
近似最近邻搜索中投影增强型残差量化方法
2020-11-11 09:01艾列富程宏俊冯学军
激光技术 2020年6期
艾列富,程宏俊,冯学军
(1.安庆师范大学 计算机与信息学院,安庆 246133;2.安庆师范大学 智能感知与计算安徽省高校重点实验室,安庆 246133)
引 言
最近邻搜索是图像检索和机器学习领域的重要基础性问题,但以图像特征为代表的大规模高维特征使得精确最近邻搜索需要花费更多的时间和更大的存储开销。如何快速并准确地获得特征向量的近似最近邻成为一个重要研究内容,即:在保证近似表示精度的情况下,如何设计紧凑的编码来标识特征向量,降低存储空间以及加速特征向量之间欧氏距离的计算。
根据衡量特征向量之间相似度距离的方式的不同,用于图像特征向量近似表示的编码算法可以划分为哈希编码算法和基于量化的编码算法两大类[1]。虽然都用于降低图像信息的存储空间需求,但不同于图像压缩[2],用编码对特征向量进行压缩存储时,允许特征向量在重构时存在误差,但要尽可能小。
欧氏距离比汉明距离对计算需求较大,但具有更好的相似度区分能力。基于量化的编码算法不仅采用二进制编码标识特征向量以减少存储空间需求,还使用近似欧氏距离保持区分能力。向量量化采用一种映射方式,又称为量化器[3],将特征向量映射到事先训练的码书中最相似的单词,并且用于近似表示该特征向量,单词的二进制编号用于标识与之对应的特征向量。
率先将量化模型用于近似最近邻搜索和图像特征检索的积量化算法(product quantization,PQ)[4-5],将特征向量分割为若干段子向量,并分别在子向量所在的向量空间训练量化器。将特征向量在各量化器的量化输出串联起来,用于近似表示该特征向量。基于PQ的思想,学者们提出了各种改进方法,具有代表性的研究工作包括:GE等人提出用带参量和无参量两种笛卡尔优化分解来最小化量化误差[6];参考文献[7]中采用倒排索引或多索引对特征向量集进行划分后,再在每一个子集上进行笛卡尔优化分解;为了进一步减少量化误差,HEO等人[8]编码总长度不变的情况下,预留一定长度的部分编码给相同量化输出但量化误差不同的向量;NOROUZI等人提出了正交k均值算法及笛卡尔积k均值算法[9];双层PQ[10]和局部优化PQ[11]以及利用图形处理器(graphics processing unit,GPU)[12]从硬件层面对PQ进行加速以及用于聚类[13]等PQ的扩展应用研究。
PQ思想基于一个假设前提:特征向量的各个维度分量相互独立,不存在相互关联。然而,实际情况一般不会总是满足这种假设。为此,BRANDT[14]将转换编码和PQ相结合,在特征向量的每个主成分维度上分别训练量化模型。在此基础上,子空间量化算法(即通过将向量空间划分为多个子空间)被用来解决特征向量维度的空间分布不平衡问题[15]。类似的研究工作还包括树形量化方法[16]对特征进行分解,在子向量空间训练子码书的同时对各子码书之间非正交联系进行约束。
上述量化模型大都考虑如何在单层码书的前提下,尽可能地减少量化误差,然而码书的大小决定了量化误差的大小。通常地,码书中单词的数量越多,会使量化误差越小,然而这带来问题的码书训练所需要的开销也就越大。对此,残差向量量化(residual vector quantization,RVQ)[17]利用多层小规模码书构成的量化器,其码书层数越多,量化误差越小,特征向量的近似表示精度越高。通过对RVQ引入正交约束条件,正交RVQ[18]设计了查询点和重构点之间近似欧氏距离计算方法。在前期研究中,提出了增强型残差量化(enhanced residual vector quantization, ERVQ)[19],在RVQ基础上对码书训练过程进行迭代优化,主要目的是在不增加码书规模的条件下,降低总体量化误差,得到更准确的码书,进而提升检索精度。
这类模型虽然训练得到的码书的区分度较高,但训练以及量化过程均发生在特征向量所在的原始向量空间。向量维度越高,带来的最直接影响是在高维向量空间训练码书花费的时间越多。因此,特征向量的高维度现象是制约这类量化方法的训练效率的关键因素之一。参考文献[20]中虽然将高维向量投影到低维空间来训练码书,但没有考虑到投影过程中所带来的投影误差。参考文献[21]中提出了一种投影残差量化(projected residual vector quantization,PRVQ),在训练量化模型时同时考虑到了投影误差,然而却没有考虑残差量化方法中存在码书训练并不是最优化总体量化误差的不足。
作者在前期关于增强型残差量化模型的研究工作基础上,提出一种将主成分分析方法与该模型相结合的量化方法,通过将特征向量从原始高维向量空间投影到低维向量空间,并低维向量空间进行码书训练,提高码书训练的时间效率。由于降维过程使特征在投影过程中产生投影误差,会降低所训练的低维向量码书的精度,而码书的精度直接影响到特征的检索准确率。为此,在优化码书的过程中,同时考虑训练码书产生的总体量化误差以及投影所产生的误差。在低维空间训练码书旨在提高码书训练的时间效率;码书优化旨在保证训练所生成的码书的精度。在此基础上,设计一种针对该量化模型的特征向量之间的欧氏距离近似计算方法,提高检索效率。
1 前期工作
作者前期所提出的ERVQ[19]是由多层码书构成,逐级量化的量化模型。所有层的量化输出向量通过累加形成输入特征向量的重构向量。除去第1层和最后一层,利用每层码书进行量化时产生的量化误差作为下一层的量化输入,旨在对特征向量应用多层量化尽可能地减少特征向量的近似表示误差。ERVQ由码书训练和量化特征向量两个部分构成。
1.1 ERVQ码书训练
为了使训练得到的多层码书能更准确地对输入特征向量近似表示,ERVQ利用k均值算法训练得到每一层初始码书后,通过总体量化误差目标函数对初始码书进行迭代优化。其中,采用RVQ[17]来训练进行迭代优化所需的初始码书;在此基础上,对每一层码书按顺序进行迭代优化,不断更新码书。
一次迭代过程包括所有层码书的顺序优化。对于某一层码书,其优化的具体实现思路是基于其它层的码书,把该层码书当作最后一层码书进行重新训练,并将新的码书代替原来的码书以及更新训练集的量化输出[22]。当目标函数收敛到一定程度时,迭代优化过程停止。
1.2 ERVQ量化特征向量
给定特征向量v,图1是一个两层ERVQ的逐层量化过程示意图。

Fig.1 Quantizing feature vector by ERVQ

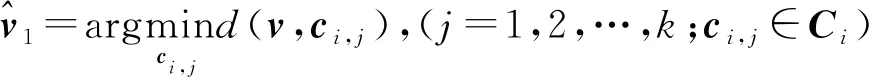
(1)
式中,i表示当前层码书的层号;C1为第1层码书的k个聚类中心对应的集合,k为每层码书的聚类中心数;ci,j为第i层码书中第j个聚类中心。
(2)根据下式,计算v的第1层量化误差对应的误差向量e1:
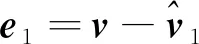
(2)
对于层数大于2的ERVQ,需要继续将第2层的量化误差输入到第3层进行量化,直到最后一层。
2 投影增强型残差量化
投影增强型残差量化方法将主成分分析方法和前期研究的增强型残差量化方法相结合,在低维空间训练量化模型得到码书以提高训练效率,与此同时,为了减少投影误差对码书精度的影响,通过迭代优化的方式提升码书精度。
投影增强型残差量化分为训练阶段和量化阶段,其中,训练阶段用于量化模型训练得到多层低维空间的码书;量化阶段则是对图像特征向量进行量化生成编码的过程。
2.1 码书训练
码书训练分为两个阶段:初始码书训练和码书优化两个阶段。
2.1.1 初始码书训练 初始码书训练过程采用类似于PRVQ[21]方法,每层初始码书的训练过程需包括步骤:利用主成分分析(principle component analysis,PCA)构造降维投影矩阵、训练集投影降维、低维向量空间上利用k均值算法训练码书、低维向量空间上量化训练集、逆投影和总体残差向量计算。
针对图2所示训练两层初始码书的示例,第1层初始码书训练过程如下:首先,利用PCA在训练集X上生成用于特征向量降维的投影矩阵M1,并将X投影到低维向量空间得到X1;然后,利用k均值算法对投影降维后的训练集进行聚类,生成第1层码书C1;紧接着,利用第1层码书,根据(1)式对训练样本集X1中特征向量进行量化;最后,利用逆投影矩阵,将X1的量化结果逆投影到原始维度,计算和原始向量之间的误差向量集E1并作为第2层码书训练的输入。
第2层初始码书C2的训练同第1层初始码书的训练方法一致,同样通过以上几个步骤完成。
2.1.2 码书联合优化 基于上述得到的初始码书,提出一种联合优化方法,通过降低特征向量的总体量化误差来对初始码书进行优化,期望得到区分度更高的多层码书,进而提高特征向量的近似表示精度。
对于L层(码书总层数L>1)初始码书,其优化方法是一个顺序优化的过程,即:从第1层码书开始依次优化直到最后一层码书。
对于第i层(1≤i≤L)码书,其优化过程通过以下步骤完成:(1)计算训练样本集中每个样本特征向量与其它层对应的量化结果对应向量之和的残差向量。这里,由于特征向量与其对应量化结果对应的向量维度不同,因而在此计算过程中,需要根据每层码书对应的逆投影矩阵,将量化结果投影到原始向量的维度空间;(2)更新码书。对具有相同第i层编码的样本特征向量对应的残差向量求均值,并将其作为新的码书;(3)根据新生成的码书,对训练样本集进行量化,更新从第i层码书到最后一层码书对应的编码。
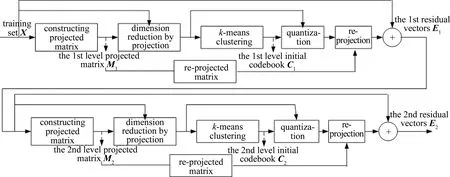
Fig.2 Training two-level initial codebooks
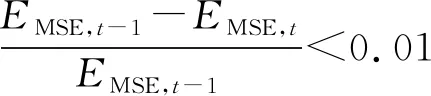
2.2 特征向量量化
给定一个特征向量v,图3中给出了投影增强型残差量化对v进行量化的两层示例。具体过程如下:(1)利用训练阶段得到的第1层投影矩阵,将v投影降维到第1层码书所在低维向量空间得到vp;(2)基于第1层码书,根据(1)式对vp进行量化,得到Q(vp);(3)利用投影逆矩阵,将第1层的量化输出逆投影到原始高维向量空间,计算v与逆投影向量之间的残差向量e1;(4)利用事先训练的第2层投影矩阵,将e1投影降维到第2层码书所在的低维向量空间得到e1,p;(5)根据第2层码书,利用(1)式对e1,p进行量化,得到Q(e1,p)。
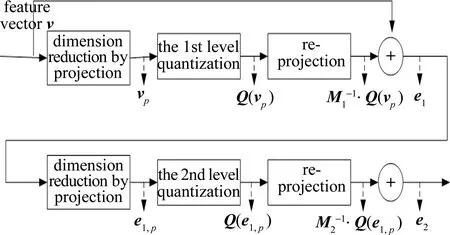
Fig.3 Quantizing vector by projection-based enhanced residual vector quantization
如果投影增强型残差量化模型的层数大于2,那么特征向量在之后码书层的量化方式与第2层一致。
3 近似最近邻完全检索
为了评估投影增强型残差量化对特征向量的近似表示精度,类似于参考文献[19],设计近似欧氏距离计算方法并用于完全检索。
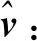
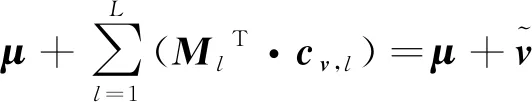
(3)
式中,μ为应用PCA之前用于调整中心的均值向量,cv,l∈Cl,cv, l(D×1向量)为v(d×1向量)在第l层码书Cl的量化输出,D为投影降维后的向量维度,d为向量的原始维度,L为投影增强型残差量化的码书总层数,MlT(d×D投影矩阵)为第l层的逆投影矩阵。
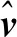
(4)
4 实 验
4.1 实验数据集和实验环境
本文中将在GIST和VLAD两个公开数据集[23]上评估应用了投影增强型残差量化在码书训练和完全检索方面的性能。如表1所示,GIST和VLAD两个数据集包含3个子集,其中,训练集用于训练码书;数据库集是用于获取从中检索同查询点近似的特征向量;查询集用于对检索算法进行性能评估。

Table 1 Information of experimental datasets
所有实验都是在一台Intel Core i5 2.8GHZ CPU, 32G内存的PC,MATLAB 2011环境下完成的。
4.2 投影维度对量化误差的影响
图4和图5反映了GIST和VLAD数据集上投影维度D∈{23,24,25,26,27,28,29}对总体量化误差的影响。实验参量设置中,投影增强型残差量化的每层码书中聚类中心数量k固定为256,码书层数为L∈{4,8,16}。
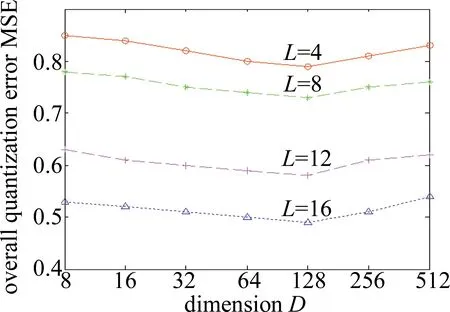
Fig.4 Overall quantization errors over variant projected dimensionality on GIST
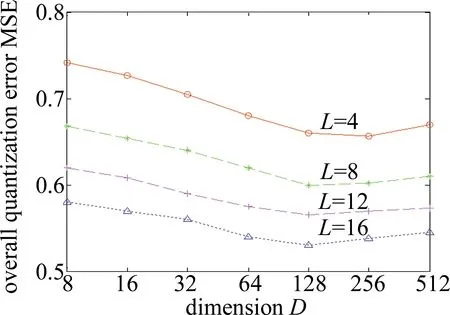
Fig.5 Overall quantization errors over variant projected dimensionality on VLAD
如图4和图5所示,当码书层数固定时(如L=8),随着PCA投影的维度从512维~8维的变化,总体误差呈现出先减少后增加的曲线变化。观察发现,当投影维度D=128维时,GIST和VLAD数据集上总体量化误差最小。
4.3 投影维度对检索精度的影响
图6和图7反映了GIST和VLAD数据集上投影维度D∈{23,24,25,26,27,28,29}对检索精度(用召回率Rrecall@n(n=100)表示,其中n表示检索返回的结果数量)的影响。实验参量设置中,投影增强型残差量化的每层码书中聚类中心数量k固定为256,码书层数为L∈{4,8,16}。
如图6和图7所示,从投影维度512维开始,检索精度先是随着维度降低而不断提升直到投影维度为128维,随后检索精度随着投影维度的降低而不断降低。对比图6和图7,参量D的变化对VLAD数据集上检索精度的影响比GIST更大。
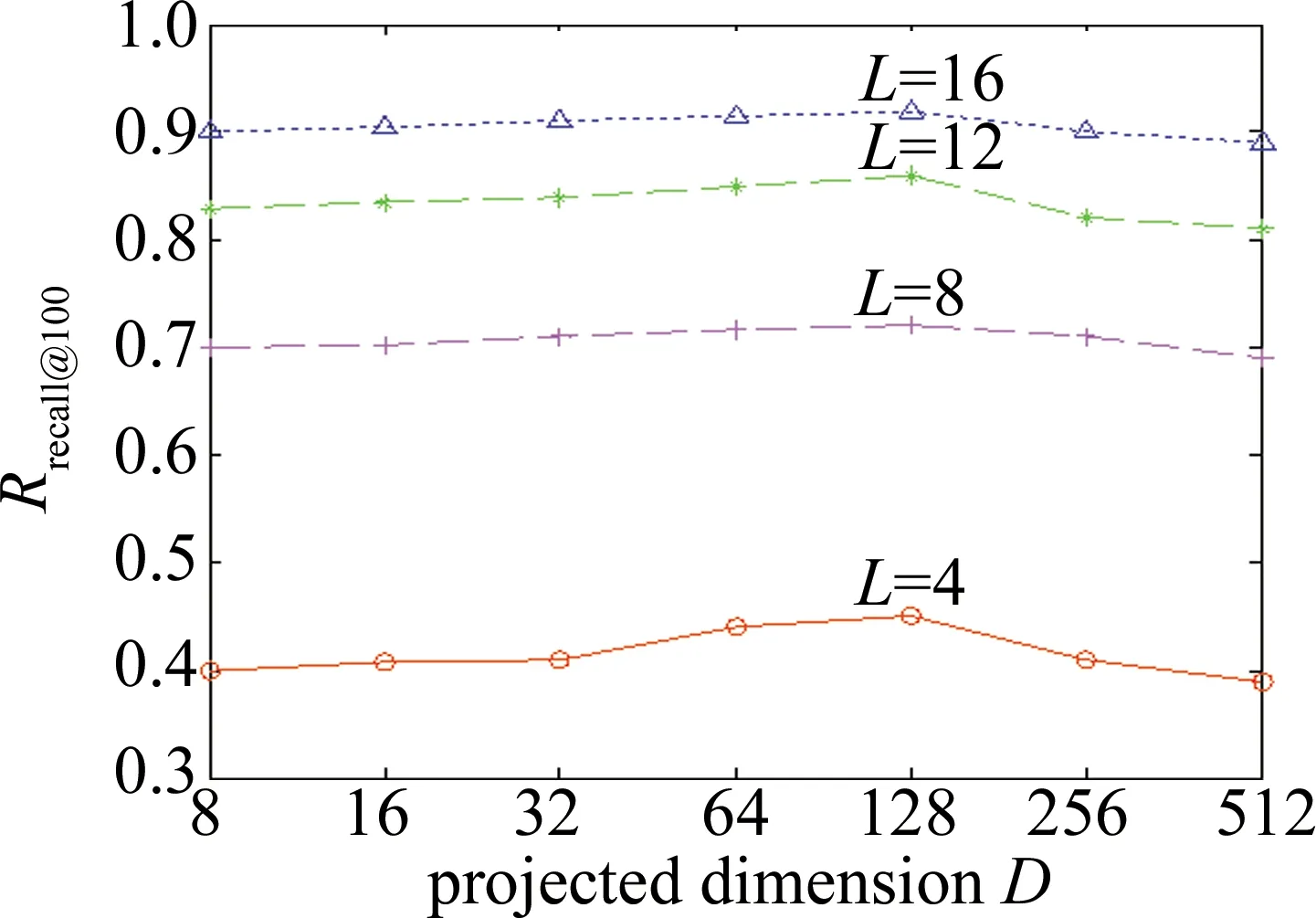
Fig.6 Rrecall@100 over variant parameter D on GIST
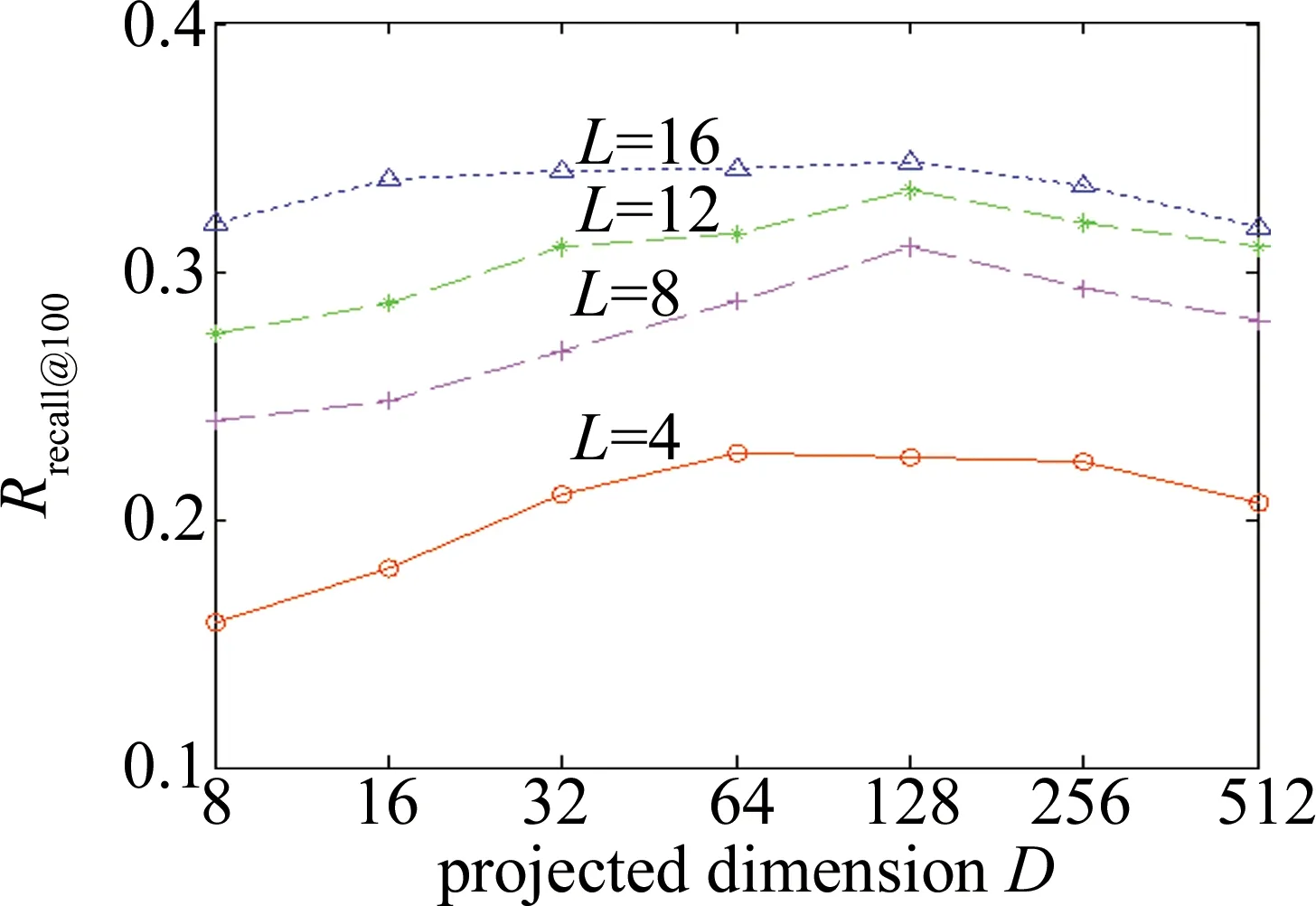
Fig.7 Rrecall@100 over variant parameter D on VLAD
4.4 同其它方法实验对比
针对最近邻搜索的性能对比,将投影增强型残差量化(projected enhanced residual vector quantization,PERVQ)与其它4种方法(见表2)从检索精度和检索效率(检索时间)两个方面进行比较。在表2所示4种方法的相关文献[4,17-19]中,依据参考文献中实验数据,综合检索速度和检索精度平衡,都是采用8个子码书,并且每个子码书都是由256个聚类中心构成。
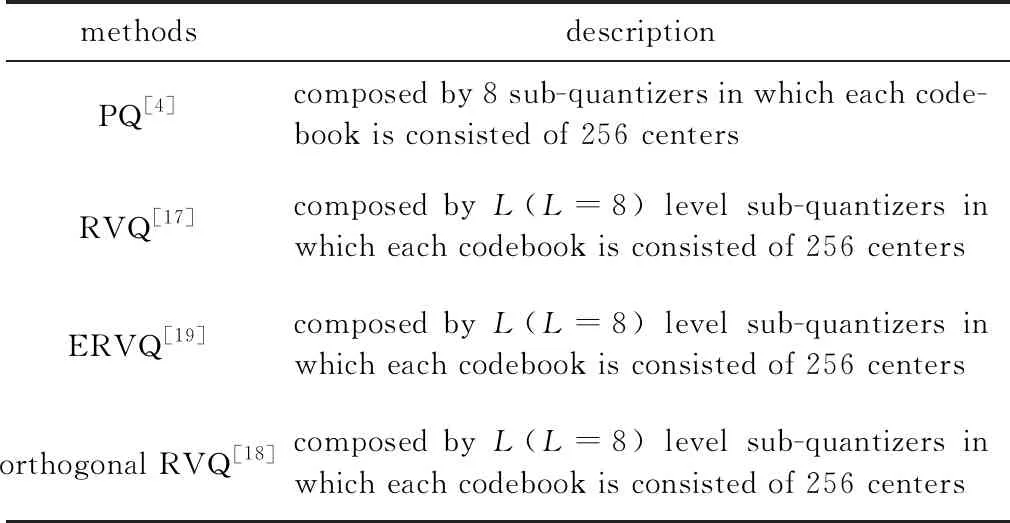
Table 2 Description of compared methods
所有方法均采用相同的编码长度,检索精度用召回率Rrecall@n指标进行评估。
为公平起见,PERVQ采用同PQ,RVQ,ERVQ和正交RVQ相同的码书参量,即L=8层码书构成的8级子量化器,并且每层码书的码书规模设置为256。
4.4.1 训练码书的时间开销对比 PERVQ建立在ERVQ的基础上,解决ERVQ在原始高维向量空间训练码书带来的码书训练时间效率受特征向量维度制约的问题,旨在提升码书的训练效率的同时,综合投影误差和量化误差对低维向量空间的码书进行优化。
图8为GIST数据集上RVQ,ERVQ以及投影到各个向量维度D∈{23,24,25,26,27,28,29}上,训练8层码书对应码书所花费的时间。相比RVQ,由于ERVQ和PERVQ都增加了码书优化步骤用于提升码书精度,因而额外增加了优化码书阶段的时间开销。从图8可以观察到,将PCA和ERVQ结合后,PERVQ训练码书花费的时间要明显少于ERVQ,此外,当D∈{23,24,25}时,PERVQ训练码书所花费的时间比RVQ少。
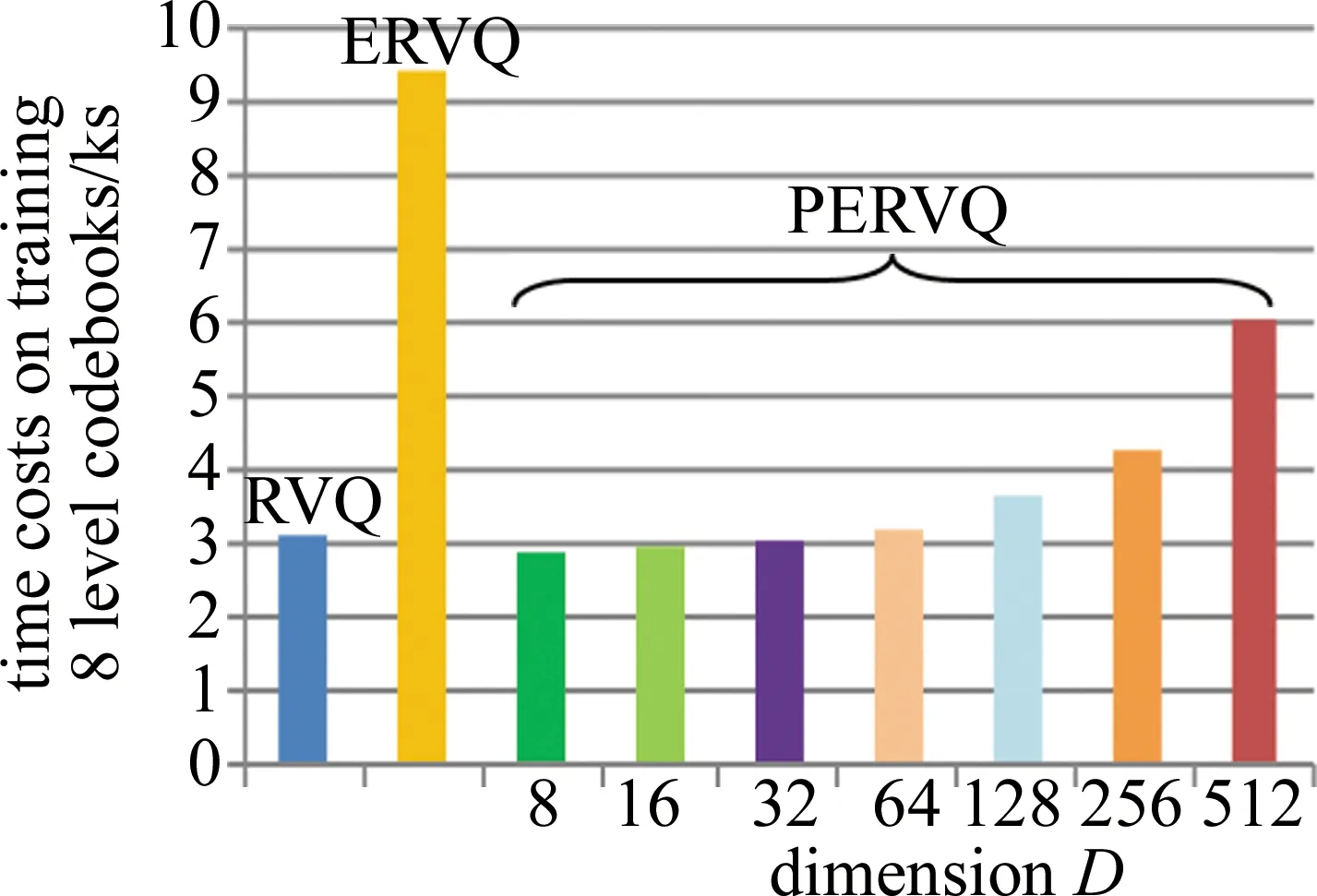
Fig.8 Time cost comparison of different methods on GIST
4.4.2 检索精度对比 从图6可以观察到,在GIST数据集上,当L=8,各层码书规模为256个聚类中心,PERVQ在D=128时,具有最优的近似最近邻完全检索精度。图9为在GIST数据集上不同方法的检索精度。PERVQ采用8层码书,每层码书初始聚类中心数为256。从图9可以看出,PQ方法检索性能明显不如其它方法,RVQ和ERVQ由于考虑了量化误差,在相同编码长度下,其检索精度有了较大提升,优于积量化。PERVQ不仅考虑了总体量化误差,也考虑了投影误差,检索精度较残差量化方法好于RVQ,ERVQ和PQ。PERVQ同orthogonal RVQ具有相当的检索精度,但orthogonal RVQ是在原始高维向量空间进行多层码书训练和优化。
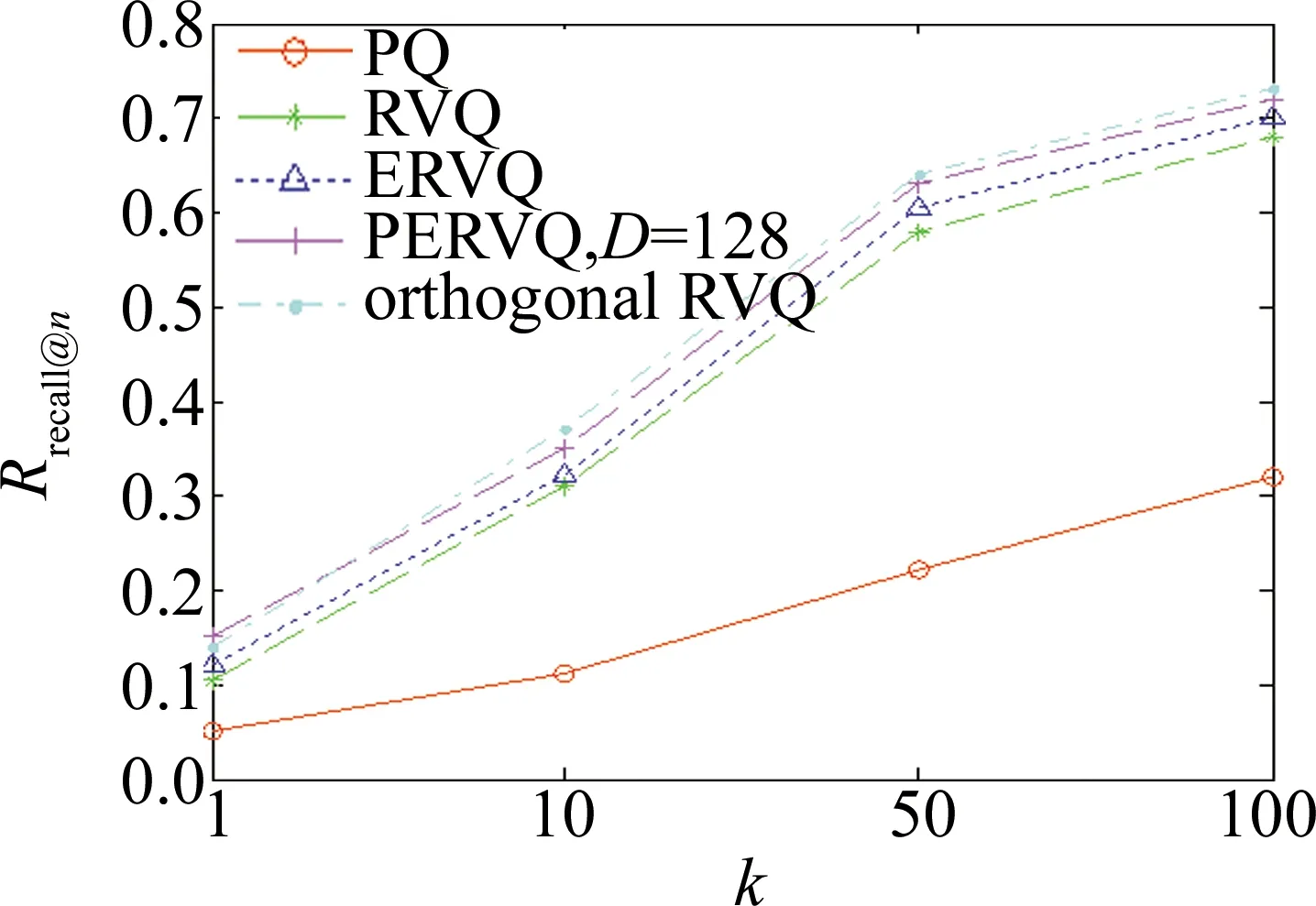
Fig.9 Rrecall@n comparison of different methods on GIST
4.4.3 检索效率对比 在GIST数据集上对不同方法的检索时间进行了比较,所有方法的参量设置同上,检索时间如表3所示。
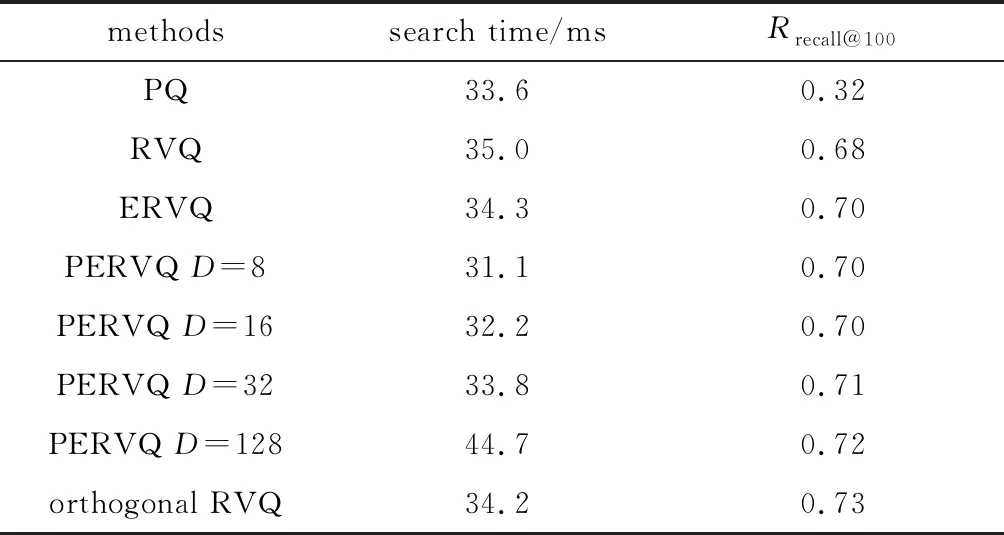
Table 3 Comparison of search time on GIST
PERVQ,ERVQ,RVQ和orthogonal RVQ在应用完全检索时都是利用向量的近似表示来计算查询向量和库向量之间的近似欧氏距离。不同之处在于ERVQ,RVQ以及orthogonal RVQ的查找表构造是在高维空间进行,而PERVQ的查找表是在低维空间进行构造,因而PERVQ生成查找表比ERVQ和RVQ具有更快的速度,但是PERVQ将查询向量投影到低维空间相比RVQ和ERVQ需要花费额外的投影时间。因此当构造查找表对效率的提升程度大于向量投影对时间效率影响程度时,PERVQ比ERVQ,RVQ以及orthogonal RVQ具有更好的检索速度。
由表3可见,PERVQ的近似最近邻完全检索在投影维度D∈{23,24,25}时,其检索时间花费少于PQ,RVQ和ERVQ。结合图6和图9,当D∈{23,24,25},PERVQ仍具有同ERVQ和orthogonal RVQ相当的检索精度。
5 结 论
提出了一种投影增强型残差量化方法,通过结合前期研究工作,在训练码书时,将图像视觉特征从高维向量空间投影到低维向量空间,降低训练过程中的时间开销;为了降低投影到低维向量空间带来的投影误差,在训练码书的过程中,同时考虑量化和投影所产生的误差,进而保证所生成码书的精度。实验结果表明,提出的PERVQ在码书训练时间效率上,较ERVQ具有明显提升作用,同时保证了检索精度。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
网络安全与数据管理(2022年3期)2022-05-23
保定学院学报(2022年2期)2022-04-07
数学物理学报(2021年1期)2021-03-29
北京航空航天大学学报(2020年10期)2020-11-14
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
自动化学报(2019年6期)2019-07-23
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
许昌学院学报(2018年4期)2018-05-02
