
基于Python的招聘信息爬虫系统设计
2020-12-23 05:47孙亚红
软件 2020年10期

摘 要: 本文詳细阐述了运用Python爬取51job上相关招聘信息的过程,并对所抓取的信息进行处理和分析,按照不同地区,不同薪资把招聘信息以图表的形式进行展示,以期帮助高校毕业生在择业时能够快速获取特定的需求信息,并通过快速数据分析得到自身择业的准确定位,从而做出更好的选择。
关键词: 爬虫;Python;招聘
中图分类号: TP3 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.10.055
本文著录格式:孙亚红. 基于Python的招聘信息爬虫系统设计[J]. 软件,2020,41(10):213214+235
【Abstract】: This paper describes the process of using Python to crawl the relevant recruitment information on 51job, and processes and analyzes the captured information. According to different regions and different education requirements, the recruitment information is displayed in the form of chart, in order to help college graduates quickly obtain specific demand information when choosing a job, and obtain the accuracy of their own employment through rapid data analysis.
【Key words】: Crawler; Python; Recruitment information
0 引言
伴随着网络信息的爆炸式增长,大数据时代悄然而至。如何在海量的数据当中获取可以有效利用的关键数据信息,成为各界研究的热点[1-5]。网络爬虫是一种按照设计者所设定的规则,模拟成为浏览器,自动驱动抓取网页信息的程序或脚本[6]。利用网络爬虫,设计者可结合自己的目标需求从海量的互联网信息中抓取目标信息数据并存储,为进一步的数据分析,用户画像做好准备。
1 系统设计流程
设计招聘信息爬虫系统的流程如下。
步骤1:分析URL。
步骤2:访问待抓取页面。该模块访问被抓取页面的相关职位信息,利用Requests库下载待抓取页面的html代码。
步骤3:下载,解析,抽取信息。在该模块,使用lxml等Python库解析页面,并根据预先制定的规则,抽取信息。
步骤4:存储。在该模块中,针对不同类型的数据创建mysql表格,把爬取的数据存储在mysql数据库的表格中。
步骤5:分析数据并可视化。
2 系统实现各关键技术
2.1 抓取模块
打开51job,在职位搜索栏中输入“数据分析师”,页面上显示所有关于“大数据分析师”的岗位信息共169页,多翻几页,分析出该类页面的地址规律,发现不同的页面其URL基本上都为“https://search.51job. com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588,2, *.html”,只有“*”处的数字发生了变化。因此,编写网页获取代码如下:
def Get_html(data,i):
Url="https://search.51job.com/list/000000,000000, 0000,00,9,99,"+data+",2,%s.html"%i
header = {'User-Agent':'Mozilla/5.0'} #头部信息
r=requests.get(Url,headers=header)
r.encoding=r.apparent_encoding
return(r.text) #函数返回html页面的内容
2.2 定义Xpath表达式,获取目标数据
Xpath将XML文档看成一个节点树模型,它能够通过一个通用的句法和语义对XML文档中的节点进行检索和定位,是在XML文档中进行寻址的表达式语言。本论文中针对下载的网页文档,通过编写相应的Xpath表达式进行目标数据的抽取。核心的代码如下:
def Get_data(html,name):
html=etree.HTML(html)
divs=html.xpath("//div[@id='resultList']/div [@class='el']")
print(divs)
for div in divs:
job1=div.xpath("./p/span/a/@title")
print(job1[0])
job_url1=div.xpath("./p/span/a/@href")
print(job_url1)
job_company1=div.xpath("./span[@class= 't2']/a/@title")
print(job_company1)
job_area1=div.xpath("./span[@class='t3']/ text()")
print(job_area1)
job_salary1=div.xpath("./span[@class='t4']/ text()")
print(job_salary1)
try:
job_salary.append(job_salary1[0])
job_area.append(job_area1[0])
shuju.append((job1[0],job_url1[0], job_company1[0],job_area1[0],job_salary1[0]))
except:
print("異常")
2.3 存储设计
针对不同的工作岗位,获得大量的招聘数据,因此,需要将数据进行存储。Python中,常用数据存储方式有两种,一种是数据库,可以是MySql数据库,Redis数据库;另外一种是文件存储,如CSV文件, Excel文档等。本文中采用MySql数据库进行数据存储。核心代码如下:
def mysql_data(name,shuju):
client=pymysql.connect(user="root",host="loca lhost",passwd="123456",db="datashiyan" charset=”utf8”)
cursor=client.cursor()
sql="insert into table_%s"%name+"values(%s, %s,%s,%s,%s)"
cursor.execute(sql,shuju)
client.commit()
cursor.close()
client.close()
利用Mysql的可视化工具Navicat对爬取的部分数据进行显示如图1所示。
2.4 数据预处理
通过Xpath表达式从网页中获取的数据均为文本数据,不适合直接进行数据分析,因此,在数据分析之前,先要对数据进行预处理。如工资数据的数字化处理,城市数据的分割等。
3 数据分析与可视化处理
3.1 岗位细化
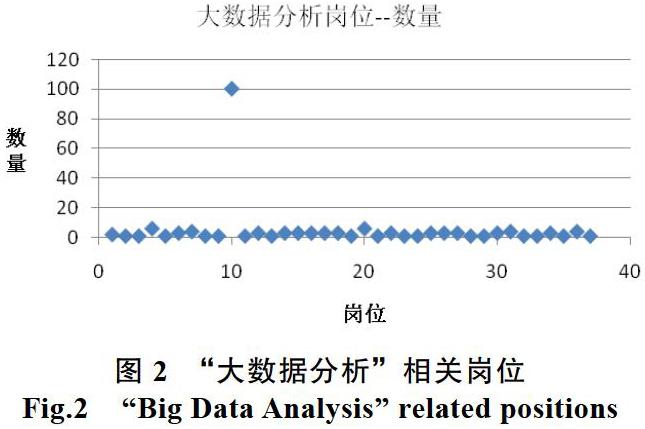
“大数据分析师”在不同的行业中又细化出若干工作岗位,如电商大数据分析师,房地产大数据分析师,交通大数据分析师等。相关的岗位需求人数统计图如图2所示。
从图中可以看出,与“大数据分析”相关的岗位主要是“大数据分析师”,需求数量达到100多,其他的相关岗位则较少,数量均在20人以下。
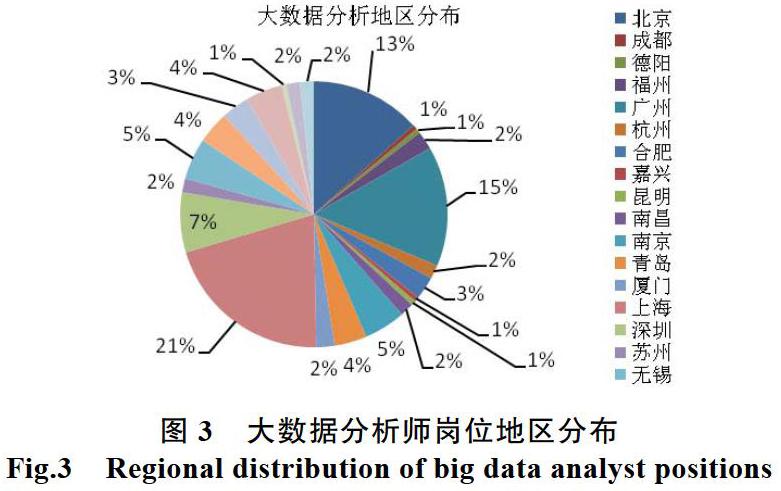
3.2 地区分布
地区是人们选择工作时要考虑的重要因素。从图3可以看出北京,广州,上海的大数据分析师需求量达到49%,几乎占到总需求人数的一半。
3.3 薪资分布
薪资是人们在找工作时的又一个重要因素。从图4中可以看出,武汉大数据分析师以年薪25.54万位居榜首,接下来是北京23.29万,杭州22.5万。
4 结束语
本文基于Python实现了51job上相关职位的爬虫编写。文中共提取有效信息35540,通过爬虫程序, 可以方便的获取目标数据。通过去重,规范化等数据处理后,以可视化图表形式直观的对不同地区的薪资,岗位进行展示,为求职者在找工作的过程中提供了便利。
参考文献
[1]侯美静, 崔艳鹏, 胡建伟. 基于爬虫的智能爬行算法研究. 计算机应用与软件, 2018, 35(11): 215-219.
[2]郑冬冬, 赵鹏鹏, 崔志明. Deep Web爬虫研究与设计. 清华大学学报(自然科学版), 2005, 45(S1): 1896-1902.
[3]周中华, 张惠然, 谢江. 基于Python的新浪微博数据爬虫. 计算机应用, 2014, 34(1): 3131-3134.
[4]杜兰, 刘智, 陈琳琳. 基于Python的文献检索系统设计与实现. 软件, 2020, 41(1): 55-59.
[5]李鹏飞, 吴为民, 周孝林, 等. 基于“用户画像”挖掘的图书推荐APP设计[J]. 软件, 2018, 39(5): 35-37.
[6]罗咪. 基于Python的新浪微博用户数据获取技术. 电子世界: 138-139.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
经营者(2016年19期)2016-12-23
中国经贸(2016年20期)2016-12-20
