
一种基于模拟退火的动态发射型CGRA编译方法
2021-05-28 12:37杨伟东
现代计算机 2021年10期
杨伟东
(上海交通大学电子信息与电气工程学院,上海200240)
0 引言
可重构架构因为其相较于ASIC的灵活性和相较于CPU的高能效比,在Dennard缩放定律逐渐失效的现在[1],获得了学术界和工业界的广泛关注[2-6]。相比于FPGA(Field Programmable Gate Array),粗粒度可重构架 构(Coarse-Grained Reconfigurable Architectures,CGRA)因为其粗粒度的重构粒度,降低了重构代价,带来更高的能效比。
传统的CGRA属于静态放置静态发射(Static Issue,Static Placement,SISP)型CGRA[7-8],该类型的CGRA一般由指令进行驱动,需要编译器显式指明每条指令的执行时间和对应的处理单元,给编译器开发带来了较多约束,例如:计算资源的约束、存储资源的约束、互连约束,等等。这些约束可能导致编译器用调度效率来交换调度正确性,将优化压力集中到编译器上,给编译器开发带来了严峻的挑战。而且,如果CGRA内部存在同步机制,每个处理单元(Processing Element,PE)需要等待执行时间最久的PE的任务完成,使得其他处理单元处于闲置状态,从而导致CGRA性能降低。
针对以上问题,Zhao在文献[9]提出一种静态放置动态发射(Static-Placement,Dynamic-Issue,SPDI)型CGRA,通过硬件机制减少编译器在时间域上的约束,对编译器的开发更加友好,同时通过算子的动态执行来减小同步机制带来的性能损失。
本文面向以上SPDI型CGRA开展编译技术研究,充分发挥其硬件性能。
1 SPDI型CGRA架构
SPDI型CGRA主要加速程序中计算密集型循环。该类型CGRA不需要配置信息显式指明算子的执行时间,其内部的Token Buffer机制可以根据算子的输入操作数是否就绪以及CGRA内部的资源情况动态地决定算子的发射时间,该类型的CGRA架构如图1所示。
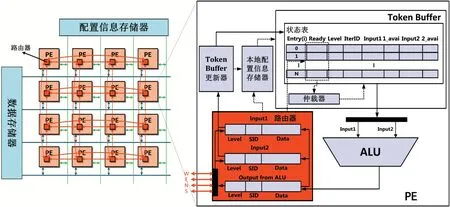
图1 SPDI型CGRA架构[9]
2 问题定义
CGRA的编译是将需要加速的代码编译成CGRA配置信息的过程,该过程不仅要保证结果的正确性,还要进行调度空间探索,寻求性能最优的调度(又称映射)方案。完整的编译流程如图2所示。
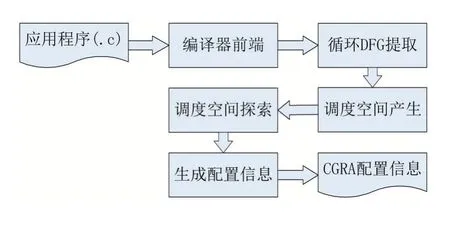
图2 完整的编译流程
调度空间探索主要研究循环映射技术,探索如何更充分地利用硬件的计算资源。SISP型CGRA循环映射方法主要借鉴软件流水[10]的思想,通过模调度算法[11]充分利用硬件资源。基于模调度的编译技术[12-16]主要研究如何在更小的迭代间隔(Initiation Interval,II)下完成数据流图(Data Flow Graph,DFG)的映射,一旦映射完成,II就是对其性能的表达(不考虑访存冲突)。
SPDI型CGRA由于其更为宽松的约束机制,更有利于编译器进行DFG的映射,更容易产生调度方案。但是由于其缺乏对性能的有效监督,导致不同调度方案会有着不同的性能,图3展示了一些应用在不同的调度方案下性能的差距。
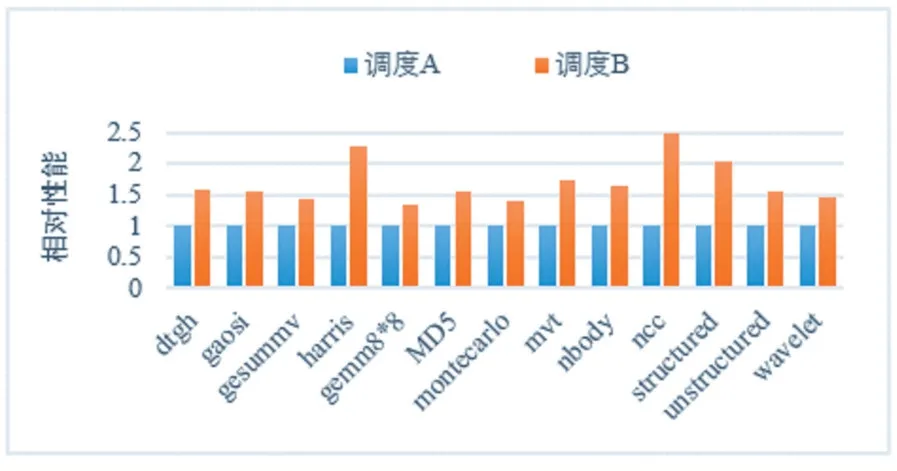
图3 不同调度方案的性能对比
基于以上分析,和SISP的编译技术解决的问题不同,SPDI型CGRA的编译技术的重点和难点在于如何去进行调度空间的探索,如何从大量的调度方案中选择正确且最优的一种调度方案。
本文设计的面向SPDI型CGRA的编译器前端主要用来提取源代码中的循环部分,这部分代码会被标记,以供编译器识别用于CGRA加速。这部分代码在转化成IR后会被编译器提取出DFG,以DFG的形式作为源代码和CGRA的媒介。DFG中的每个节点对应CGRA中每个PE所执行的一个运算,DFG中的边(表示节点间的依赖性)对应CGRA中的互连部分,由此引出了面向CGRA的有效映射的定义,如定义1所示:
定义1(有效映射):给定一个DFG D=(VD,ED),以及一个PE阵列G=(VG,EG),其中VD表示DFG中的节点集合,ED表示DFG中的边的集合,VG表示PE集合,EG表示PE间支持的互连方式的集合,f(u)表示节点u映射的目标PE,f(l)表示DFG的边l映射的互连方式。因此,一个有效映射D->G需满足以下要求:

满足定义1的映射,即为面向SPDI型CGRA的有效映射,可以将该映射转换成CGRA的配置信息,从而使用CGRA来对应用进行加速。SPDI型CGRA由于缺少了时间轴上的约束,带来了比传统SISP型CGRA更为宽松的互连映射条件。
调度的高效性问题体现在不同的调度方案会产生不同的性能,需要选择其中最优的方案。这是一个典型的组合优化问题,即从有限个可行解的集合中找出最优解的过程,其数学表示如式(3)所示。

式中D表示所有满足定义1的调度映射的集合即可行解的结合,f(x)表示当前调度映射方案x下硬件的执行时间。面向SPDI型CGRA的编译器后端的主要工作就是解决上述这个组合优化问题。
3 问题求解
基于第2节中定义的问题,基于SPDI型CGRA的编译主要关注以下两个问题:
(1)确定可行解的集合,即调度空间的产生;
(2)从可行解的集合中寻找最优解,即调度空间的探索。由于可行解集合的规模随着DFG和PE规模的扩大而迅速增长,无法通过穷举来找出最优解。
3.1 调度空间产生
调度空间的产生要求正确且尽可能全面地覆盖所有可能的调度方案,从而更好地进行调度空间的探索。另外,由于调度空间产生和探索属于编译器的一部分,从利于程序员编程的角度考虑,需要自动化地产生调度空间,尽量少地需要人为干预。
进行调度空间探索要求迅速产生调度方案,基于以上考虑,采用文献[16]中的前向贪婪和反向回溯的方法来作为本文中产生调度方案的算法。将调度方案的产生分为两个子问题:算子的排序以及算子的放置。
对于前者,可以采用广度优先搜索(Breadth First Search,BFS)和深度优先搜索(Depth First Search,DFS)来对DFG进行遍历,从而得到一个一维的算子序列。在算子放置的过程中,可以采用贪婪算法,按照算子序列的顺序进行放置,在放置过程中要考虑互连约束,如果出现违背定义1约束的情况,则进行回溯,直到满足定义的1要求为止。同时,在算子放置的过程中,加入一个启发式策略:每个处理单元所执行的算子数目尽量均衡,这样一般会比不均衡的情况的性能更高。通过这样的方式,可以迅速得到定义1约束的调度映射。但是贪婪算法容易陷入局部最优解,无法得到全局最优解,所以只通过此方式来得到可行解,寻找最优解的过程依赖于后续其他的算法。
上述算法可以正确地产生一个可行解,但是确定可行解的集合的问题和调度空间的探索问题有一定的耦合性,将于3.2小节中进行介绍。
3.2 调度空间探索
调度问题转化为了一个组合优化问题,可以使用模拟退火算法进行调度空间探索,该算法主要需要考虑两个问题:代价函数的制定和邻域的选择。
针对代价函数的制定有两种方案,一种是直接在仿真器上运行,另一种是对仿真器进行建模,用表达式来对仿真器的运行结果进行近似,前者结果准确但是需要耗费大量时间,后者花费时间少,但动态发射的执行模式以及编译时难以预知的访存冲突,导致建模的方案较难实现,所以本文采用直接在仿真器上运行的方案。
另一个问题是邻域的选择,该问题也可以认为是3.1小节中调度空间的产生问题。之前的研究主要采用交换算子分配的PE的方式[17]。SPDI型架构因为不涉及时间轴的约束,不用因为DFG上两个节点相邻时间不为1而添加路由操作,路由开销较小。而交换PE的方式会带来额外的路由算子开销,一定程度上抵消了SPDI型架构的优势,而且直接交换PE会产生大量的不满足定义1的非法解,不适合本文中的调度空间探索。所以本文提出通过在算子排序阶段对算子顺序进行交换的方式来进行邻域的选择,然后通过贪婪算法进行放置,以此方式来保证每次邻域交换几乎都能产生有效解。两个步骤共同作为模拟退火算法中的一次迭代(算法1中的NeighborTran函数和ScheduleGen函数),以此来进行调度空间的探索。
同时,在执行模拟退火算法的过程中,记录曾经出现过的最优解。最终的算法如下所示。
算法1:基于模拟退火的调度空间探索
输入:经过编译器前端得到的中间表示IR
输出:寻优后的调度方案及其性能


4 实验结果与分析
4.1 实验方法
本文基于LLVM8.0.0实现了面向SPDI型CGRA的编译器,可以将C语言编写的应用程序转化成SPDI型CGRA的配置信息,并通过C++编写的SPDI型CGRA架构仿真器评估本文提出的编译算法的效果。
表1展示了实验所采取的CGRA的硬件参数,其中Torus的互连方式如图1中红色线条所示。
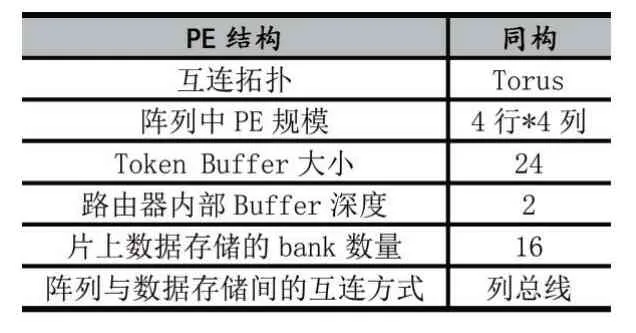
表1 CGRA硬件参数配置
benchmark选用来自EEMBC、MediaBench、Mach-Suit和Polybench等的循环核心。
本文将当前执行时间与理论最优执行时间的比值作为评估编译算法性能的标准,并将文献[9]中的编译算法作为baseline,验证本文编译算法的有效性。理论最优执行时间的计算如公式(4)所示。
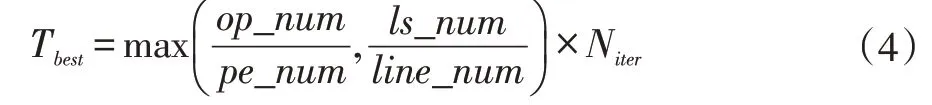
式中,Tbest表示理论最优执行时间,op_num表示应用中算子数量,pe_num表示阵列中PE的数目,ls_num表示应用中访存(load和store)算子的数量,line_num表示阵列中列的数量,Niter表示循环的总迭代次数。
4.2 实验结果
图4展示了本文的编译算法下不同应用的性能和文献[9]中编译算法下相应性能的对比。其中纵坐标为当前执行时间与理论最优执行时间的比值,即纵坐标为1时,性能为理论最大值。
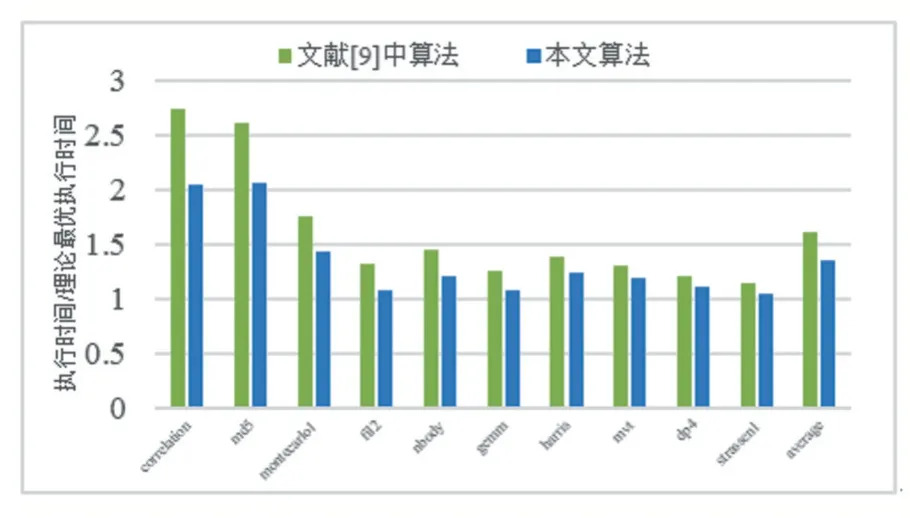
图4 不同编译算法下性能比较
统计图4结果发现,本文的编译算法相比文献[9]的算法,可获得最高33.40%,平均19.80%的性能提升,体现了本文提出的编译算法的有效性。
本算法导致性能提高的原因主要在于:
(1)更广泛的调度空间。之前的调度空间的产生有其局限性,有些应用即使完全穷举,依然无法搜索到本文算法得到的最优解。
(2)更为有效的寻优算法。
5 结语
本文针对SPDI型CGRA架构的编译问题进行分析,将问题抽象为一个组合优化问题,并通过使用模拟退火算法解决这个组合优化问题。实验结果显示,本文提出的算法比之前的算法获得了平均19.80%的性能提升。
猜你喜欢
计算机与数字工程(2022年7期)2022-08-26
南方农业·下旬(2022年4期)2022-05-24
校园英语·上旬(2020年1期)2020-05-09
卷宗(2017年16期)2017-08-30
小学阅读指南·低年级版(2017年1期)2017-03-13
国外科技新书评介(2014年12期)2015-01-05
计算机辅助工程(2012年5期)2012-11-21
祝您健康(1993年3期)1993-12-30
