
基于层间互相关感知损失的风格迁移方法*
2020-12-04 08:56庄轩权李彩霞黎培兴
中山大学学报(自然科学版)(中英文) 2020年6期
庄轩权,李彩霞,黎培兴,2
(1. 中山大学数学学院,广东广州510275;2. 中山大学广东省计算科学重点实验室,广东广州510275)
风格迁移技术指对某个图像进行渲染,使其艺术风格与某个艺术绘画作品相似,且画面的主体内容不变(见图1)。2015 年Gatys 等[1-2]开创性地将卷积神经网络运用到风格迁移领域,提出了度量特征相关性的Gram 矩阵用于风格表示,开创了现代风格迁移时代。Gram 矩阵的核心思想是利用预训练网络强大的特征提取能力得到有意义的特征映射输出,并将特征映射之间的相关性作为风格的度量。此后,Justin 等[3]基于Gram 矩阵设计了基于前馈网络的快速风格迁移模型,使得Prisma等图像艺术风格化的应用得以流行。

图1 风格迁移示例Fig. 1 Examples of style transfer
然而自Gatys等提出Gram矩阵以来,风格迁移研究领域对于损失函数的构造一直没有足够的探索,本文提出使用层间互相关矩阵作为Gram 矩阵的代替或补充,在得到良好结果的情况下缩短20%以上的计算时间,从而提高训练效率。
1 风格迁移技术
2015 年,Gatys 等[1-2]提出使用Gram 矩阵来度量图像的风格,由此开辟了基于深度学习的图像风格迁移领域。对于一张图片,使用预训练好的分类网络,如VGG-16[4],将图片输入得到某一层的特征映射,对特征映射的各个通道两两做互相关计算得到对称矩阵,这个矩阵就称为Gram矩阵。严格来说,衡量图像之间风格差异的损失函数LS(Is,X)定义为

其中,Is和X 分别表示风格图像和待优化图像,li表示特征映射处于预训练网络的层数,Lli为第li层两图像间的风格损失,wli为对应的权重参数。第ls层的风格损失函数定义为


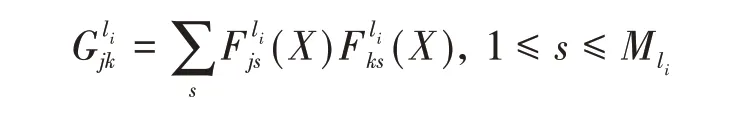
风格迁移任务的目标是使用风格图像的纹理特点绘制内容图像的内容信息。因此,除了对风格进行迭代逼近之外,对内容的逼近也同样重要。在Gatys 等的实验中,直接使用预训练网络的中间几层特征映射之间的像素值差异作为衡量语义信息相似度的标准,并获得了良好的效果。这其中的原因是这些预训练网络都是以图像分类任务为目标进行训练的,训练集包含了大量的物体类别,因此卷积神经网络在训练中降低多类别交叉熵损失函数的过程中,卷积层的卷积核在试图提取各种能描述不同物体差异的信息,这其中就包括了低层到高层的语义信息。以内容图像和待优化图像作为输入,预训练网络在第li层得到的特征映射的损失严格定义为
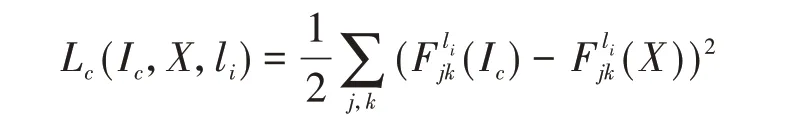
其中,Ic表示内容原始图像,X 表示待优化图像,j表示在第li层特征映射中第j个卷积核的编号,k表示该卷积核得到的特征映射中第k 个位置的像素点。可以看出,衡量两张图像内容上差异的损失函数仅仅只是简单使用特征映射之间的平方损失,我们不得不感叹于卷积神经网络强大的特征提取能力。由各层内容损失得到的总体内容损失为

其中,wli为赋予第li层内容损失的权重。由此我们得到了以待优化图像,内容图像,风格图像作为共同输入的三元损失
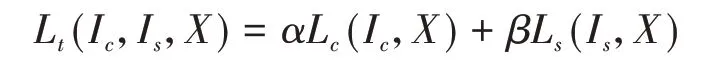
其中α 和β 为内容损失和风格损失的权重参数。在原文中,作者选择的预训练网络是VGG-16,VGG-16在VGG系列的卷积神经网络中是应用最为广泛的,因为其具有良好的准确率以及不错的效率。在内容损失方面,作者选取了conv4_2 作为计算内容损失的特征映射。在风格损失方面,作者选 取 了conv1_1、 conv2_1、 conv3_1、 conv4_1、conv5_1 作为计算风格损失的特征映射,并赋予各层相等的权重,而α/β选取10-3或10-4。
尽管使用Gram 矩阵进行的图像风格迁移取得了良好的效果,但对于Gram 矩阵的本质、是否有其他方式度量风格差异等问题,文中并没有给出答案。Li 等[5]从迁移学习的角度出发去看图像风格迁移。文章将风格迁移任务看做是一种域适应的问题,并从理论上证明了Gram 矩阵实际上与二阶多项式核的最大均值差异等价。从这种等价关系可知:
(i)图像的风格可以本质上表示为卷积神经网络中不同卷积层下的特征分布;
(ii)风格迁移的过程可以看成是从内容图像到风格图像的一种分布调整。
Li 等尝试将二阶多项式核函数替换成其他多项式核函数或高斯核函数,实验结果表明,不同的核函数替代Gram 矩阵进行风格迁移能得到类似的良好结果,同时又有许多不同的细节上的变化,从最小均值差异出发使用不同的核函数度量风格差异的做法大大丰富了风格迁移结果的多样性。
针对Gatys 等[1]通过迭代更新像素值的方式效率较低的问题,以Justin等[3]为代表的一系列研究提出了使用前馈网络直接输出风格迁移结果的快速风格迁移方法,按模型可承载的风格数量可划分为单模型单风格方法[3,6]、单模型多风格方法[7]、单模型任意风格方法[8-9]。
自2014 年Goodfellow 等[10]提出生成式对抗网络(generative adversarial networks,GAN) 以来,有关生成式对抗网络的研究便一直活跃在众多研究领域当中。深度卷积生成式对抗网络[11]提出使用卷积层和转置卷积层对生成式对抗网络进行改进,为生成式对抗网络在图像领域的发展开拓了更优的思路。
近年来,部分研究将生成式对抗网络运用于两个域之间的图像的相互转换,这可以看作是一种广义上的风格迁移方法。Zhu 等[12]提出使用两个对称的生成式对抗网络构造一种循环一致性损失,从而实现将输入的图像向特定分布转换的目的,如将夏季的图像转换为冬季的图像。类似的想 法 还 有DualGAN[13]和DiscoGan[14]等。Style-GAN[15]利用风格迁移领域提出的AdaIN 模块[8]对生成式对抗网络进行优化,成功实现了对输入图像的各种细节进行微调的重大突破,成为生成式对抗网络和广义风格迁移领域的里程碑之一。
尽管使用生成式对抗网络系列的方法也能做到将输入的图片进行纹理风格上的转化并保持图片内容上的一致性,但和基于Gram 矩阵的一系列风格迁移方法有许多差异:
(i)基于Gram 矩阵的风格迁移方法使用Gram矩阵衡量图像之间的风格差异,是一个可以被计算的统计量,可以量化地给出任意一张图片的风格数值;生成式对抗网络系列方法无法显式给出风格的定义,而是通过对抗训练对两个域的分布进行学习,试图让网络自行拟合出一套进行风格转换的参数。
(ii)基于Gram 矩阵的风格迁移方法可以学习任意单一图像的纹理风格特征并将其迁移到任意图像之上;而生成式对抗网络由于损失函数和训练的动机限制,只能学习一类图像的风格而无法刻画单一图像的纹理风格特征,比如其通过训练可以学习画家梵高的画作整体风格,但无法很好地学习梵高的《Starry Night》这幅画作的风格。尽管一些工作尝试通过生成式对抗网络学习单一图像的纹理分布,但基本只能输出与原风格图像在内容上极度统一的结果[16],而基于Gram 矩阵的方法通过将对多个图像分别进行学习得到的参数进行简单组合就可以得到融合后的风格输出,因而也能学习一类图像的风格纹理特征。
(iii)由于(ii)中提及的原因,基于Gram 矩阵的风格迁移方法得到一个输出结果良好的模型所需的数据获取成本会远低于基于生成式对抗网络的方法;另外,由于期望网络自行学习一种风格纹理的概率分布,在训练生成式对抗网络时需要更庞大的参数量,以及更多的训练技巧和尝试从而规避无法收敛或学习不出特征的问题,其训练的时间成本也远大于Gram矩阵方法。
(iv)生成式对抗网络在生成高分辨率的图像上效果不如低分辨率图片,或是需要更大的模型和更长的训练周期才能达到较好效果;基于Gram矩阵的方法则在各个分辨率尺度上都有稳定的表现。
自Gatys 等[1-2]的工作以来,基于Gram 矩阵的风格迁移方法一直是该领域的主流方法,至少现阶段包括基于生成式对抗网络在内的方法都还无法得到这样高效且效果良好的风格迁移结果。但Gram 矩阵作为人工设计的统计量,必然受到人们先验知识的限制,通过对生成式对抗网络训练过程的深度挖掘以及与Gram 矩阵之间的关联的分析或许能为风格迁移进一步的发展提供动力。
2 基于层间互相关感知损失的风格迁移技术
2.1 层间互相关矩阵
卷积神经网络的卷积核提取的特征等级往往与该卷积核所处的深度有关,即浅层的卷积核提取低级特征,深层的卷积核提取高级特征。理论上,Gram 矩阵只能表现同层级的特征之间的相关程度。针对这一问题,我们提出使用层间互相关矩阵来进行补充。
给定图像I 在预训练网络的第l1、l2层的输出Fl1(I)及Fl2(I)(l1<l2),层间互相关矩阵为一个Nl1× Nl2的矩阵Gl1l2=(Gjk)Nl1×Nl2,

其中Nl1和Nl2分别为预训练网络的第l1层和第l2层的通道数,M表示特征映射的长宽乘积,D(*)为降采样函数。
由于不同深度的特征映射的长宽不一致(如VGG-16不同层的特征映射的长宽最大相差16倍),我们需要对浅层特征映射使用降采样或对深层特征映射使用升采样,使得用于层间互相关矩阵计算的两个特征映射的长宽一致。考虑到计算成本等原因,我们选择对浅层特征映射进行降采样,降采样函数可使用平均池化或最大池化等。
对于不同的特征映射组,需要使用不同的降采样参数使得两者得感受野对齐。以VGG-16网络为例,通过对感受野的计算可以发现,特征映射relu2_1的每一个元素实际上对应着特征映射relu1_1 中一个8× 8 大小的区域。具体地,我们需要在大小为3 的填充下使用8× 8 大小的池化滤波器以步长为2的方式对relu1_1进行池化操作。表1中为VGG-16 中部分特征映射层使用池化方式进行层间互相关计算应该使用的参数,特征映射层A为池化操作的作用层。

表1 层间互相关矩阵计算池化操作参数Table 1 pooling parameters for cross-layer correlation matrix computation
2.2 层间互相关矩阵与Gram矩阵对比
2.2.1 语义特征的登记对比 Gram 矩阵可以理解为层内互相关矩阵,计算同等级语义特征间的相关程度。与之对应,层间互相关矩阵计算不同等级语义特征间的相关程度。从这个意义上来理解,Gram 矩阵和层间互相关矩阵在对图像风格的描述上应该是互为补充的。
从直观理解出发,层间互相关矩阵的意义甚至比层内互相关矩阵更重要。举例而言,不同的颜色应该属于同一等级的特征,不同的动物、植物也应该属于同一等级的特征,而对于图像中一块具体的感受野来说,只应该是某个颜色或者某种动植物,而不应该同时具备多个。相比之下,层间互相关矩阵的可解释性更强,如某种动植物或山水的特征与某个颜色或线条纹理的特征相关性强,可以理解为作品中对某种事物的刻画使用了某种技法,这些相关性共同描述了作品的艺术风格。因此,如果从相同深度的卷积核只提取同等级的语义特征这个前提出发,层间互相关矩阵对于风格差异的描述更加具有可解释性。然而在实际的预训练网络中,相同深度的卷积核提取的特征有时也难以说明是否为同一等级的特征,甚至有许多卷积核提取的特征拿出来单独看无法从人的视觉角度理解,因此无论层间互相关矩阵还是层内互相关矩阵在实际的应用中都表现出相似的效果。
2.2.2 计算与存储效率对比 显然,区别于Gram矩阵的对称方阵的特点,层间互相关矩阵是一个C1× C2的矩阵,且每个元素对应的含义都唯一。而相比之下Gram 矩阵有将近一半的重复元素,信息的冗余度较高,占用大量内存的同时却没有尽可能精简出不重复的信息。层间互相关矩阵通过融合两个特征映射层使得其可以用单个矩阵对两个特征映射层的信息进行表达,且其存储和计算量都低于Gram矩阵方法。
以relu3_1 和relu5_1 为例,使用Gram 方法进行风格迁移需要存储的Gram 矩阵大小为2562+5122= 327 680,使用层间互相关矩阵方法需要存储的矩阵大小为256 × 512 = 131072,仅为Gram方法存储量的40%,自然,风格损失的计算量也为Gram 方法的40%;而计算Gram 矩阵本身的成本也比计算层间互相关矩阵要高,Gram 矩阵方法需要 进 行 约2 ×(2562× 642+ 5122× 162)≈6.7× 108次运算,层间互相关方法仅需进行约2 ×(256 ×512 × 162)≈6.7× 107次运算,仅为前者的10%。
然而Gram 矩阵相对层间互相关矩阵而言,由于不需要关注特征映射大小改变的问题,在训练过程中计算过程更加简单可理解,相比之下层间互相关矩阵的计算不仅要根据特定的两个层的选择来确定采样操作中的参数,对于不同的预训练网络而言也要重新计算,增加了额外的计算且拓展性不如Gram矩阵好。
3 实 验
3.1 实验设计
本文实验采用与Gatys 等[1]相似的模型结构,选取多个特征映射层及其组合计算Gram 矩阵和层间互相关矩阵,并对比它们在纹理合成及风格迁移中的实际效果。
实验使用python3.6 及tensorflow1.13,预训练网络使用matlab 平台在ImageNet 数据集上预训练的VGG-16 网络①MatConvNet Pretrained Models.http://www.vlfeat.org/matconvnet/pretrained/imagenet-ilsvrc-classification.,使用一块Tesla K80 GPU 加速。所有图片均缩放至256 × 256 大小,区别于Gatys等[1]的实验,我们使用Adam 优化器[17],学习率设置为10-2。在纹理合成实验中,损失函数仅使用风格损失,不加入内容损失。
3.2 实验条件
3.2.1 优化器的选择 在本文所进行的所有实验中,统一选择了Adam 优化器进行模型的训练。在Gatys等[1]最初提出的风格迁移方法中,使用了LBFGS 方法进行梯度求解。我们注意到,从Johnson等[3]开始的一系列风格迁移的研究中,使用Adam优化器已经成为了主流的方法。在大量的研究实验中,Adam 优化器证明了其在大规模参数优化当中卓越的性能[18-19],几乎所有的深度学习框架对其都有良好的支持,更方便结果的横向比对。Adam 算法的提出时间和Gatys 等[1]提出Gram 矩阵的时间相近,在当时仍未普遍使用,但现如今使用Adam 算法已经是主流的做法。为了保持实验条件的一致性,我们在复现Gatys 等[1]提出的方法时也将优化方法改为了Adam 方法,以保证结果对比的公正客观。
3.2.2 特征提取网络的选择 Gatys 等[1]的实验中选择了VGG-19[4]作为特征提取网络,这也是VGG 系列中最深且性能最强悍的网络。在本文的所有实验中,特征提取网络都选择了VGG-16 网络。这是由于在多个权威的图像分类数据集上VGG-19 相比VGG-16 在准确率上的提升都不明显,且参数量更大,占用资源更多。图像分类的准确率相当反映出模型在特征提取上的能力相当,而风格迁移中使用预训练的特征网络的核心目的就是借助其特征提取能力得到有意义的特征映射,因此选择VGG-16 与VGG-19 在结果上的区别并不明显(可以从本文的实验和Gatys 等[1]的实验结果对比看出),综合实验的计算资源限制等因素,本文使用VGG-16代替VGG-19。
近年来,一些具有革命性意义的模型改进方法使得更深更大的神经网络模型的训练成为可能,在性能上也大大超越了早期的VGG 等模型[20-21]。然而,这些方法需要的计算规模也远超早期的方法,且往往层数很大,这会给风格迁移任务带来一个问题,即如何有效地选择适合的特征映射层进行Gram 矩阵或层间互相关矩阵的计算。由于使用大部分特征映射层计算得到的Gram 矩阵共同进行风格损失的计算并不现实,而通过实验对比选择适合的特征映射层又有层数过多的问题导致实验成本较大,使用最新的高精度模型作为特征提取网络并不是一个好的选择。这也解释了大部分风格迁移方法的研究中都使用较浅的神经网络模型进行特征提取的原因。
3.3 实验结果
3.3.1 风格纹理学习实验 风格纹理学习实验使用不同的特征映射层计算层间互相关矩阵和Gram矩阵,对六幅绘画作品的风格纹理进行学习,得到输出结果(图2)。层间互相关矩阵方法全部使用平均池化对浅层特征映射做降采样处理。从输出结果可以看出,单纯使用层间互相关矩阵作为损失函数学习到的风格纹理与使用Gram 矩阵的模型得到的相似,说明单纯使用层间互相关矩阵也可以很好地完成风格迁移的目标;其次,通过对输出结果的观察我们可以看出,层间互相关矩阵方法得到的输出结果的语义等级(纹理的颗粒度、色彩深浅)大概处于其使用的两个特征映射层分别使用Gram 矩阵方法进行纹理学习得到的输出结果之间,可以看做是两者的一个加权融合。
另外,从风格纹理学习的实验中我们发现了一些值得关注的细节问。
(i)层间互相关矩阵使用的两个特征映射层越深,学到的风格图像中的语义信息越多。这也映证了越深的特征映射层会提取越多高级特征,使得输出结果带有越多风格图像中的画面轮廓。这也是层间互相关矩阵和Gram矩阵共同具有的属性,而这点也可以启发我们在风格迁移任务中根据对风格迁移程度的要求对风格损失函数的组合进行选择。
(ii)理论上风格迁移任务中对风格图像的学习并不需要对其进行缩放,因为层间互相关矩阵或者Gram 矩阵的输出大小都与原始图像输入大小无关。然而由于部分语义相关信息的带入,可能会使得风格迁移结果的纹理大小粗细在输出尺寸下显得突兀,导致风格迁移的结果不佳。因此,对于原始风格图像与风格迁移目标输出尺寸相差较大的需要进行缩放处理。
(iii)从随机得到的噪声图像开始优化图像,单纯使用风格损失很难避免局部失真的现象,即局部色块中出现明显不符合原风格图像特征的噪声点。使用更小的学习率以及更多的迭代次数只能稍微缓解该现象,使用一定的平滑技术才能较好地解决该问题,如在目标损失函数中加入总变分损失。但加入的平滑技术会在一定程度上破坏渲染出的风格纹理,引入局部的条状或块状纹理。因此,如何寻找合适的平滑技巧或其他方法使得输出结果,尤其是在高分辨率输出中避免局部失真现象仍是需要解决的问题。在第二部分的风格迁移实验中我们使用内容图像作为初始化代替了引入平滑损失的做法,并发现具有较好的效果。
(iv)实验部分展示的层间互相关矩阵方法得到的结果均采用降采样的方法。除了2.1节中提到的资源消耗原因外,在实际的实验结果中我们也发现基于上采样的层间互相关矩阵方法效果较差。最重要的原因是上采样无法类似降采样通过步长以及卷积核大小的控制进行感受野的对齐,造成了特征相关关系的紊乱;另外,降采样的过程是将特征进行组合精简,是特征的再提取过程,但上采样则试图将精简后特征还原,而这并非一个可逆的过程。
(v)风格纹理学习实验部分展示的结果均使用平均池化,我们在实验中发现使用最大池化得到的结果在纹理的细节和连贯上不如平均池化效果好,即纹理出现局部失真和断层的现象更多。在风格迁移实验部分我们展示了最大池化和平均池化的结果对比。
3.3.2 风格迁移实验
风格迁移实验对使用不同特征映射层进行计算的Gram 矩阵方法及层间互相关矩阵方法的输出结果进行对比(图3),用图2 中的三种风格对图1中中山大学怀士堂、中山大学北门牌坊两张图片进行风格迁移。从风格迁移实验的输出图像以及训练时长对比(表2)中,我们得到以下结论:

图2 纹理合成实验结果Fig.2 Texture synthesis outputs

表2 风格迁移方法结果比较Table 2 comparision of style transfer methods
(i)选取相同的特征映射层,层间互相关矩阵方法和Gram 矩阵方法会得到相似水平的输出,例如图3第3行中,使用relu1_1,relu2_1,relu3_1三个特征映射层的Gram 矩阵方法和层间互相关矩阵方法都较好地保留了礼堂整体轮廓形状,而加入了特征映射层relu4_1 后的三个输出结果,整体轮廓都在一定程度上被破坏;第5行中,后三组实验的天空部分有明显的黄色块状纹理,而前三组则没有。
(ii)无论是Gram 矩阵方法还是层间互相关矩阵方法,都存在一定的局部失真。在风格迁移的实际实验过程中,我们首先尝试了内容损失、风格损失和总变分损失三部分进行加权组合的损失函数,但发现尽管总变分项的加入使得最终的输出结果更平滑,但会带来与艺术风格不匹配的局部纹理。另外,总变分损失的加入使得训练过程中内容损失和风格损失的下降变得困难,难以达到令人满意的输出结果,且对于不同的风格和内容,总变分损失部分的损失似乎都需要特殊的调参,否则结果差异较大。基于此事实,以及本文比较不同风格损失函数的核心,最终在实验中我们舍弃了总变分损失的部分,虽然导致风格迁移结果局部失真,但在实际实验中使用内容图像进行初始化的方式很大程度地缓解了问题。

图3 风格迁移实验结果Fig.3 style transfer outputs
(iii)尽管在使用的特征映射层相同的条件下,使用Gram 矩阵和层间互相关矩阵方法得到的风格迁移输出结果类似,从个别例子中仍能看出使用最大池化的方法不如使用平均池化方法得到的图像效果稳定,相比之下其差异会更大。如图3 第6行的后三组实验中,使用最大池化得到的结果和使用Gram 矩阵或平均池化的层间互相关矩阵方法得到的结果差异较大。
(iv)在得到相似输出水平的情况下,使用层间互相关矩阵方法比使用Gram 矩阵的方法在速度上有着显著优势。在风格迁移的所有实验中我们对输入图像的优化迭代次数都是20 000 次,这也是前期实验对比得出的经验值。我们发现无论是Gram 矩阵方法还是层间互相关矩阵方法,得到效果良好的输出图像所需要的迭代次数是相当的,这可能是因为相似的损失函数构成和相同的学习率使得每次反向传播过程中给出的梯度值都在基本相同的量级。因此在表2的运行时间对比中我们给出了单次迭代耗时,实际上也是总耗时与迭代次数的比值。在前三组实验中,使用平均池化、最大池化方法的单次迭代耗时约为Gram 矩阵方法的74.54%及71.6%;后三组实验中,使用平均池化、最大池化方法的单次迭代耗时约为Gram 矩阵方法的75.54%及69.93%,提速均在20%以上,使用最大池化的层间互相关矩阵方法速度最快。
(v)我们在第2 节中提到,理论上层间互相关矩阵刻画的是不同等级语义特征之间的相关性。然而,在实际实验结果中我们发现,艺术风格纹理的差异主要是使用了不同的特征映射层造成的,与使用层间互相关矩阵还是Gram 矩阵的关系并不显著。这是由于这种理论上的语义等级差异并不完全和实际情况相符。实际上,卷积神经网络的中间隐藏层所提取的很多特征从人的角度是难以理解的,其对语义特征等级的区分也和人的理解有差异。另外,卷积神经网络也难以确保在训练中将同等级的特征提取放在同一层中进行,光依靠卷积层和池化层的结构是无法保证这种限制的。因此,同一层的卷积核提取的特征之间也可能存在等级差异,很多情况下,只要选取的特征映射一致,Gram 矩阵方法和层间互相关矩阵方法得到的风格迁移输出结果整体不会有很大差异。但这并不妨碍在细节处层间互相关矩阵带来的纹理多样性。
(vi)本文实验中对比了Gram 矩阵和层间互相关矩阵在Gatys 等[1]提出的算法中表现的差异,若在基于前馈网络的快速风格迁移系列方法 中 将Gram 矩阵替换为层间互相关矩阵,则无法提升模型使用时的效率,而是提升了模型训练时的效率。
4 结 论
本文提出使用层间互相关矩阵作为Gram 矩阵的代替或补充,用于风格迁移任务中风格损失的计算。实验表明,在获得与基于Gram 矩阵的神经风格迁移方法相似水平的输出结果的情况下,使用层间互相关矩阵的方法可以在一定程度上提高模型的训练效率。
除了风格迁移任务本身外,层间互相关矩阵和Gram 矩阵的有效性也表明深度学习方法在艺术风格的表示、分类、聚类等问题上有着很大的潜力。另外,由于风格迁移任务的特殊性,我们可能需要更多艺术专业领域的专家知识的指导,作为先验知识,这可能为未来风格迁移的效果带来一定的提升。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
山东交通科技(2020年1期)2020-07-24
电子制作(2019年13期)2020-01-14
学生导报·东方少年(2019年20期)2019-11-27
电子制作(2019年11期)2019-07-04
振动工程学报(2019年2期)2019-05-13
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
智能制造(2016年11期)2017-01-03
