
2型糖尿病风险预测模型的比较
2020-12-14 04:37毕迎春王培培潘媛媛甘良进叶明全
电脑知识与技术 2020年28期
毕迎春 王培培 潘媛媛 甘良进 叶明全
摘要:目的:探讨分类算法在2型糖尿病风险预测中的应用价值。方法:针对Pima Indians Diabetes数据集,经过2种情况的数据预处理,选择逻辑回归、支持向量机、多层感知机、随机森林等4种分类算法分别构建2型糖尿病风险预测模型,分析对比准确率和F值等评价指标,以验证其对具有空值数据集的应用性能。结果:经过比较,对原始数据进行分类预测时,多层感知机的值最高,随机森林的值最低,4种分类算法对删除属性后的数据集也取得了较好的预测效果。结论:分类算法可以有效预测2型糖尿病,并对具有一定缺失值的数据集具有良好的实用价值。
关键词:糖尿病预测;数据预处理;逻辑回归;支持向量机;多层感知机;随机森林
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2020)28-0008-03
Abstract: Objective:To explore the application value of classification algorithm in the risk prediction of type 2 diabetes mellitus(T2DM). Methods:According to the data set of Pima India diabetes, after two kinds of data preprocessing, four kinds of classification algorithms such as logistic regression, support vector machine, multi-layer perceptron and random forest are selected to construct the risk prediction model of type 2 diabetes respectively, and the evaluation indexes such as accuracy and F-Measure are analyzed and compared to verify its application performance to the data set with null value.Results:After comparison, when the original data is classified and predicted, the value of multi-layer perceptron is highest, and the value of random forest is lowest. Four classification algorithms have also achieved better prediction results for the data set after attribute deletion.Conclusion:The classification algorithm can effectively predict T2DM and has a good practical value for data set with certain missing values.
Key words: diabetes prediction; data preprocessing; logistic regression; support vector machine; multi-layer perceptron; random forest
糖尿病是世界上最致命的慢性病之一,預计到2045年,全球将有近7亿人患糖尿病[1]。我国糖尿病以2型糖尿病为主,2013年全国调查中2型糖尿病患病率为10.4%,未诊断糖尿病比例高达63%[2]。2型糖尿病的早期症状轻微,甚至无任何症状,很难及早干预,当出现临床症状再去就诊时,由于拖延了病程,很多患者已经病情较重,甚至开始伴随多种并发症,由于无法根治,糖尿病患者将承受巨大的疾病痛苦和沉重的经济负担,2型糖尿病的早期预测显得尤为重要。分类算法已经广泛应用于医学领域,应用分类算法构建2型糖尿病风险预测模型,辅助临床决策,早发现,早诊断,提升患者的防治意识,提高2型糖尿病的防治水平。
研究表明决策树、支持向量机、贝叶斯、随机森林、深度学习等方法在糖尿病风险预测中都获得了较好的预测结果[3-5],但不同的实验环境、不同的数据集、不同的数据预处理,很难将各种算法进行有效对比,本文在以Python3为核心程序的Anaconda3平台上,选用UCI上的Pima Indians Diabetes数据集(简称PIDD),在不同的数据预处理情况下,分别应用逻辑回归(简称LR)、支持向量机(简称SVM)、多层感知机(简称MLP)和随机森林(简称RF)等4种分类算法,构建2型糖尿病预测模型,进行实验对比,为2型糖尿病早期预测提供科学依据。
1 数据与方法
1.1 数据来源
本文选用的糖尿病数据集为UCI上的PIDD经典数据集,该数据集包含了768例21岁以上女性患者的医疗信息,共8个与糖尿病相关的数值型特征属性和1个标签,其中268例为糖尿病患者,标签值为1,500例为非糖尿病患者,标签值为0,具体见表1。
1.2 研究方法
1.2.1 数据预处理
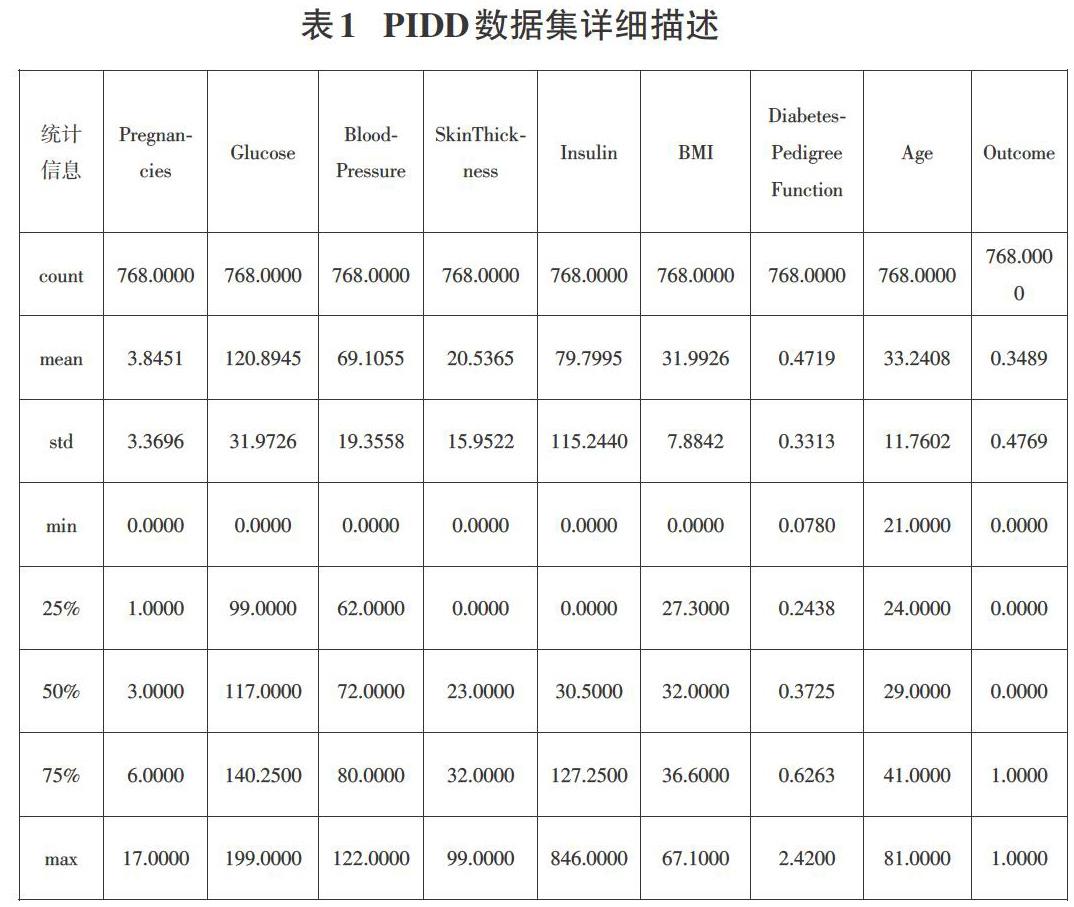
用空值替换PIDD数据集中各属性的0值,得到数据缺失值情况,如图1所示,共5个属性有缺失值,其中Glucose和BMI属性缺失值较少,分别缺失5个和11个,BloodPressure属性缺失35个,SkinThickness属性缺失227个,Insulin属性缺失374个。在数据预处理时均未做插值处理,因为通过实验证实,用均值等插值方法处理空数据后,得到的实验结果并未得到明显改进,所以为保持原始数据的完整性和验证各分类算法对数据集的处理能力,不做插值处理。
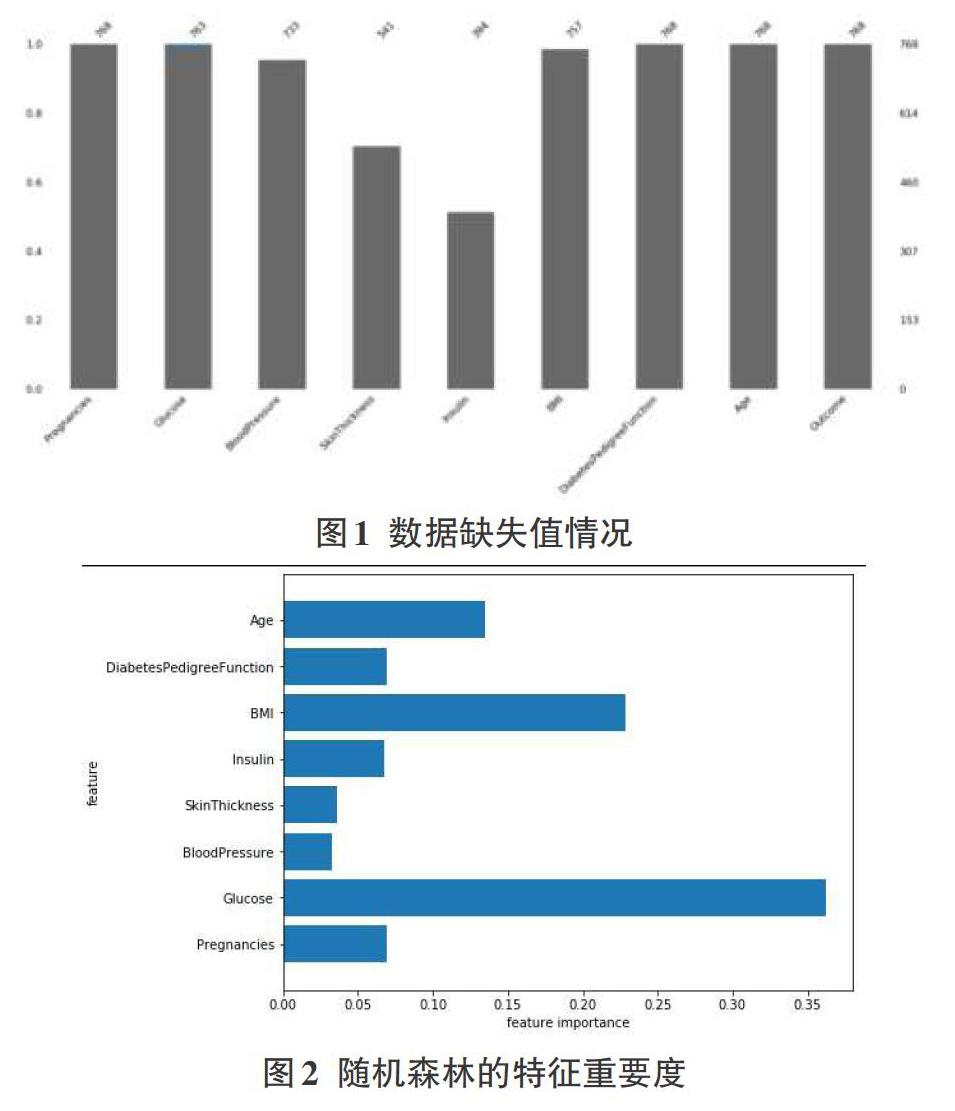
本文将数据预处理分为两种情况:1)去掉缺失值最多的SkinThickness和Insulin2个属性;2)图2为PIDD数据集中随机森林的特征重要度,去掉重要度中最低的3个属性,分别为SkinThickness、Insulin和BloodPressure属性。
1.2.2 总体思路
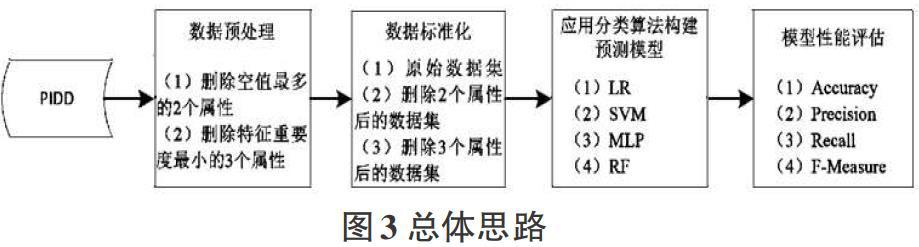
实验环境选择以Python3为核心程序的Anaconda3(64-bit)平台,针对PIDD数据集,首先进行数据预处理,实验中分3种情况下的数据集进行实验对比,分别为1)原始数据集;2)根据数据预处理中第一种情况,去掉2个缺失值最多的属性后得到的数据集;3)根据数据预处理中第二种情况,去掉3个特征重要度最小的属性后得到的数据集。随后将这3种数据集分别按照8:2比例划分为测试集和验证集,其中训练集中标签为1和0的数量分别为214和400,测试集中标签为1和0的数量分别为54和100。为保证数据特征在同一尺度范围内变化,分别对训练集和测试集数据进行标准化处理,选用StandardScaler类的fit_transform方法,把数据转换成标准正态分布,数据度量标准化后,分别应用LR、SVM、MLP和RF共4种分类算法进行模型训练,调整模型参数,构建2型糖尿病预测模型,最后利用测试集进行模型性能评估,具体如图3。
1.2.3 参数设置
在8:2的数据集比例下,应用sklearn中的train_test_split函数,将PIDD数据集随机划分为训练集和测试集,为了在拟合过程中获得一个确定的行为,保证重复实验时能够在同样的训练集和测试集下计算得到相同的实验结果,便于数据分析,设置固定的random_state参数值,其中train_test_split函数中的random_state参数设置为66,各算法中random_state参数均设置为1。
LR算法中将solver设置为'liblinear',即选择Liblinear优化算法,应用坐标轴下降法来迭代优化损失函数,penalty设置为'l2',使用L2正则化;SVM算法中kernel设置为'rbf',即选择径向基(RBF)内核训练SVM,惩罚系数C设置为1;MLP算法中设置solver设置为'adam','adam'参数为应用基于随机梯度的优化器[6], hidden_layer_sizes设置为[120,],表示只有一层隐藏层,该隐藏层包含120个神经元,隐藏层的激活函数activation设置为线性整流函数'relu',即f(x) = max(0, x)[7]。RF算法中n_estimators设置为100,利用该参数限定森林里树的数目,criterion设置为'gini',即基尼不纯度(Gini impurity),树的最大深度max_depth根据实验验证,在无删除属性时设置为3,有删除属性时设置为4。其余各算法的参数均选用系统默认值。
2 结果
2.1 模型评价标准
选择准确率(Accuracy)、查准率(Precision)、召回率(Recall)和F值(F-Measure)作为评价标准,其中TP(True Positive)、TN(False Negative)、FP(False Positive)和FN(False Negative)的总和为测试样本总数,F值为查准率和召回率的调和平均值[8]。公式如下:
Accuracy=(TP+TN)/(TP+FP+TN+FN) (1)
Precision=TP/(TP+FP) (2)
Recall=TP/(TP+FN) (3)
F-Measure=2*(Precision*Recall)/(Precision+Recall) (4)
2.2 模型比較
为能够同时观察各分类算法预测糖尿病和非糖尿病的能力,表2~表4分别为各分类算法在原始数据集和经过2种数据预处理后得到的数据集下的准确率、精确率、召回率和F值,其中0-Precision,0-Recall,0-F-Measure,1-Precision,1-Recall,1-F-Measure分别为预测标签0和1所对应的Precision、Recall和F-Measure值。因标签为1的样本数量少,所以大部分情况下,预测标签0的查准率和召回率均高于预测标签1的值。由于F-Measure均衡了Precision和Recall,所以主要观察Accuracy和F-Measure的值,值越高预测效果越好。
表2~表4中,算法之间进行对比分析,MLP算法的Accuracy、0-F-Measure和1-F-Measure均比其他三个分类算法高,RF算法对应的值均最低;表2中无删除属性时MLP算法的效果最好。同一算法在不同情况下比较时,LR算法在无删除属性时计算得到的值最高,而删除2个属性和删除3个属性时,取得了相同的结果;SVM算法在三种情况下均得到了相同的Accuracy,但0-F-Measure和1-F-Measure均不同,在删除2个属性时SVM算法预测后得到的1-F-Measure高于其他两种情况下获得的值;MLP算法在无删除属性时值最高,在删除3个属性时值最低;RF算法在删除3个属性时Accuracy最低,其他两种情况下取得了相同的值,无删除属性时0-F-Measure最高,删除2个属性时1-F-Measure最高。
3 讨论
在对比评价标准的同时,图4画出三种情况下各分类算法的ROC(Receiver Operating Curve)曲线,并计算出ROC曲线下面积AUC(Area Under Curve),对比AUC的值,a表中SVM最高,b表中MLP最高,c表中SVM最高,三个表中LR的AUC值均是最低的,其中最高的是c表中的SVM,最低的是c表中的LR。
表3、表4與表2相比算法结果均有所下降,但下降幅度较小,删除2个或3个属性,既节省了空间复杂度也提高了运算时间,可见这四种分类算法对于有空值的数据集处理能力均较强,尤其是SVM和MLP算法,对预测5年内是否患有糖尿病均能起到很好的效果,建议同时应用两个以上算法进行预测,以期得到更准确的结果。PIDD数据集数据量不大,应用分类算法可直接作用在原始数据上,当遇到大样本数据时,根据空值情况,或根据特征重要度有效去除部分属性,减少特征数量,能够有效提高计算速度,节约计算成本和时间,今后会从医院体检信息中整理更多实际数据,验证这些分类算法的特性,为能够更精准的糖尿病预测,探讨更多分类方法。
本文应用四个经典的分类算法,对有缺失值的PIDD数据集,在经过删除缺失值最多的2个属性和基于随机森林特征重要度删除特征重要度最小的3个属性后,分别构建风险预测模型,均得到了75%以上的准确率,其中MLP的预测效果最好,实验证明分类算法能够对有缺失值的数据集进行有效的预测2型糖尿病。根据体检信息对预测未来5年内会患有2型糖尿病的高风险人群,进一步临床诊断,提早预防,及时干预,加强防范意识,能够有效降低或减缓2型糖尿病的发生风险,减轻个人的疾病损伤和经济负担,节约国家的医疗资源和经济开支。
参考文献:
[1] Cho, N. H., Shaw, J. E., Karuranga, S., et al. IDF Diabetes Atlas: Global estimates of diabetes prevalence for 2017 and projections for 2045[J]. Diabetes Research and Clinical Practice, 2018,138, 271–281.
[2] 中华医学会糖尿病学分会.中国2型糖尿病防治指南(2017年版)[J].中国实用内科杂志, 2018,38(4):292-344.
[3] Sisodia,D.,Sisodia,D.S.. Prediction of Diabetes using Classification Algorithms[J]. Procedia Computer Science, 2018, 132, 1578–1585.
[4] 白江梁, 张超彦, 李伟, 等. 某医院体检人群糖尿病预测模型研究[J].实用预防医学, 2018, 25(1):116-119.
[5] 贺其, 赵岗, 菊云霞,等. 机器学习算法在糖尿病预测中的应用[J]. 贵州大学学报:自然科学版, 2019, 36(2):65-68.
[6] Kingma, Diederik, and Jimmy Ba.Adam: A Method for Stochastic Optimization[J].Computer Science, 2014.
[7] Hahnloser R H R , Sarpeshkar R , Mahowald M A , et al. Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit[J]. Nature, 2000, 405(6789):947-951.
[8]林鑫, 李晋, 刘蕾, 等. 二型糖尿病肾病风险预测模型的比较[J]. 中华医学图书情报杂志, 2019(4):44-48.
【通联编辑:王力】
猜你喜欢
南水北调与水利科技(2016年6期)2017-01-06
中国水运(2016年11期)2017-01-04
科学与财富(2016年28期)2016-10-14
现代电子技术(2015年15期)2015-08-14
现代电子技术(2015年8期)2015-07-09
