
基于改进YOLOv3的猪脸识别
2021-03-19 05:56何屿彤陶浩兵辜丽川
中国农业大学学报 2021年3期
何屿彤 李 斌 张 锋 陶浩兵 辜丽川 焦 俊
(安徽农业大学 信息与计算机学院,合肥 230036)
近年来,随着生猪养殖业智能化的发展,生猪的精准管理变得尤为重要,而识别生猪个体则是进行针对性养殖的关键。传统的识别方式包括颜色标记、佩戴射频识别耳标(Radio frequency identification,RFID)等。使用颜色标记的方法虽然直观,但仅限于生猪较少的情况;而佩戴耳标则可能存在耳标损坏,脱标以及生猪感染寄生虫等问题。
现有的猪脸识别研究较少,主要包括:1)Naoki等[1]利用特征空间方法,采用手动分割的特征实现生猪个体识别,在16个类别的数据集上达到 97.9% 的识别率;2)Hansen等[2]搭建了基于卷积,最大池化等结构的CNN模型,在农场猪脸识别上取得了较好结果;3)秦兴等[3]利用双线性卷积神经网络进行生猪面部特征提取,并将不同层次的特征做外积融合形成最终个体特征,在其测试图像集上达到了95.73%的识别准确率。上述研究在解决猪脸识别问题时,主要考虑单个个体样本受光照、姿态、场景等因素的影响,当样本图像中有多个个体时,难以完成自动化管理中复杂环境下的多个体识别任务。
随着深度学习技术在计算机视觉领域的广泛运用[4-6],深度卷积神经网络在人脸识别领域成果颇丰。理论上,应用于非侵入式场景的人脸识别对于猪脸识别有一定参考价值。深度学习技术在人脸识别领域的研究主要包括:1)Taigman等[7]提出的Deep-Face方法,使用4 000个人200万的大规模训练数据训练深度卷积神经网络,对人脸对齐和人脸表示提出改进,在LFW数据集上达到97.35%的准确率;2)Sun等[8-9]提出的DeepID系列使用25个网络模型,并在网络结构上同时考虑分类损失和验证损失等,显著提升了人脸识别效果;3)Sun等[10]提出的DeepID2神经网络结构利用人脸识别信号提取不同人脸特征,增大不同人脸图像间的类间差异,并使用人脸验证信号提取同一个人脸的特征,减小类内差异,从而学习到区分能力较强的特征;4)Florian 等[11]提出的FaceNet网络结构共拥有27层网络层,引入Triplet损失函数提取人脸的特征信息,使得模型的学习能力更高效;5)Omkar等[12]在网络结构中引入跨层连接,并使用了260万的大规模数据集,在LFW和YTF数据集上达到很好的结果。
基于以上研究,本研究拟采用在骨干网络中引入密连块(DenseBlock)以及在检测器中引入改进的SPP单元的方法,以期设计出能够在多个尺度特征图上对不同大小的目标进行检测,能够有针对性的实现多个体识别任务的猪脸识别算法。
1 材料与方法
1.1 样本采集
样本猪来自安徽蒙城京徽蒙养猪场,使用罗技C920 Pro摄像头作为实时采集工具,利用NanoPc-T4开发板将USB连接的摄像头采集到的图像传输到开发板的I/O缓冲区中,在开发板的图形运算单元上对图像数据进行压缩打包处理,利用4G通信模块将图像信息经过互联网传输到服务器。试验中安装摄像头的圈舍光照较为充足,且试验采集装置能够远程控制摄像头的旋转,使得采集到的样本图像具有不同角度的生猪个体脸部信息。
为保证采集到的样本画面连续,能够辨认生猪个体是否为同一只,试验采集装置采样时间间隔设置为0.5 s;由于过短的时间间隔可导致采集的样本图像之间相似度过高甚至画面接近重复,故对采集到的样本图像进行了筛选。本研究对连续采集图像之间采用结构相似性指数(Structural similarity index,SSIM)进行比较。经过对样本进行一系列的比较试验,试验样本同时选用SSIM值<0.78的2张图像,若大于该值,则选用序号靠后的图像,样本图像分辨率为1 920像素×1 080像素。
1.2 YOLOv3
YOLOv3模型使用连续的1×1和3×3卷积以及残差模块构成了1个包含52个卷积层以及1个全连接层的53层特征提取器Darknet53,结构见图1,此时输入图片大小为256像素×256像素。在预测时,为了能够充分利用早期特征映射中的上采样特征和细粒度特征,YOLOv3模型使用了多尺度预测方法[13],输入图片大小为416像素×416像素。YOLOv3模型首先去除特征提取结构中的全连接层,在最后1个残差块的后面增加若干个核大小为1×1和3×3的卷积层集合,并使用最后1个1×1卷积层进行预测,此即为scale1。然后对该尺度提取到的特征图执行上采样操作,并使用concat操作将其与上一个残差块提取到的大小为26×26的特征拼接,拼接后的特征图投入其后的多层卷积集合并预测,此即为scale2。最后,将scale2中提取的特征上采样到52×52,并将其与上上个残差块输出的特征拼接形成大小为52×52的特征图,将该特征图输入其后的卷积层集合进行第3次预测,此即为scale3。
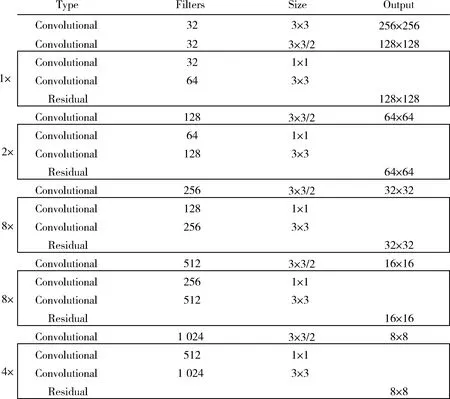
图1 Darknet53结构
YOLOv3模型提供3种不同尺寸的先验框,并依据不同的下采样尺度,采用K-means方法聚类得到9种尺寸的先验框,按照大特征图小尺寸框的原则分配。YOLOv3模型利用线性回归预测每个先验框的目标分值[14]。网络模型给每个ground truth对象只分配1个先验框。训练时,采用误差平方和作为边框预测的损失函数。图2给出先验框与预测边界框在图像上的关系。预测边界框的中心坐标(bx,by)及宽度bw,高度bh的计算过程为:
(1)
式中:σ()为sigmoid函数;tx,ty为预测边界框的中心偏移量;Cx,Cy分别为目标所在单元相对于图像左上角的横坐标与纵坐标;pw,ph分别为先验框的宽度和高度;tw,th分别为预测边界框的宽度和高度缩放比例。
YOLOv3模型为每个边界框采用多标签分类,使用单独的逻辑回归分类器取代softmax分类。在训练过程中,利用二值交叉熵损失(Binary cross entropy)来预测类别。

1.先验框;2.预测边界框
1.3 DenseNet
密连网络(DenseNet)是卷积神经网络中的一种跨连模型。密连网络包括密连块和用于连接密连块的过渡层。密连网络的优势在于能够有效解决深层神经网络的梯度消失问题,并在实现特征重用的同时减少了参数[15-16]。

xl=Hl([x0,x1,…xl-1])
(2)
式中:xl为第l层的输出;Hl(·)为批标准化层(Batch normalization layer,BN Layer),ReLU函数以及3×3卷积层构成的组合函数。
2 YOLOv3_DB_SPP模型
由于猪场养殖环境的限制,采集到的生猪样本面部存在脏污遮挡,需要深层神经网络提取更具表征性的特征用于识别。然而,由于标记检测图像的时间代价大,短期内无法获取较大的样本数来应对深层神经网络可能出现的梯度消失问题。本研究在原始YOLOv3模型的基础上提出了YOLOv3_DB_SPP模型。该结构首先在基础特征提取器中引入了DenseNet中的DenseBlock。其次,为了在不引入过多参数的前提下融合多尺度的信息,该结构在骨干网络之后添加改进的SPP单元,以提高检测猪群样本中占整张图片面积较小的生猪个体时的准确率。
2.1 特征提取器
YOLOv3_DB_SPP模型的特征提取器包括Convolutional单元和DenseBlock模块2部分,结构见图3。Convolutional单元由BN Layer,7×7或3×3的卷积层,Leaky ReLU激活函数构成(图4)。其中BN Layer用于自适应的重参数化,起到避免网络参数分布发生偏移的作用,在一定程度上能够缓解深层网络的过拟合以及梯度消失问题,且对参数初始化的影响比较小。为了更充分的保留原图信息,提高对小目标的检测精度,本研究参考ResNet[17]和GoogLeNet[18]的做法,将特征提取器第一个卷积层的核大小设置为7×7,并在该层实现第一次下采样,其余的4次下采样均采用3×3的卷积层实现。
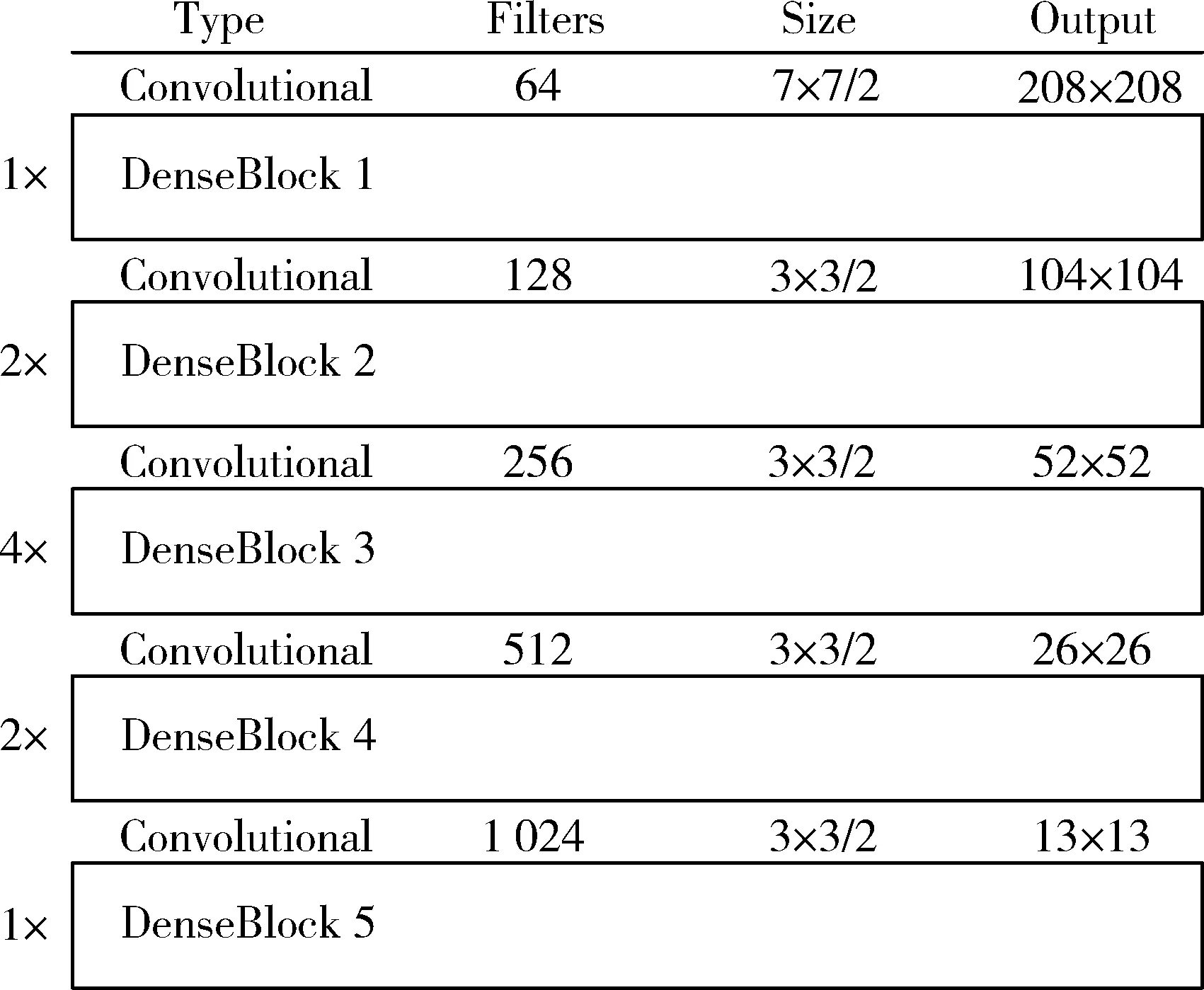
图3 特征提取器
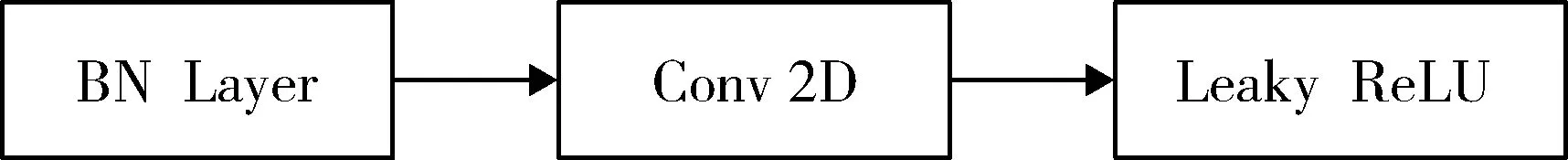
图4 Convolutional单元
改进的特征提取器使用DenseBlock代替原来的Residual单元,DenseBlock中每个卷积层输出的特征图数目为k,k值的设置较残差模块会小得多,使得网络更窄,在加深层次的同时参数数目不至于增长的过多,减少网络计算量。本研究采用的5个DenseBlock除Denseblock1之外其余4个DenseBlock的结构一致,如图5所示。其中非线性转换Hi由BN Layer,1×1的卷积层,Leaky ReLU激活函数以及大小为3×3的卷积层组成。本研究使用Leaky ReLU函数取代原DenseNet网络中使用的ReLU函数,以防止取到负值的参数被置0导致该神经元无法学习。在3×3的卷积层之前仍然添加1×1的卷积作为瓶颈层,用于对输入到3×3卷积层的特征进行降维,减少计算量。
为了不引入过多参数,本研究使用的DenseBlock1中每个卷积层的输出通道数设置为32,且仅使用3层的结构。经过DenseBlock1对特征的重复利用之后,对后面的DenseBlock2,3,4采取或加深层次或减小输出通道数的做法,这3个密连块的k值分别为16、16、32,且均包含8个卷积层。最后一个密连块为了输出更加丰富的特征信息设置了较大的通道数64,采用4层结构。由于DenseBlock中的卷积层较Residual中要多,故将其叠加使用次数分别减少到1、2、4、2、1。避免因次数使用过多导致网络层次过深,影响到模型的效率。YOLOv3_DB_SPP模型结构见图6。
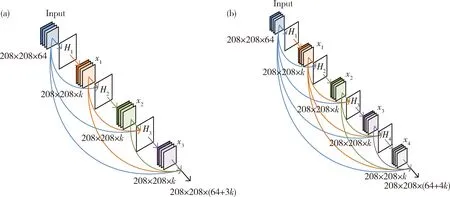
图5 DenseBlock1(a)和DenseBlock2,3,4,5 (b)的结构图

图6 YOLOv3_DB_SPP模型结构图
2.2 检测器
由于猪场养殖环境分为单只圈养和多只圈养,采集多只圈养的样本时,样本图像中生猪个体多且拥挤,部分生猪距离摄像头距离较远,且有遮挡猪脸的情况发生。为了能够检测到这类小目标,本研究提出的YOLOv3_DB_SPP模型引入了改进的SPP模块。
在YOLOv3_DB_SPP模型中,先在特征提取器之后增加Convolutional Set。它包括3组1×1和3×3的卷积层,再在该单元的后面引入改进的SPP单元(图7)。改进的SPP单元对卷积层提取的特征图分别进行大小为7×7,5×5以及3×3的最大池化。为了保持输入输出尺寸一致,在池化操作前对特征提取器的输出做了padding操作,并设置池化步长为1。

图7 改进的SPP单元
改进的SPP单元对3种不同尺度池化的结果进行了concat操作,多次最大池化操作在不同尺度上保留响应最强烈的特征,且利用拼接特征提取器的输出与改进的SPP单元的输出保留卷积层提取的特征,再经过1个3×3卷积层的处理后,输入第一尺度检测器的1×1卷积层,实现在尺寸为13×13的特征图上的检测操作。
相对于传统的SPP,改进的SPP单元将输入的特征图与池化后的特征图进行通道合并,使得更多的特征被捕获,提高了大目标及一般目标的识别精度。其中较小尺度的池化,用于提取远距离小目标的代表性特征。
网络的第二个尺度对改进的SPP单元输出与骨干网络输出拼接得到的特征图进行上采样,输出特征图大小为26×26。与YOLOv3模型不同,YOLOv3_DB_SPP模型中密连块层数较多,如果仍然将上采样得到的26×26的特征图与DenseBlock4输出的特征图进行拼接操作,输出的通道数将会变得很大,而在此处进行1×1降维又有可能会丢失部分特征,故在第二尺度采用第四个下采样层大小为26×26的输出与其进行拼接。再经过Convolutional Set和3×3卷积后输入1×1卷积层,完成第二次检测。最后一个尺度重复第二个尺度的操作,将第三个下采样层的输出与第二尺度拼接后特征的上采样特征进行拼接,经过一系列1×1和3×3卷积后在最后一个1×1卷积上完成预测。
3 试验数据集
试验中网络模型的输入为416像素×416像素的RGB彩色生猪图像,原数据集2 128张,经过水平翻转,随机裁剪,镜像翻转以及随机移位产生 8 512 张样本,训练集和测试集样本数比例约为9∶1。
试验采用的猪脸数据集包含的10个生猪个体分别编号为pig1,pig2,…,pig10。使用labelImg手动标框并赋标签名,界面见图8。labelImg生成的XML文件包含了样本图像的尺寸以及样本框左上角和右下角的坐标等信息。
4 试验方法
本试验采用的操作系统为Ubuntu18.04.3,CPU为Intel i5 9400F 2.9 GHz,内存64 G,GPU为NVIDIA GEFORCE RTX 2080Ti,显存32 G;深度学习框架为Tensorflow,版本号1.13.0。
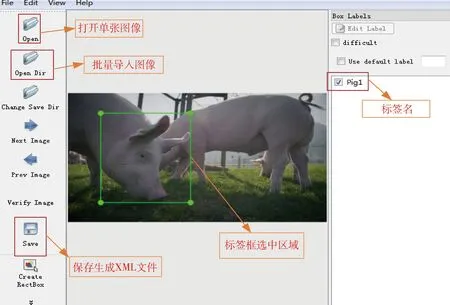
图8 生猪数据集的打标签界面
试验分为3个阶段,分别训练15、25、40个epoch,batch尺寸为32,设置最大学习率lrmax和最小学习率lrmin,迭代步数指迭代的batch数目。由于网络训练初期可能出现loss值为NaN的情况,为了避免该问题,第一阶段的学习率设置为当前迭代步数与第一阶段总迭代步数的比值与lrmax的乘积,该阶段用于稳定训练,学习率逐渐增大至lrmax。第一阶段与第二阶段均冻结除去检测器外所有层的参数,利用模型在PASCAL VOC2007数据集上训练得到的参数作为初始参数,仅训练检测器层,最终学习率为lrmax与lrmin的中值。最后一阶段进行全网训练,最终学习率为lrmin。
由于改进的YOLOv3_DB_SPP模型与YOLOv3模型在卷积层层数,参数数目等方面均有区别,因此在训练时本试验根据模型收敛实际情况使用了2组参数。针对YOLOv3和YOLOv3_DB模型,lrmax和lrmin分别设置为10-4和10-6,针对YOLOv3_DB_SPP模型,lrmax和lrmin分别设置为10-5和10-7。
网络模型的损失函数分为3个部分,目标类别的损失Lcls以及置信度损失Lconf使用二值交叉熵函数,定位损失Lloc采用预测偏移量与真实偏移量之间差的平方和作为损失函数,三者之和为最终损失total_loss,具体如下:

(3)

(4)
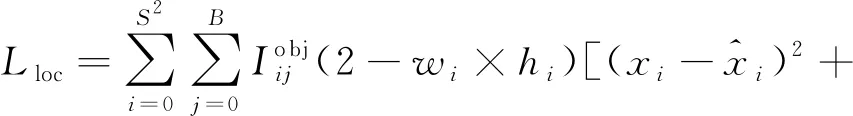
(5)
total_loss=Lclass+Lconf+Lloc
(6)
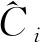
5 结果与分析
在迭代20 315个迭代步数后,3个模型的总损失值均收敛到0.15附近(图9),三者训练时间均为3.0~3.5 h。
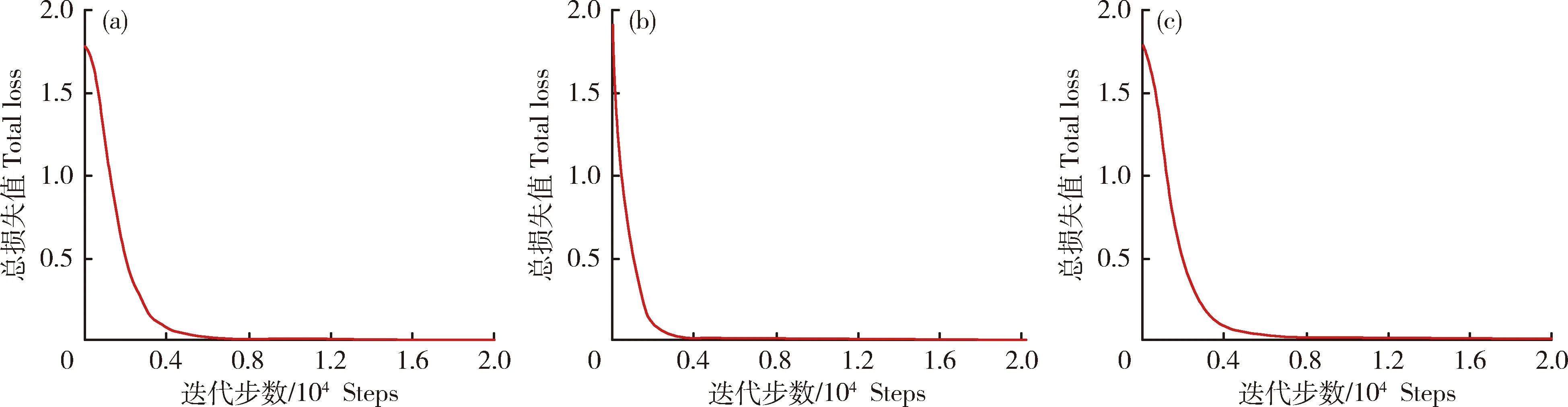
图9 YOLOv3 (a)、YOLOv3_DB (b)以及YOLOv3_DB_SPP (c)的总损失值曲线
表1示出当IOU阈值为0.5,分类概率阈值T=0.1时3种模型对猪脸数据集的检测结果,包括平均精度均值(Mean average precision,mAP)与平均精度值(Average precision,AP)。其中YOLOv3_DB模型表示未加改进的SPP单元的检测器。可以看出,YOLOv3_DB模型与YOLOv3_DB_SPP模型的mAP值均高于YOLOv3模型,且后者较前者有显著提升,说明本研究提出的方法对提高检测准确率有明显作用。YOLOv3_DB方法在前7类样本上的AP值虽然有所提升,但对于pig8,pig9,pig10这种多只圈养的生猪样本,检测结果并不够好,而YOLOv3_DB_SPP模型不仅前7类样本的检测效果优于前2种模型,且对多只圈养的样本仍有较高检测结果,说明改进的SPP单元对于检测距离较远,遮挡较多的小目标物体有所助益。

表1 T=0.1时3种模型对猪脸数据集的检测结果
为了进一步说明模型的性能,表2示出不同分类概率阈值下3种模型检测猪脸数据集时的mAP值以及检测速度,此时IOU阈值仍为0.5。可以看出随着分类概率阈值的不断提升,YOLOv3模型的mAP下降十分明显,而改进的2版模型结果受影响相对较小,结果表明YOLOv3模型的检测结果普遍是低概率的,一旦阈值提升,低概率结果被剔除,mAP也就随之下降;且对这10类样本进行目标检测时,改进的网络模型检测每种生猪个体时的mAP相较于YOLOv3模型均有不同幅度的提升,但YOLOv3_DB模型与YOLOv3_DB_SPP模型的检测速度要次于YOLOv3模型。

表2 不同阈值T下3种模型检测猪脸数据集时的平均精度均值及速度
图10示出YOLOv3,YOLOv3_DB和YOLOv3_DB_SPP这3种模型对多只圈养样本的检测结果。可以看出,相对于YOLOv3模型,YOLOv3_DB模型能够很好检测出右下角有阴影遮挡的生猪;YOLOv3_DB_SPP相对于YOLOv3和YOLOv3_DB模型,实现了对角落里遮挡较多的小样本的检测。
图11示出YOLOv3,YOLOv3_DB和YOLOv3_DB_SPP这3种模型检测多只圈养样本时产生的预测边界框。可见,YOLOv3_DB模型相对于YOLOv3模型,预测边界框框出的检测目标更加完整;YOLOv3_DB_SPP模型相较于前2种模型能够实现对较远距离下遮挡较多的小目标的检测,但对小样本边界框的定位不够精确。

图10 YOLOv3 (a)、YOLOv3_DB (b)以及YOLOv3_DB_SPP (c) 3种模型对猪脸图像的检测结果

图11 YOLOv3 (a)、YOLOv3_DB (b)以及YOLOv3_DB_SPP (c) 3种模型检测猪脸图像时的预测边界框
6 结 论
本研究将DenseBlock引入YOLOv3模型的特征提取器Darknet53得到检测模型YOLOv3_DB,并将其与改进的SPP单元结合,提出一种新的检测模型YOLOv3_DB_SPP,应用到生猪识别中。当IOU阈值为0.5,分类概率阈值为0.1时,YOLOv3_DB模型检测猪脸数据集时的平均精度均值为82.76%,检测速度60帧/s,与YOLOv3模型相比,其平均精度均值高出2.76%,速度仅相差5帧/s;YOLOv3_DB_SPP模型检测猪脸数据集时的平均精度均值为90.18%,检测速度56帧/s,相较于YOLOv3模型,其平均精度均值高9.87%,速度慢9帧/s。试验表明本研究提出的YOLOv3_DB_SPP模型在检测速度损失不大的情况下,提高了检测精度并实现了对远距离有遮挡小目标的检测,但预测边界框的定位精度仍有待提高。
猜你喜欢
今日畜牧兽医(2022年10期)2022-12-23
今日农业(2021年19期)2021-11-27
北京航空航天大学学报(2021年9期)2021-11-02
今日农业(2019年14期)2019-09-18
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
农家之友(2018年12期)2018-03-12
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
