
基于边缘检测和Blob分析的车牌识别技术研究
2021-01-13 12:17李百明
装备制造技术 2020年10期
李百明
(闽南理工学院,工业机器人测控与模具快速制造福建省高校重点实验室,福建石狮362700)
随着科技的进步和人们生活水平的提高,对汽车的需求量逐年上涨,导致城市交通问题日益严峻。智能交通系统(Intelligent Traffic System,简称ITS)的出现带来了高效可行的解决方案[1]。ITS将计算机、图像处理、通信、自动控制及模式识别等技术综合运用于现代交通管理体系中,实现交通管理的自动化与车辆行驶的智能化,解决了交通管理中存在的一系列问题[2-3]。车牌识别技术是ITS不可或缺的核心技术,30年间受到大量学者和企业的广泛研究,诞生的识别方法层出不穷。目前,国外的车牌识别系统已经非常成熟,比如英国PIPS公司的号牌识别系统堪称世界最先进的识别系统[4];美国SCT公司研发的车牌识别系统,在车速高达350 km/h的情况下仍可以捕捉到车牌牌照[5-6];以色列Hi-Tech公司的See Car系统,几乎可以识别所有国家的车牌。但国外的车牌识别系统无法识别中国的车牌,因为中国的车牌除了数字和字母外还有汉字字符。国内对车牌识别系统的研究始于20世纪90年代,业界口碑较好的车牌识别系统有厦门宸天车牌识别公司的SupPlate、深圳科安信实业有限公司的KC系列等产品,并已在高速公路收费站和大型停车场等场所得到了成功的应用。然而,现有的车牌识别系统在交通监控、卡口治安系统上对违章或违法犯罪车辆快速进行车牌锁定的时效性和准确性上仍有很大的差距[7]。因此,建立一个成熟完善的车牌识别系统迫在眉睫。
车牌识别技术的核心是车牌的定位和字符识别,其中车牌能否精准定位直接决定了系统识别成功率的高低。目前,常用的车牌定位方法有基于颜色识别定位法、基于边缘检测定位法和基于Blob分析定位法。颜色识别法依据车牌的背景色进行目标区域定位,利用颜色模型通过车牌的颜色来寻找车牌所在位置[8、9]。颜色识别法的优点是对车牌的大小、位置及图像背景的限制较少;缺点是当车身颜色与车牌颜色相近时,差错率较高。边缘检测法根据车辆、车牌及字符之间存在着明显的灰度变化这一特点,只保留高频的车牌区域、车辆边缘和字符,去除图像中大量无关信息,仅保留最基本的轮廓结构,再利用车牌的形状特征实现目标区域定位。边缘检测的优点是能成功定位大多数车牌;缺点是当车牌图像中有大量矩形边缘时,难以准确的定位车牌所在区域。Blob分析法根据车牌区域与周围背景灰度值存在较大差异这一特点,运用二值化、形态学和特征筛选等手段实现车牌区域的定位。Blob分析的优点是灵活性好[10]、能保留车牌的完整图像信息;缺点是受背景光的影响较大、适应性差。
针对上述问题,本文提出了一种改进型定位方法——基于边缘检测和Blob分析定位法,并设计了一套完整的车牌自动识别系统。该系统具有适应性强、定位快速和识别准确率高等特点。本文的创新点如下:(1)在HSV颜色空间采用边缘检测算法对车牌在图像中的区域进行粗定位。(2)利用Blob分析法对粗定位的区域做进一步筛选,实现车牌的准确定位。
1 车牌识别系统设计
本文设计的车牌识别系统由车牌采集、通道转换、车牌定位、字符分割、字符识别和车牌显示六个模块组成,系统的原理如图1所示。
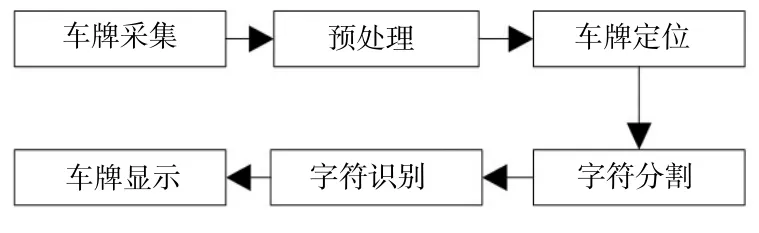
图1 车牌识别系统原理图
车牌采集模块负责加载事先拍摄好的车牌图像,或从摄像机中实时获取车牌图像;通道转换模块负责颜色空间的转换;车牌定位模块负责提取出车牌所在区域,定位时先用边缘检测法进行粗定位,再由Blob分析进行精定位;字符分割模块负责将车牌中的字符分割开来;字符识别模块完成车牌的识别功能;车牌显示模块负责显示提取出的车牌信息。
1.1 通道转换
图像的颜色有多种表示方式,最常用的是RGB颜色模型。车牌采集模块采集到的图像便是RGB三通道图像。R、G、B分别表示红、绿、蓝三种基本的颜色。彩色图像在处理前,一般需要进行降维处理,常用的降维方法有图像灰度化处理和图像通道拆分。在实际的车牌识别系统中,无论是将车牌图像直接转成灰度图像还是拆分成R、G、B三个单通道的灰度图像,车牌的特征都不太明显,不利于车牌的准确定位。
除了RGB颜色模型外,图像的颜色还可以用HSV颜色模型来描述。其中,H为色调,表示颜色的纯度;S为饱和度,表示颜色由浓渐渐变淡的特征;V为亮度,表示光场的强度。HSV颜色空间能较好的反映人对色彩的感知和鉴别能力。将RGB颜色模型转成 HSV颜色模型可用公式(1)~(3)来表示[11]。
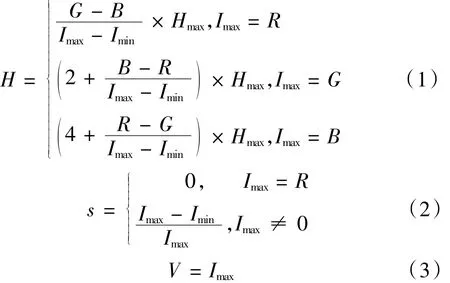
图2为对原彩色图像拆分后得到的R、G、B三个单通道灰度图像。图3为由R、G、B转换的H、S、V图像。从图2和图3可知,在RGB空间车牌区域特征并不明显,将其转换为HSV通道后,S通道的车牌区域特征特别明显,为下一步的车牌定位做好了准备。

图3 车牌图像HSV通道
1.2 车牌定位
1.2.1 边缘检测粗定位
常用的边缘检测算法有Robert算法、Sobel算法、Prewitt算法和Canny算法。其中,由于Canny算法具有对信号干扰适应性强、边缘检测准确完整、连续性好等优点[12],所以本文采用Canny算法对车牌区域进行粗定位。
Canny算法边缘检测的步骤[6]如下:
(1)滤波
用高斯滤波器和车牌图像进行卷积,达到平滑降噪的目的,具体实现如公式(4)所示。
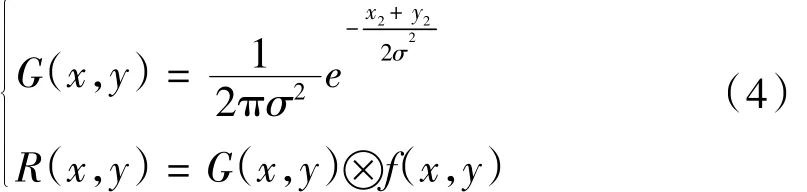
式中:G(x,y)表示二维高斯卷积核;σ表示高斯分布参数;f(x,y)表示处理前的图像;R(x,y)表示处理后的图像。
(2)计算梯度的幅值和方向
用一阶偏导的有限差分计算图像沿X与Y方向的偏导数Gx、Gy,则梯度的幅值和方向如公式(5)所示。
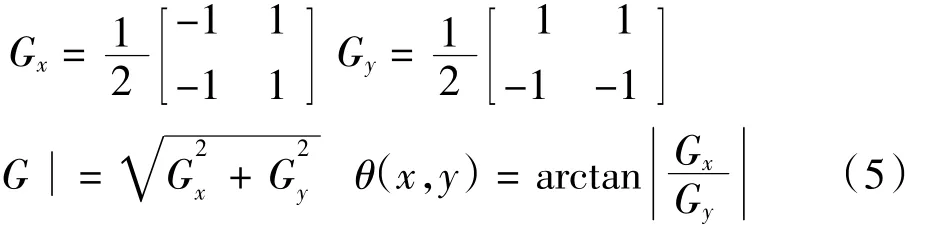
(3)对梯度幅度值进行非极大值抑制
非极大值抑制就是寻找像素点的局部最大值。非极大值抑制的原理是先沿幅角方向检测模值,其最大值处即为边缘点,再沿8个方向进行遍历,并比较像素点偏导值与邻像素的模值,得到的最大值点为边缘点,然后将其灰度值清0。重复上述操作,即可得到初步的边缘位置。
(4)用双阈值算法检测,并对边缘进行链接
用两个阈值 A,B(令 A<B)作用于步骤(3)获取的图像,阈值A检测出的图像边缘相对完整,但噪声多;阈值B检测出的图像滤掉了大部分噪点,但边缘信息不完整;最后用A检测的图像对B检测出的图像进行补充,便可得到链接边缘。
图4是用Canny边缘检测算法提取的车牌区域。从图4可知,利用Canny算子准确的找到了车牌区域的边界,且边界信息完整,但也产生了很多假边缘,需要进一步处理。

图4 边缘检测结果
1.2.2 Blob分析精定位
Blob又称团块,是指像素相连通的区域。Blob分析就是对连通阈的形状、数量、方向等特征进行统计和处理,进而达到检测目的。
(1)二值化
二值化的目的是将边缘检测后的图像对象转换为区域对象,同时缩减车牌区域以外的区域,减少干扰,保留关键信息。车牌图像二值化的难点是阈值的选取。常用的阈值确定方法有固定阈值法和自适应阈值法。本文采用自适应阈值法中的大津法(OTSU)来实现车牌图像的二值化[13],OTSU的原理如下。
设当前的阈值为T,背景点占整幅图像的比例为ω背,背景点的灰度均值为,前景点占图像的比例为ω前,前景点的灰度均值为,则整幅图像的灰度均值u为:
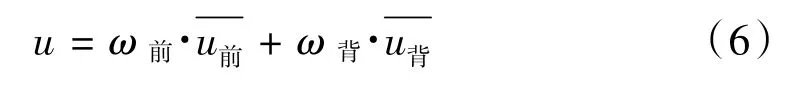
设前景与背景的类间方差为g(T),则
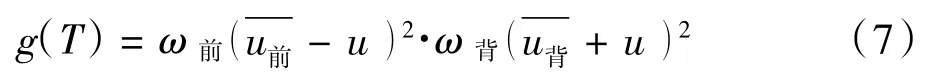
将(6)式带入(7)式,得类间方差的等价公式为:
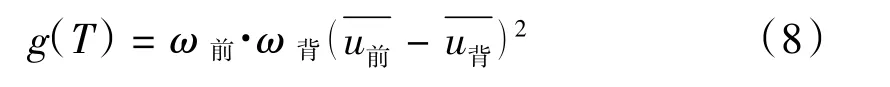
最后只需遍历每个灰度值,找到这个灰度值所对应的类间方差,当某个灰度值使g(T)最大时,该灰度值即为最佳分割阈值。对粗定位后的图像进行OTSU阈值分割后的结果如图5所示。

图5 OTSU二值化图
(2)形态学处理
经二值化处理后,车牌字符之间可能变成多个分离的区域,在车牌的定位中,需要将这些部分变成一个整体。因此,先对二值化后的区域进行膨胀处理,使分开的相邻字符区域连成一个整体,并对区域中的细小孔洞进行填充。但经膨胀处理后,车牌所在区域变大了,为了获得车牌的实际大小,还需在进行一次腐蚀处理。图6为先膨胀后腐蚀后的结果。

图6 先膨胀后腐蚀结果
(3)特征筛选
我国的车牌都是矩形的,且长宽比为3∶1,可根据这一特征对图像的候选区域进行筛选。对于实际拍摄的图片,车牌可能发生倾斜和变形,故将车牌的长宽比设为2~6。另外在图像中车牌区域还有一定的面积,且外形似矩形,因此本文同时选择了面积、长宽比和矩形度三个方面的特征对候选区域做最终的筛选。图7为经过筛选后得到的车牌位置,图8为转正后的车牌。

图7 定位后的车牌

图8 转正后的车牌
1.3 字符分割
字符分割是指将车牌中的7个字符分割成相互独立的连通域,每个连通域代表一个待识别的字符。中国的车牌是由字符、数字加汉字组成的。通过分析不难发现所有的数字和字母都是一个完整的连通域,而汉字在提取时却有些复杂。由于汉字存在上下结构、左右结构,很容易误将一个汉字拆成多个字符,进而影响识别结果的准确性。为解决这个问题,本文先将转正后的车牌图像转成灰度图像,然后将灰度图像变成白底黑字模式,为后续字符识别做好准备;接下来对灰度图像进行二值化,并联合特征筛选实现车牌字符的筛选。经二值化处理后,汉字可能被拆成两个独立的连通域,因此需要对特征筛选后的区域进行膨胀处理,使分开的区域连在一起。膨胀后车牌的字符会发生变形,影响识别结果,故还需做每个字符的最小外接矩形,最后用这些外接矩形和原图像求交集,便可得到7个完整独立的区域。图9为字符分割的详细流程,图10为分割后的效果。
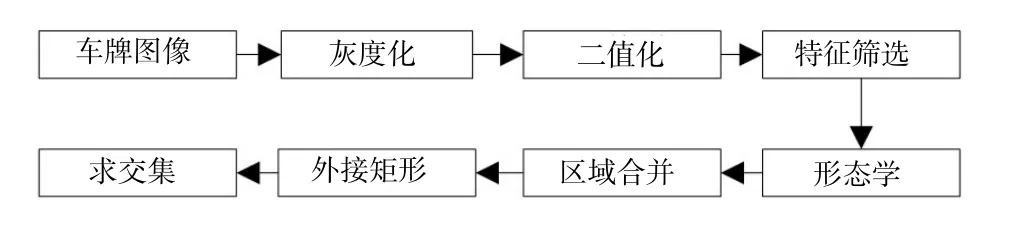
图9 字符分割流程图

图10 字符分割结果
1.4 字符识别
目前,车牌字符识别的常见方法有基于规则推理、基于模板匹配和基于人工智能等方式[14]。本文采用基于MLP(Multilayer Perceptron,多层感知)分类器进行字符识别。MLP也叫人工神经网络(Artificial Neural Network,ANN),是一种模仿生物神经元传输的机制,主要由输入层、输出层和多个中间隐藏层构成。最简单的MLP只有一个中间隐藏层[15]。MLP的三层结构如图11所示。图12为MLP分类器字符识别的基本流程。
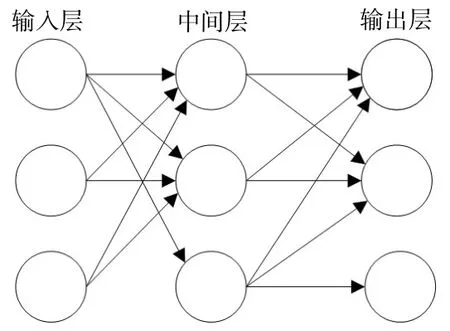
图11 多层感知器
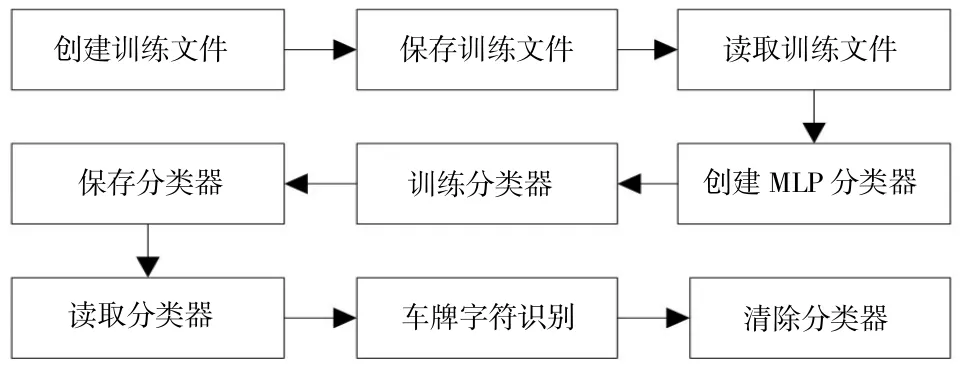
图12 MLP分类器车牌字符识别流程图
2 检测实验及结果分析
车牌识别系统的算法部分采用德国Mvtec公司开发的Halcon机器视觉软件平台进行设计,该平台具有强大的几何与图像计算能力,被广泛应用于工业自动检测领域。但Halcon软件无法直接生成应用程序,故系统的GUI界面部分在VS2015平台上采用C#编程语言设计。
本文从网络上搜集了20幅白天拍摄的车辆照片对该系统进行测试。经过统计20张车牌中有19张车牌可以实现精准定位,1张车牌定位区域偏大,但并未对车牌的正确识别产生影响;有18张车牌被准确识别,2张识别失败。本系统对白天车牌的精准定位准确率为95%、字符识别准确率为90%,平均识别每幅车牌的时间为0.485 s。部分识别结果如图13所示。其中图13(a)为正面拍摄时的识别结果,图13(b)为侧拍拍摄时的识别结果。

图13 部分车牌识别结果
经过分析,两幅车牌识别失败的主要原因是:(1)拍摄的车牌图片分辨率低,字符模糊且车牌字符有不同程度的缺损;(2)训练的样本数量太少,不能正确识别不完整的字符。
3 结束语
(1)针对传统车牌定位方法的不足,本文提出了一种在HSV颜色空间下基于边缘检测和Blob分析的定位方法。实验结果表明,白天时该方法定位可靠、准确率接近100%。
(2)在确定了车牌定位方法的基础上设计了一套完整的车牌识别系统,实验表明该系统的识别准确率为90%,平均识别时间约为0.5 s,具备良好的使用性能。
(3)设计了系统的GUI界面,增强了系统的实用性能。该系统可以广泛应用于商场、超市、小区及城市道路交通监控等场合。
(4)本系统目前仅对白天的车辆进行了实验测试,未来的研究工作主要有:1)对夜间的车辆进行识别调试,增加系统的通用性;2)大幅增加训练样本,提高识别准确率;3)加入远程数据库,识别套牌车辆,违章和违法车辆并及时报警。
猜你喜欢
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年12期)2019-07-16
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
科学与财富(2016年28期)2016-10-14
