
运用SAS广义线性混合模型分析裂区试验数据
2021-03-15 01:29张久权李彩斌凌爱芬董建新
中国农业科技导报 2021年2期
张久权, 李彩斌, 凌爱芬, 董建新
(1.中国农业科学院烟草研究所, 农业农村部烟草生物学与加工重点实验室, 山东 青岛 266101; 2.贵州省烟草公司毕节市公司, 贵州 毕节 551700; 3.四川省烟草公司凉山州公司, 四川 西昌 615000)
裂区设计由于能够突破试验条件限制,为实际操作提供方便等诸多优点[1],受到广大科研人员的普遍欢迎,在许多研究领域得到广泛运用[2-11]。然而,由于此类试验数据的统计分析较难,F检验的主区因子和副区因子所用的误差项不同[4,6],主区因子间、同一主区因子不同副区因子间均值比较的t值计算方法也不同[1,12],使裂区试验的数据分析具有很大挑战性。如果仅依赖计算机软件程序进行统计分析,一般很难处理,有些需要手工计算,但计算量很大[1]。从国内外研究进展看,人们对裂区设计的统计分析常常存在误用的现象[2,13]。Yossa等[14]调查表明,65%的已发表SCI论文存在试验设计、F检验或多重比较错误。其中,裂区设计占比较大,但目前有关裂区设计试验的统计方法存在不系统或太复杂等问题,通常需要手工计算,给科技工作者增加了负担。
传统上,学者们在利用SAS程序进行裂区设计的方差分析和均值比较时,主要采用一般线性模型(general linear model,GLM)程序模块,而该程序模块是在20世纪80年代开发的,当时没有考虑到在进行裂区设计的F检验时,主区因子与副区因子需采用不同的误差均方与自由度,均值比较也需采用不同的误差均方和自由度,因而计算F值时需要编写大量的复杂代码来进行修正[15]。后来,虽然可以用 “h=……”语句进行弥补,但是进行处理间均值比较时,需要选用合适的、不同的误差项。然而,对于某些情况,GLM程序模块没有可用于定义所需误差项的选项,所以误差项无法列出[15]。
近年来,SAS等商业软件进行了创新,广义线性混合模型(general linear mixed model,GLIMMIX)有了很大发展[15],其能适用于多种分布的变量[16]。本研究应用SAS的GLIMMIX程序模块对裂区试验数据进行方差分析和均值比较,通过与传统的GLM程序模块和混合模型(MIXED)程序模块进行对比,介绍GLIMMIX 程序模块在裂区试验数据统计中的优势,以供广大科技工作者参考。
1 材料与方法
1.1 试验材料与设计
裂区试验的处理设计一般采用全因子试验,即各因子的水平全部交叉,构成完整的处理组合。关于主、副区因子的确定与分配,参照张久权等[1]方法。下面将采用其中实例进行试验设计和原始数据分析,实例设计如下。
第一年在福建省三明市进行烤烟品种比较试验,单因子4水平随机区组设计,4水平为4个烤烟品种(翠碧1号、KRK26、YN116、CF209),重复3次。第二年,为了探明移栽期对各品种产量的影响,对4个品种增加了3个移栽期:1月24日(1)、1月31日(2)、2月8日(3)处理,试验改为裂区设计,品种为主区因子,移栽期为副区因子。第二年的产量数据见表1。
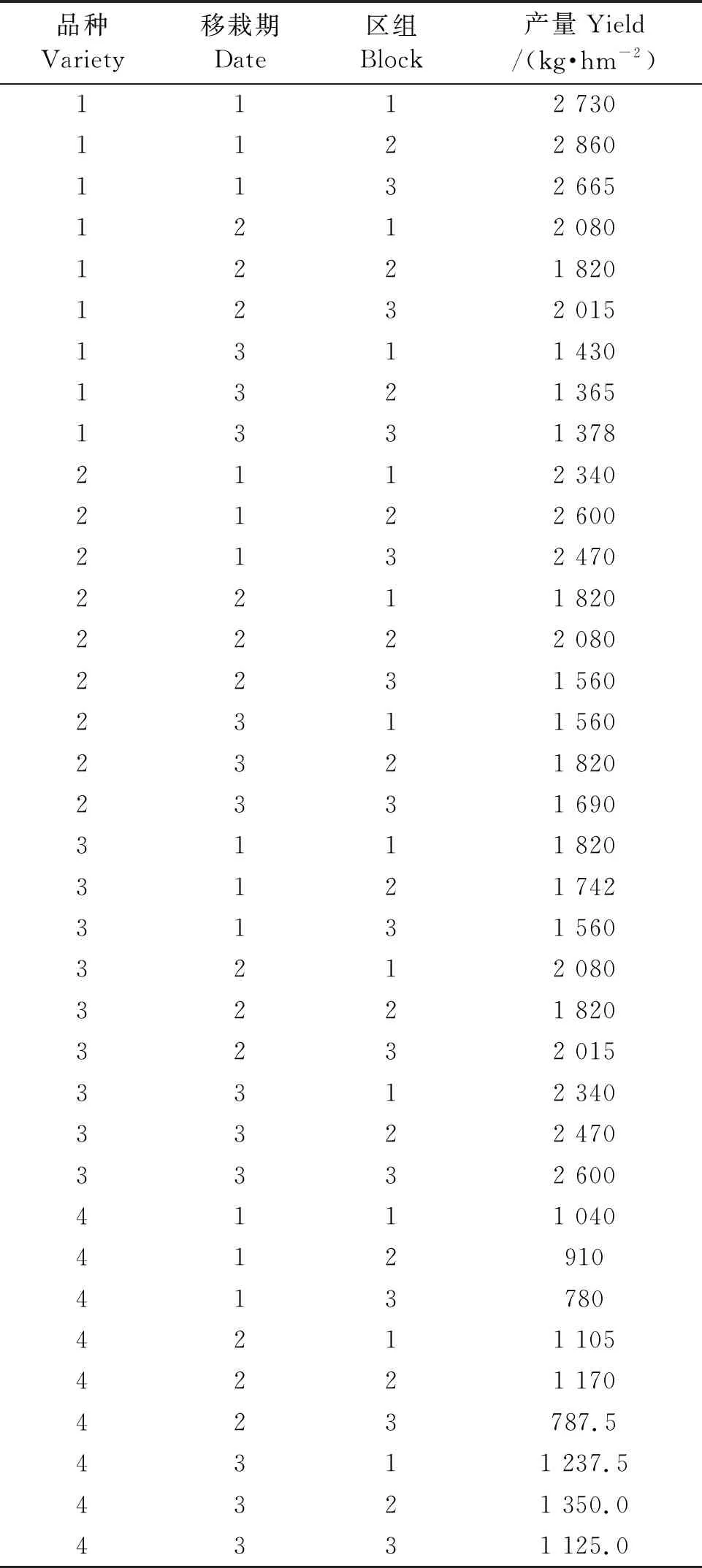
表1 产量数据Excel输入表Table 1 Yield data entry for Excel
1.2 方差分析模型
对于两因素裂区设计,如果主区因子的排列为随机区组,副区因子在主区内随机排列,其线性可加效应模型如下。
Yijk=μ+αi+βj+αiβj+rk+wik+eijk
(1)
式中,Yijk为某小区的观察值,如小区产量;μ为总体均数;αi为主区因素A第i水平的效应,βj为副区因素B第j水平的效应,αiβj为A因素i水平与B因素j水平交互作用效应,均为固定效应;rk为区组K的效应,wik为主区误差,eijk为副区误差,均为随机效应。为了便于理解,将主区元素放在前,副区元素放在后,将(1)式改写为(2)式。
Yijk=μ+rk+αi+wik+βj+αiβj+eijk
(2)
式中,区组效应rk,主区误差wik和副区误差eijk应满足以下条件。
(1)所有的随机效应项rk、wik和eijk相互独立。
(2)区组效应rk为iidN(0, σR2),即rk服从同一正态分布,相互独立,方差均为σR2。
(3)主区误差wik为iidN(0, σw2)。
(4)副区误差eijk为iidN(0, σ2)。
从模型可看出,对于这类资料的分析可以分两步。第一步,将总变异分解为主区组间变异、主区因子间变异和主区误差;第二步,将整个试验的总变异分解为主区变异、副区因子变异、主副因子之间的交互作用和副区误差。
如果主区因子为完全随机,需要将公式(1)和(2)中的区组效应rk删除。其他试验设计的线性模型依此类推。
1.3 方差分析和多重比较SAS程序
1.3.1用GLIMMIX模块进行F检验和所有处理组合间的均值比较 运用SAS 9.4软件的GLIMMIX模块对表1数据进行F检验。SAS程序1的代码如下。
ODS RTF;
ODS graphics on;
PROC IMPORT
OUT= split
DATAFILE= "E:yancao.xls"
DBMS=EXCEL REPLACE;
SHEET="Sheet1$";
GETNAMES=YES;
RUN;
PROC GLIMMIX data = split;
Class block variety date;
Model yield = variety date variety*date / ddfm=satterth;
Random block block*variety;
Lsmeans variety*date/plot=meanplot (sliceby=variety join);
Lsmeans variety date variety*date /diff;
Lsmestimate variety*date ′date1 vs date2 in variety1 ′ 1 -10;
RUN;
ODS graphics off;
ODS RTF close;
程序说明:输入代码时注意分号为英文字符。数据文件存放地址为E:yancao.xls sheet1,数据格式见表1。PROC IMPORT直接读取EXCEL文件的数据。其他数据格式如文本格式也可以输入,但EXCEL比较方便。PROC GLIMMIX调用GLIMMIX程序,采用限定的最大似然法进行F检验和多重比较。Class 语句列出所有的分类变量。Model语句“=”右边只需列出固定效应变量。ddfm=satterth对误差方差、自由度等进行校正,以保证F值的正确性。“Lsmeans variety*date/plot = meanplot (sliceby=variety join)”语句输出交互作用效果图,join选项将各点连成曲线。“Lsmeans variety*date /diff” 语句对所有处理水平组合的最小二乘均值(least square means,lsmean)进行两两比较,计算t值和差异显著性。在平衡的试验设计中,最小二乘均值与处理均值相同。
1.3.2用GLIMMIX模块进行F检验和部分处理组合间的均值比较 SAS程序1中的语句“Lsmeans variety date variety*date /diff;”输出所有处理组合的最小二乘均值及其差值,本例中共64对,输出超过30页。为了有选择性地比较处理组合间的均值差异,需要将上述语句进行替换。如要比较date1(1月24日)与date2(1月24日)的产量差异,即需要替换为“Lsmestimate variety*date ′date1 vs date2 in variety1′ 1 -10;”;要以variety1 date1(翠碧1号,1月24日移栽)为对照进行产量差异比较,则需替换为“Lsmeans variety*date /diff = control (′1′ ′1′);”;要比较品种1(翠碧1号)与所有其他3个品种平均产量的差异,则需替换为“Estimate ‘variety1 vs others’ variety -3 1 1 1 /divisor =3;”。
1.3.3用MIXED程序模块进行F检验和均值比较 SAS的MIXED也可用来进行裂区设计的方差分析。进行F检验时,class、model、random、lsmeans语句的用法与GLIMMIX的完全相同,F检验和均值比较的程序如下。
PROC MIXED data = split;
Class block variety date;
Model yield = variety date variety*date/ddfm=satterth;
Random block block*variety;
Lsmeans variety date variety*date /diff;RUN;
2 结果与分析
2.1 运用GLIMMIX模块进行F检验、多重比较及交互作用比较
运行程序1,得 到F检验的主要结果见表2。可以看出,烤烟产量主区因子品种间、副区因子移栽期之间,以及他们的交互作用效果都达到极显著水平(P<0.001)。因此,有必要分别对各处理组合的产量均值差异进行比较。受篇幅所限,仅列出部分处理组合间的产量均值差异(表3)。其中,第1行数据表示variety1(翠碧1号),在date1(1月24日)移栽的烤烟产量比在date2(1月31日)移栽的极显著地高出780 kg·km-2(P<0.001)。

表2 F检验结果(Ⅲ型)Table 2 Output of F test (Type Ⅲ SS)
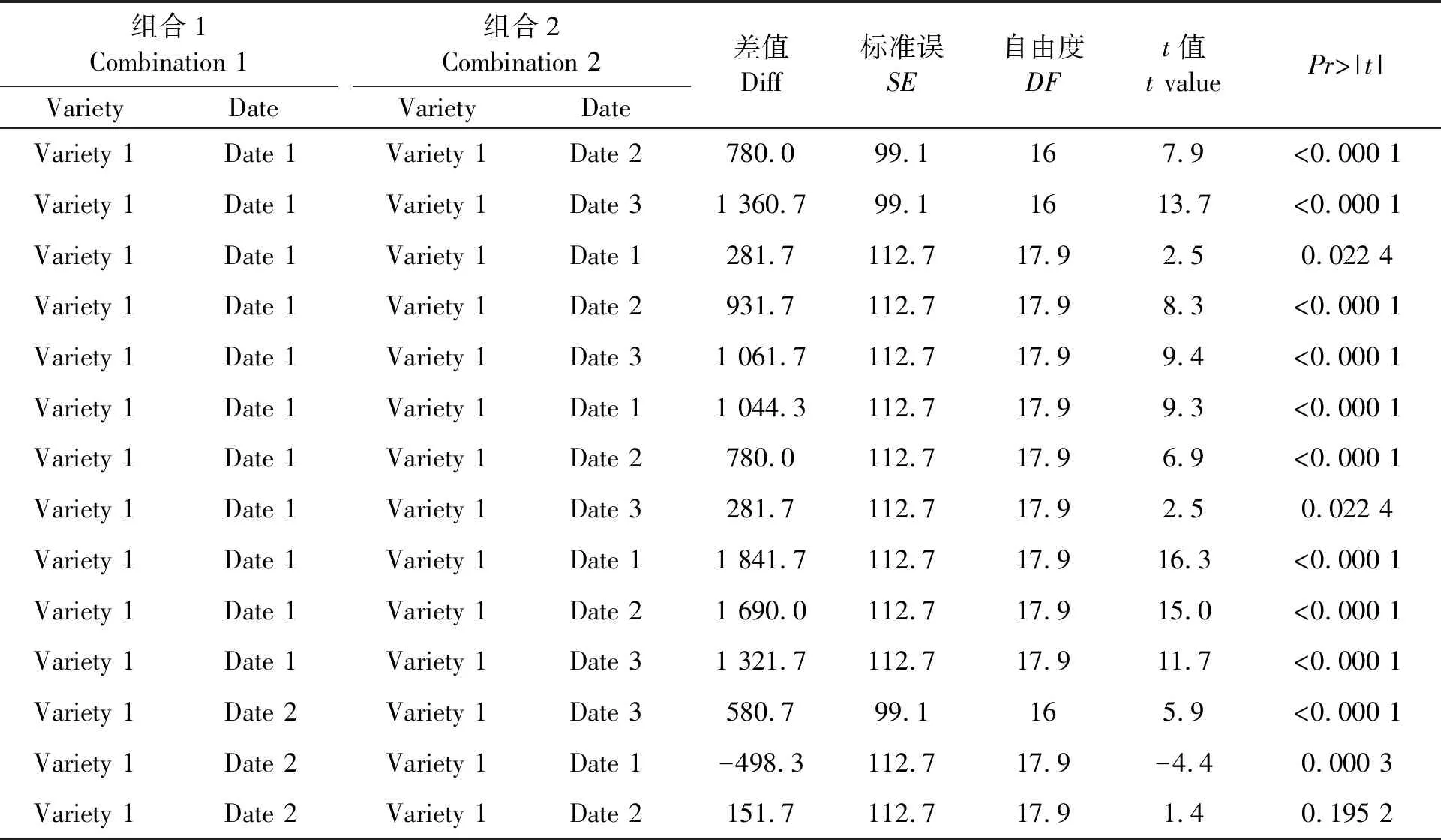
表3 部分处理组合的产量均值差异比较Table 3 Difference comparison of mean yield between part treatment combinations
品种和移栽期的交互作用效果图见图1,可以看出,各品种烤烟产量随不同移栽期处理的变化趋势明显不同,variety1、2随移栽期的推迟,产量下降;variety3、4随移栽期的推迟,产量增加。在date1(1月24日)移栽时,variety1产量最高,variety4最低;而在date3(2月8日)移栽时,品种1产量最低,品种3最高。如果品种和移栽期处理间的交互作用不存在,这些线将呈现平行趋势。
综上,结合均值比较结果(图1)能够很容易地确定产量最高的最佳处理组合,即最佳移栽期为date1(1月24日)的variety1(翠碧1号)。从表3的第1、2行可以看出,variety1的date1组合与variety1的date2组合,及variety1的date1组合与variety1的date3组合差异均为极显著水平。因此,variety1(翠碧1号)的最佳移栽期为date1(1月24日)。
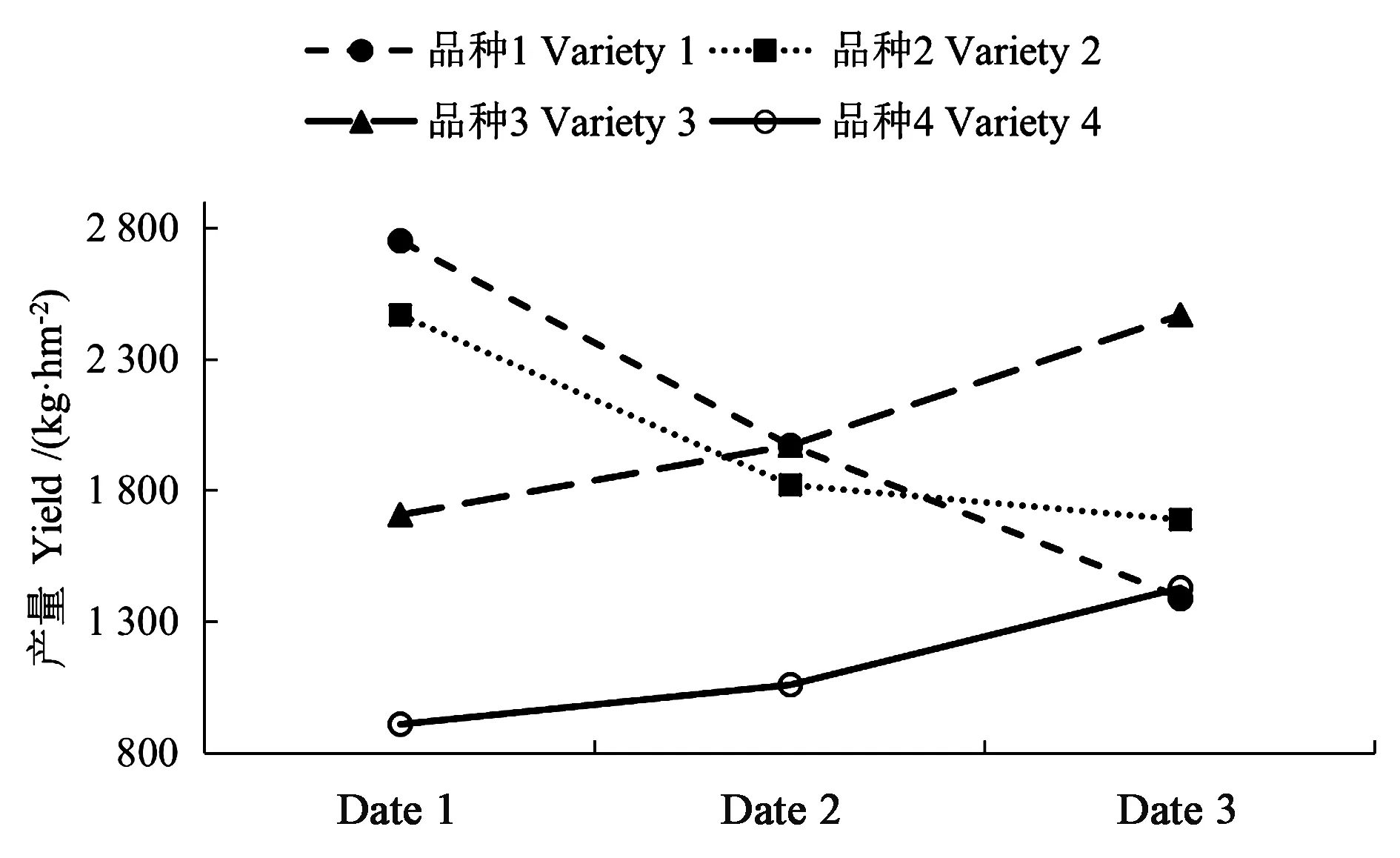
图1 品种与移栽期交互作用Fig.1 Profile of interaction between variety and date
为了进行方法说明,现假定品种与移栽期的交互作用效果不显著,即假定表2中的variety*datePr>F大于0.05,即品种的产量效果不受移栽期的影响,同时移栽期的产量效果与品种无关,此时的均值比较仅需对品种和移栽期分别进行。用Lsmeans variety/diff比较品种间的均值差异,结果见表4。可见,综合3个移栽期的平均产量结果,variety1、2、3与4的产量差异达到极显著水平,而其他品种间无显著差异。用Lsmeans date/diff 比较不同移栽期产量之间的均值差异,结果见表5。可见,综合4个品种的平均结果,date 1与date2和3的产量差异均达到极显著水平,而date2与date 3间无显著差异。需要特别说明的是,这种均值比较只有在品种与移栽期交互作用效果不显著的前提下才能进行,否则没有意义。
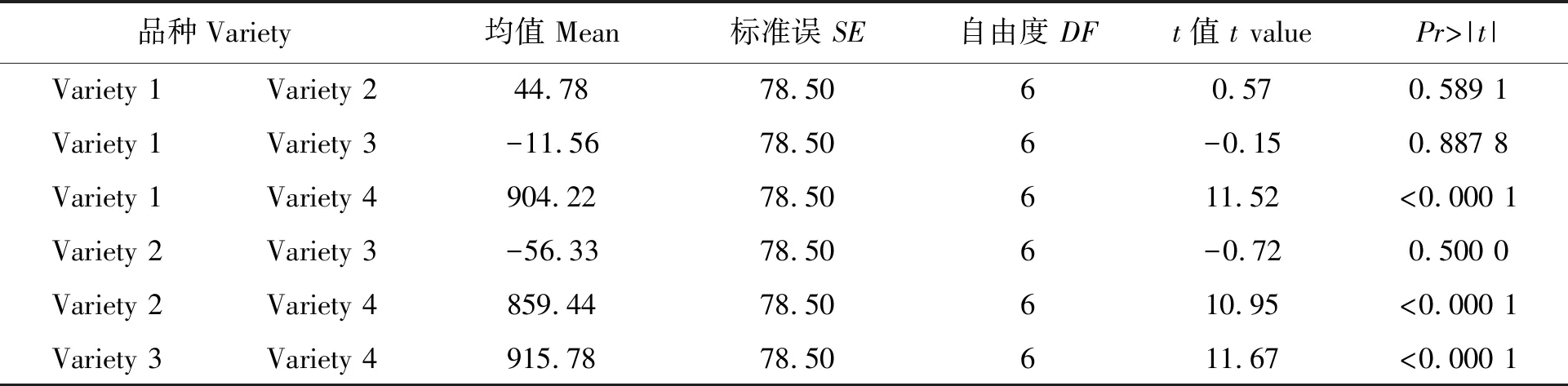
表4 各品种间产量差异显著性(所有移栽期平均)比较示例Table 4 Example of mean difference between varieties across all of the dates

表5 各移栽期间平均产量的差异显著性示例Table 5 Example of mean difference of yield between dates across all varieties
2.2 部分处理组合间的均值比较结果
为了节省输出文档的篇幅,避免产生大量不必要的输出,可以进行某些特定均值间的差异比较,如1.3.2 中语句“Lsmestimate variety*date ′date1 vs date2 in variety1 ′ 1 -10;”的输出结果见表6,可以看出, date1(1月24日)与date2(1月31日)的产量差值为780.0 kg·hm-2,与表3中date1(1月24日)与date2(1月31日)的产量差值相同。说明语句“Lsmestimate variety*date ′date1 vs date2 in variety1 ′ 1 -10;”的作用与“Lsmestimate variety*day”是相同的,但该语句的输出内容更简洁。

表6 Lsmestimate 输出示例Table 6 Example output of Lsmestimate
3 讨论
在进行裂区设计的方差分析时,通常采用ANOVA或GLM程序模块[1, 5, 17-18]。由于主、副区处理需要采用不同的误差方和及自由度,ANOVA或GLM缺乏内置程序进行自动处理,某些情况下需要手工计算,大大增加了计算量和难度[1],且容易出错。本研究采用GLIMMIX程序模块能恰当地解决这些问题,即使是非平衡设计(如各处理组合的重复次数不等或缺区)的情况。
本研究采用的实例数据与孙久权等[1]的实例数据完全相同,而孙久权等[1]采用GLM进行统计分析,程序繁杂,如其在计算variety处理效应(主区因子效应)的F值时,SAS的默认方法有误,需要通过语句"Test h = replicate variety e = replicate*variety”进行修正,才能得到更准确的、与采用GLIMMIX程序模块相同的F值(64.92)。MIXED和GLIMMIX能够区别对待固定效应和随机效应变量,在Model语句中,只需列出固定效应变量即可,如本研究中可以采用以下语句。
Model yield = variety date variety*date / ddfm = satterth;
Random block block*variety;
而GLM程序模块的model语句需要列出所有变量,如孙久权等[1]的model语句如下(replicate与block等同)。
Model yield = replicate variety date replicate*variety variety*date;
Test h = replicate variety e = replicate*variety;
为了正确计算主区因子的F值,GLM程序模块需要使用Test语句。类似地,使用LSMeans进行主区因子间的差异比较时,必须单独指明误差项,即“LSMeans variety/ e = replicate(variety) stderr, tdiff;”;否则GLM程序模块将默认使用副区误差项计算t值。
在MIXED和GLIMMIX程序模块中,只要在random语句中列出随机效应项,如本研究中的“Random block block*variety”,SAS在计算F和t值等统计量时,就会根据适当的方差结构,自动选用恰当的误差项方和与自由度等,这是GLIMMIX程序本身事先内置的功能。GLM缺乏该内置功能,需要列出误差项,即使使用random语句也不能实现。然而,有些情况下,GLM程序模块缺乏此内置误差项,因而GLM不能自动计算该统计量[15,19-20]。此外,GLIMMIX程序模块可以方便地输出交互作用效果图(图1),但GLM和MIXED无此功能。
虽然GLIMMIX模型在分析裂区设计试验数据时,优势很多。但是,GLIMMIX模型是基于线性混合模型进行迭代的[20],不能用于嵌套模型的比较,且允许残差方差及不同协方差结构的类型有限[21],由于PROC GLIMIX对随机效应的标准误估计有偏差,因而不能用于随机效应的显著性检验。
在GLIMMIX进行裂区设计试验数据分析时,仍有一些要点需要注意。本研究程序1用ddfm=satterth对标准误、自由度等进行校正,以保证F值的正确性。Kenward和Roger[17]用“ddfm = kr”来修正标准误、自由度、检验统计量等的计算,所得结果的准确性得到进一步提高。如果裂区设计为平衡设计,satterth和kr效果完全相同;如果为非平衡设计或存在缺区,尤其是在重复测量和空间相关的情况下,二者有本质区别,推荐使用kr。在输出交互作用图时,本研究将变量date视为分类变量,所以x轴为等距。如果x轴要按比例显示,需要采用Gplot程序作图。如果要将variety设为横坐标,可用sliceby= date 代替sliceby=variety 选项。程序1的输出不含某些均值比较。例如,检验品种1与所有其他3个品种平均产量的差异显著性时,可以通过estimate、contrast或lsmestimate语句后的系数来实现,语句为“Estimate ‘variety1 vs others’ variety -3 1 1 1 /divisor =3;”。其中,系数的顺序一定要与程序1中class语句的变量顺序一致,即variety在date之前。本研究中,各品种的产量与date存在直线或曲线关系(图1)。因此,可以以移栽期为自变量,产量为因变量进行回归分析,建立产量与移栽期的回归方程,用以预测产量,具体可采用SAS的REG、MIXED等模块进行拟合和统计检验。
在MIXED模块中,SAS使用限制最大可能性估计(REML)或ANOVA方式进行方差分量,默认方式为REML。若采用ANOVA进行估计,语句为“PROC MIXED data = split method = type3”。对于平衡设计,REML与ANOVA结果相同,但ANOVA能够输出更详细的方差分析结果。在进行均值比较时,GLIMMIX模块可采用estimate、contrast或lsmestimate语句。但lsmestimate语句是针对GLIMMIX模块开发的,MIXED模块不能使用。然而,estimate、contrast语句的写法较繁琐[19],SAS公司对其进行了简化,变为lsmestimate,写法更加简便[20]。
猜你喜欢
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
数学大世界(2018年35期)2018-02-22
发明与创新·中学生(2017年5期)2017-05-12
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
山东青年(2016年2期)2016-02-28
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
