
基于机器学习评估光纤链路传输质量
2021-03-26 03:30王家馨侯韶华
电子元器件与信息技术 2021年11期
王家馨,侯韶华
(南京邮电大学,江苏 南京 210023)
0 引言
近年来,相干光传输技术取得较大进展,通过对相互关联参数(比如,调制格式,码元速率等)的微调,使得大量的光纤链路可行方案成为可能。在具体的链路规划部署之前,评估光纤链路的传输质量是极其重要的一步[1]。
传统的光路传输质量评估使用复杂分析模型和近似公式[2]。前者能够非常精确地评估光路的传输质量,但其计算量很大,不能得到推广。后者因为计算速度快,模型简单,被广泛采用,但引入了较多链路冗余,造成资源浪费[3]。
机器学习凭借能够解决耗时复杂的非线性分类或回归问题,广泛应用于光网络和光通信的各个方面[4]。机器学习利用已经部署光路的历史测量数据评估光路的传输质量,避免了之前两种传统方法的缺点,能得到传输质量高精度评估结果[1,5]。目前,许多评估光路传输质量的方法基于二分类器,如随机森林(RF),K近邻(KNN),支持向量机(SVM)三种分类器对光路传输质量进行二分类,SVM获得最高0.9915分类准确度[6];KNN,SVM,人工神经网络(ANN),逻辑回归算法(LR)分类器对光路的剩余冗余进行二分类,通过比较准确率,F1分数,得到ANN是获得最佳泛化能力的模型,两个指标分数均达到0.99以上[7]。除了经典的机器学习算法,在机器学习中,集成学习也是研究的热点。集成学习利用一定的规则组合不同的学习器构建具有很强的鲁棒性和泛化能力的集成模型,具备高精度评估光路传输质量的潜力。本文提出基于不同集成学习算法的三分类器。
1 系统设置和数据集生成
1.1 系统模型设置
在网络线性拓扑中,假设相邻节点间是9个信道,信道间隔为50GHz,符号速率为32GBaud,噪声带宽为32GHz的偏振复用相干未补偿系统[6]。系统采用标准单模光纤(光纤损耗系数0.22dB/km,非线性系数1.3 1/w*km,色散系数21ps^2/km),构成等跨度的透明传输的同质链路[8],掺铒光纤放大器(EDFA)完全弥补上一个跨度的损耗,噪声指数为5dB,节点由具有波长选择开关(WSS)技术的可重构光分插复用器构成。
1.2 数据集生成
由于缺乏真实的网络监测历史数据,本文使用文献[6]中传输质量评估工具和上述系统模型生成数据。此传输质量评估工具是根据加性高斯白噪声模型,将光路中总的非线性光信噪比(OSNR)作为关于信道发射功率(PTx)和线性噪声(PASE),非线性(PNLI)贡献的函数,误码率(BER)作为关于Eb/N0(每比特的能量与噪声功率谱密度之比)和调制格式的函数[9]。

(2)式中,a和d通过误码率与调制格式的关系计算[9]得出,Eb/N0 通过文献[6]中公式得出。
生成数据集所需的链路系统参数[2]如表1所示:
数据集特征选择链路长度,跨度长度,调制格式,数据速率,信道发射功率。数据集标签为BER。
基于MATLAB2020a平台,利用传输质量评估工具生成数据集。根据ITU-TG.975.1建议的前向纠错标准,preBER 阈值为4*10^(–3)。本文将BER 分为小于4*10^(–5),大于4*10^(–5)且小于4*10^(–3),大于4*10^(–3),分别对应传输质量优良,合格,不合格。通过对数据集中样本类别数量适当均衡,得到32991个样本,其中8722个小于4*10^(–5)的样本,4391个大于4*10^(–5)且小于4*10^(–3)的样本,19878 个大于4*10^(–3)的样本。
2 机器学习分类器
2.1 分类器分类过程
将数据集中BER小于4*10^(–5)的样本标签设为0,大于4*10^(–5)且小于4*10^(–3)的样本标签设为1,大于4*10^(–3)的样本标签设为2。分类器的分类过程如下。首先将数据集按比例8∶2随机分成训练集和测试集,然后标准化训练集特征,接着将标准化后的训练集输入分类器,分类器利用训练集进行超参数网格搜索,最后测试集输入具有最好超参数的分类器,得到预测值。
2.2 机器学习算法
机器学习算法中,集成学习拥有重要的地位,选取六个经典集成学习算法。
2.2.1 集成学习算法[10]
a.投票分类器(Voting Classifier)
硬投票法:聚合不同分类器的预测,然后票数最多的结果作为预测类别。一般,投票分类器的准确率高于集成中最好的分类器。
软投票法:如果每个分类器能够估算出类别的概率,然后计算出平均概率,那么平均概率高的作为预测。
软投票通常比硬投票获得更高的精度,因此本文采用软投票法。
b.随机森林(RandomForest)
随机森林是决策树的集成,实现分类和回归。在随机森林中,许多决策树同时被训练,但是每棵树只接受一个样本,并且每个节点在确定最佳分裂时只考虑全部特征的一个子集。随机森林通过投票决定样本的预测分类。
c.极端随机树(Extra Trees)
极端随机树是由极端随机的决策树组成,由于每个特征都使用随机阈值,所以,生成出的决策树得更加随机。极端随机树与随机森林的性能需要通过交叉验证甚至网格搜索超参数才能进行比较。
d.自适应增强(AdaBoost)
AdaBoost:循环训练分类器,每一次都对前一次分类器评估的欠拟合训练示例进行关注,实例权重不断更新,使新的分类器越来越专注于难缠的问题。
本文AdaBoost集成的分类器为单层决策树。
e.梯度提升(GradientBoosting)
梯度上升与AdaBoost一样,逐步在集成中添加预测器,但不同的是,它是让新分类器对前一个分类器的预测值与实际值的差值进行拟合。本文梯度上升分类器使用的基础分类器为决策树。
f.极端梯度上升(XGBoost)
XGBoost是梯度提升的优化实现,速度快,可移植与可扩展。
2.3 分类指标
多分类指标分为两种:
(1)多分类转化成二分类的评估
a.准确率(Accuracy),b.宏平均F1,微平均F1,加权平均F1。(Macro F1,Micro F1,Weighted F1)
(2)直接定义的多分类指标
a.Kappa系数,b.海明距离,c.杰卡德相似系数(jaccrd_similarity_score):根据平均方式分为jaccrd_macro, jaccrd_micro, jaccrd_weighted。
3 仿真过程和结果分析
3.1 算法模型
基于Sklearn机器学习python应用程序接口实现算法调优和训练,测试,评估。6种集成学习算法进行超参数调优后,得到的模型为:
a.Gamma为0.2,C为2000的高斯核SVM,C为200,penalty为l2的逻辑回归,500个估计器的随机森林集成的投票分类器;
b.500个估计器,最大深度为20的随机森林分类器;
c.500个估计器,最大深度为20的极端树分类器;
d.1500个估计器,学习率为1的AdaBoost分类器;
e.500个估计器,学习率为0.01,最大深度为10的梯度上升分类器;
f.91个估计器,学习率为0.01,最大深度为20,subsample为1,gamma为0.001,min_child_weight为0.01的XGBoost分类器。
3.2 仿真结果
3.2.1 集成算法性能比较
图1和图2是6种分类器关于性能指标的对比图。由图1可知所有分类器性能分数都在0.89以上,其中投票分类器的所有性能指标分数都高于其他分类器,都在0.97以上。投票分类器集成的分类器都是超参数最优的分类器,SVM和KNN经过超参数调优,性能指标分数都在0.94以上,由于逻辑回归的性能指标分数低于SVM和KNN很多,最高只有0.90,因此导致投票分类器总体性能稍逊于SVM。实验表明,只有当投票分类器中的性能指标分数均衡,投票分类器才能性能指标分数高于集成中所有分类器。
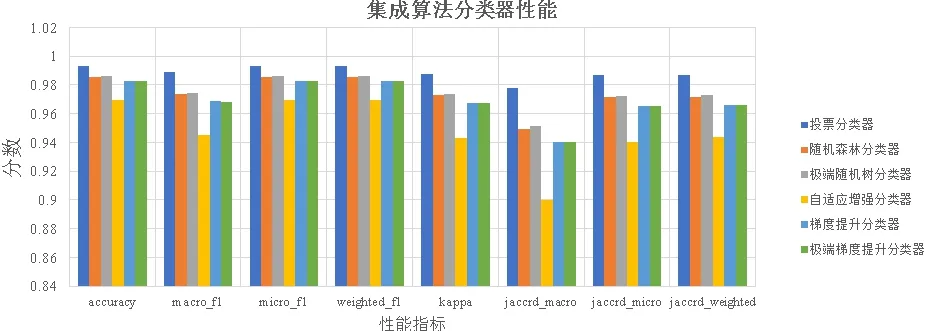
图1 集成算法分类器性能比较
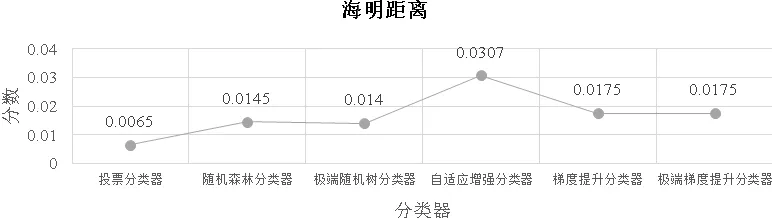
图2 算法分类器海明距离比较
极端树分类器与随机森林分类器各指标柱状高度相近,极端树分类器各指标分数稍微高于随机森林分类器。极端树分类器性能指标分数在0.95以上,随机森林分类器在0.94以上。梯度提升分类器与XGBoost分类器各性能指标分数一样,最低为0.94。AdaBoost分类器各性能指标分数均低于其他分类器。
图2海明距离指标与图1指标相反,海明距离指标分数越接近0,性能越好,越接近于1,性能越差。图2中分数投票分类器最低,非常接近于0;随机森林分类器与极端树分类器分数很接近,在0.014附近;梯度提升分类器与XGBoost分类器分数为0.175;AdaBoost分类器分数最高,高于投票分类器0.02差值。
分类器性能除了比较性能指标系数,还需要比较训练,测试时间。
图3是关于分类器的训练时间与预测时间的比较。从图可见,梯度上升分类器的训练时间最长,随机森林分类器的训练时间最短。在具有相同的性能指标情况下,XGBoost分类器的训练时间比梯度上升分类器短约95秒,测试时间短约5秒,表明XGBoost分类器是对梯度上升分类器的提升优化。六种分类器的预测时间最短为XGBoost 0.062秒,最长为AdaBoost 0.81秒。
结合图1,图2,图3,投票分类器分类性能指标分数最优,训练时间中等,预测时间偏短;极端树分类器与随机森林分类器分类性能指标分数次优,训练时间最短,预测时间较短;梯度上升分类器与XGBoost分类器性能指标分数相同,但XGBoost分类器训练和预测速度更快;AdaBoost分类器分类性能指标分数最低,训练和预测时间都较长。

图3 集成学习分类器训练与预测时间比较
综上可知,在光纤链路传输质量多分类评估时,6种集成学习算法中可取的是投票分类器,随机森林分类器与极端树分类器,三种分类器都能得到高性能。
4 结语
本文提出评估链路传输质量的6种经典集成学习算法三分类器并分析两种类型的多分类指标。通过生成综合数据来训练分类器,利用多分类指标评估分类器。实验表明,6种基于集成学习算法的三分类器的性能指标分数都能达到0.89以上,汉明距离低于0.03。其中投票分类器,随机森林分类器,极端树分类器在计算时间和分类性能达到很好的平衡。结果证明,基于集成学习算法的三分类器能够很好地评估光纤链路传输质量,与二分类器相比较,三分类器对传输质量进一步分类评估,满足现实传输所需的链路传输质量要求。
猜你喜欢
移动通信(2021年5期)2021-10-25
石油沥青(2021年1期)2021-04-13
空间科学学报(2020年3期)2020-07-24
空间科学学报(2020年4期)2020-04-22
计算机应用(2017年4期)2017-06-27
考试周刊(2017年7期)2017-02-06
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
制冷技术(2016年4期)2016-08-21
中国交通信息化(2014年3期)2014-06-05
