
基于BERT的水稻表型知识图谱实体关系抽取研究
2021-06-09 10:25袁培森李润隆徐焕良
农业机械学报 2021年5期
袁培森 李润隆 王 翀 徐焕良
(1.南京农业大学人工智能学院,南京 210095;2.国网江苏省电力有限公司信息通信分公司,南京 210024)
0 引言
植物表型组学数据分析是近年来植物学、信息科学领域研究的交叉热点,其本质是对植物基因数据的三维时序表达,以及地域分布特征和代际演进规律[1]。表型组学指利用生物的遗传基因组信息对生物的外部及内部表型数据进行研究的一门综合性学科[2]。植物表型组学不仅研究植物的外在形状,还研究其内部结构、物理和生化性质以及遗传信息。亟需研究建立植物表型组学数据完整知识库的智能计算方法[3]。
中国是世界上水稻产量最大、消费最多的国家[4],水稻的培育及研究是中国粮食安全战略的重要内容[5]。水稻表型组学研究是植物生物学的研究热点,水稻表型数据的高通量、高维、海量的数据特征对数据的快速检索和知识的有效提取提出了更高的技术要求[6]。
知识图谱将知识转化为图,利用计算机进行推理分析,实现从感知智能到认知智能的飞跃,是人工智能领域的一项重要技术[7]。知识图谱是一个具有结构化特征的语义知识库,采用符号的形式描述数据中的实体及之间的关系[8],利用对语义的抽取和分析,并结合数据科学、人工智能等学科的前沿技术和方法,在学科知识库构建领域获得了广泛关注。
对知识图谱系统的构建包括2个核心步骤:实体抽取、实体间关系的构建,其中实体关系的构建需要关系的抽取技术。关系抽取任务的研究目标是自动对两个实体和之间联系所构成的3元组进行关系识别[9]。关系抽取能够提取文本数据中的特征,并提升到更高的层面[10]。
实体关系的抽取方法可以分为3类:基于模板、基于传统机器学习和基于深度学习的方法[11]。基于模板的关系抽取方法是早期基于语料学知识及语料的特点,由相应领域的专家和研究人员手工编写模板,这种方法需要耗费大量专业人力,可移植性较差。基于传统机器学习的关系抽取方法主要包括使用核函数[12]、逻辑回归[13]以及条件随机场[14]等,是一种依赖特征工程的方法。HASEGAWA等[15]使用聚类方法计算上下文的相似性。赵明等[16]采用本体学习,使用有监督的、基于依存句法分析的词汇-语法模式对百度百科植物语料库进行关系抽取,在非分类的关系抽取任务中表现较好,为构建植物领域知识图谱奠定了基础。
基于深度学习的关系抽取方法包括递归神经网络模型[17]、卷积神经网络模型[18]、双向转换编码表示模型(Bidirectional encoder representation from transformers, BERT)[19]等。深度学习能够实现语义特征的自动提取,从而使模型能够对不同抽象层次上的语义进行分析[20]。BERT为典型的深度学习模型[19],通过自动学习句中特征信息、获取句子向量表示,能够对水稻表型组学数据进行关系抽取。在水稻知识图谱构建中,区分水稻表型组学实体之间的复杂关系与水稻表型组学知识库的构建有关。因此,研究水稻表型组学的关系抽取十分重要。
本文使用爬虫框架获取水稻表型组学数据,根据植物本体论提出一种对水稻的基因、环境、表型等表型组学数据进行关系分类的方法。使用词向量、位置向量等算法提取句中特征,在获取水稻表型组学实体关系数据集的基础上构建基于双向转换编码表示的关系抽取模型,并将本文方法与卷积神经网络(Convolutional neural network,CNN)[21]、分段卷积神经网络(Piece wise CNN,PCNN)[18]进行对比,以期实现句子级别的关系抽取。
1 水稻表型组学关系数据集
1.1 关系数据获取
本文关系数据集主要来自国家水稻数据中心(http:∥www.ricedata.cn/)以及维基百科中文语料库。数据爬取使用可对网页的结构性数据进行获取以及保存的框架Scrapy[22],实现水稻数据中心本体系统以及维基关系数据集的爬取。对爬取的水稻表型数据进行清洗处理,获得了用于关系分类处理的水稻表型组学关系数据集,数据集详情如表1所示。

表1 数据集来源分布
1.2 关系数据分类
在水稻表型组学关系数据的分类问题上,本文参照了植物本体论(Plant ontology)[23]对植物表型组学的分类,通过关系分类将水稻的解剖结构、形态、生长发育与植物基因数据联系起来,从而对水稻表型组学数据进行分类。
本体[24]指的是在某一领域内的实体与其相互间关系的形式化表达,本体论是概念化的详细说明,它的核心作用是定义某一个领域内的专业词汇以及他们之间的关系[25]。
植物本体论[23]是一种结构化的数据库资源,是用来描述植物解剖学、形态学等植物学的结构性术语集合,它将植物的内部解剖结构、外表形态结构等表型组学数据与植物基因组学数据联系起来,使用关系来描述基因、环境、表型之间的联系。如今植物本体论的描述范围从最开始的水稻单个物种扩大到了22种植物,对这些植物的基因或基因模型、蛋白质、RNA、种质等表型和基因数据进行描述。本文依据其分类规则,将水稻表型组学数据分为7类:①is a,用来表示父术语以及子术语之间的关系,表示对象O1是O2的子类型或亚型。②has part,用来表示对象O1的每个实例都有一部分O2的实例。③has a morphology trait,表示O1通过O2的形态特征表现出来。④develop from,表示O1从O2发育而来,O2的世系可以追溯到O1。⑤participate,表示实体O1的每个实例都参与开发O2的某些实例。⑥regulate,O1对O2有调节或调控作用。⑦other,表示其他关系。
分类完成后的关系抽取数据集示例如表2所示。表2中,ddu1(Dwarf and disproportionate uppermost-internode1)为使用甲基磺酸乙酯诱变粳稻品种兰胜而成的矮化突变体的品种名称;SPL5(Spotted leaf 5)为经γ射线辐射诱导粳稻品种Norin 8而成的水稻类病变突变体的品种名称;FLW1(Flag leaf width NAL1)为剑叶宽度基因。最后,将数据集按8∶2分为训练集和测试集。

表2 关系抽取数据集示例
1.3 关系数据存储
水稻实体及关系采用图方式进行建模以及数据存储,本文使用图数据库Neo4j[26]存放实体和关系数据。Neo4j的核心概念是节点和边,节点用来存储实体,使用圆形图例表示,边用来存储关系数据结构中实体之间的关系,使用带箭头的线表示。不同实体以及关系的相互连接形成复杂的数据结构,实现对某个实体进行关系的完整增删改查等功能。
对收集的数据集进行预处理,提取2 021个实体和2 689条关系,通过Cypher语言[27]进行快速的查询工作。图1为Neo4j数据库存储的水稻表型组学关系示例。由于实体名称较长,图1中的“12号染…”为12号染色体;“等位基因…”为等位基因STV11-S。
2 水稻表型组学关系抽取模型构建
2.1 向量化表示
本文BERT关系抽取模型使用词向量、位置向量以及句子向量相结合的输入向量序列,不仅能简单获取词语语义上的特征,而且能够对深层次语义进行表示和抽取。
2.1.1词向量
本文使用BERT模型中的词嵌入方式来动态产生词向量,即将词转化为稠密的向量。通过这种词嵌入方式,该模型能够根据上下文预测中心词的方式来获得动态的语义特征,以解决传统词嵌入模型产生的多义词局限性,可以产生更精确的特征表示,从而提高模型性能。
BERT的词向量生成方法如下:给定语句序列s=w0,w1,…,wn。其中w0=[CLS]、wn=[SEP]表示句子的开始以及结束。模型将原有的序列映射为具有固定长度的向量来表示语义关系。
2.1.2位置向量
设句子为s=w0,w1,…,wn,实体为i1与i2,则对于每一个单词wi,计算其与i1、i2的相对距离,即i-i1和i-i2,使得该句子可以根据两个实体生成两部分的位置向量,并且能体现距离和实体的关系。本文使用的位置向量维度为50。
2.1.3句子向量
句子向量按照句子的数目进行标记,对于第1条句子的每个单词添加向量v1,给第2条句子中的每个单词添加一个向量v2。
2.1.4输入表示
BERT模型的输入示例如图2所示。图2中的BERT模型输入的句子为“稻是谷类,原产中国与印度”,模型生成每个词的词向量,根据每个词与实体之间的距离生成句向量,根据句子的条数生成对应的句向量,将此作为BERT模型的输入。
2.2 BERT关系抽取模型构建
BERT是以Transformer的编码器为基础的双向自注意力机制表示模型,能够对所有层基于上下文进行双向表示。BERT模型使用双向自注意力机制来进行构建,使用Transformer的编码器来进行编码,并且使用遮挡语言模型以及下一句预测两个方法来更有效地训练模型。
2.2.1双向自注意力机制
BERT使用双向自注意力机制[28]进行构建。双向自注意力机制是注意力机制中的一种,注意力机制在自然语言处理领域的多个任务得到了实际应用。注意力机制可以描述为一个查询Q到相应键值对〈K,V〉的一个映射过程[29],可描述为
At(Q,K,V)=Sf(Sm(Q,K))V
(1)
式中At——注意力机制函数
Sf——Softmax函数
Sm——相似度函数
注意力值的计算过程可分为3部分:①首先计算查询Q和每个键K之间的相似度S,获得权重,使用的相似度计算函数有点积、拼接以及感知机。②使用Softmax函数进行权重归一化。③将权重以及键值对中的值V进行加权,获得最终的注意力值。自注意力机制即检索自身的键值对进行加权处理,Q=K=V,将序列进行重新编码,获得更具整体性的特征序列[30]。自注意力机制的结构图如图3所示。
自注意力机制将输入序列通过向量映射的方式输入到嵌入层,注意力层进行查询向量和值向量的相似度计算,Softmax层使用函数加权后将序列输出。BERT所用的多头自注意力机制在输入到注意力层之前对查询Q、键K以及值V进行多次线性变换,线性变换的次数即为多头,多头自注意力机制可以获得多种序列的子特征,进而获得较长序列中的相隔较远的向量特征[31]。
2.2.2Transformer编码器
BERT使用Transformer编码器进行编码,Transformer[32]通过对语义信息以及位置信息的分析来完成自然语言处理任务,其框架为编码器加解码器结构。其中,编码器框架使用了层叠结构,每一层有两部分:进行加权处理的多头注意力机制和进行前馈化网络的全连接层,在两部分之间使用残差进行连接然后进行标准化。解码器的层数与编码器相同,同时在每一层之内还添加了一个进行计算翻译效果的部分。Transformer编码器结构图如图4所示,图中N×表示编码器或解码器包含的层数。
Transformer编码器由3部分组成:①首先对输入句子进行向量化,将词嵌入到编码器中。②编码器接受向量序列,随后使用自注意力机制对序列进行处理,通过对序列中所有单词之间建立联系来进行序列编码,处理后的序列通过残差网络进行求和与归一化。③自注意力机制结束以后,输入到全连接的前馈网络中,输出标准化后的向量。
BERT模型使用多个Transformer编码器进行编码,编码器输出后进入到一个全连接层与激活函数构成的分类层并输出相应的概率[33]。图5是对水稻表型进行编码示例,输入的句子为“产量性状是与植物可收获产物相关的性状”。
BERT模型在使用过程中,仅需要在编码器后面加上一层全连接层就能够完成关系抽取任务。在后期的微调部分中,设之前遮盖处理后的输出向量为C,使用Softmax分类器完成关系分类的概率Pr为
Pr=Sf(CWT)
(2)
式中W——向量矩阵
对于本文的关系多分类问题,类别标签y∈{1,2,…,M}。给定测试样本x,Softmax函数预测类别c∈{1,2,…,M}的条件概率为
(3)
式中wc——权重
wi——第i类权重
p——概率
BERT模型输出关系类别以及其对应的概率。另外,BERT模型在预训练部分使用了遮挡语言模型以及下一句预测两个方式来训练模型。
2.2.3遮挡语言模型
遮挡语言模型(Masked language model)[19]指的是在进行BERT模型训练时,由于进行的注意力机制是多头而不是单向的,如果按照CNN等模型的训练方式进行训练,则BERT模型的训练将成为一个先获得后文再进行预测的任务,无法正确获取语义特征,因此进行双向注意力机制训练时,BERT使用了遮挡语言模型,将输入的词进行随机遮盖,从而使得双向编码器能够真正对前后文进行预测[19]。本文对15%的词进行遮挡,并且遵循以下规律:①被遮挡的词有80%的概率被替换成屏蔽符号[mask]。②10%的概率被换成随机词。③10%的概率保持原有单词不变。这样后期微调部分的向量输入不会与遮盖处理中的向量差距太大。
2.2.4下一句预测
下一句预测(Next sentence prediction)[19]使BERT模型能够学习下一句和上一句的内在联系,BERT模型在数据集中随机选取句子S1,对于其下一句S2,有50%的概率将S2替换为无关的句子S3,以此来学习句子间的关系。
3 关系分类结果与分析
3.1 试验环境
选择Intel Corei5-8250u处理器@1.6 GHz,8 GB内存,1 TB硬盘,Windows 10操作系统。
3.2 参数设置
BERT模型的参数设置如表3所示。为防止模型训练后期的波动,学习率衰减采用了文献[34]中的推荐值,设置为2×10-5。

表3 BERT模型参数设置
梯度下降算法(Gradient descent optimizer)[35]能够帮助模型进行目标函数的最大化或最小化计算,一个优秀的梯度下降算法能够减少损失函数的值。常用的梯度下降算法有随机梯度下降(Stochastic gradient descent,SGD)[35]、自适应力矩估计(Adaptive moment estimation,ADAM)[36]、解耦权重衰减的自适应矩估计(Adaptive moment estimation with decoupled weight decay,ADAMW)[37]等,本文选择ADAMW算法。
3.3 数据集
根据植物本体论进行实体关系数据的分类,共获得7大类、2 689条关系数据,类型有:is a、has part、has a morphology trait、develop from、participate、regulate、other。各个关系类型的数量及分布如表4所示。

表4 水稻表型组学关系数据集的数量分布
3.4 算法性能评估指标
使用精度(Precision,P)、召回率(Recall,R)、F1值(F1)作为评价指标,将BERT与传统的卷积神经网络模型[21]与分段卷积神经网络模型[18]进行对比。
3.5 BERT模型关系分类结果
本部分对梯度下降算法[35]、批尺寸[38]和表2中的关系进行了试验分析测试。
3.5.1梯度下降算法
对于BERT关系抽取模型,本文进行了梯度下降算法的对比,选择批(Batch)尺寸为8,3种梯度下降算法在BERT模型上的结果如图6所示。
由图6可以看出,ADAMW的精度、召回率和F1值比SGD和ADAM高,SGD最低,3个指标均在60%左右。ADAM和ADAMW都在94%以上。
3.5.2批尺寸
选择批尺寸分别为8、16、32、64进行试验,选择ADAMW作为梯度下降算法,其在BERT模型上的结果如表5所示。
由表5可知,批尺寸为8时,ADAMW算法的精度达到了95.11%,召回率为96.61%,F1值为95.85%。相比批尺寸为16、32、64,精度分别提高了0.52、0.63、0.88个百分点;F1值分别提高1.04、0.22、1.23个百分点。

表5 不同批尺寸在BERT模型上的对比
3.5.3不同关系类型的处理结果
本试验批尺寸为8,BERT模型使用ADAMW算法对本文数据集上的不同关系抽取结果进行对比,结果如表6所示。
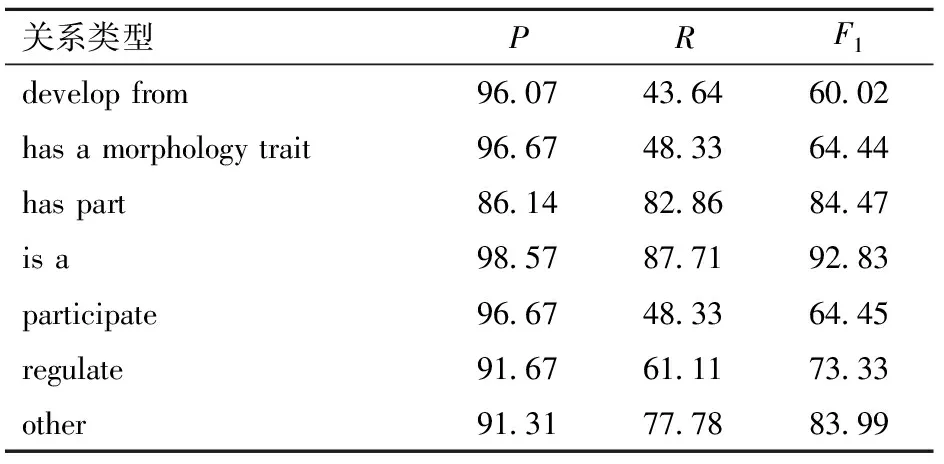
表6 BERT模型对不同关系的处理结果
由表6可知,BERT模型对于不同关系的F1值都不低于60.02%,但是对于不同关系的处理效果也不同。其中,对于has part、is a、other、regulate关系分类效果较好,其F1值都不小于73.33%,而对于develop from、participate、has a morphology trait的分类效果相对较差。在7种关系中,is a关系类型的测试结果最佳,其F1值达到了92.83%,是develop from类型的1.546 7倍。develop from、has a morphology trait和participate 分类效果较差的原因是这3个关系类别的数据库中关系数较少,且数据集中各个类别的分布不均衡。其解决方法有:①通过增加这3个类别实体关系数据使BERT模型提取更多有效的语义和词汇特征。②将各个关系数据的条数进行调整,保持各个类别实体关系数据的数量均衡。
3.6 模型对比
本文将CNN[21]、PCNN[18]与BERT模型进行对比,CNN和PCNN模型的参数设置如表7所示。

表7 CNN和PCNN模型参数设置
CNN在批尺寸为16时,使用SGD算法时获得最高精度、召回率与F1值,精度为81.79%,召回率为82.35%,F1值为82.07%。PCNN的批尺寸为16,使用SGD算法时,获得最高精度、召回率与F1值,精度为85.95%,召回率为81.67%,F1值为83.66%。BERT模型在隐藏层数量为1 536、最大序列长度为80、学习率衰减为2×10-5、训练轮数为5、批尺寸为8、梯度下降算法为ADAMW时,关系抽取的精度、召回率与F1值达到最优,精度为95.11%,召回率为96.61%,F1值为95.85%。
BERT在精度、召回率以及F1值上都明显高于其他两种模型,其F1值是CNN的1.17倍、PCNN的1.15倍。
综上所述,在使用BERT模型进行水稻表型组学数据关系抽取时,BERT模型能够根据上下文预测中心词的方式来获得动态的词向量,使用自注意力机制获得双向的语义特征,大幅度提高了关系抽取的质量。
4 结束语
本文基于植物本体论提出基于水稻表型组学的关系分类方法,将水稻表型的实体关系分为7类,使用词向量、位置向量以及句子向量进行句子特征抽取,构建BERT模型,并将BERT模型与CNN、PCNN模型进行对比。结果表明,BERT模型的精度、召回率与F1值分别为95.11%、96.61%和95.85%,达到了预期分类效果。
猜你喜欢
中华医学图书情报杂志(2022年1期)2022-11-18
网络安全与数据管理(2022年1期)2022-08-29
中国现代医生(2022年21期)2022-08-22
昆明医科大学学报(2022年3期)2022-04-19
锻压装备与制造技术(2021年5期)2021-11-13
昆明医科大学学报(2021年4期)2021-07-23
科学技术创新(2021年5期)2021-03-17
智慧健康(2021年33期)2021-03-16
天津医科大学学报(2021年1期)2021-01-26
天津医科大学学报(2021年1期)2021-01-26
