
基于XGBoost算法的水质CODmn预测模型研究
2021-05-28 12:37魏福平方朝阳宗宇
现代计算机 2021年10期
魏福平,方朝阳,2,宗宇
(1.江西师范大学地理与环境学院,南昌330022;2.鄱阳湖湿地与流域教育部重点实验室,南昌330022)
0 引言
水质是人们十分关注的一个领域,水质的好坏直接影响人们的生产生活。高锰酸盐指数(Permanganate Index,CODmn)是常用来反映饮用水、水源水和地表水受有机和无机可氧化物质污染的程度的一个指标[1]。传统化学方法虽然具有精度高稳定性好的优点,然而其操作复杂耗时、易产生二次污染的缺点也不容小觑[2]。采用紫外-可见光谱技术对水样的光谱进行测定,分析其光谱特征并结合相应数学关系可以快速便捷地获取CODmn的值[3]。
本文针对国标法检测水样的水质CODmn的各种问题,基于极限梯度提升(eXtreme Gradient Boosting,XGBoost)算法,采用实际水样的紫外-可见光谱数据,构建了预测水质CODmn值的XGBoost的模型。研究表明,XGBoost算法在水质CODmn值的预测中具有模型精度较高、拟合优度好的特点。
1 方法介绍与模型构建
1.1 紫外-可见光谱法
紫外-可见光谱法是通过分析水样对入射光谱的某些波段吸收形成的光谱特征,从而得到水样中物质的组分和浓度等信息的方法,如图1所示。波长在10nm~380nm区间内的为紫外光谱,而在这个区间内又可以细分为远紫外光谱(10~200nm)和近紫外光谱(200nm~380nm)。波长在380nm~780nm区间内的为可见光谱。
1.2 极限梯度提升(XGBoost)算法
2015年,美国华盛顿大学博士陈天奇等人首次提出XGBoost算法,该算法是在梯度提升树(Gradient Boosting Decision Tree,GBDT)算法的基础上进行工程上的优化。XGBoost在原理上与GBDT算法相同,只是在工程上把GBDT的速度和效率发挥得更极致(ex-treme)。XGBoost算法与GBDT算法的主要区别在于:GBDT中梯度下降利用的是一阶泰勒公式展开,而XG-Boost采用了二阶泰勒公式展开进行梯度下降;此外,为防止出现过拟合的情况,XGBoost加入了GBDT所没有的正则项。
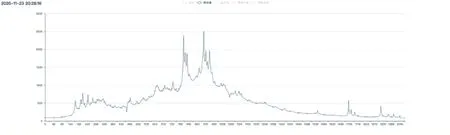
图1 水质探头反馈回来的水样光谱曲线图
XGBoost是一个树集成模型,它使用的是K(树的总数为K)个树的每棵树对样本的预测值的和作为该样本在XGBoost系统中的预测。现有一个包含了n个样本的数据集D={(x1,y1),(x2,y2),…,(xj,yj),(xn,yn)},(xj∈R,yj∈R),其中,xj为第n=j个样本的特征,yj为第n=j个样本的标签值(真实值)。XGBoost的预测过程如下:
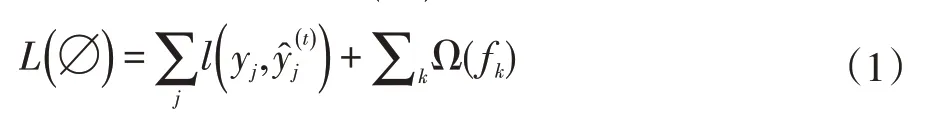

在公式(2)中,K为决策树输出叶子节点的个数,为(t-1)次的预测值,ft(xj)为当前时刻误差预测值。
经CT诊断有49例为阳性,53例为阴性,eFAST检查方式的特异性为96.23%,敏感性为89.80%,详情见表。
(2)整合目标函数L(∅):
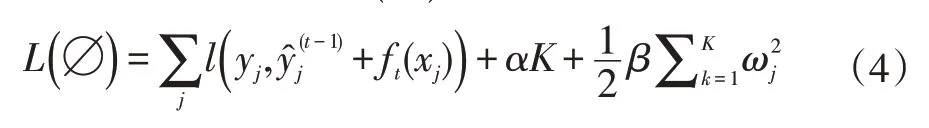
(3)对目标函数L(∅)使用二阶泰勒公式展开,得:
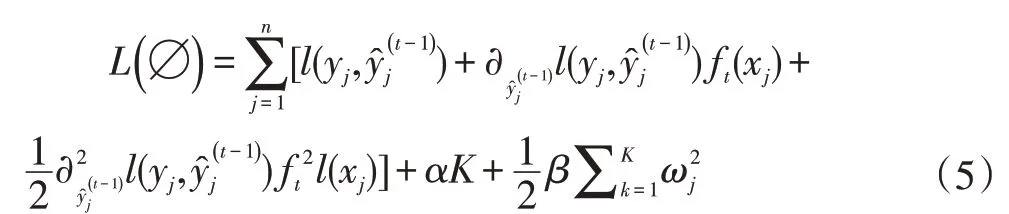

综上,公式(6)即为所求。
1.3 预测水质CODmn值的XGBoost模型构建
本文提出的XGBoost预测模型基本流程为:在获取所需数据并进行数据预处理后,对实验数据进行异常值分析与处理,剔除其中的异常值,并对数据进行归一化处理,再将数据转化为模型所需的数据。然后将模型所需数据划分为训练集、验证集和测试集三部分。将数据导入XGBoost模型,通过采用训练集训练模型、测试集测试模型的方式,多次重复模型训练与模型参数调整这一过程,最终得到较为理性的模型,并以验证集验证模型的泛化能力。
2 数据处理和评价函数选取
本文实验数据维度为29×2048。第1列至第2047列为水样的全波段吸收光谱数据,第2048列为国标法(锰法)测得的水样CODmn值(单位:mg/L)。水样吸收光谱数据采用成都益清源科技公司生产的D73-10A型水质紫外-可见光谱探头测得,该设备可发射在155nm~925nm波长范围内若干组平行光束。水样为连续三天同一时刻在两处不同的水样采集点采集的水样。实验数据如表1所示。
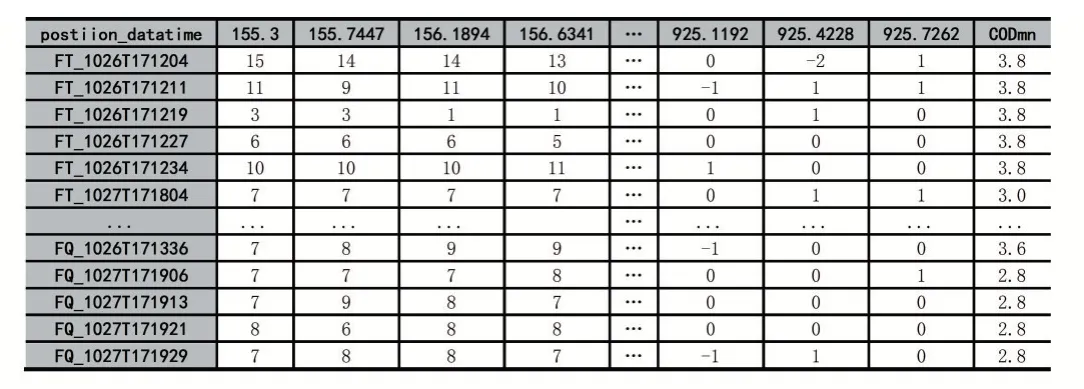
表1 水样光谱数据和CODmn实测数据
2.1 数据预处理
由于仪器中搭载的光谱探头会受到各种因素影响,导致某些波段下的吸收光谱出现了不合常理的值,为保证数据具有较好的连续性和模型具有较好的稳定性,需要对这类异常值进行处理。此外,由于数据中各特征的量纲都不一致,为提高模型的稳定性和精度,需要对特征属性值进行归一化处理。
(1)异常值处理
观察表1可知,小于0的光谱吸收光谱值为异常值,全部集中分布在916~925nm处,而780nm以外的光谱波段已经不属于紫外可见光谱范围了,这一区间对测定CODmn已无影响[2]。因此,可以从实验数据中直接去除这一区间的值。
(2)数据归一化
由于光谱吸收值和CODmn各自的量纲不统一,其值的取值范围差别很大,为了消除量纲在数据分析中的影响,提高模型的预测能力,需要对数据进行归一化处理,使得各属性下的数据取值范围在[0,1]之间。本文采用离差标准化(Min-Max Normalization)函数,其转换函数如下:

其中,x'为归一化后的样本数据,xi为某时刻某个属性的样本数据,xmax、xmin依次为某属性下样本数据的最大值、最小值。
2.2 评价函数选取
本文采用决定系数(R2)、平均绝对误差(Mean Ab-solute Error,MAE)、均方差(Mean Square Error,MSE)来评价模型。
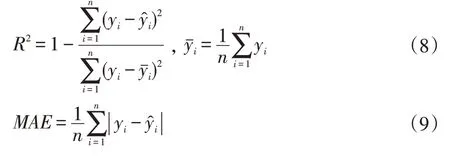

公式(8)-(10)中n为样本数据的数量,yi为样本数据中CODmn的实际值,̂代表模型预测出的COD-mn值,为测试数据集中实际CODmn的均值。对于R2而言,其取值范围为[0,1]:R2越接近0,说明模型的拟合效果越差,即拟合优度越低;R2越接近1,说明模型拟合效果越好,即拟合优度越高。对于MAE和MSE而言,其取值范围为[0,+∞),值越接近0说明模型越完美,模型的精度越高。
3 模型训练与结果
按训练集占总数据的80%、测试集占总数据的20%比例将数据集划分好。在Windows10系统下的Anaconda3实验环境中,采用Python语言编写好XG-Boost水质预测模型,反复训练模型,并根据模型的结果反馈及时调整模型的参数使之获得最佳预测效果。经调试,模型的最佳参数分别是:'objective':'reg:linear','booster':'gbtree','eta':0.03,'max_depth':10,'subsample':0.9,'colsample_bytree':0.7,'silent':1,'seed':10。
为验证XGBoost模型在预测水质CODmn过程中的有效性,另使用Python语言构建了以RBF做核函数的支持向量回归(Support Vector Regression,SVR)模型作为对比。
两种模型的拟合图如图1所示。
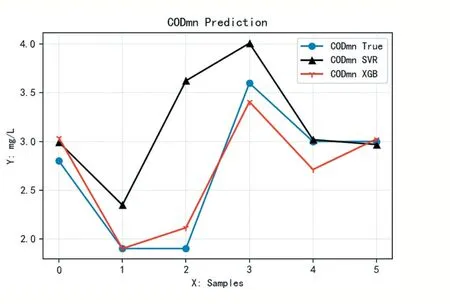
图2 SVR模型和XGBoost模型的拟合图
分别对SVR模型和XGBoost模型进行评价,其评价表如表2所示。其中,R2xgb=0.9021,R2svr=0.4814,XGBoost相较于SVR更接近1,说明XGBoost模型的拟合优度比SVR模型的拟合优度更好;MAExgb=0.1597 表2 SVR模型和XGBoost模型评价结果 本文采用实际水样的实测紫外-可见光谱吸收光谱数据及国标法(锰法)测定的CODmn数据,构建了吸收紫外-可见光谱的CODmn训练和测试数据集,并用经典的机器学习算法SVR和当今数据科学领域较为流行的XGBoost算法分别建立了CODmn预测模型。实验结果表明,针对本文的实验数据,XGBoost模型在水质CODmn的预测上具有更好的拟合优度和模型精度,为利用机器学习方法构建模型预测水质CODmn提供了新思路。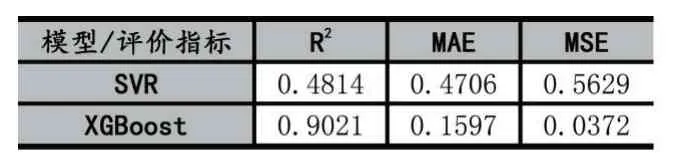
4 结语
猜你喜欢
农业工程学报(2022年8期)2022-08-08
科学24小时(2019年6期)2019-09-05
分析化学(2019年3期)2019-03-30
环境与发展(2018年6期)2018-09-17
分析化学(2016年11期)2017-04-25
光学仪器(2016年6期)2017-04-24
世界文学评论(2014年2期)2014-04-12
祝您健康(1989年2期)1989-12-30
祝您健康(1989年5期)1989-01-06
