
深度学习在电力设备锈蚀检测中的应用
2020-10-23 01:55范海兵胡锡幸刘明一肖俊
广东电力 2020年9期
范海兵,胡锡幸,刘明一,肖俊
(1. 国网浙江省电力有限公司检修分公司,浙江 宁波 315000;2. 国网浙江省电力有限公司杭州供电公司,浙江 杭州 310007;3. 国网浙江省电力有限公司金华供电公司,浙江 金华 321000;4. 浙江大学 计算机科学与技术学院,浙江 杭州 310012)
随着社会的快速发展,社会用电需求逐年上涨。据《浙江省电力发展“十三五”规划》披露,在“十二五”末的2015年,浙江全省最高负荷和用电量分别达到62.9 GW、355.3 TWh左右。此外,依据《浙江省电力发展“十三五”规划》中推荐方案的预测,在“十三五”末的2020年,全省最高负荷、用电量将分别达到84.0 GW、453.0 TWh。随着电网规模的扩大,对电力供应的可靠性的要求也在不断提高。电力设备在长期运转的过程中,不可避免地会出现锈蚀问题。而作为基础设施的电力设备一旦出现严重的锈蚀缺陷问题,极有可能导致设备故障,影响整个相关区域的电力系统正常运行,从而严重影响生产生活并带来难以预计的经济损失。这就需要对相应的电力设备进行定期巡检和及时的维护检修。及时发现锈迹并检修锈蚀问题,能够有效减少电力设备的恶劣性故障,从而保障电网安全稳定运行。
传统的电气设备状态查验主要是依靠人工的方式对电力设备进行定期的巡视检查,这种人力巡检方式存在许多问题[1]:①巡检人员的安全难以保证。与其他普通巡检任务不同,对电力设备的检视通常需要工作人员暴露在大量高负荷运转的电气设备中,且这些设备随时可能发生故障,具有一定的安全风险。②巡检效率低。安排人力定期逐个检查设备,对管理人员和作业人员都是很大的考验,工作强度较大,如果遇到恶劣天气则更加影响工作效率。③巡检准确度不高。人力巡检的判断主观性比较强,尤其是长期重复作业,更容易降低该作业的稳定性。
2019年,国家电网有限公司做出了加快构建“三型两网”的主要战略部署,提出了构建状态全面感知、信息高效处理、应用便捷灵活的泛在电力物联网。构建设备状态全感知、数据高度信息化的能源互联网已经成为必然的发展趋势,针对电力设备的锈蚀,有必要研究准确而又高效的智能巡检方法。
网络通信基础设施的建设,使视频图像采集任务得到保障。目前主要的图像采集方式是无人机巡检[2-4]和核心设备间安装的全天候视频监控[5]。这些智能化的设备会产生大量的巡检图像,并实时传输到后台系统中,再由监控中心的工作人员根据捕获到的视频图像资料判断是否存在异常。依靠人工查验这些采集到的视频图像信息并找出设备锈蚀的方案虽然存在可行性,但是效率低、反馈慢,而且人力成本昂贵;因此,对于智能化识别方法的需求十分迫切[6]。常规的图像处理方法泛化能力不足,这些方法通过产生滑动窗口对整幅图像进行遍历,得到候选区域后,提取区域内的边缘、轮廓等特征,然后送入分类器进行目标物体的类别判断。这种基于常规图像处理的目标检测方法存在一些问题:①滑动窗口往往是设定固定的1个或者多个尺寸,没有灵活性,对图片中不同大小的物体检测任务冗余性太大;②边缘、轮廓这种人工预设的特征鲁棒性较差[7]。
近年来,得益于单位成本计算能力的提高,机器学习、深度学习发展迅猛。尤其是深度学习下的目标检测技术,得到了学术界和工业界的广泛认可[8-12]。本文基于目标检测领域中主流的Faster R-CNN算法和YOLOv3算法,提出基于深度学习的电力设备锈蚀检测技术,并从高精度和高速度2个方面进行实例验证,实现从视频、图片数据流中检测并定位实际作业环境中电力设备上的锈蚀区域。
1 基于深度学习的电力设备锈蚀检测
1.1 研究现状
目标检测是采用卷积神经网络(convolutional neural network,CNN)等深度学习方法来快速定位图像中感兴趣目标的技术,它不仅要检测出目标所属的类别,还要定位出目标所在的位置和大小,该方向是当前计算机视觉的研究热点。2012年之前,目标检测算法主要是基于手工提取目标特征,因此算法的实际效果很大程度上取决于人力在模型训练和参数调整上的经验,泛化能力差而且对复杂对象的特征学习效果不好。2012年AlexNet模型[13]的提出,标志着深度学习、目标检测乃至计算机视觉进入了全新的阶段。发展至今,深度学习下的目标检测技术主要分为单阶法和双阶法2类。双阶法是先产生候选框,然后将候选框中的图像特征送入分类器进行预测并得到最终的分类结果,代表的模型有区域卷积神经网络(region-based convolutional neural network,R-CNN)[14]和它的改进版本Fast R-CNN[15]和Faster R-CNN[16]等;单阶法是将目标检测作为回归任务,对图像的网格直接进行回归操作,不生成候选框,代表的模型有YOLO(you only look once)[17]、SSD(single shot multi detector)[18]和RetinaNet[19]等。
目前,基于深度学习的目标检测技术开始逐渐应用到电网电力系统中[20-24]。双阶法凭借训练速度快、提取的特征可复用等优势,成为众多非实时性检测任务的首选方法。上海大学的汤踊、韩军[25]等人利用Faster R-CNN来实现输电线路上不同部件的识别与分类,并提出通过调整CNN模型的卷积核大小和通过对图像的旋转变换来扩充数据集的方法,更好地提高模型的识别准确率和缩短识别时间;上海电力大学的马静怡[26]等人针对Faster R-CNN算法在电力设备状态图像处理过程中生成的候选框与目标设备不匹配而导致的设备识别率降低问题,提出依据像素值相近及位置相邻原则构建连通域,将连通域的长宽比作为输入信息对Anchor候选框进行修正;长沙理工大学的王超洋[27]等人提出了基于融合特征金字塔网络(feature pyramid network,FPN)结构的Faster R-CNN配电网架空线路异常状态检测系统,可以更好地识别变压器等小目标物体。在单阶法方面,樊绍胜等人提出基于改进的SSD电力设备红外图像异常自动检测方法[28]和基于YOLOv3的输电线路故障检测方法[29],不仅泛化性强,而且可以在极短的时间内对待检测图像实现物体的定位和分类,从而实现实时自动检测,使现有电力巡检设备实现“智能+”。
在锈蚀检测领域,难点主要在于如何解决锈迹不规则和数据集样本不足的问题。对此,中国石油大学的薛冰提出基于Mask R-CNN的电力设备锈蚀检测识别方法[30],采用Faster R-CNN完成目标检测的功能,采用全卷积网络(fully convolutional network,FCN)完成语义分割的功能,最后实现像素级别的分类识别,一定程度上解决了识别不规则图像的问题。浙江大学的纪扬等人[31]在电缆隧道铁锈识别这项任务中,引入迁移学习的概念,很好地解决了基于中小规模数据集训练的CNN难以获得较高识别精度的问题。
1.2 Faster R-CNN
R-CNN是目标检测领域中十分经典的方法,相比于传统的手工特征提取方式,R-CNN使用CNN来提取图像的深度特征,然后接1个分类器来预测候选区域的类别,并得到最终的结果。Faster R-CNN是R-CNN的改进方法,网络框架如图1所示,该算法由区域提案网络(region proposal net,RPN)候选框提取模块和Fast R-CNN检测模块组成。

ROI—感兴趣区域,region of interest的缩写。图1 Faster R-CNN网络框架Fig.1 Faster R-CNN framework
1.2.1 RPN
以往的目标检测算法生成候选框都非常耗时,如OpenCV中的AdaBoost使用滑动窗口和图像金字塔来产生建议窗口,R-CNN使用基于遍历的选择性搜索(selective search,SS)[32]方法。Faster R-CNN丢弃传统的滑动窗口和暴力遍历方法,使用RPN来生成建议窗口,明显地加速了候选框的区域提案。
RPN可以通过图形处理器(graphics processing unit,GPU)来加速网络训练计算速度,其中Anchor是RPN的核心。在得到特征图后,使用滑动窗口来生成建议区域,特征图上滑动窗口的中心映射在原图的1个区域就是Anchor,然后以此为中心,生成3种尺度和3种长宽比两两组合成的9种Anchors。特征图每个位置都会对应9个Anchors,如果特征图的大小为W×H,那么这张图中Anchors的数量就是W×H×9。这种滑动窗口的方式可以关联整张特征图,最后得到多尺度、多长宽比的Anchors。
特征图上的每个点前向映射得到k(k=9)个Anchors,后向输出512维度的特征向量,而Anchors是用来获取用于分类和回归的区域候选框,因此全连接层后需要连接2个子连接层,即分类层和回归层(网络框架如图2所示)。分类层用于判断Anchor属于前景(foreground,待预测)还是背景(background,需要舍弃),向量维数为2k;回归层用于计算Anchors的偏移量和缩放量,实现输出结果的精准定位,共4个参数{X,Y,W,H},分别代表该矩形候选框的中心点坐标和矩形的长宽,向量维数为4k。

图2 RPN网络框架Fig.2 RPN framework
1.2.2 Fast R-CNN分类网络
Fast R-CNN用于对前面通过RPN生成的建议区域进行分类和边框回归的计算,从而获得精准的目标位置。如图1所示,整个系统共享卷积特征图,即通过CNN计算得到的特征图(feature map)不仅作为RPN的输入,也作为Fast R-CNN的输入,避免了重复计算,加快了运行速度。
分类(classification)部分如图3所示,首先网络结合RPN得到的ROI和主干网络输出的卷积特征(proposal feature),通过全连接层(full connect layer)和softmax函数计算这些区域最终分类到哪个类别(cls_prob,如人、车、树等),输出的是一个概率向量;同时,再次利用矩形框回归(bounding box regression)计算每个建议区域的位置偏移量,并不断修正,得到更加精确的目标定位框(bbox_pred)。

图3 分类网络框架Fig.3 Classification network framework
1.2.3 模型训练
整个Faster R-CNN网络的损失函数L分为2个部分﹝式(1)﹞,即分类损失Lcls和回归损失Lreg。分类损失﹝式(2)﹞是经典的二分类交叉熵损失,回归损失﹝式(3)﹞是对anchors位置偏差的计算,其中fsmooth为smooth函数表达式,见式(4)。
(1)
(2)
(3)
(4)

1.3 YOLO
不同于Faster R-CNN这种2步检测算法,YOLO这种单阶法是直接在待预测图像上计算候选框的类别概率和位置信息。YOLO算法采用1个单独的CNN结构实现端到端(end-to-end)的目标检测,不需要利用RPN来生成候选框,因此YOLO算法的检测速度比R-CNN算法快。
1.3.1 网格划分下的回归和分类
YOLO算法首先把1张图像拆分为S×S个方格(grid cell),若1个物体的中心落在某个方格之内,那么这个方格就负责预测这个物体。这样的话,就不需要生成候选框,直接对每个方格进行计算即可。比如,图4中“狗”的中心坐落于5行2列的方格中,所以这个方格就负责预测图像中的“狗”。具体来说,每个方格会预测若干个边界框(Bounding Box)和每个边界框的置信度(confidence score)。其中置信度包括2个方面,一个是考虑边界框含有“目标”的可能性,另一个是边界框的准确度。前者记为Pobject,当该边界框为背景时(即不包含任何物体),此时Pobject=0;而当该边界框包含物体时,Pobject=1。边界框的准确度通过采用预测框和实际框(ground truth)的交并比(intersection over union,IOU)来表征,记为Itruth,pred。因此回归层面的置信得分定义为C=Pobject×Itruth,pred。这样来看,每个边界框的预测值包含5个元素{X,Y,W,H,C}。

图4 YOLO算法网格划分示意图Fig.4 Schematic diagram of YOLO grid partitioning
对分类的处理和回归类似,同样是基于拆分好的单元格,模型网络对每个单元格预测c个类别的概率值。值得注意的是,1个单元格可能会归纳为多个边界框中,但是只预测1组类别概率值,这是算法上的缺陷,相应的改进措施将在后文中论述。
1.3.2 网络设计
与大多数深度学习下目标检测的模型一样,YOLO算法采用CNN来提取特征,接着使用全连接层来获取预测值。YOLO算法的网络层级如图5所示,网络结构参考Google Net模型,包含24个卷积层和2个全连接层。这种深层模型主要由1×1和3×3的卷积层组成,且每个卷积层后面都接上一个批次归一化层和1个Leaky ReLu激活层。此外,在后期还引入了ResNet的残差模块来解决网络深度加深时出现的训练退化问题。

图5 YOLO算法网络架构Fig.5 Network framework of YOLO algorithm
1.3.3 损失函数
YOLO算法的损失函数主要分为3个部分,即坐标误差Lcoord﹝式(5)﹞、IOU误差Liou﹝式(6)﹞和分类误差Lcls﹝式(7)﹞:
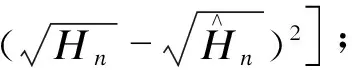
(5)

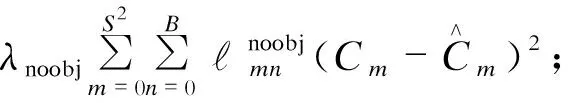
(6)

(7)

1.4 CNN的平移不变性和位置敏感性
基于深度学习的CNN在长期发展和应用中,尤其是在计算机视觉领域中,取得了很好的成绩。同时,也逐渐暴露出一些问题:分类网络的“位置不敏感性”(平移不变性)和检测网络中“位置敏感性”之间的矛盾[33]。如图6所示,深度神经网络在进行图像分类时﹝图6(b)和图6(c)﹞,无论图中的“猫”处于图片中的何处,最终都能识别出这张图片是“猫”,这种现象被称为“位置不敏感性”。但是对于“目标检测”这种输出结果包含“目标坐标位置信息”的检测网络﹝图6(a)﹞,一定是对位置敏感的。

图6 “位置不敏感性”和“位置敏感性”的示例Fig.6 Examples of the dilemma between ‘translation-invariance’ and ‘translation-variance’
目前绝大部分基于深度学习的检测网络都是以预训练的图像分类网络模型作为主干网络和特征提取网络,这些网络大部分属于“位置不敏感”,从而导致最终提取的特征丢失了很多信息。对此,一些方法比如空间变换网络(spatial transformer networks,STN)、FCN和数据增广等方法被提出,用于改善目标检测这类任务的检测效果。
2 模型改进
2.1 空间变换网络
CNN在图像分类中取得显著的成效,主要是得益于其深层结构具有空间不变性;因此,即使对图像中的目标物体作了平移变换或者旋转变换,CNN模型依然可以将其识别出来。可以通过选择合适的降采样比例来保证准确率和空间不变性,但是池化层带来的空间不变性是不够的,它受限于预先选定的固定尺寸的感受野。STN引进了一种可学习的采样模块Spatial Transformer[34],该模块的学习不需要引入额外的数据标签,可以在网络中对特征图进行空间变换操作。
CNN是尽可能让模型适应物体的形变,而STN是通过Spatial Transformer将形变后的物体变换回正常形态(比如将字摆正),然后再送入分类器识别。如图7所示,U为原始图像,V为经由网络映射后的输出结果。图7(a)中的图如果送入分类器进行识别的话,通常输出的结果是“字母a”,但是经过仿射变换后分类器的输出结果是“数字9”﹝图7(b)﹞。

图7 仿射变换示例Fig.7 Affine transformation examples
在实际生产作业环境中,监控探头等图像采集设备捕获的视频图像资料容易因光线干扰、设备安装位置移动和信号噪声等而产生畸变;因此,需要深度学习网络模型进行必要的修正,对获取到的ROI的特征进行变换,变为相对正确的姿态再送入分类器进行识别。
2.2 R-CNN系列下的改进
2.2.1 主干特征网络的调整
Faster R-CNN采用VGG16[35]作为主干网络(backbone)来提取输入图像的特征,已经取得了不错的成绩。从经验来看,神经网络的深度对模型性能影响很大,当增加网络层数后,网络可以进行更深更复杂的特征提取,所以理论上网络层数越深,模型的效果应该越好;但是,大量实验结果表明深度的网络会出现退化现象,网络准确度出现饱和甚至下降。深层网络存在梯度消失或者梯度爆炸问题,这使得深度学习模型很难训练。对此,带有“短路机制”的残差深度神经网络模型ResNet[36]被提出,可以很好地解决退化问题。本文在实例验证部分,还会选用ResNet的升级版ResNeXt网络[37]进行对比实验。
2.2.2 更精准和精细的RPN
对于RPN的改进,可以通过生成更多Anchor来实现。但是这样会增加计算量,降低模型预测速度。此外,针对电力设备锈蚀这一检测任务,分类单一而且数据集标注不够精确,刻意地增加Anchor未必能提高网络模型的效果,甚至会出现性能降低。
本文选用FPN对Faster R-CNN的RPN进行优化。FPN先进行传统的自下而上(bottom-up)的特征卷积,然后对左侧横向对应特征图进行特征融合,并生成自顶而下(top-down)的特征,从而得到不同分辨率下的特征。可以发现,FPN已经有不同大小的特征,无须像RPN中选用3种不同比率、尺寸的Anchor,只需要3种比率不同的框,即每级Anchor的尺寸相同。
2.3 YOLO系列下的改进
2.3.1 分类的置信得分计算
从前文对YOLO算法的介绍可知,对划分好的方格进行概率预测时,这些概率值其实是在各个边界框置信度下的条件概率,即Pclassi|object。因此,无论1个方格预测多少个边界框,其只预测1组类别的概率值。对此,可以把类别概率预测和边界框绑在一起,实现方法如式(8)所示,同时可以计算出各个边界框类别的置信度。
Pclassi|object×Pobject×Itruth,pred=PclassiI×truth,pred.
(8)
2.3.2 分类损失函数
YOLO算法在初代版本使用的是softmax函数,这种损失函数会扩大最大类别概率值而抑制其他类别概率值。其后期版本中已更改为每一个类独立使用逻辑分类器,使用交叉熵(cross-entroy)损失,这样能够更好地处理标签重叠(包含)关系。
2.3.3 多尺度预测
YOLO算法虽然检测速度快,但是初期最大的问题是对小尺寸物体的检测效果不理想。在YOLOv3中,通过对低分辨率的特征图与高分辨率的特征图进行特征融合的方法,形成新的特征图层,并对其作单独预测,形成最终的多尺度预测。
值得注意的是,YOLO系列中的多尺度有2种含义,一个是输入图像的多尺度,另一个是不同分辨率的特征图,本文选用后者。此外,原模型作者是先对图像进行归一化再缩放到统一尺寸。考虑到电力设备锈迹的不规则性,本文是先进行图像预处理直接缩放到统一尺寸,再送入CNN,并在YOLOv3的特征金字塔结构(Darknet-53)的基础上额外增加1次下采样用于模拟类FPN结构。
3 实验验证
3.1 数据集的收集与预处理
通过对变电站、输电网络等电力设备实际作业环境的实地图像采集和对电网系统监控视频流的图片抽取,收集形成初步的图像数据集。在图像预处理阶段,对图片的文件格式和编码格式进行统一。本文实验中模型训练所采用的数据集格式统一为RGB三通道的jpg文件,通过编写程序进行格式转换和必要的数据清洗,图8为初筛之后数据集的部分样本图片。

图8 数据集部分样本Fig.8 Dataset samples
3.2 数据集的标注
无论是R-CNN系列还是YOLO系列算法,都属于全监督机器学习模型,所以需要对数据集样本进行标注,以便网络在训练过程中有可以作为参照基准的目标位置和类别标签。本文使用目前主流的一款开源标注软件labelImg对已经清洗完毕的图片数据集进行标注,这个软件可以帮助用户快速生成带有Bounding Box(物体的目标位置)和Label(物体类别)数据的XML文件,供程序在模型训练时读取。
3.3 数据增广
锈迹识别与其他目标检测任务的主要区别在于:不同设备上铁锈的形状和颜色相差较大,相同设备在不同生产环境下产生的锈迹也有所不同。此外,人力对数据集的标注主观性比较强,对于一些锈迹的边缘区域难以标注或者是选择性标注。因此,用于训练的锈迹图像数据集具有自身性的缺陷。对此需要采取一些额外的操作来尽可能降低这些缺陷造成的影响。如图9所示,本文对清洗完毕的数据集采取一些非形变的几何变换类和颜色变换类的数据增广方法,来实现对那些形状、颜色差异性较大而且样本数较少的锈蚀图像的数据扩充。

图9 数据增广示例Fig.9 Examples of data augmentation
3.4 模型训练和结果分析
本文的实验环境为Intel(R) Xeon(R) CPU E5-2667 v2 @3.30 GHz,128 GB RAM,单张Nvidia GTX 1080Ti @12 GB,以及Ubuntu 16.04 LTS操作系统。算法模型基于PyTorch机器学习框架,实验验证的指标包括准确率和召回率,准确率为正确检测的目标数量与标记目标总数量之比,召回率为正确检测的目标数量与实际目标总数量之比。值得注意的是,本文对预测结果的阈值设置为0.8,这是相对于应用场景过高的一个数值。阈值越低,最终得到的召回率和精准率越高。为了在消融实验中得到较好的对比效果,故采用较高的阈值。真实生产环境下的预测结果可参照后文的预测可视化结果。
3.4.1 实验结果的可视化
实验结果表明Faster R-CNN在不同主干网络下表现无明显差异,可视化结果上不作冗余展示。图像检测的部分可视化结果如图10所示。
从可视化角度来说,最终训练好的模型都能够检测出较为明显的锈蚀。对比来看,Faster R-CNN的检测结果要优于YOLOv3的检测结果。这是因为Faster R-CNN中相对更加复杂的网络结构能够更深度地提取出锈蚀的图像特征,而且双阶法能够提案更多有意义的候选框。
3.4.2 实验数据及其分析
本文为了更具体地表现单阶法(以YOLOv3为例)和双阶法(以Faster R-CNN为例)的区别及不同改进方法对模型最终表现的影响,设计了消融实验,通过实验结果的对比,验证电力设备锈蚀检测技术的可行性和多场景应用的适应性。
如图11的损失曲线所示,以Faster R-CNN和YOLOv3的损失曲线为参照,模型基本在迭代数64 500左右收敛到局部最小值,故以下的消融实验中默认选用迭代数为65 000的模型进行测试。

图11 模型训练损失曲线Fig.11 Training loss curves of models
本文从整套消融实验中选取了具有代表性的9组实验,表1为这9组实验模型的最终测试结果。其中,第8组和第9组中的“Darknet*”代表对原YOLOv3网络结构的修改版本,包括多尺度参数的调整、网络增加下采样层等。

表1 模型测试结果Tab.1 Model test results
下面详细分析表格中所展示的消融实验结果。首先,最明显的一点是YOLO系列的速度比R-CNN系列快得多,这是因为R-CNN系列在使用RPN产生候选框时消耗了大量的计算时间。本文的实验平台采用的是高性能GPU计算平台,如果在中央处理器(central processing unit,CPU)平台上运行网络模型,则两者的差距会更明显。同时,更多的计算消耗带来的是更精准的预测结果,从测试结果数据上来看,R-CNN系列比YOLO系列准确度高约10%。
接着,从R-CNN系列来看,模型性能基本会随着各个模块的优化而得到提升,召回率呈现增长趋势。由第4组和5组分别与第3组的数据对比可知,FPN相比于STN的改进效果更好。这个现象可以从以下2个方面进行解释:①FPN产生的多尺度特征比RPN产生的多尺度Anchor更具有价值,尤其是在电力设备锈蚀这种形状颜色不规则的使用场景下,优势更为明显;②在数据预处理阶段已经对数据集进行了空间变换的增广,这样就使得STN的优势难以体现出来。召回率的增长基本符合理论预期,但是对比第5组和第6组的实验数据可知,召回率提高,而精准率却略微降低。这一现象主要是因为在对网络结构改进时,为了追求检测小物体而对PRN产生候选框的惩罚系数设置不合理,也就是侧重于Anchor的产生而不重视边界框回归或分类失败的损失。
然后,从YOLO系列来看,模型性能整体提升的幅度并不明显。值得注意的是,STN在YOLO下的优化效果要稍好于在R-CNN下的提升,这很大程度上取决于两者在特征金字塔模型设计上的差异。此外,Faster R-CNN下的RPN是一个很成熟的网络,这也限制了STN提升的空间。
3.4.3 实验结果总结
总的来说,单阶法、双阶法这2种目标检测方法都可以有效地检测出电力设备的锈蚀。2种方法的特点也非常明显:双阶法精度更高,模型训练时间快,检测速度稍慢;单阶法精度稍低,模型训练时间慢,检测速度快。通常情况下,对于那些配有高性能服务器的大型数据中心,对检测的实时性要求较低,则可以选用双阶法的目标检测算法模型。此外,由于拥有的海量数据可以及时更新模型,双阶法对模型训练也足够友好,训练成本低。而对于那些类似于无人机实时巡检任务的场景,采用单阶法的目标检测算法则是更好的选择。在考虑模型实际应用时,首要考虑的是在高速度和高精度之间的优先选择,如果没有明确界限,则需要再考虑模型后期升级成本或者模型运行的计算硬件条件,综合各方面因素选用较为合适的方案。
4 结束语
本文将深度学习中的目标检测技术应用到电力设备锈蚀检测中,并分别以Faster R-CNN和YOLOv3模型为基础模型进行实例验证。结果表明这2种模型都可以检测并定位较为明显的锈蚀,而且从实验数据可以看出这2种深度学习模型有着各自的特点:Faster R-CNN在准确度和小尺寸的锈蚀检测方面有着更好的表现;YOLOv3在检测速度上略胜一筹。实际应用时,可根据不同使用场景的需求选用不同的模型。该技术的应用可以很好地提升电力系统监控的自动化、信息化水平。
下一步的研究重心主要有以下几点:①增加数据集的样本数,初期考虑到数据资料保密性等原因,能收集的图像数据有限,而数据集规模的增大通常能够对模型的鲁棒性和精准度有所促进;②增强对于小尺寸目标的检测能力,加强小目标的特征表达,优化模型的损失函数(如交叉熵损失[38]);③裁剪模型,尽可能在不太影响预测结果的前提下减少网络层数和参数,减小执行预测任务时的计算量,实现边缘设备的模型部署[39-40]。
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
数学小灵通(1-2年级)(2021年4期)2021-06-09
江苏安全生产(2020年7期)2020-09-04
科技创新导报(2020年3期)2020-05-06
计算机技术与发展(2020年2期)2020-04-15
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
通信电源技术(2018年3期)2018-06-26
火力与指挥控制(2018年3期)2018-04-19
