Q function is estimated by the deep neural network, which effectively solves the problem of dimension disasters in the path planning of complex waters environment caused by the traditional Q-learning algorithm. The mapping relationship between the perception (input) and the decision (output) can be established effectively by the trained model. According to the mapping relationship, a USV chooses the action with the largest Q value in each decision cycle, so that it can successfully avoid obstacles and plan the optimal route. The simulation results show that, the average loss function can converge well through the iteration training of 8 000 times, which proves that the USV has learned how to avoid obstacles and plan the optimal route effectively. This method is an end-to-end path planning algorithm which does not depend on models.
Key words:
unmanned surface vessel (USV); autonomous obstacle avoidance; path planning;
deep Q network; convolutional neural network; reinforcement learning
0 引 言
水面無人艇(unmanned surface vessel, USV)在复杂水域环境中要具备自主航行和避障能力,首先面对的是避障路径规划问题,即如何规划出一条从出发点到目标点的安全且最优的航线。目前,根据智能化程度,研究与应用较多的USV路径规划算法包括传统算法、启发式算法、智能算法、强化学习算法等4类[1]。
传统算法如可视图法[2]、人工势场法[3]等缺乏灵活性,易于陷入局部最优值。启发式算法是相对于最优化算法提出的,是一种搜索式算法,在离散路径拓扑结构中得到了很好的应用[4]。智能算法是人们在仿生学研究中发现的算法,常用的智能算法包括遗传算法、神经网络算法和群智能算法[1]。以上3类算法都是基于样本的监督学习算法,即算法需要完备的环境信息。因此,在未知环境(即系统中没有新环境的先验信息)水域采用这3种算法USV很难有效地进行路径规划。
强化学习算法是由美国学者MINSKY于1954年提出的。目前常用的强化学习算法主要包括Q学习、SARSA学习、TD学习和自适应动态规划算法等。该类算法通过智能体与环境进行大量的交互,经过不断试错获取未知环境的信息反馈,从而优化路径规划策略。该类学习算法不依赖模型和环境的先验信息,是一种自主学习和在线学习算法,具有较强的不确定环境自适应能力,可以借助相应传感器感知障碍物信息进行实时在线路径规划。例如,王程博等[5]提出了一种基于
Q学习的无人驾驶船舶路径规划方法,将强化学习创新应用至无人驾驶船舶的路径规划领域,利用强化学习具有自主决策的特点来选择策略最终完成无人驾驶船的自主避障和路径规划。然而,传统的Q学习是以Q值表的形式存储状态行为信息的,而在复杂水域环境中Q值表存储不了大量的状态行为信息从而会导致维数灾难问题。
为解决维度灾难问题并使USV在未知环境水域具有较高的自适应性和稳定性,本文基于深度Q网络提出一种端对端的USV路径规划算法。该算法将深度学习与Q学习相互融合,以神经网络输出代替Q值矩阵,有效解决了维度灾难问题。该算法是一种无模型的端到端的路径规划算法,即通过深度学习实时感知高维度障碍物信息,然后根据感知到的环境信息作出决策,通过端到端的训练环境信息输入和规划路径输出,减少了大量中间环节的运算,有效提高了算法的自适应性和模型泛化能力。此外,由于该算法是一种不依赖模型的端到端的路径规划算法,所以基于该算法的USV智能系统通过实时与环境交互获取环境信息,并根据获取的交互数据不断学习和改善自身决策行为,最终获得最优策略,规划出最优路线。相比于传统路径规划算法,本文所提出的路径规划算法更具通用性。
1 Q学习算法
Q学习算法最初是由WATKINS等[6]提出的一种无模型的值函数强化学习算法。该算法通过构建一个Q值表储存状态动作值,通过智能体与环境的不断交互获得奖励值,进而更新Q值表,更改动作策略集,最终使智能体趋于最优动作集。算法原理图见图1。
在Q学习算法中,USV根据当前的状态选择一个动作对环境造成影响,并收到环境给出的反馈(正反馈或负反馈),根据反馈信号作出下一步决策,原则是使得环境的正反馈概率最大[7]。例如,USV路径规划决策系统在t时刻选择动作at,环境接收动作后由状态st转移到下一个状态st+1,状态转移概率P取决于at和st:
根据未来奖励对当前奖励长期影响的观点选择最优动作,在策略π的作用下,状态值函数被定义为
式中:Rt(a)为当前状态下采取行动的即时奖励;γ∈[0,1]为折扣因子,表示未来奖励对当前奖励的重要程度。学习的最终目的就是找到最优策略π*,使得每个状态的值函数取得最大值。
定义状态动作值函数Q:
式中,Q*(s,a)表示在状态s下采取动作a所得的最大累积奖励值;s0和a0分别为初始状态和在初始状态下执行的动作。基于当前的状态和动作,在最优策略π*的作用下,系统将以概率P(s,a,st)转移到下一状态st,则由式(4)可得Q学习算法的基本形式:
由式(3)進一步可得最优策略的状态动作表达式:
式(6)表明,在路径规划时只需求得当前的状态动作值函数Q(s,a),通过不断对上一状态的值函数进行迭代更新,即可规划出全局最优策略。其迭代公式为
式中:α为学习率,主要用于迭代公式的收敛。
2 避障路径规划算法
2.1 算法模型结构
本文结合卷积
神经网络[8]和强化学习提出一种深度强化学习(深度Q网络)路径规划算法。该算法可实现从感知(输入)到决策(输出)的端到端的策略选择。输入图片像素后,经过卷积神经网络对环境信息的逐层提取和对高维特征的感知,从动作空间选取Q值最大的动作执行,从而得到平均奖励最大的策略即为最优策略,实现对USV的端到端的自主避障控制和路径规划。本文提出的路径规划算法结构见图2。
首先根据马尔科夫决策过程模型[9]和Bellman方程[10]得到当前状态的动作值函数:
式中:st+1为下一状态;at+1为下一状态最优动作;R为采取下一状态的奖励。通过多次实验可找到最优Q*(s,a):
在状态s下通过多次实验可得到多个Q值,当实验次数足够多时,该期望值就无限接近真实的Q值。因此,可以通过神经网络估计Q值:
式中,θ是神经网络的参数。
利用式(10)估计Q值的方法会产生一定的误差,因此引入损失函数来反映利用神经网络估计的Q值与真实Q值之间的差:
采用随机梯度下降方式不断优化网络参数,使损失函数尽可能降到最低,即估计的Q值尽可能逼近真实值,使得智能体每次都能选取最优的Q值从而进行最优决策。
2.2 动作空间设计
在仿真过程中对USV和仿真环境进行简化处理:把USV近似为1×1像素大小的像素块,定义USV的动作空间
包括上、下、左、右4个基本动作,并采用ε贪婪策略,分别以ε的概率进行随机动作选择来探索新环境,以1-ε的概率选择Q值最大的动作a。本文设置的探索-利用机制如下:
采用ε贪婪策略,既可以保证USV在策略选择时选取较优策略,又能保证所有状态空间都能被探索到。
2.3 激励函数的设计
本实验中动作空间是有限且离散化的,故可将激励函数R做泛化处理:当USV到达目的地时,奖励值设为100;当USV与黑色方块重合时,即表示USV没有进行有效的避碰,奖励值设为-100,以示惩罚;其他白色可通行区域所有状态的奖励值均设为0,激励函数的表达式如下:
R=100 (到达目的地)0 (未碰撞,未到达)-100 (发生碰撞)
2.4 深度Q网络结构
本文采用的卷积神经网络结构包括2个卷积层和2个全连接层,卷积神经网络训练参数设置见表1。
在卷积神经网络中输入像素为25×25×3的仿真地图,见图3。首先经过卷积核数量为10、大小为2×2的第一个卷积层,提取高维特征,生成25×25×10的特征图;将第一个卷积层的输出作为第二个卷积层的输入,其中第二个卷积层的卷积核数量为20、大小同样为2×2;将第二个卷积层的输出作为第一个全连接层的输入,通过重塑数据形状,将特征图转化为1×12 500的特征向量,再输入到第二个全连接层,输出一个1×4的矩阵,分别对应USV的上、下、左、右4个离散动作,最后根据每个数据点的Q值的大小选出最优动作。
3 仿真与实验
3.1 建立仿真环境
基于Python及相应工具包构建如图4所示的二维仿真环境。随机生成625张像素为25×25的图片,每个像素块都代表环境的一个状态,并且在像素为25×25的图片中随机生成位置各不相同的1×1像素的黑色方块代表障碍物,白色区域为可自由通行区域。随机变换障碍物位置200次,即生成了200×625张图片作为训练数据进行训练。从12 500张图片中随机选取4张作为仿真环境,如图4所示。图4中左上角、右下角灰色方块分别代表无人艇的出发点和目标点。
结合仿真环境建立二维直角坐标系,如图5
所示:A点为USV的出发点,坐标为(1,1);B点为目标点,坐标为(25,25)。本文中所有仿真环境的出发点和目标点均与图5保持一致。对于USV来说,这些环境信息都是未知的。
3.2 实验结果分析
实验环境配置:CPU为intel i7-7700 4.2 GHz,内存为16 GB,显卡为英伟达GTX1080 Ti,操作系统Ubuntu 16.04。实验中采用的训练数据来自随机生成的12 500张像素为25×25的图片。利用同样的方法随机生成具有不同障碍物分布的20张图片作为测试集进行测试。
为简化仿真实验复杂度,仿真实验仅在模拟的水上障碍物静态环境中进行,在实验前期USV在不同的时间步与障碍物发生碰撞,环境给出惩罚,以降低下次出现相似状况的概率,有效指引USV选择最优策略。在上述4种仿真环境中的路径规划效果见图6。
在训练开始时,USV会多次与障碍物发生碰撞且规划路径波动较大;在训练3 000次时,算法逐渐规划出安全路径,但此时路径并非最短,所耗费时间也较长;在训练5 000次时,系统可以有效避开障碍物,算法趋于平稳并逐渐规划出有效路径,所需时间也明显缩短;当训练8 000次时,系统可以高效避开障碍物并规划出最优路径。表2为在上述4种仿真环境中分别训练不同次数产生的数据平均值。
从训练数据中随机选出一批图片进行训练,其权值更新取决于损失函数,随着训练次数的增加,
式(11)的max Q(st+1,at+1s,a)对应上、下、左、右4个动作中的Q值的最大值。首先将神经网络预测的Q值存储起来。经过一段时间的训练,更新Q值并存储在与训练模型相同的文本文件中。新Q值又可以用来训练模型。重复几个步骤,直到算法学习到所需的特性。当训练开始时,神经网络估计的Q值与真实Q值的差值较大,此时的损失函数波动加大(见图7),显然此时算法还没有学会如何避开障碍物。
随着训练次数的增加,算法逐渐学会捕捉相应的特性,当训练结束时算法的平均损失已经明显收敛(见图8),这表明网络误差较小,USV已经很好地学会如何避开障碍物规划安全航线。
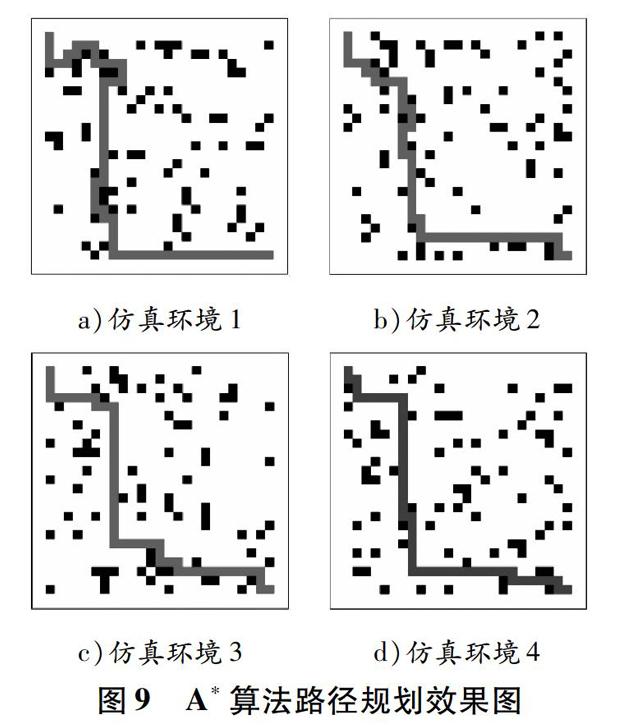
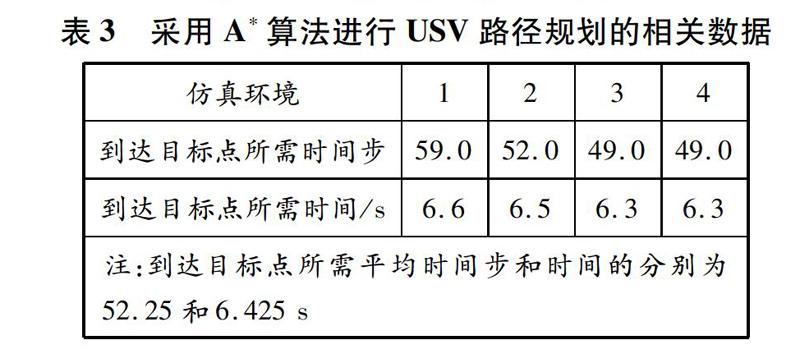
针对上文的4种仿真环境,采用A*算法对USV进行路径规划,如图9所示:随着仿真环境的变化,A*算法并不稳定,在仿真环境1和仿真环境2中,USV的路径规划均存在绕远现象,并不是最优路线,没有实现高效合理的路径规划目标。采用A*算法进行路径规划的相关数据见表3。
由表2和表3可知:采用深度Q网络进行USV路径规划时,当迭代8 000次时算法已经收敛,从出发点到目标点所需平均时间步和时间分别为49.0和5.3 s;采用A*算法进行USV路径规划时,从出发点到目标点所需平均时间步和时间分别为52.25和6.425 s。由此可知,采用深度Q网络进行USV路径规划比采用传统的A*算法更加高效。
以上仿真结果表明,本文提出的路径规划算法可以实现USV航行的全局路徑规划,并且比传统的A*算法更加高效,可以有效地避开环境中的障碍物并规划出最优航线。
4 结束语
本文基于深度Q网络提出一种无须模型的端到端的无人艇(USV)路径规划算法。该算法以神经网络的输出代替Q值矩阵,解决了采用传统Q学习进行路径规划时的维数灾难问题。采取经验回放机制,有利于提高USV的学习效率,提高USV到达目标的速度。该算法无须知道环境先验信息,能够通过与环境的交互获取数据并进行在线学习,相比于传统的基于模型的路径规划算法,本文所提出的路径规划算法更具通用性。通过仿真可知:USV在与环境交互初期,对环境信息了解较少,会发生碰撞及路径规划波动较大等现象;随着迭代次数的增加,USV的决策系统累积学习经验,提高对环境的自适应性,最终成功规划路径并安全抵达目标点。通过对比实验可知,基于深度Q网络的USV路径规划算法比传统的A*算法更加高效合理。然而,本文对USV的动作空间进行了离散化处理,与真实情况尚有差距,针对USV的连续动作空间进行路径规划将是今后的研究方向。
参考文献:
[1]刘志荣, 姜树海. 基于强化学习的移动机器人路径规划研究综述[J]. 制造业自动化, 2019, 41(3): 90-92.
[2]李洪伟, 袁斯华. 基于Quartus Ⅱ的FPGA/CPLD设计[M]. 北京: 电子工业出版社, 2006.
[3]陈超, 耿沛文, 张新慈. 基于改进人工势场法的水面无人艇路径规划研究[J]. 船舶工程, 2015(9): 72-75.
[4]邱育红. GIS空间分析中两种改进的路径规划算法[J]. 计算机系统应用, 2007, 16(7): 33-35.
[5]王程博, 张新宇, 邹志强, 等. 基于Q-learning的无人驾驶船舶路径规划[J].船海工程, 2018, 47(5): 168-171.
[6]WATKINS C J C H, DAYAN P. Q-Learning[J]. Machine Learning, 1992, 8(3/4): 279-292.
[7]卫玉梁, 靳伍银. 基于神经网络的Q-learning算法的智能车路径规划[J].火力与指挥控制, 2019, 44(2): 46-49.
[8]林景栋, 吴欣怡, 柴毅, 等. 卷积神经网络结构优化综述[J].自动化学报, 2018(2): 75-89.
[9]刘成勇, 万伟强, 陈蜀喆, 等. 基于灰色马尔科夫模型的船舶交通流预测[J]. 中国航海, 2018, 41(3): 95-100.
[10]李金娜, 尹子轩. 基于非策略Q-学习的网络控制系统最优跟踪控制[J]. 控制与决策, 2019(4): 17-25.
(编辑 赵勉)
收稿日期: 2019-08-26
修回日期: 2019-09-29
基金项目:
国家自然科学基金(61403250)
作者簡介:
随博文(1992—),男,河南商丘人,硕士研究生,研究方向为深度强化学习,(E-mail)201410121215@stu.shmtu.edu.cn;
黄志坚(1979—),男,江西九江人,高级工程师,研究方向为控制算法,(E-mail)zjhuang@shmtu.edu.cn
猜你喜欢
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
中国新通信(2016年22期)2017-01-13
电脑知识与技术(2016年28期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
科技视界(2016年26期)2016-12-17
电脑知识与技术(2016年26期)2016-11-25
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
科技视界(2016年20期)2016-09-29
