
基于改进的卷积神经网络的虾苗自动计数研究
2020-12-24 13:39范松伟林翔瑜
渔业现代化 2020年6期
范松伟,林翔瑜,周 平
(1 浙江理工大学信息学院,浙江 杭州 310018;2 杭州万深检测科技有限公司,浙江 杭州 310018)
2018年中国淡水养殖产值5 884.27亿元,水产苗种产值644.62亿元,其中对虾养殖产量2 681 265 t,比2017年增长513 670 t,且仍处在上升阶段[1]。生产实践中,虾苗的放养和销售等环节至今仍用质量法、杯量法等人工方式计数,容易记错、数错等致使计数不准确且费时费力[2-3]。因此,如何高效准确计数虾苗有着迫切的用户需求。
国内首次采用光电计数法实现自动虾苗计数,对虾苗自动计数速度最高达30万尾/h,计数误差±2%,但因计数稳定性欠佳,至今未被养殖户采纳[4]。张康德[5]用方盆和框格方法取样计数,取2格虾苗平均后乘以总方格数计算虾苗总量,取样复杂不适用大量虾苗;薛志宁等[6]建立虾苗尾数与质量的回归关系计数日本对虾,因虾苗大小与体重生长关系随品种不同存在差异而未普及;刘世晶等[7]通过改进主成分分析(PCA)算法的自动识别运动虾苗,提取图像中不同运动状态的虾苗,识别正确率达98%,但其识别精度和稳定性易受虾苗粘连和光照影响。季玉瑶等[8]提出了一种对数商连通域标记面积估算虾苗,过程烦琐且计数准确率不高。姜松等[9]发明了一种虾苗计数装置以及计数方法,可降低劳动强度,但智能化程度不高。张建强等[10]发明了一种对虾苗种计数装置,不会影响出苗时苗种存活率,计数成本低,但计数误差受计数速度影响大。
近年来,深度学习在目标识别计数方面表现优秀,能够自动提取图像特征并给出计数结果,操作简单,应用广泛。为解决虾苗因个体小、易粘连和聚集打堆等产生的计数难题,提出了一种利用卷积神经网络模型实现对虾苗的自动计数方法。
1 材料与方法
1.1 材料
1.1.1 数据来源
虾体透明且长度不一,为排除光照等外在影响,于同时间段统一使用500万像素彩色相机在均匀背光源下实拍长度约为6~15 mm虾苗图像共1 438张,包含有3种不同聚集密度分布,各图中的虾苗约129~3 000尾不等,平均每张图片上虾苗约有1 163尾,按照文献[11]设置,将其分成训练集和测试集,分别占据数据集的4/5和1/5,并对数据集采用五重交叉验证。
1.1.2 样本集制作
随机抽取部分原始样本集进行平移、镜像[12]、旋转[13]及亮度调节等方式增强数据,用以增加样本的数据量,同时防止出现过拟合现象[14],并提高模型的泛化能力和鲁棒性。在深度学习中,训练样本的质量直接影响模型性能,有效的标注方式至关重要,样本标记的基本事实计数(Ground Truth)不准确将导致损失函数的计算错误[15]。尤其虾苗打堆的情况下,采用滑动窗口法提取候选区域真正包含目标很少,在检测过程中速度很慢且网络在后续处理中采用NMS[16]会把重叠度较高的矩形框丢弃,导致出现较多的漏标记,故未用Labelimg工具提取图像目标的感兴趣区域(ROI)[17]。选用对样本图中每个虾苗用一个像素做点标记,仅用归一化为一个总和的二维高斯核来模糊每个点标记以生成基本事实,确定二维空间位置信息和个数[18-19]。试验统一采用在虾头中心进行标注,共标记虾苗样本总数68 932尾,图1为其中部分样本标记前后拍摄图。

图1 虾苗标记图像示例
1.2 方法
1.2.1 VGGNet基础网络
VGGNet由输入层、卷积层、池化层、全连接层、softmax输出层构成[20],其中有13个卷积层与3个全连接层和5个池化,采用卷积+卷积(+卷积)+池化的结构(图2)。

图2 VGGNet网络结构
VGGNet的结构简单,但所包含的权重数目却很大,达到了139 357 544个参数,具有很高的拟合能力。网络组成分量介绍如下:
1)输入层是实拍的虾苗样本图。
2)卷积层的卷积操作用于提取输入图像的不同特征,有4个超参数指定,分别是滤波器的数量、滤波器的大小、步长和零值填充的数量,共同决定卷积层的输出大小。
3)池化层用于减少网络参数降低计算量,同时控制过拟合。其运算一般有平均池化(mean-pooling)和最大池化(max-pooling)。平均池化,即对邻域内特征点只求平均;最大池化,即对邻域内特征点取最大。池化操作没有参数进行训练,但可以通过池化来减小计算的复杂度。池化层选用统一步长2的2×2 最大池化,使得高和宽是前一层的一半。
4)全连接层用于连接所有的特征,并在最后一层用Dropout方法[21]减少过拟合,将输出值传给分类器。
1.2.2 对基础网络的改进
VGG16起初主要用作图像分类,在处理计数问题需要对网络改进使其效果更佳。当图片中目标密度过大时,计算量会激增,为了减少浮点运算的数量,提高模型的计算效率,对此,参考人群计数相关网络结构作出如图3所示的改进。
首先,相机拍摄角度会影响虾苗的失真程度,因此,为了输入图像大小可以任意,用卷积层代替全连接层使其更好将网络学习的特征图映射到密度图。其次,多次池化操作会导致空间位置特征丢失,因此将第4个最大池化层的步幅设置为1、第5个池化层换成一个1×1的卷积核处理输出特征图,这样处理后最终的特征图大小由输入图像尺寸的 1/32变为1/8,并使用膨胀卷积处理第4个最大池层中步幅的移除引起的感受不匹配。最后在整个网络中,在每个卷积层后面添加线性整流函数(Rectified Linear Unit,ReLU)作为激活函数[22]。

图3 改进的网络结构
1.2.3 网络结构优化
训练阶段用平方损失函数衡量预测模型的估计密度图与真实密度图之间的差距。该平方损失函数如式(1):
(1)
式中:N为训练图片样本数;Xi为第i张样本图;F(Xi;Θ)为估计密度图;Fi为第i张图片的真实密度图;Θ为待优化的网络参数;L(Θ)为真实密度图和估计密度图之间的损失值。
1.2.4 密度图的制作
用回归分布密度图的方法估计图中虾苗数量。训练样本图输入到网络学习前,根据数据集中每个虾苗训练样本的像素点生成虾苗的真实密度图。
虾苗图中坐标为(xi,yi) 虾苗标记点,可表示为δ(x-xi,y-yi),假设某图中有M个虾苗标记点,则可表示为式(2):
(2)
将式(2)与一个高斯滤波器Gσ做卷积可将标注过的图像转成连续的密度图,如式(3)所示:
(3)
式中:M为图像中虾苗总数;δ(x-xi,y-yi)为delta函数;F(x,y)为真实密度图在坐标点(x,y)的值;Gσ为高斯滤波器。
2 结果
2.1 试验平台
为保证严谨性,所有试验均在相同试验平台和数据集上进行。硬件环境:处理器Intel Corei 7,GPU是NVDIA GTX1080;软件环境:Python 3.6,CUDN 9.0,cuDNN 7.0,Tensorflow-GPU 1.6,操作系统为CentOS 7;各目标的训练和测试算法均以TensorFlow深度学习框架[23]为基础,与上下文感知网络(CAN)[24]、多列卷积神经网络(MSNN)[25]、拥挤场景识别网络(CSRNet)[26]网络模型作对比。
2.2 实现细节
采用L2正则化避免过度拟合,预先训练的模型初始化部分参数,自适应学习率优化算法Adam更新网络参数,网络参数用方差为0.1的高斯函数做初始化。训练阶段的网络初始学习率设置为0.000 01,动量设为0.9,选取5、10、20、25个像素步幅来扫描图像,用训练图像经过反复迭代数万次训练后,将测试样本送入模型检测评估,并将获得的密度子图合并作为估计密度图。
2.3 试验结果
2.3.1 误差结果
根据相关文献[27],采用平均绝对误差(XMAE)、均方根误差(XRMSE)、精确度(XAcc)评估虾苗计数效果。XMAE用于量化预测准确性,XRMSE用于评估训练性能。XMAE值和XRMSE值越低,且XAcc值越高,则计数性能越好。计算公式如下:
(4)
(5)
(6)

随机抽取40张验证集样本图进行交叉验证,其虾苗最少284尾,最多1 543尾,平均每个图像804尾,试验结果误差波动见图4所示,每张图中的计数平均误差在7尾左右,最大误差为47尾,XMAE为12.70,故在可接受范围内。
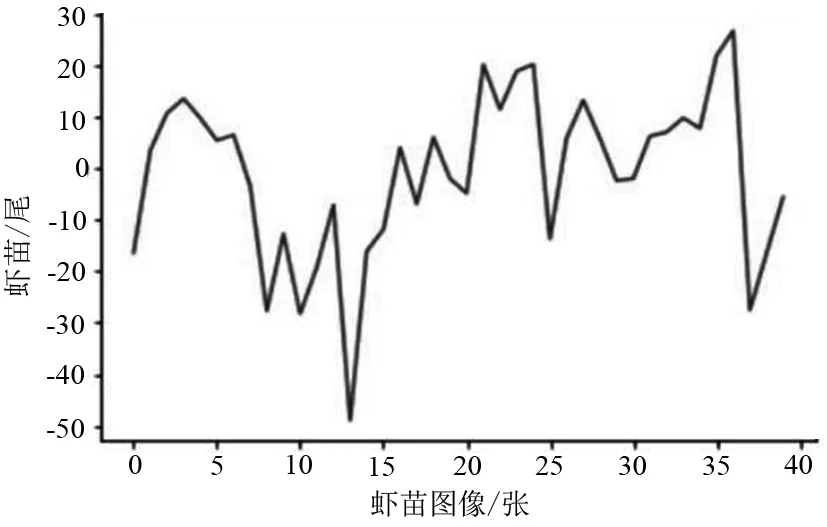
图4 用XMAE评估虾苗计数精度
每张样本图中的网络获得的估计数量和基准的基本事实计数的对比散点图见图5,其XAcc值为97.59%,从散点图的对比中可以看出两者之间的波动稳定,故较好解决了虾苗个体小、有重叠、较透明的计数难点。

图5 40张虾苗图像真实值与估计值的对比
2.3.2 计数的可视化验证
为了更好地解释本研究模型,图6对部分虾苗计数实例可视化,列举了3张虾苗的原图(第1行)、真实密度图(第2行)和估计密度图(第3行)。对应图的下方是真实和估计的虾苗数量。

图6 估计密度图与真实密度图对比
从图6中可以看出,两者相似度很高,说明算法输出密度图的质量极佳,因而取得优秀的计数效果。估计数量和基准的基本事实计数的总和呈小数,是因标记点靠近图边缘时,其高斯概率部分处于图像外所致。图6b数据显示真实值与估计值之间误差相对大些,这是因虾苗过分聚集重叠所致,故虾苗聚集情况需要有个限度,不能过度遮挡。
2.4 与相关算法的比较
图7显示了数据集中每个图像在3种情况下计数结果,包括改进网络获得的预测数量,基本网络获得的预测数量以及基准的基本事实计数。在多数情况下,改进网络预测的数量比实际数量更接近真实数量。但是在极少数情况下,改进网络不如基本网络准确。例如,对于基本事实计数512,改进网络的预测计数为525,XMAE为13,而来自基础网络的预测计数为520,XMAE只有8。即便如此,改进网络在预测高密度虾苗数量方面的准确性图像仍超过90%的基础网络。
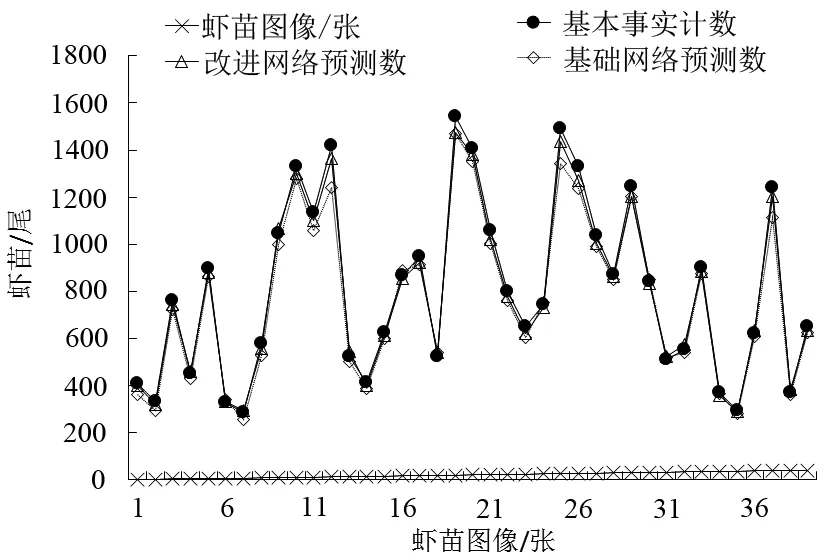
图7 改善网络前后的计数比较
将本文方法与MCNN、CSRnet、CAN等优秀网络进行比较,表1用XMAE和XRMSE以及XAcc等量化试验。可以看出,本文网络模型的准确率为97.59%,XMAE为12.70,XRMSE为14.21,XMAE较MCNN、CSRnet、CAN分别降低了7.6、4.8、3.2,获得了较好的计数水平。
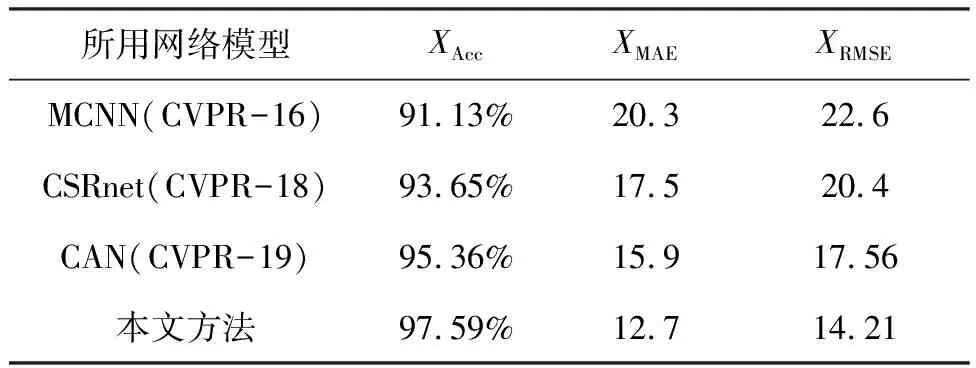
表1 本文方法与其他网络模型的比较
2.5 虾苗计数原型机研发
图8是与万深检测科技合作研发的虾苗计数仪原型机,灯箱为白色内壁,内壁上方布置了一圈24 W的白光LED灯带,以产生漫反射无影照明效果,避免了光直射底面的虾苗水盘而形成投照光斑,影响虾苗自动识别,对被计数虾苗重新做了充分的标记学习并形成虾苗识别计数文件,以在手机App上使用。用捞网每次捞取3 000尾以内的虾苗放在盛有150 mL清水的白扁盘内,晃一下后放入拍摄视野,点按灯箱顶部的手机软件来控制连拍5张虾苗图,自动按图片清晰度评价算出最清晰3张图的虾苗数,自动平均后显示出计数结果量,整个操作过程在20 s内完成。进一步验证试验发现:虾苗计数精度跟标记学习量呈正相关,与虾苗聚集密度呈负相关。故每次计数需控制虾苗总量在100~3 000尾,以不使虾苗过分密集堆叠。
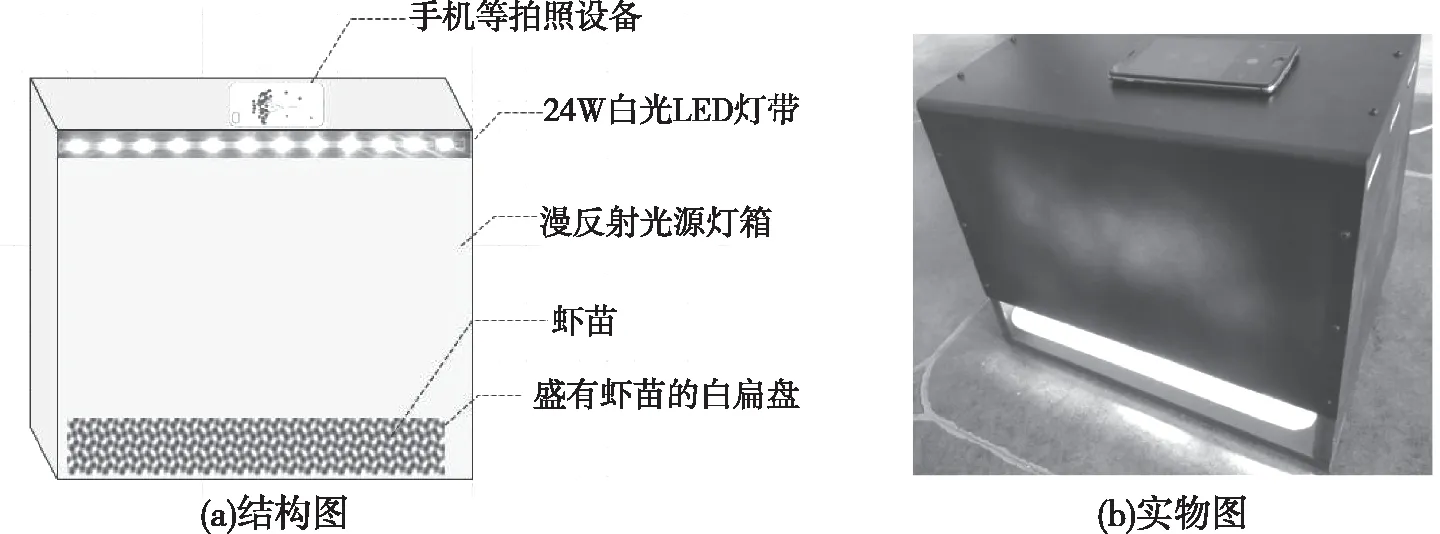
图8 虾苗计数仪原型机
3 讨论
3.1 改进网络模型带来的影响及优化
改进的模型相比基础网络,保持优秀的特征提取能力[20],通过减少了VGG16中不必要的层,使训练时间减少23.86%,模型大小缩小88.40%,提高网络识别的实时性,具有低运算的特点。与其他计数模型比较中,改进网络通过提取更细节的图像特征构建密度函数参数[19]回归分布密度图的方式计数虾苗,算法有更高的鲁棒性和准确性,计数稳定性也显著提高,解决了一定虾苗密度和重叠度计数困难的问题,说明本研究模型更适合实际情况,可以更好地估计虾苗的数量以及有效区分背景区域和虾苗目标,无须进行预处理或人工操作,满足了实际虾苗计数的需求。
3.2 光电计数仪与计数仪原型机对比
光电计数仪在虾苗之间粘连接触通过水流时,因虾苗的大小不一致,通道获得的虾苗电信号会不准确,导致计数误差、计数稳定性差等问题[4],并容易在操作过程中受熟练度的影响使苗种存活率会有所降低,但相较于手工计数在计数速度上有很大优化。计数仪原型机操作简便、停留时间短、智能化程度高,使用过程中对虾苗的伤害很小,在保证计数速度、精确度的同时,可以稳定对虾苗自动计数。
5 结论
改进的网络模型相比于传统的图像处理方式以及其他网络模型,在计数准确度、效率和稳定性都有提高,基本能解决虾苗交易和养殖过程的计数问题。但虾苗过分密集会因其过分重叠而丢失相当多的虾苗证据,导致自动预测准确性计数下降。未来通过更大量的虾苗数据集标记学习,进一步优化网络模型参数,提高密度图的质量,使虾苗计数精度和鲁棒性获得一定程度的提高。本研究可延伸推广到对鱼苗的智能化计数中。
猜你喜欢
计算机应用(2022年9期)2022-09-25
当代水产(2022年3期)2022-04-26
软件导刊(2022年3期)2022-03-25
当代水产(2021年6期)2021-08-13
当代水产(2021年4期)2021-07-20
当代水产(2021年3期)2021-07-20
中等数学(2020年8期)2020-11-26
小学生学习指导(低年级)(2020年4期)2020-06-02
数学大王·低年级(2019年8期)2019-08-27
计算机技术与发展(2019年1期)2019-01-21
