
深度迁移主动学习研究综述
2021-05-28 12:38刘大鹏曹永锋张伦
现代计算机 2021年10期
刘大鹏,曹永锋,张伦
(1.贵州师范大学数学科学学院,贵阳550025;2.贵州师范大学大数据与计算机科学学院,贵阳550025)
0 引言
近些年来深度学习在很多领域中都取得了十分显著的成效[1-3]。其取得显著效果的前提条件是需要数以万计的带有标签的样本,而获取这些标签(标注)需要消耗大量的金钱、时间和精力,成本十分昂贵。如何利用很少量的标注样本达到目标任务高性能是急迫解决的难题。
深度迁移学习和深度主动学习是应用于深度领域中解决标注样本不足的两类主流方法。深度迁移学习降低了训练样本必须与测试样本独立同分布的要求,尝试将知识从源域迁移到目标域,以提高深度模型的性能[4-5]。从空白开始训练一个目标任务模型需要大量目标域标注样本。而从一个与目标任务相关却不同的源任务模型开始训练目标任务模型,所需目标域标注样本将会大大减少[6]。此外,源域标注样本还可以直接为目标任务免费使用[7-8]。尽管如此,在多数情况下,将源任务模型调整到适应目标任务仍然需要较大数量的目标域标注样本。并且从源域中迁移的标注样本的分布可能与目标域分布差异很大,造成“负迁移”,使得模型的性能降低。
深度主动学习旨在对未标注样本集进行选择性采样并标注,通过使用最少量代表性的样本来最大化深度模型的性能,以此减少训练深度模型所需的标注数量[9]。虽然深度主动学习可以在一定程度上降低训练深度模型需要的标注成本,但是想要训练一个高性能的深度模型仍然需要大量的标注样本。
在解决训练样本缺乏的问题上,深度迁移学习和深度主动学习各有擅长与不足。为了更好地解决训练样本不足的问题,近些年来,有研究者开始将两种方法进行结合产生了深度迁移主动的学习方法。一来可以结合深度主动学习的思想,解决“负迁移”的问题;二来也利用了深度迁移学习降低深度主动学习中获得训练样本的代价。本文首先对深度迁移学习和深度主动学习进行归纳,然后总结最新的深度迁移主动学习工作,并指出了可行的研究方向。
1 研究现状
1.1 深度迁移学习
在深度迁移学习中,训练数据和测试数据不需要服从独立同分布,并且目标任务模型不需要从零开始训练,这显著降低了深度模型在目标域内对训练样本量和训练时间的需求[10]。基于迁移的目标形态,可将深度迁移学习分为:基于实例的深度迁移学习[5,11-12]和基于映射的深度迁移学习[13]。对深度迁移学习的一种稍复杂的不同形式分类可参考文献[14]。
(1)基于实例的深度迁移学习
基于实例的深度迁移学习是将源域中与目标域相似的样本迁移到目标域中并赋予权重以辅助目标任务模型训练,越相似的样本,赋予的权重就越大。这样训练出来的模型会很好地适应到目标域中。
Wenyuan Dai等人[5]提出了一种集成迁移学习框架TrAdaBoost,他们利用了AdaBoost的技术调整源域样本的权重,来减弱源域中与目标域差异性大的样本对目标任务模型的影响。在每一个迭代中,使用重新加权的源域样本和有标注的目标样本训练模型。实验证明,即使在目标域样本稀少的情况下,也能借助加权后的源域样本构建高性能模型。
Xiaobo Liu等人[7]在Wenyuan Dai等人[5]的基础上进行了改进,增加了重采样算法——Weighted-Resam-pling。在每次迭代中只从源域挑选权重值最大的样本迁移到目标域中,并结合目标域中的原始样本来重构训练集。
很多实例迁移的研究[5,7]都是通过欧氏距离来衡量实例之间的差异。但是在很多实际应用中欧氏距离并不能很好地表达实例之间的相似或差异性,Yonghui Xu等人[12]提出了一种可以很好弥补这一缺陷的度量算法——MIFT。MIFT是一个多目标学习框架,可以同时学习源域数据的实例权值、目标域的马氏距离度量以及目标域的最终预测模型。
(2)基于映射的深度迁移学习
一般地,任意深度神经网络可以看成是将特定输入(样本,样本对,多源样本对,…)和特定输出(预测概率,距离测度值,…)建立的一个映射。基于映射的深度迁移学习是指利用源域样本(或者源域和目标域的样本联合)训练一个网络模型,并使用该网络模型服务于目标任务(通常会嵌入到目标任务初始模型内部)。根据训练样本所用域的个数,基于映射的深度迁移学习再分为:基于单域映射的深度迁移学习和基于联域映射的深度迁移学习。
1)基于单域映射的深度迁移学习
基于单域映射的深度迁移学习是指对仅经过源域样本训练的局部网络(包括其网络结构和连接参数)进行重用,将其转变为目标任务模型的一部分。
Yong Xu等人[4]在语音识别的任务中设计出了一种深度迁移学习方法。该方法将DNN神经网络的隐藏层作为语音识别的特征提取层,认为特征提取层是可以在多种语音之间相互迁移的;最后一层为语音识别的分类层。其将一个在样本丰富的语音样本集中预训练的DNN网络迁移到样本稀缺的语音数据集上,通过冻结预训练模型的特征提取层仅微调分类器层的方式再训练模型。实验证明仅使用少量的目标样本就能显著提高DNN的性能。
Jason Yosinski等人[15]通过实验量化了深度卷积神经网络各层神经元的一般性与特异性,指出神经网络中各层神经元的可迁移性会受到两个负面问题的影响:①源任务模型高层神经元学习到的是针对源任务的特征表示,并不适用于目标任务;②冻结过多的前层微调后层会导致网络参数优化困难。对在ImageNet[16]上训练的示例网络的迁移实验结果表明,他们证明了这两个问题都可能占主导地位,这取决于是否从网络的底部、中间或顶部迁移特征。除此之外,实验结果还表明即使从很不相似任务迁移来的网络参数也要比随机生成的参数更好。
Maxime Oquab等人[17]重用了在ImageNet上训练的特征提取层并在后面新添了两个全连接层。在微调模型以适应目标任务时,冻结了在ImageNet上训练的层,只在PASCAL VOC数据集中学习模型最后两层参数。最终研究表明迁移学习显著提高了物体和动作的分类结果。
2)基于联域映射的深度迁移学习
基于联域映射的深度迁移学习是指在预训练中联合使用源域和目标域的样本训练网络模型,使得网络能够学习到使得两域分布尽可能相近的表示。这样训练出来的网络模型能够更好地适用于目标任务。
Eric Tzeng等人[18]提出了一个新的CNN迁移学习框架,它引入了适应层和域距离损失。在适应层中通过MMD[19]的方法计算两域的分布距离,通过最小化分类损失和域距离损失以学习语义上有意义且域不变的表示形式。
Mingsheng Long等人[20]在Eric Tzeng[18]的基础上有了改进:①使用多核变体MMD(MK-MMD[21])距离替换MMD距离;②将在一个适应层中计算域距离损失替换为在三个全连接层中计算域距离损失。
Eric Tzeng等人[22]提出了一种域适应的广义迁移学习框架,可以将最近的域适应的方法[13,18,20]作为特殊情况包含进去。此外,他们还提出了一种新的对抗判别域适应方法AMMD:考虑源域分类损失的同时,通过引入GAN[23]来对抗学习域不变的特征表示,这样在学习域不变表示的同时能够对源域样本较好的分类。
1.2 深度主动学习
深度主动学习选择最有价值的样本来查询其标签,旨在使用少量的样本训练模型以达到使用全部样本训练的效果。一般地,设计一个深度主动学习框架需考虑三个主要部分[9,24]:①构建初始训练集;②设置主动查询函数;③迭代训练。对一般主动学习(没有使用深度模型)的详细总结可参考文献[25]。
(1)构建初始训练集
构建初始样本集是深度主动学习框架的起始阶段。根据初始样本集可训练得到一个具备一定分类能力的初始模型,为主动挑选样本做准备。
构建初始样本集的方法主要有两种。一种比较常见的是从所有未标注样本的集合中,按照一定的比例随机抽取出来并标注;Asim Smailagic等人[9]提出一个新的构建方法,他们采用ORB算法构造初始样本集,是为了找到彼此最不相似的图像,从而覆盖更大的搜索区域。
(2)设置主动查询函数
设置主动查询函数是深度主动学习框架的核心。主动查询函数可大致分为以下几类:基于度量不确定的主动查询函数、基于度量多样性的主动查询函数[26]和基于度量差异性的主动查询函数[9]。
常见的基于度量不确定的主动查询函数有:LC[25]、MS[27]、EN[28]。LC是根据模型对样本预测的最大概率值对所有未标注样本进行排序;MS是根据最优标号和次优标号对应预测概率的差值对所有未标注样本进行排序;EN是根据模型对样本预测概率的熵值对所有未标注样本进行排序;Keze Wang等人[24]提出了一个与半监督方法相结合的深度主动学习方法,其在主动查询时挑选两种互补性样本:高置信度样本和低置信度样本,来训练当前深度模型。其中当未标记样本的预测概率高于某个阈值时被认定为高置信度样本,低置信度样本是根据EN挑选得到的。
Asim Smailagic等人[9]设计出了一个用于医学图像分割的深度主动学习方法MedAL,其主动查询函数基于样本之间的差异性度量。每次主动学习迭代都挑选与已有样本差异最大的样本来标注学习。
Zongwei Zhou等人[26]提出了一个基于度量样本多样性的主动学习方法,其将样本的多样性定义为样本增广图片预测的一致性。使用自定义的多样性函数首先计算两个增广图片之间多样性,然后将样本所有增广图片之间的多样性指标相加得到该样本的多样性。
(3)迭代训练
迭代训练是深度主动学习框架的运行环节,它规定了如何使用不断累积的标注数据训练模型。
在每次主动学习迭代中,大部分研究都选择将新标注的样本放回已标记样本池中,然后使用已标记池的全部样本训练分类器[9,26];另一种方式是使用新标注样本和先前可用训练样本的特定子集[24]。Keze Wang等人[24]用新标注的样本和由模型自动伪标注的样本训练模型。自动伪标注样本每一轮都会重新更新,这样做可以减少错误的伪标记样本混乱模型。Zongwei Zhou等人[29]在每次迭代中剔除掉在已标注池中模型预测确置信度的样本。这样可以使得模型不再专注学习预测高的样本而偏向学习那些难以预测的样本。
1.3 深度迁移主动学习
主动迁移学习是将主动学习和迁移学习相结合的方法。如前文所述,迁移学习和主动学习各自包含很多类型的子方法,将这些子方法进行结合会产生更多变化。本文将主动迁移学习的方法归纳为强结合和弱结合两种类别(参见图1)。弱结合的方法是指:虽然其包含了迁移学习和主动学习,但是两者在发挥作用时没有关联性,其中一种方法作用时并不需要另一种方法的支撑。相比之下,强结合的方法是指:主动学习和迁移学习紧密地结合在一起,彼此在发挥作用的时候有着关联性。
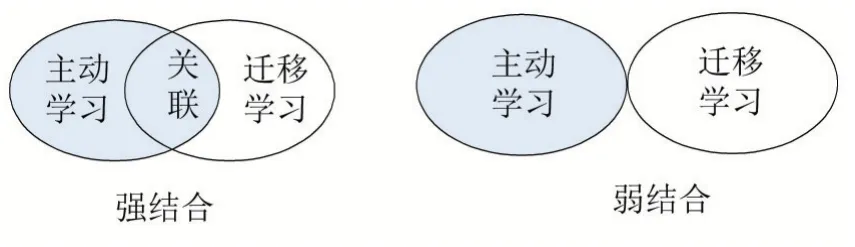
图1 两种类别的主动迁移学习方法
有一些研究[30-31]将主动学习、迁移学习与浅层模型进行了结合。Cheng Deng等人[30]通过MS的主动学习方法从目标域未标记数据集中挑选最具信息量的样本进行标注,再结合源域样本来训练模型,并且在优化函数中添加MMD正则化项来解决两域样本之间存在的域适应问题。因为其主动学习部分与迁移学习所用的方法没有联系点、均独立发挥作用,所以属于弱结合的方法。
Sheng-Jun Huang等人[31]设计出一种强结合的迁移主动学习方法。此方法主动从加权后的源域样本中挑选最不确定性以及与目标域分布匹配的样本,其中源域样本的权值和主动挑选的样本是在一个基于分布匹配框架下交替优化得到。该方法为“实例迁移”和“主动学习”的强结合。
近些年,开始有少量研究将深度主动学习和深度迁移学习进行结合。Zongwei Zhou等人[26]提出了AIFT深度迁移主动学习方法。其使用了AlexNet[32]网络模型并且迁移了在ImageNet数据集中训练的网络参数,同时使用了多样性与不确定性结合的主动学习方法在目标域未标记池中挑选最具信息量的样本训练模型。其迁移学习部分只是简单的“单域映射迁移”,主动学习部分采用的方法也没有与迁移学习有联系点,因此是一种典型的弱结合方法。
Sheng-Jun Huang等人[6]同样采用了在ImageNet数据集预训练的深度网络模型,并且设计了动态权衡独特性和不确定的主动学习方法从目标域中挑选样本。其主动学习部分需要利用源域样本在特征层空间的投影点计算独特性指标,此处加强了主动学习和迁移学习的联系,因此该方法属于强结合类别。
Cheng Deng等人[8]使用了源域的部分样本和通过MS主动学习函数从目标域中挑选得到的最具信息量的样本联合训练在源域中预训练过的深度模型。其将迁移来的源域样本与主动从目标域挑选的样本组合训练模型,同时采用主动学习方法从源域样本中剔除那些会影响目标模型性能的样本。这是一种强结合的深度主动迁移学习的方法。
2 结语
本综述主要对深度迁移学习、深度主动学习、深度主动迁移学习三个领域进行了总结和概述。
深度迁移学习和深度主动学习都可以一定程度上解决标注样本不足的问题,而将深度主动学习和深度迁移学习结合能够进一步降低标注成本。然而,当前对两者的结合,即深度迁移主动学习的研究工作还不多,研究工作的深度和广度都不够。例如,多数工作停留在了“弱”结合的范畴,而不是“强”结合范畴;多数是两种方法的结合:如“单域映射迁移”+“主动学习”[6,26],而很少进行三者结合:如“实例迁移”+“单域映射迁移”+“主动学习”[8];稍复杂的“联域映射迁移”还未见与“主动学习”的结合。因此,深度迁移主动学习领域仍存在巨大的探索空间,对其的研究探索才刚刚开始。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
小天使·三年级语数英综合(2022年4期)2022-04-28
新高考·高三数学(2022年3期)2022-04-28
福建基础教育研究(2019年6期)2019-05-28
汽车导报(2017年5期)2017-08-03
数学学习与研究(2017年3期)2017-03-09
求学·理科版(2017年1期)2017-03-02
中学生数理化·高二版(2016年4期)2016-05-14
计算技术与自动化(2014年1期)2014-12-12
棋艺(2001年21期)2001-01-06
