
基于DTW算法的电力调度语音识别研究和应用
2021-03-25 04:18王素宁朱俊杰李志勇黄宇星田朝阳陈凯锋
电力与能源 2021年1期
王素宁,朱俊杰,李志勇,黄宇星,李 琪,田朝阳,陈凯锋
(1.国网上海市电力公司崇明供电公司,上海 202150;2.东方电子股份有限公司,山东 烟台 370602)
调度自动化作为智能电网系统重要的一部分,在人工智能方向的应用有大数据、云计算、调控云等[1-5]。但是在调度控制系统方面还是采用键盘加鼠标的传统交互方式,因此研究新形式的人机语音交互方式很有必要[6]。人机语音交互技术在其他领域应用已经比较成熟,因此把其应用到电网调度运行中具有可行性[7-8]。人机语音交互首要需要解决的问题就是语音识别技术,电力调度具有很强的专业术语和特殊符号等,同时每个调度员有自己的说话口音、语序和方式,在相对嘈杂的环境中如何有效地识别出调度人员的声音并准确完成相对应的指令操作尤为重要[9-10]。
语音识别可分为孤立词识别、连接词识别和连续语音识别等[11]。针对语音识别最主要的方法有动态时间规整 (Dynamic Time Warping,简称DTW)算法、隐马尔可夫模型(Hidden Markov Model,简称HMM)、神经网络,深度学习等[12-15]。本文将采用改进的DTW与GMM-HMM算法相结合完成语音地精准识别。
1 语音识别系统原理和步骤
1.1 语音识别基本框架
一个语音识别系统框架主要包括:声学分析(Signal Analysis)、声学模型(Acoustic Model)、词典(Lexicon)、语言模型(Language Model)、搜索/解码(Search/Decoding),具体如图1所示。

图1 语音识别系统框架
(1)声学分析,也称特征提取,用于提取有用信息,将一段语音帧解析为一个固定维数的特征向量。常用方法有梅尔频率倒谱系数(Mel-frequency cepstral Coefficient,简称MFCC)和感知线性预测系数(Perceptual Linear Prediction,简称PLP)。
(2)声学模型:解析声学信号,比如将特征向量解析到一个特征的建模单元上,并获得相应的得分,常用算法有动态时间规整 (Dynamic Time Warping,简称DTW)、人工神经网络-隐马尔可夫模型(Artificial Neural Network-Hidden Markov Model,简称ANN-HMM)、深度神经网络-隐马尔可夫模型(Deep Neural Network-Hidden Markov Model,简称DNN-HMM)等。
(3)词典:给单词和发音提供HMM模型(亚词)和语言模型间关联。通常基于音素,由专家手工完成。
(4)语言模型:提供这部分的先验概率,可以区分相同发音时的识别结果。
(5)搜索/解码:根据状态系列,在时间状态序列(Time-state Trellis)中找到一个最优路径,或者说根据声学模型输出的结果,结合辞典、语言模型信息,找出最有可能的识别结果。
1.2 语音识别流程
语音识别原理:①首先对声音进行预处理(预加重、分帧、加窗和端点检测);② 再根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的MFCC 特征参数和基音周期,在此基础上建立语音识别所需的模板[16-17]。计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入语音信号的特征进行比较,根据一定的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板。然后根据此模板的定义,通过查表就可以给出计算机的识别结果。具体流程如图2所示。

图2 语音识别流程图
图2的左半部分可作为前端,用于处理音频流,从而分隔可能发声的声音片段,并将它们转换成一系列数值。声学模型就是识别这些数值,给出识别结果。图2的右半边作为后端,是一个专用的搜索引擎,它获取前端产生的输出,在一个发音模型、一个语言模型、一个词典这三个数据库进行搜索[18-20]。显然,计算机查表取得最优的结果与特征的选择、语音模型的好坏、模板是否准确都有直接的关系。
2 改进的DTW算法
2.1 DTW算法原理
同一个人在不同时间段对相同组词发音都可能存在差异。这种差异导致音强的大小、频谱的偏移和音节长短每次都不完全相同[21]。DTW算法用于比较两个序列的相似程度,或者说两个序列的距离。基于动态规划构建序列和序列的距离矩阵,具体公式如下:
dp(i)[j]=
(1)

DTW算法最后的输出结果就是要找到一条累积距离最小的扭曲曲线,也就是损失矩阵的最后一行最后一列的值,即给定了距离矩阵,如何找到一条从左上角到右下角的路径,使得路径经过的元素值之和最小。最优路径示意图见图3。
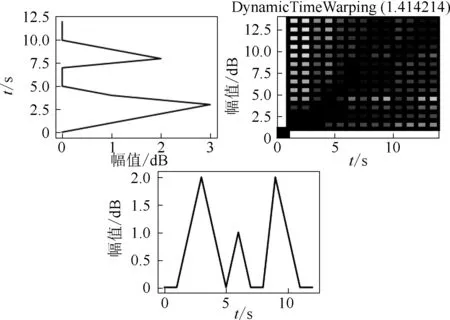
图3 最优路径示意图
2.2 GMM-HMM算法原理
GMM-Model算法是基于高斯分布,主要通过加权的方式组合得到。隐马尔可夫模型(HMM)由Markov(状态转移序列) 链和每次状态转移时转移状态和记录的时间之间组成的信号和状态序列两个随机过程组成[21]。HMM 模型在数学模型上的符号描述为λ=(π,A,B),如图4所示。

图4 HMM示意图
在语音识别系统中,根据采集到的语音信号通过相应的算法去建立相对应的高斯混合模型,结合GMM算法拟合说话者的语音产生。
(2)
式中xi——D维语音特征矢量;pi(xi)——GMM模型片段概率;ai——相应片段概率pi(xi)的权重;M——GMM算法中的片段数目。
2.3 DTW算法的优化
在语音识别中使用DTW算法进行语音相似度比较,将实时语音指令与指令语音样本序列号成向量进行相似度比较,选取相似度最大的指令语音样本所对应的指令来判断是否是实时语音所输入的指令。通过相似度比较,简单判断可以取最近距离的结果来进行判断,但为了提高准确率,需要进一步对算法进行优化。
2.3.1 对语音分片和分组
本次研究的输入指令格式是固定的,每个指令有多少“3U0图”、“电网精灵”、“通道监视图”等。每个指令的元音辅音个数是确定的,即语音包络的峰谷个数也是确定的,因此在进行语音DTW计算时不是与所有样本匹配,同时由于发音会有长短变化,所以也不能只用时长、峰谷个数来限定匹配范围,对于“图”、“站”是指令中经常出现的语音单元,通过对包络切片,识别最后一个包络如图5和图6所示。

图5 “图”波形

图6 “站”波形
2.3.2 路径权重优化
根据式(1)计算出“测试指令”与“指令1”和“指令2”的距离,如图7和图8所示。

图7 测试指令和指令1的距离

图8 测试指令和指令2的距离
从图7和图8可以看出,“测试指令”与“指令1”相似。“测试指令”与“指令1”和“指令2”的距离分别是dq1和dq2。其中,dq1=1.802 776;dq2=1.723 369。dq2更小,这个结果与实际不符合。因此,对路径计算引入权重,设权重系数为α。这个α和原算法的距离dp相乘,得到更新后的dp*。基于原算法距离,可以求出dp[i][j],改进后dp[i][j]*,的公式如下:
(3)
式中mseqLen——图中最优路径节点个数;mcomLen——每段直线路径对角线个数。
改进后:dq1=0.725 113;dq2=0.861 68。改进后“测试指令”和“指令1”距离更小,更符合匹配结果。
2.3.3 路径搜索范围优化
同样的语音指令在稳定状态有时间长短、振幅差异,总体包络形态相似。因此,在进行DTW计算之前先将峰谷单元进行归一化。即每个峰谷都归一化成时间长短0.5 s,振幅正负1的归一化单元波形。DTW计算搜索的范围不对所有点进行搜索,集中偏移和对角线邻居范围搜索。
2.4 频谱优化及应用
频谱反应了说话人声音器官发音的频率范围,高频率会在波形中产生更紧密的周期性能量叠加。同时固定的背景噪声也有固定的频谱,因此在以下方面进行优化。
通过语音波形计算出语谱,然后进行二阶高斯模糊函数处理,降低高频谱分量的权重,调整高斯函数的μ(x的均值),σ(x的方差)来适应不同语音速度的模糊处理。例如语音指令,其波形、语谱,高斯模糊处理后的语谱经过图像压缩后得到语谱hash,如图9和图10所示。通过处理后可减少DTW向量匹配个数,“地理图”可加快匹配速度。
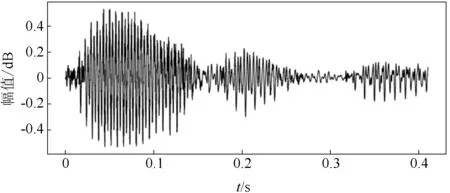
图9 “地理图”波形
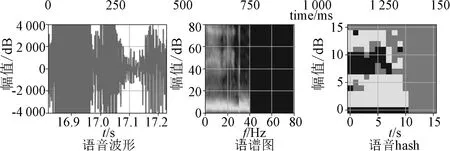
图10 语音波形、语谱和hash图
3 结语
本文提出了一种基于改进的DTW在电力调度中应用的语音识别方法,通过试验表明该方法在电力调度语音识别中更具有优良性。通过在上海崇明电网主配网站一体化的DF8003系统上应用,减少了调控人员的操作,提高了崇明地调人员的工作效率,可以在上海甚至全国电网调度推广。由于本次制作的电力调度语音库词汇有限,针对更复杂的语音库需要进一步进行研究。
猜你喜欢
家庭影院技术(2020年6期)2020-07-27
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
测控技术(2018年5期)2018-12-09
测控技术(2018年2期)2018-12-09
雷达学报(2018年5期)2018-12-05
家庭影院技术(2018年10期)2018-11-02
电信科学(2016年10期)2016-11-23
通信电源技术(2016年3期)2016-03-26
焊接(2016年5期)2016-02-27
