
A survey on adversarial attacks and defences
2021-06-19 13:04AnirbanChakrabortyManaarAlamVishalDeyAnupamChattopadhyayDebdeepMukhopadhyay
Anirban Chakraborty| Manaar Alam| Vishal Dey| Anupam Chattopadhyay|Debdeep Mukhopadhyay
1Department of Computer Science and Engineering,Indian Institute of Technology Kharagpur,Kharagpur,West Bengal,India
2Department of Computer Science and Engineering,The Ohio State University,Columbus,Ohio,USA 3Schoolof Computer Science and Engineering,Nanyang Technological University,Singapore
Abstract Deep learning has evolved as a strong and efficient framework that can be applied to a broad spectrum of complex learning problems which were difficult to solve using the traditional machine learning techniques in the past.The advancement of deep learning has been so radical that today it can surpass human-level performance.As a consequence,deep learning is being extensively used in most of the recent day-to-day applications.However,efficient deep learning systems can be jeopardised by using crafted adversarial samples,which may be imperceptible to the human eye,but can lead the model to misclassify the output.In recent times,different types of adversaries based on their threat model leverage these vulnerabilities to compromise a deep learning system where adversaries have high incentives.Hence,it is extremely important to provide robustness to deep learning algorithms against these adversaries.However,there are only a few strong countermeasures which can be used in all types of attack scenarios to design a robust deep learning system.Herein,the authors attempt to provide a detailed discussion on different types of adversarial attacks with various threat models and also elaborate on the efficiency and challenges of recent countermeasures against them.
1|INTRODUCTION
Deep learning is a branch of machine learning that enables computationalmodels composed of multiple processing layers with high level of abstraction to learn from experience and perceive the world in terms of hierarchy of concepts.It uses backpropagation algorithm to discover intricate details in large datasets in order to compute the representation of data in each layer from the representation in the previous layer[1].Deep learning has been found to be remarkable in providing solutions to the problems which were not possible using conventional machine learning techniques.With the evolution of deep neural network(DNN)models and availability of highperformance hardware to train complex models,deep learning made a remarkable progress in the traditional fields of image classification,speech recognition and language translation along with more advanced areas like analysing potential of drug molecules[2],reconstruction of brain circuits[3],analysing particle accelerator data[4,5]and effects of mutations in DNA[6].Deep learning network,with their unparalleled accuracy,has brought in major revolution in artificial intelligence(AI)-based services on the Internet,including cloudcomputing-based AI services from commercial players like Google[7],Alibaba[8],and corresponding platform propositions from Intel[9]and Nvidia[10].Extensive use of deeplearning-based applications can be seen in safety and security-critical environments like malware detection,selfdriving cars,and drones and robotics.With recent advancements in face-recognition systems,ATMs and mobile phones are using biometric authentication as a security feature;voice controllable systems(VCS)and automatic speech recognition(ASR)models made it possible to realise products like Amazon Alexa[11],Apple Siri[12]and Microsoft Cortana[13].
As DNNs have found their way from labs to real world,security and integrity of the applications pose great concern.Adversaries can craftily manipulate legitimate inputs,which may be imperceptible to human eye,but can force a trained model to produce incorrect outputs.Szegedy et al.[14]first showed that well-performing DNNs can also be a victim of adversarial attack.Carlini et al.[15]and Zhang et al.[16]independently brought forward the vulnerabilities of ASR and VCS.Attacks on autonomous vehicles have been demonstrated by Kurakin et al.[17]where the adversary manipulated traffic signs to confuse the learning model.The paper by Goodfellow et al.[18]provides a detailed analysis with supportive experiments of adversarialtraining of linear models,while Papernot et al.[19]addressed the aspect of generalization of adversarial examples.Abadi et al.[20]proposed a method to protect the privacy of training data by introducing the concept of distributed deep learning.Recently,in 2017,Hitaj et al.[21]exploited the real-time nature of the learning models to train a generative adversarial network(GAN)and showed that the privacy of the collaborative systems can be jeopardised.Since the findings of Szegedy et al.,a lot of attention has been drawn to the context of adversarial learning and its consequences.A number of countermeasures have been proposed in recent years to mitigate the effects of adversarialattacks.Kurakin et al.[17]proposed the idea of using adversarial training to protect the learner by augmenting the training set using both original and perturbed data.Hinton et al.[22]introduced the concept of distillation which was used to propose a defence mechanism against adversarial attacks[23].Samangoueiet al.[24]proposed a mechanism to use GAN as a countermeasure for adversarial perturbations.Although each of these proposed defense mechanisms was found to be efficient against particular classes of attacks,none of them could be used as a one-stop solution for all kinds of attacks.Moreover,implementation of these defence strategies can lead to degradation of performance and efficiency of the concerned model.
1.1|Motivation and contribution
The importance of deep learning applications is increasing day by day in our daily life.However,a number of studies have shown that these applications are vulnerable to adversarial attacks.Akhtar et al.[25]presented a comprehensive outline and summarized adversarial attacks on DNNs,but in a restrictive context of computer vision.There have been a handfulof surveys on security evaluation related to particular machine learning applications[26–29].Kumar et al.[30]provided a comprehensive survey of prior works by categorizing the attacks under four overlapping classes.The primary motivation of this paper is to summarize recent advances in different types of adversarial attacks with their countermeasures by analysing various threat models and attack scenarios.We follow a similar approach like prior surveys,but without restricting ourselves to specific applications and also in a more elaborate manner with practical examples.
1.1.1 |Organization
Herein,we discuss recent advancements on adversarialattacks and present a detailed understanding of the attack models and methodologies.While our major focus is on attacks and defences on DNNs,we have also presented attack scenarios on support vector machines(SVM)keeping in mind their extensive use in real-world applications.We first provide a taxonomy of related terms and keywords and categorize the threat models in Section 2.This section also explains adversarialcapabilities and illustrates potential attack strategies in training(e.g.poisoning attack)and testing(e.g.evasion attack)phases.We discuss in brief the basic notion of black-box and white-box attacks with relevant applications and further classify blackbox attack based on how much information is available to the adversary about the system.Section 3 summarizes exploratory attacks that aim to learn algorithms and models of machine learning systems under attack.Since the attack strategies in evasion and poisoning attacks often overlap,we have combined the work focusing on both of them in Section 4.In Section 5,we discuss some of the current defense strategies and we conclude in Section 6.
2|TAXONOMY OF MACHINE LEARNING AND ADVERSARIAL MODEL
Before discussing in details about the attack models and their countermeasures,in this section,we will provide a qualitative taxonomy on different terms and keywords related to adversarialattacks and categorize the threat models.
2.1|Keywords and definitions
In this section,we summarize predominantly used approaches with emphasis on neural networks to solve machine learning problems and their respective application.
·Supportvectormachines:SVMs are supervised learning models mathematically formulated as optimal hyperplanes for linearly and non-linearly separable hyperspace using kernel functions.They are widely used for classification,regression or outlier detection,representing data as points in space with objective of building a maximum-margin hyperplane and splitting the training examples into classes,while maximizing the distance between the split points.
·Neuralnetworks:Artificial neural network(ANN)is a framework based on a collection of perceptrons calledneurons.The concept of ANN is inspired by the biological neural networks.The objective of each neuron is to map a set of inputs to an output using an activation function.The learning governs the weights and activation function so as to be able to correctly determine the output.Weights in a multi-layered feed forward are updated by the backpropagation algorithm.Neuron was first introduced by McCulloch-Pitts,followed by Hebb’s learning rule,eventually giving rise to multi-layer feed-forward perceptron and back-propagation algorithm.ANNs deal with supervised(convolutional neural network[CNN],DNN)and unsupervised network models(self-organizing maps)and their learning rules.The neural network models used ubiquitously are discussed below.
1.DNN:While single-layer neural net or perceptron is a feature-engineering approach,DNN enables feature learning using raw data as input.Multiple hidden layers and its interconnections extract the features from unprocessed input and thus enhance the performance by finding latent structures in unlabelled,unstructured data.A typical DNN architecture,graphically depicted in Figure 1,consists of multiple successive layers(at least two hidden layers)of neurons.Each processing layer can be viewed as learning a different,more abstract representation of the original multidimensional input distribution.
2.CNN:A CNN consists of one or more convolutionalor sub-sampling layers,followed by one or more fully connected layers,to share weights and reduce the number of parameters.The design of the architecture of CNN,shown in Figure 2,is done in such a way so that it can take advantage of two-dimensional(2D)input structures(e.g.image).Convolution layer creates a feature map.A process called pooling(also known as sub-sampling or downsampling)is deployed to reduce the dimensionality of feature maps.However,it ensures to retain the most important information to have a model robust to small distortions.For example,to describe a large image,feature values in original matrix can be aggregated at various locations(e.g.max-pooling)to form a matrix of lower dimension.The last fully connected layer uses the feature matrix formed from the previous layers to classify the data.CNN is mainly used for feature extraction;thus it also finds application in data pre-processing commonly used in image recognition tasks.
2.2 |Adversarial threat model
The security of any machine learning model is evaluated considering the goals of an adversary and his capabilities in accessing the model.In this section,we taxonomize different adversarial threat models possible keeping in mind the strength of an adversary.We first present the identification of threat surface[31]of various real-life applications which are built using machine learning models to identify how and where an adversary may try to compromise the proper working nature of the system.
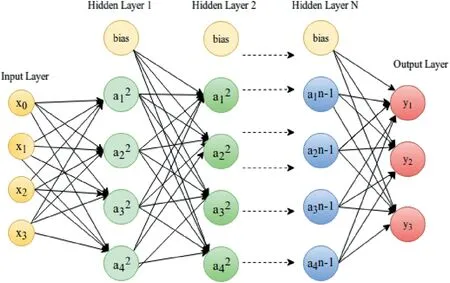
FI GUR E 1 Deep neuralnetwork
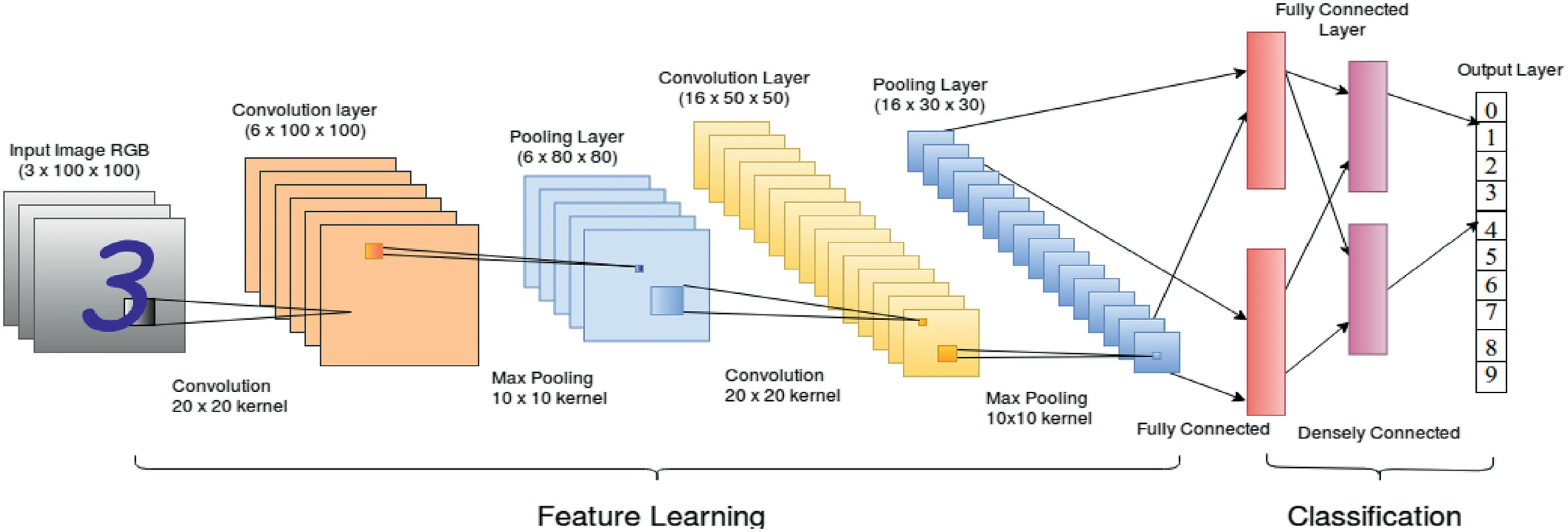
FI GUR E 2 Convolutional neural network for MNIST digit recognition
2.2.1 |The attack surface
A system built on machine learning can be viewed as a generalized data processing pipeline.A primitive sequence of operations of the system at the testing time can be viewed as(a)collection of input data from data repositories or sensors,(b)transferring the data in the digital domain,(c)processing of the transformed data by machine learning modelto produce an output and,finally,(d)action taken based on the output.For illustration,consider a generic pipeline of an automated vehicle system as shown Figure 3.
The system collects sensor inputs(images using camera)from which model features(tensor of pixel values)are extracted and fed to the models.The model then tries to interpret the meaning of the output(probability that the image is of a stop sign),and takes appropriate action(stopping the car).Theattacksurface,in this case,can be interpreted based on the data processing steps.The objective of an adversary could be to attempt to manipulate either the datacollectionor the dataprocessingin order to corrupt the target model,thus tampering the original output.The main attack scenarios identified by the attack surface are sketched as follows[29,32]:
1.Evasionattack:This is the most common type of attack in the adversarial setting.The adversary tries to evade the system by adjusting malicious samples during testing phase.This setting does not assume any influence over the training data.
2.Poisoningattack:This type of attack,known as contamination of the training data,is carried out at training phase of the machine learning model.An adversary tries to inject skilfully crafted samples to poison the system in order to compromise the entire learning process.
3.Exploratoryattack:These attacks do not influence training dataset.Given black-box access to the model,they try to gain as much knowledge as possible about the learning algorithm of the underlying system and pattern in the training data.
The definition of a threat model depends on the information the adversary has at their disposal.Next,we discuss in details the adversarialcapabilities for the threat model.
2.2.2 |The adversarialcapabilities
The term adversarial capabilities refer to the amount of information available to an adversary about the system,including the attack vector used on the threat surface.For illustration,again consider the case of an automated vehicle system as shown in Figure 3 with the attack surface being the testing time(i.e.an evasion attack).An internaladversary is one who have access to the model architecture and can use it to distinguish between different images and traffic signs,whereas a weaker adversary is one who have access only to the dump of images fed to the model during testing time.Though both the adversaries are working on the same attack surface,‘the former attacker is assumed to have much more information and is thus strictly a stronger adversary.We explore the range of attacker capabilities in machine learning systems as they relate to inference and training phases’[31].
Trainingphasecapabilities
Most of the attacks in the training phase are accomplished by learning,influencing or corrupting the model by direct alteration of the dataset.The attack strategies are broadly classified into the following categories based on the adversarial capabilities:
1.Datainjection:The adversary neither has access to the training data nor to the learning algorithm but has ability to augment a new data to the training set.He can corrupt the target model by inserting adversarial samples into the training dataset.
2.Datamodification:The adversary does not have access to the learning algorithm but has full access to the training data.He poisons the training data directly by modifying the data before it is used for training the target model.
3.Logiccorruption:The adversary is able to meddle with the learning algorithm.Apparently,it becomes very difficult to design counter strategy against these adversaries who can alter the logic of the learning algorithm,thereby controlling the modelitself.
Testingphasecapabilities
Adversarialattacks at the testing time do not interfere with the targeted model but rather forces it to produce incorrect outputs.The effectiveness of an attack is determined by the amount of knowledge about the model which is available to the adversary.These attacks can be categorized aswhite-boxorblack-boxattack.Before discussing these attacks,we provide a formal definition of a training procedure for a machine learning model.Let us consider a target machine learning modelfis trained over input pair(X,y)from the data distributionμwith a randomized training proceduretrainhaving randomnessr(e.g.random weight initialization,dropout etc.).The model parametersθare learnt after the training procedure.More formally,we can write
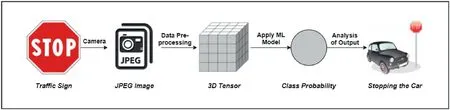
FI GUR E 3 Generic pipeline of an automated vehicle system

Now,let us understand the capabilities of the white-box and black-box adversaries with respect to this definition.An overview of the different threat models has been shown in Figure 4
White-boxattacks
In white-box attack on a machine learning model,an adversary has total knowledge about the model(f)used for classification(e.g.type of neural network along with number of layers).The attacker has information about the algorithm(train)used in training(e.g.gradient-descent optimization)and can access the training data distribution(μ).He also knows the parameters(θ)of the fully trained model architecture.The adversary utilizes this information to analyse the feature space where the model might be vulnerable,that is,for which the modelhas a high error rate.Then the modelis exploited by altering an input using adversarial example crafting method,which we discuss later.The access to internalmodelweights for a white-box attack corresponds to a very strong adversarial attack.
Black-boxattacks
Black-box attack,on the contrary,assumes no knowledge about the modeland uses information about the settings and prior inputs to exploit the model.‘For example,in an oracle attack,the adversary explores a modelby providing a series of carefully crafted inputs and observing outputs’[31].Black-box attacks are further subdivided into the following categories:
1.Non-adaptiveblack-boxattack:For a target model(f),a non-adaptive black-box adversary can only access the model’s training data distribution(μ).The adversary then chooses a proceduretrain′for a modelarchitecturef′and trains a localmodel over samples from the data distributionμto approximate the model learned by the target classifier.The adversary crafts adversarial examples on the local modelf′using white-box attack strategies and applies these crafted inputs to the target model to force misclassifications.
2.Adaptiveblack-boxattack:For a target model(f),an adaptive black-box adversary does not have any information regarding the training process,but can access the target modelas an oracle.This strategy is analogous to chosenplaintext attack in cryptography.The adversary issues adaptive oracle queries to the target model and labels a carefully selected dataset,that is,for any arbitrarily chosenx,the adversary obtains its labelyby querying the target modelf.The adversary then chooses a proceduretrain′and modelarchitecturef′to train a surrogate modelover tuples(x,y)obtained from querying the target model.The surrogate model then produces adversarial samples by following white-box attack technique for forcing the target modelto mis-classify malicious data.
3.Strictblack-boxattack:A black-box adversary sometimes may not contain the data distributionμbut has the ability to collect the input–output pairs(x,y)from the target classifier.However,he cannot change the inputs to observe the changes in output like an adaptive attack procedure.This strategy is analogous to the known-plaintext attack in cryptography and would most likely to be successful for a large set of input–output pairs.
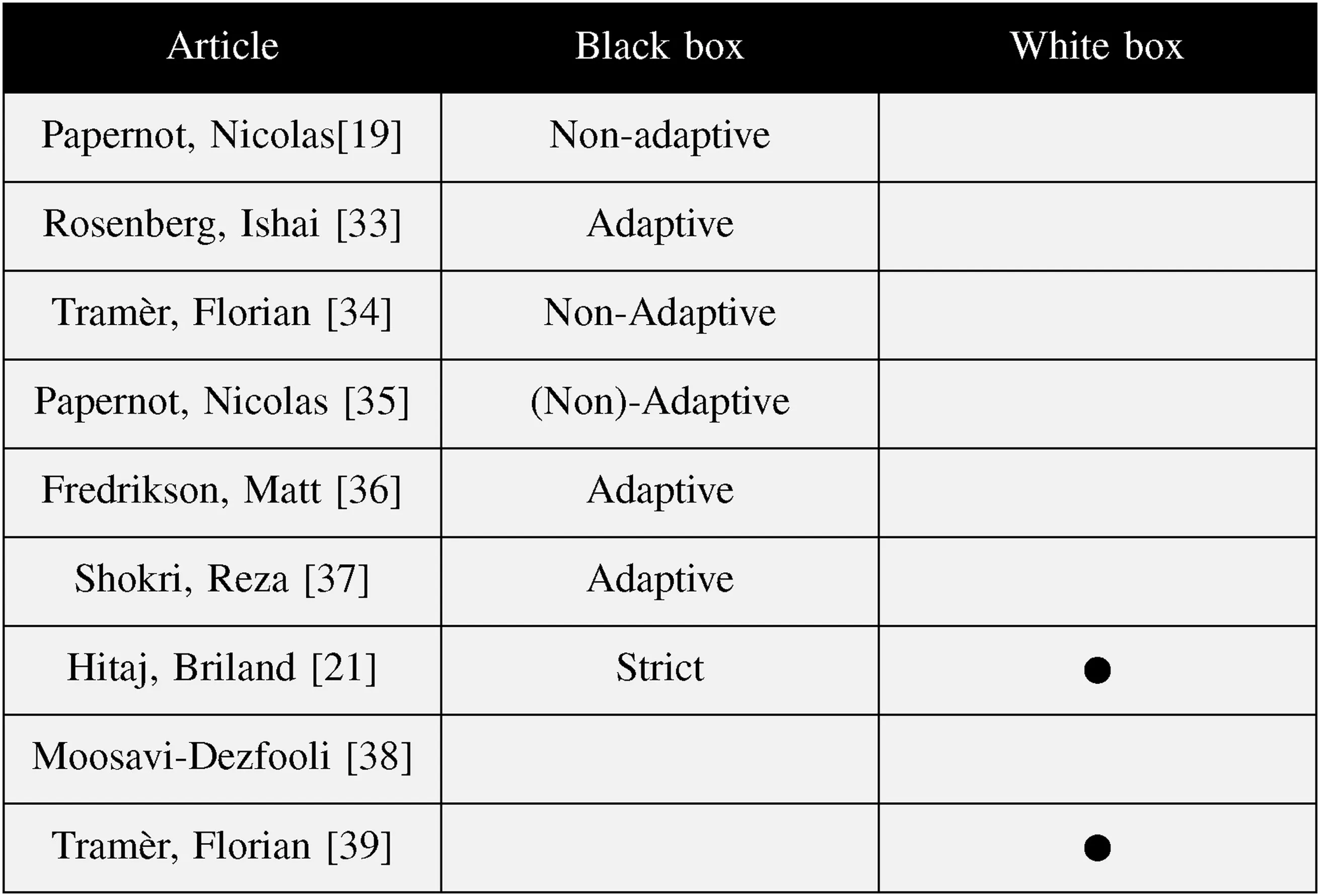
FI GUR E 4 Overview of threat models in relevant articles[19,21,33–39]
The point to be remembered in the black-box attack framework is that an adversary neither tries to learn the randomnessrused to train the target model nor the target model’s parametersθ.The primary objective of a black-box adversary is to train a local model with the data distributionμin case of a non-adaptive attack and with carefully selected dataset by querying the target model in case of an adaptive attack.Table 1 shows a brief distinction between black-box and white-box attacks.
The adversarial threat model not only depends on the adversarial capabilities but also on the action taken by the adversary.In the next subsection,we discuss the goal of an adversary while compromising the security of any machine learning system.
2.2.3 |Adversarial goals
An adversary attempts to provide an inputx*to a classification system such that it produces an incorrect output.The objective of the adversary is inferred from the incorrectness of the model.Based on the impact on the classifier output integrity,the adversarial goals can be broadly classified as follows:
1.Confidencereduction:The adversary tries to reduce the confidence of prediction for the target model.For example,a legitimate image of a‘stop’sign can be predicted with a lower confidence having a lesser probability of class belongingness.
2.Mis-classification:The adversary tries to alter the output classification of an input example to some other class.For example,a legitimate image of a‘stop’sign will be predicted as any other class different from the class of stop sign.
3.Targetedmis-classification:The adversary tries to craft the inputs in such a way that the modelproduces the output of a particular target class.For example,any input image to the classification modelwill be predicted as a class of images having‘go’sign.4.Source/targetmis-classification:The adversary tries to classify a particular input source to a predefined target class.For example,the input image of‘stop’sign willbe predicted as‘go’sign by the classification model.
The taxonomy of the adversarialthreat modelfor both the evasion and the poisoning attacks with respect to the adversarial capabilities and adversarialgoals is represented graphically in Figure 5.The horizontal axis of both figures represents the complexity of adversarialgoals in increasing order,and the vertical axis loosely represents the strength of an adversary in decreasing order.The diagonal axis represents the complexity of a successful attack based on the adversarial capabilities and goals.
Some of the noteworthy attacks along with their target applications is shown in Table 2.The overall architecture of the attack threat model has been categorized in Table 3.Further in Table 4,we categorize those attacks underdifferent threat models and discuss in detail about them in the next section.

TABL E 1 Distinction between black-box and white-box attacks
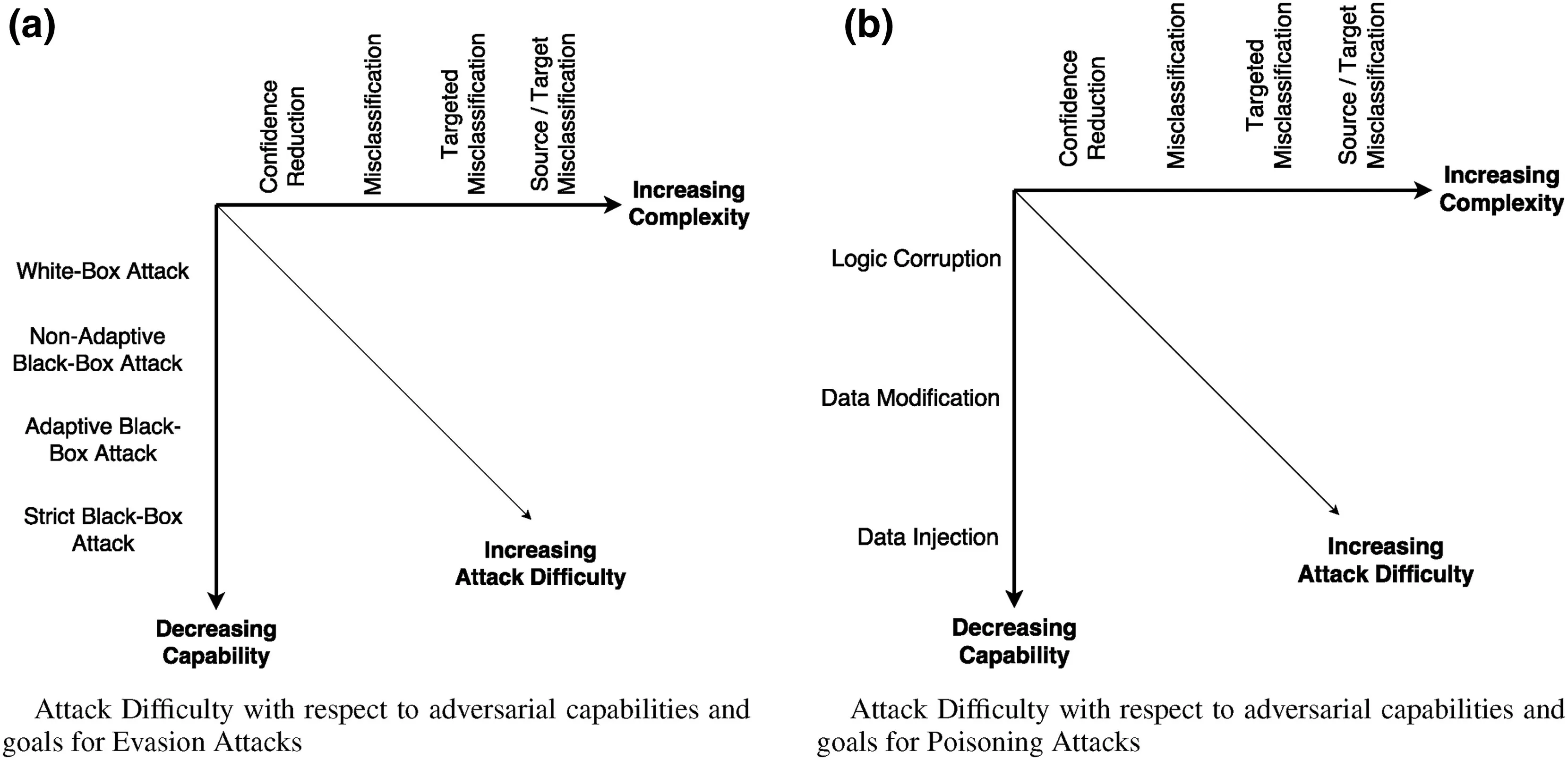
FI GUR E 5 Taxonomy of adversarial model for(a)evasion attacks and(b)poisoning attacks with respect to adversarialcapabilities and goals
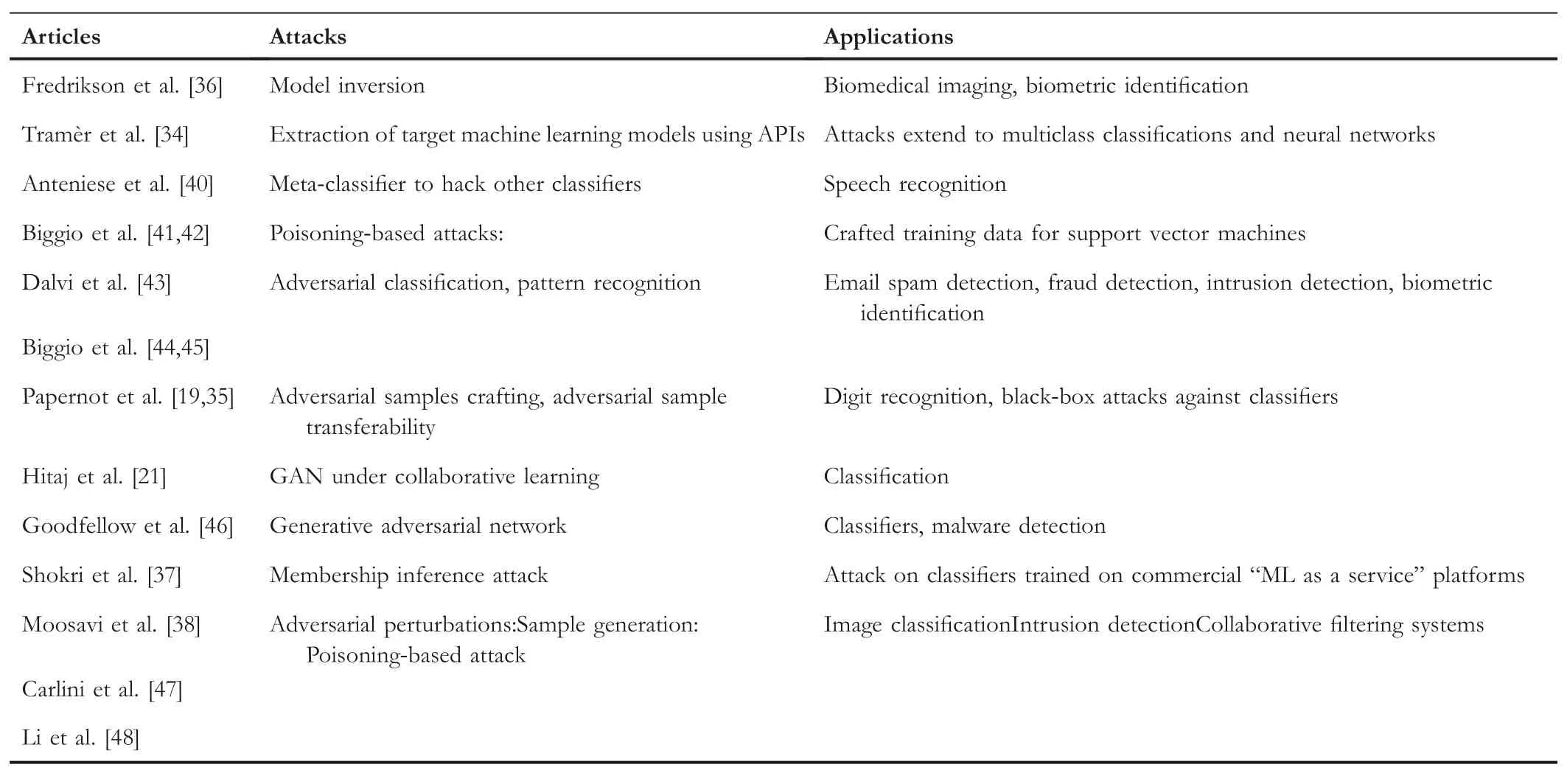
TABL E 2 Overview of attacks and applications
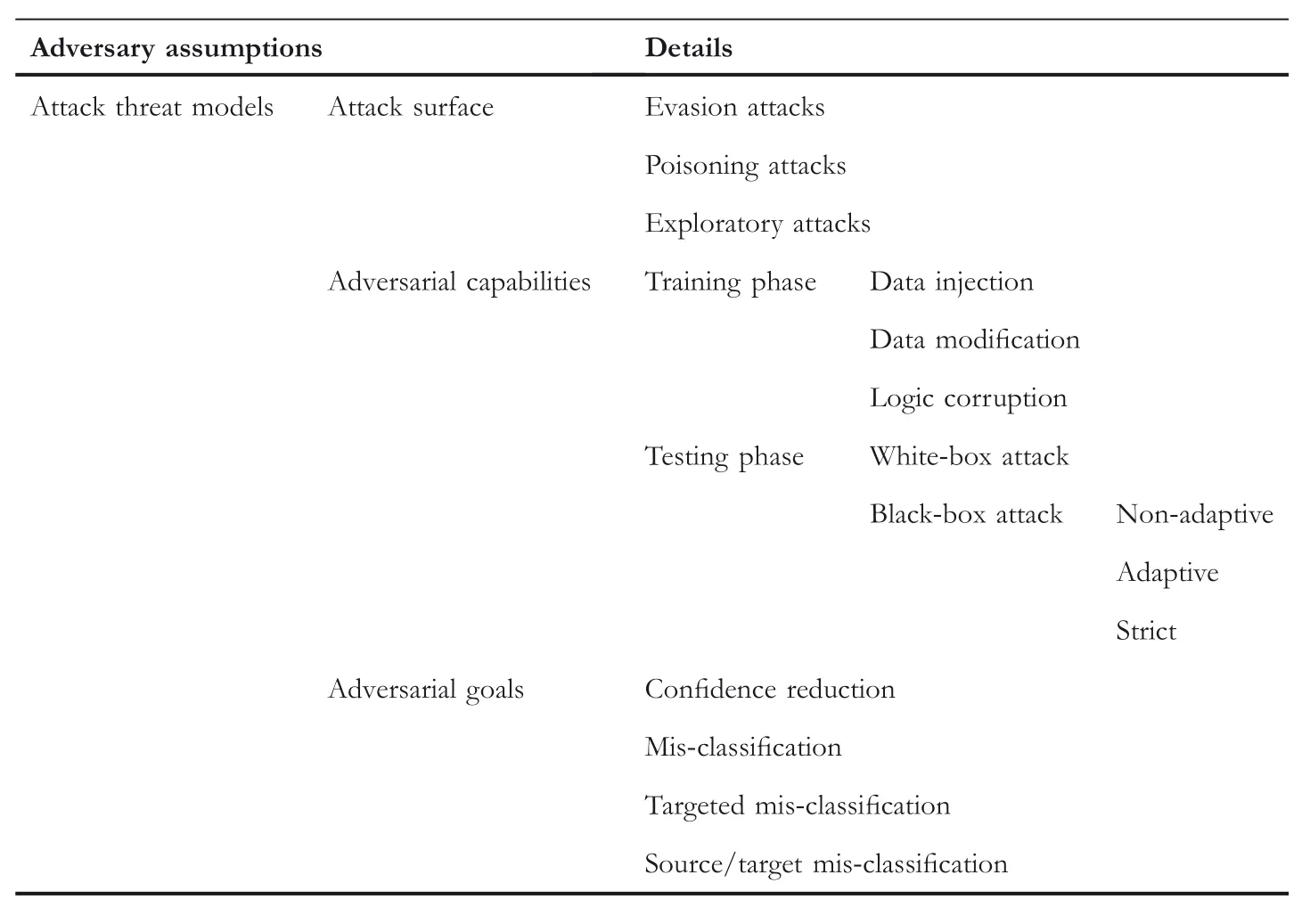
TABL E 3 Classification of differentattacks based on the attack threat model
3|EXPLORATORY ATTACKS
Exploratory attacks do not modify the training set but instead try to gain information about the state by probing the learner.The adversarial examples are crafted in such a way that the learner passes them as legitimate examples during the testing phase.
3.1 |Model inversion attack
Fredrikson et al.introduced‘model inversion’(MI)in[49]where they used a linear regression modelffor predicting drug dosage using patient information,medical history and genetic markers;explored the model as a white box and an instance of dataand try to infer genetic markerx1.The algorithm produces‘least-biased maximum a posteriori(MAP)estimate’forx1by iterating over all possible values of nominalfeature(x1)for obtaining target valuey,thus minimizing adversary’s mis-predictionrate.It has serious limitations;for example,it cannot handle larger set of unknown features since it is computationally not feasible.
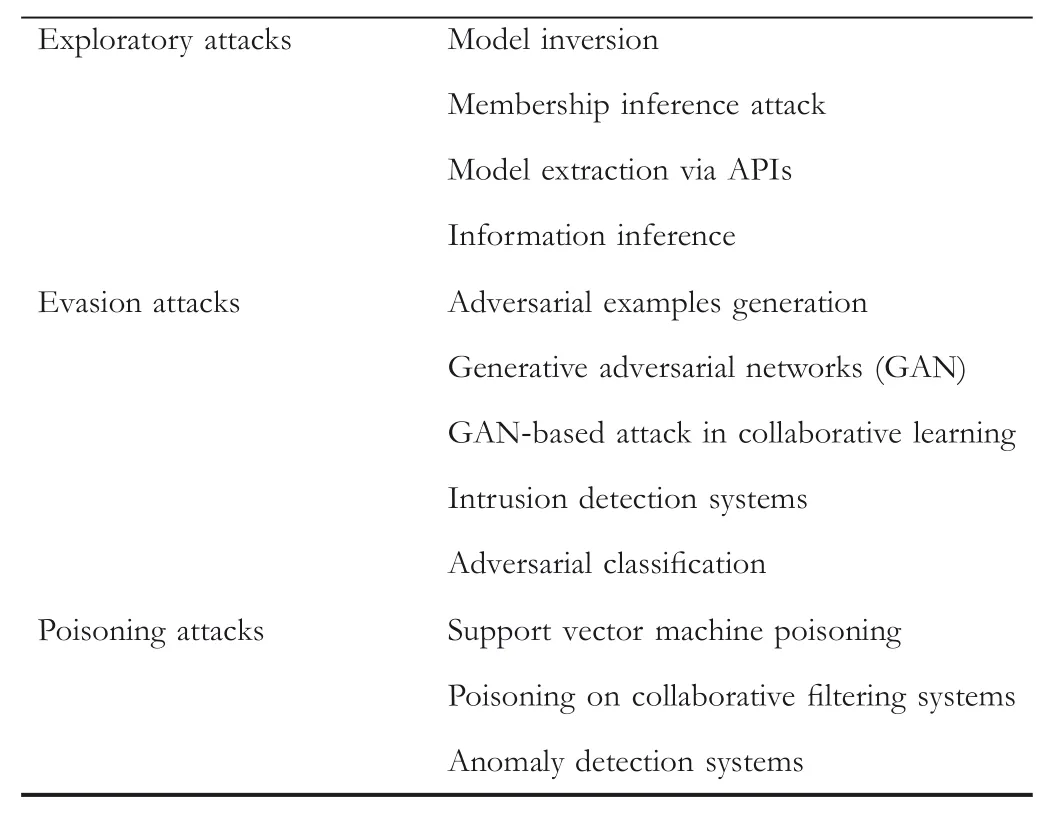
TABL E 4 Attack summary
Fredrikson et al.[36]intended to remove limitations of their previous work and showed that patient’s genetic markers can be predicted by an attacker in a black-box environment.This new MI attack through Machine Learning(ML)APIs that exploit confidence values in a variety of settings and explored countermeasures in both blackbox and white-box settings.This attack has been successfully experimented in face recognition using neural network models:multilayer perceptron(MLP),softmax regression and stacked denoising autoencoder network(DAE);given access to the model and person’s name,it can recover the facial image.Figure 6 illustrates the reconstruction produced by the three algorithms.Due to the convoluted structure of DNN model,MI attacks cannot retrieve more than some prototypical samples which might not have great similarity with the original data that was used to define that class.
3.2 |Model extraction using APIs
Tramèr et al.[34]presented simple attack scenario using which an adversary can extract information about target machine learning models such as decision trees,regression and neural networks.These attacks are strict black-box attacks which could develop localmodels having close functionality to target model.The authors demonstrated model extraction attack on online ML service providers such as Amazon Machine Learning and BigM.Machine learning APIs provided by MLas-service providers return probability values along with class labels.Since the attacker does not have any information regarding the model or training data distribution,he can attempt to solve mathematically for unknown parameters or features given the confidence value and equations by queringd+1 randomd-dimensional inputs for unknownd+1 parameters.

F I GURE 6 Reconstruction of the individual on the left by Softmax,multilayer perceptron and denoising autoencoder network(Image credit:Fredrikson et al.[36])
3.3 |Inference attack
Ateniese et al.[40]elaborated on gathering relevant information from machine learning classifiers using a meta-classifier.Given the black-box access to a model(e.g.via public APIs)and a training data,an attacker may be interested in knowing whether that data was part of the training set of the model.They experimented with a speech recognition classifier that uses hidden Markov models and extracted information such as accent of the users which was not supposed to be explicitly captured.
Another inference attack presented by Shokri et al.[37]is membership inference attack,which determines if a data point belongs to the same distribution as the training dataset.This attack may fall under the category of non-adaptive or adaptive black-box attacks.In a typical black-box environment,the attacker uses a datapoint to query the target model and obtains its output which is a vector of probabilities that specifies whether the data point belongs to a certain class.For training the attack model,a set of shadow models is built.Since the adversary has the knowledge of whether a given record belongs to the training set or not,supervised learning can be employed and the corresponding output labels are then fed to attack model to train it to distinguish shadow model’s outputs.
Figure 7 illustrates the end-to-end attack process.The output vectors obtained from shadow modelare added to the training dataset of the attack model.The shadow modelis also queried using a test dataset and added to the training dataset of the attack model.Thus a collection of target attack models is trained by utilizing the black-box behaviour of the shadow models.The authors used membership attacks on classification models trained by commercialplayers like Amazon and Google who provide‘ML as a service’.
4|EVASION AND POISONING ATTACKS
Evasion attacks are the most common attacks on machine learning systems.Malicious inputs are craftily modified so as to force the modelto make a false prediction and evade detection.Poisoning attack differs in that the inputs are modified during training and the model is trained on contaminated inputs to obtain the desired output.
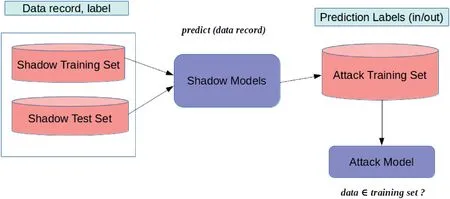
FI GUR E 7 Overview of membership inference attack
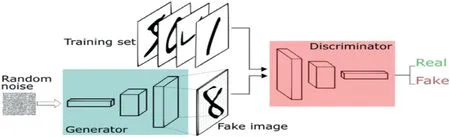
FI GUR E 8 Generative adversarial learning(Image credit:Thalles Silva[50])
4.1|Generative adversarial attack
Goodfellow et al.portrayed GAN[46]as a game between two learning networks:one generates samples similar to the training set,having almost identical distribution,and the other discriminates between original and crafted training sample.The GAN procedure,as depicted in Figure 8,is composed of a DNNG,known as Generator and another DNND,known as Discriminator.Formally,Gis trained to maximize the probability ofDmaking a mistake.This competition leads both the models to improve their accuracy.The procedure ends whenDfails to distinguish between originaltraining samples and those generated byG.The entities and adversaries are in a constant duel where one‘(generator)tries to fool the other(discriminator)’,while the other tries to prevent being fooled.
The authors(Goodfellow et al.[46])defined the value functionV(G,D)as
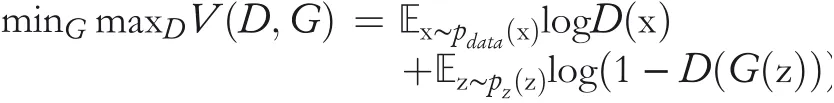
wherepg(x)is the generator’s distribution andpz(z)is a prior on input noise[46].The objective is to trainDsuch that it maximizes the probability to assign correct labels to sample examples,while simultaneously trainingGto minimize it.It was found that optimizingDwas computationally intensive and on finite datasets,there was a chance of overfitting.Moreover,during the initial stages of learning forG,Dcan discriminate crafted samples byGwith relatively high confidence and rejects them.So,instead of trainingGto minimize log(1-D(G(z)),they trainedGto maximize log(D(G(z)).
Radford et al.[51]introduced deep convolutional generative adversarial networks(DCGANs)which overcome these constraints in GANs and make them stable to train.Some of the key insights of DCGAN architecture were as follows:
·The overall network architecture was based on all convolutionalnet[52]replacing deterministic pooling functions with strided convolutions.
·A random noisezwas introduced as input to the first layer.The result thus obtained was transformed into a 4D tensor.The last layer was transformed into a vector and fed into a single sigmoid output(Figure 9).[53]
·They used batch normalization[54]to stabilize the learning.They normalized the input to achieve zero mean and unit variance.This solved the problem of instability of GAN during training which arise due to poor initialization.
·For generator,ReLU activation[55]was used in all layers for the output layer,whereas Leaky ReLU activation[56,57]was used for alllayers in discriminator.
4.2 |Adversarial examples generation
In this section,we present an overview for adversarial sample modification that can be performed both in training and testing phases,so that a classification modelyields an adversarialoutput.
4.2.1 |Training phase modification
A learning process fine-tunes the parametersθof the hypothesishby analysing a training set.This makes the training set susceptible to manipulation by adversaries.Barreno et al.[26]first coined the termPoisoningAttacks;training dataset is manipulated(‘poisoned’)with the intention of altering decision boundary characteristics of the target model following the work of Kearns et al.[58],thus challenging the learning system’s integrity.The poisoning attack of the training set can be done in two ways:either by direct modification of the labels of the training data or by manipulating the input features depending on the capabilities posed by the adversary.We present a brief overview of both the techniques without much technical details,as the training phase attack needs more powerful adversary and thus is not common in general.
·Labelmanipulation:If the adversary has the capability to modify the training labels only,then he must obtain the most vulnerable labelgiven the fullor partial knowledge of the learning model.A basic approach is to do perturbations of the labels randomly,that is,selecting new labels drawn from a random distribution for a subset of training data.It was shown that a random flip of 40%of the training labels can significantly reduce the performance of the SVM classifiers[41].
·Inputmanipulation:In this scenario,the adversary is more powerfuland can modify both the labels and input features of the training data with knowledge of the learning algorithm to effectively train the model on poisoned data.
Kloft et al.[59]presented a study in which they showed that the decision boundary of an anomaly detection classifier could be gradually shifted by inserting malicious points in the training dataset.The learning algorithm they used works in an online fashion.The parameter values of the learning algorithm are fine-tuned based on a sample of that training data which are collected at regular intervals in online learning scenario.Thus,injecting new points in the training dataset is essentially an easy task for the adversary.Poisoning data points can be obtained by solving a linear programming problem with the objective of maximizing displacement of the training data’s mean.
In offline learning scenario,Biggio et al.[42]presented an attack scenario in which an adversary uses gradient ascent algorithm to craft inputs into training dataset that corresponds to local maxima error.The study shows that insertion of these crafted inputs into the training set degrades inference accuracy for SVM classifier on test data.Following their approach,a generic framework for poisoning was proposed[60]as an optimization problem to find optimal change to the training set sufficient for adversarialclassification if the loss function used in targeted learning model is convex and it’s input domain is continuous.
4.2.2 |Testing phase generation
·White-box attacks:In this subsection,we precisely discuss how adversaries craft adversarialsamples in a white-box setup.Papernot et al.[23]introduced a general framework which builds on the attack approaches discussed in recent literature.The framework is split into two phases:(a)directionsensitivityestimationand(b)perturbationselectionas shown in Figure 10.The figure proposes an adversarial example crafting process for an image classification using DNN,which can be generalized for any supervised learning algorithm.
SupposeXis an input sample,andFis a trained DNN classification model.The objective of an adversary is to selectively add a perturbationδXwith the sampleX,thereby generating a malicious exampleX*=X+δX,so thatF(X*)=Y*,whereY*≠F(X)is the target output which depends on the objective of the adversary.An adversary begins with a legitimate sampleX.Since the attack setting is a white-box attack,an adversary can access parametersθFof the target modelF.The adversary employs a two-step process for the adversarial sample crafting,which is discussed below:
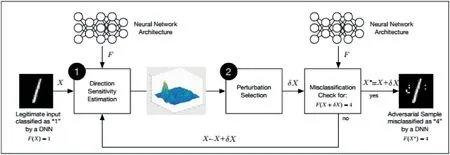
FI GUR E 1 0 Adversarialexample crafting framework for evasion attacks(Image credit:Papernot et al.[23])
1.Directionsensitivityestimation:The adversary evaluates and estimates the variability of output on input feature vectors on how a modelresponds to change in input feature by identifying directions in input space around vicinity of sampleX.
2.Perturbationselection:The adversary then exploits the knowledge of sensitive information to choose a perturbationδXin order to obtain an adversarialperturbation which is most efficient.
The adversary may repeat both the steps by substitutingXbyX+δXat each iteration untilhis goalis satisfied such that the sum of perturbation used for craftingX*from a valid example needs to be as minimum as possible.This helps the adversarial samples to remain imperceptible to human eye.
It becomes insignificant to use large perturbations to craft adversarial samples.Thus,it is better to define appropriate norm‖.‖to denote the difference between two input points,so as to formalize adversarial samples‘as a solution to the following optimization problem’[23]:
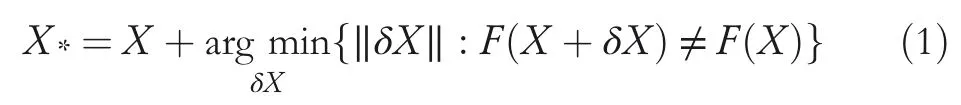
In most cases,it becomes hard to find a closed solution to the above problem because of its non-linear and non-convex nature.The authors have described different techniques to devise an attack approximating the solution using both the steps.
Directionsensitivityestimation
In this step,the adversary takes a sampleX,ann-dimensional input vector,and tries to find out the dimensions for which the model behaves as expected by the adversary,with as little perturbation as possible.This can be achieved by changing the input components ofXand evaluating the sensitivity of the model for these changes.There are a number of techniques to evaluate the sensitivity of a model,some of which are discussed below.
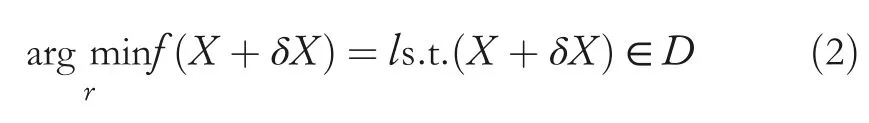
1.L-BFGS:In 2014,Szegedy et al.[14]were the first to formalize the following minimization problem as the search for adversarial examples.Formally,Equation(2)findsδXsuch that the input exampleXalthough accurately labelled byf,if perturbed withδXresults adversarial exampleX*=X+δXandX*still belongs to the input domainD,it is assigned the target labell≠h(X).For non-convex models like DNN,the authors used theL-BFGS[61]optimization to solve Equation(2).Though the method gives good performance,it is computationally expensive while calculating adversarial samples.
2.Fastgradientsignmethod(FGSM):An efficient solution to Equation(1)is introduced by Goodfellow et al.[18].They proposed an FGSM which calculates perturbation to input data in a single step using the gradient of the loss(cost)function with respect to the input data with the objective to maximize the loss.The adversarial examples are produced using the following equation:
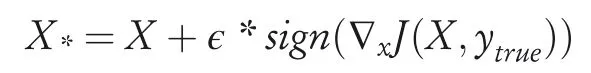
Here,Jis the cost function of the trained model,∇xdenotes the gradient of the model with respect to a normal sampleXwith correct labelytrue,andϵdenotes the input variation parameter which controls the perturbation’s amplitude.Recent literature has used some other variations of FGSM,which are summarized as follows:
(a)Targetclassmethod:This variant of FGSM [17]approach maximizes the probability of some specific target classytarget,which is unlikely the true class for a given example.The adversarial example is crafted using the following equation:
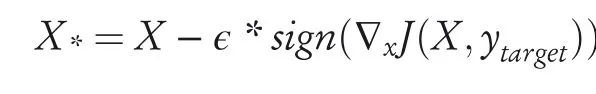
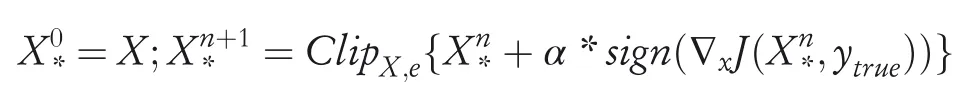
(b)Basic iterative method:This is a straightforward extension of the basic FGSM method[17].This method generates adversarial samples iteratively using small step size:Here,αis the step size andClipX,e{A}denotes the element-wise clipping ofX.The range ofAi,jafter clipping belongs in the interval[Xi,j-ϵ,Xi,j+ϵ].This method does not typically rely on any approximation of the model and produces additional harmfuladversarialexamples when run for more iterations.
3.Jacobian-basedmethod:Papernot et al.[62]introduced a different approach for finding sensitivity direction by using forward derivative,by using Jacobian of the trained model.This method provides gradients of the output features corresponding to each input feature.The knowledge thus obtained is used to craft adversarialsamples using a complex saliency map approach which we will discuss later.This method is particularly useful for source–target misclassification attacks.
Perturbationselection
After gaining knowledge about the network sensitivity,the adversary will try to determine the dimensions for which the target model will generate misclassification with smallest of perturbations.The perturbed input dimensions can be of two types:
1.Perturballtheinputdimensions:Goodfellow et al.[18]proposed using FGSM to compute cost function gradient with respect to input dimenisons and perturb every input dimensions but with a minuscule amount in the direction of the sign of the gradient.FGSM method efficiently minimizes the loss computed as distance between the adversarial and the original training samples.
2.Perturbaselectedinputdimensions:Papernot et al.[62]used saliency map to perturb a finite number of input dimension.The objective of using saliency map is to assign values to the combination of input dimensions which indicates whether the combination if perturbed,will contribute to the adversarial goals.This method effectively reduces the number of input features perturbed while crafting adversarial examples.Given all the dimensions sorted in decreasing order of adversarial saliency value,the perturbations can be crafted by choosing input dimension in order.The saliency valueS(x,t)[i]of a componentiof a legitimate examplexfor a target classtis evaluated using the following equation:
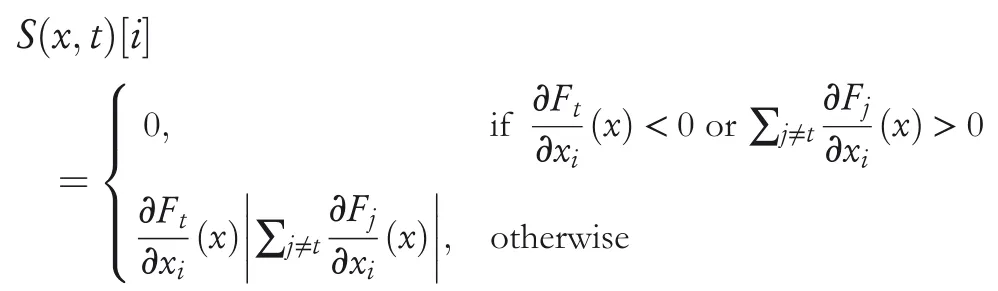
Each method has its own advantages and drawbacks.The first method can generate adversarial samples relatively faster but with high perturbations making them easier to detect.The second method actually reduces the perturbations but it is computationally intensive.
·Black-boxattacks:In this subsection,we discuss in details on the generation of adversarial examples in a black-box setting.Crafting adversarial samples in non-adaptive and strict black-box scenario is straightforward.In both the cases,the adversary has access to a vast dataset to train a local substitute model which approximates the decision boundary of the target model.Once the local model is trained with high confidence,any of the white-box attack strategies can be applied on the local model to generate adversarial examples,which eventually can be used to deceive the target model because of the“Transferability Property”[19](will be discussed later).However,in an adaptive black-box setting,the adversary cannot access a large dataset and thus augments a partial or randomly selected dataset by selectively querying the target model as an oracle.One of the popular methods of dataset augmentation presented by Papernot et al.[35]is discussed next.
Jacobian-baseddataaugmentation
Although an adversary can make unlimited queries to an Oracle to obtain its output for any given input,the process is not amenable considering the continuous domain of an input to be queried,and the system might also detect the abnormal behaviour of the adversary.An alternative can be to heuristically generate adversarial inputs in the direction along which the model’s output is varying,given the original training set.With more input–output pairs,the direction can be captured easily for a target OracleO.Hence,the greedy heuristic that an adversary follows is to prioritize the samples while querying the oracle for labels to get a substitute DNNFhaving decision boundary identical to that of the Oracle.The decision boundary can be determined by evaluating the sign the Jacobian matrixJfof the substitute DNNwherexis the input label.The originaldatapointxis augmented with the termλ*sgnJF(x)[O(x)]( )to generate the‘new synthetic training point’[35].The iterative data augmentation technique can be summarized using the following equation:
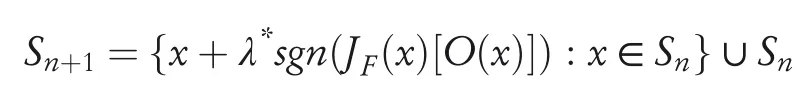
whereSnis the dataset at thenth step andSn+1is the augmented dataset.The substitute model training following this approach is presented in Figure 11.
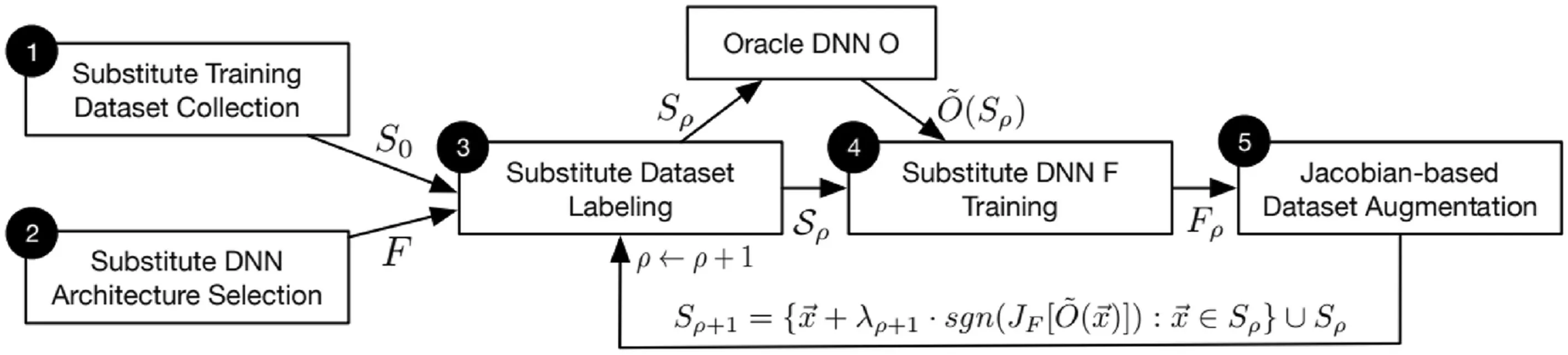
FI GUR E 1 1 Substitute mode training using Jacobian-based data augmentation(Image credit:Papernot et al.[35])
4.2.3 |Transferability of adversarial samples
Adversarial samples have a property where the samples produced to deceive a particular model can be used to deceive other models,irrespective of their underlying architectures—leading to adaptive black-box attacks as discussed in Section 2.2.2.This property is known as‘Transferability of Adversarial Samples’[19].Since in the case of black-box attack,an adversary cannot access the target modelF,he can train asubstitutemodelF′locally to generate adversarial exampleX+δXwhich then can be transfered to the victim model.Formally,ifXis the original input,the transferability problem can be represented as an optimization problem(1).
It can be broadly classified into two types:
1.Intra-techniquetransferability:Both the modelsFandF′are trained using similar machine learning technique(e.g.both are NN or SVM)
2.Cross-techniquetransferability:If learning technique inFandF′are different,for example,one is an NN and the other one SVM.
This substitute model in effect transfers knowledgecrafting adversarial inputs to the victim model.Owing to the limited capability of the adversary to query the target model for outputs given a number of datapoints,the model can be considered as an oracle.To train the substitute model,dataset augmentation as discussed above is used to capture more information about the predicted outputs.The authors also introduced‘reservoir sampling to select a limited number of new inputsKwhen performing Jacobianbased dataset augmentation’[19].It reduces the number of queries made to the oracle.However,the choice of substitution model architecture does not affect the transferability property.
The attacks have been shown to generalize to nondifferentiable target models,for example,logistic regression(LR)and DNNs(differentiable models)‘could both effectively be used to learn a substitute modelfor many classifiers’trained with a SVM,decision tree,DNN and nearest neighbour.The amount of knowledge of the classifier required by the adversary to force a mis-classification of skilfully crafted inputs is greatly reduced by the cross-technique transferability.Learning substitute model alleviates the need of attacks to infer architecture,learning model and parameters in a typical blackbox-based attack.
4.3 |GAN-based attack in collaborative deep learning
Hitajet al.[21]presented a GAN-based attack to extract information during training phase from‘honest victims in a collaborative deep learning framework’.GAN tends to produce samples identical to those in the training set without having access to the original training set.In a typicalwhite-box setting,the motive of the adversary is to extract tangible information about the labels that do not belong to his own dataset without compromising privacy.
Figure 12 shows the proposed attack,which uses GAN to generate similar samples as that of training data in a collaborative learning setting,with limited access to shared parameters of the model.A,Vparticipates in a collaborative learning.V(the victim)chooses labels[x,y].The adversaryAalso chooses labels[y,z].Thus,while classyis common to bothAandV,Adoes not have any information aboutxand thus tries to collect maximum information possible about the classx.Auses GAN to produce instances that look similar to classxand injects them into the classifier as classz.Vfinds it hard to differentiate between the two classes(xandz)and as a result reveals a lot of information about classx.Thus by mimicking the samples,the adversary gains additionalinformation about the classes with the help of the victim himself.
The authors[21]proved that GAN attack was successful in all sets of experiments conducted juxtaposed with MI attacks,DP-based collaborative learning,and so on.‘The GAN will generate good samples as long as the discriminator is learning’.
4.4 |Adversarial classification
Dalvi et al.[43]defined adversarial classification from costsensitive game-theoretical perspective as a game between two players:Model(classifier)and an Adversary,each competing to maximize its utility.The classifier tries to learn a functionyc=C(x)from the training set which predicts the instances in the training set accurately.The adversary modifies the instances in the training data fromxtox′=A(x)and tries to force the classifier to misclassify the instances in the training data.The classifier and the adversary constantly try to defeat each other by maximizing their own pay-offs.The classifier uses a cost-sensitive Bayes learner to minimize its expected cost while assuming that the adversary always plays its optimal strategy,whereas the adversary tries to modify feature in order to minimize its own expected cost[27,63].The presence of adaptive adversaries in a system can significantly degrade the performance of the classifier,especially when the presence and type of adversary are unknown to the classifier.The objective of the classifier is to maximize its expected utility(UC),whereas the adversary would try to find an optimal feature modification strategy in order to maximize its expected utility(UA):
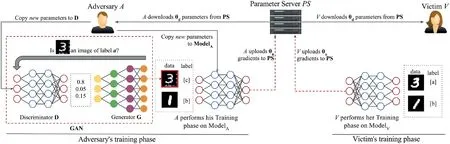
FI GUR E 1 2 Generative adversarialnetwork attack on collaborative deep learning(Image credit:Hitajet al.[21])
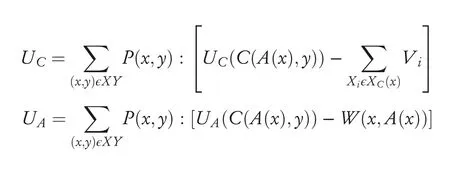
4.5 |Evasion and poisoning attack on support vector machines
SVMs are popular classifiers for detecting malwares and intrusion in a system.Owing to thestationarityproperty in SVM,that is,the same distibution should be used to sample both the training and test samples.However,in adversarial learning,an intelligent and adaptive adversary can modify data and thereby violates the stationarity in order to exploit vulnerabilities present in the learning system.
Biggio et al.[64],using gradient-descent based approach,demonstrated the evasion attack on kernel-based classifiers[65].Even if the adversary does not have any knowledge on the classifier’s decision function,it can evade the classifier by learning asurrogateclassifier.The authors considered two settings where the adversary had complete or no knowledge about feature space and classifier’s discriminant function;the adversary can‘learn asurrogateclassifier on a surrogate training set’.SVMs can be deceived with relatively high probability even if there is a little possibility that an adversary can imitate the actual modelwith the surrogate data.Formally,the optimal strategy to find a samplexcan be stated as an optimization problem with the objective of minimizing the value of classifier’s discriminant functiong(x)as in Equation(3):
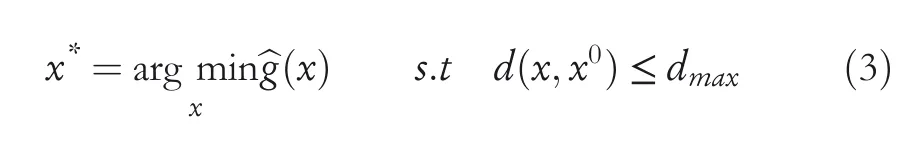
However,ifĝ(x)is non-convex,the gradient descent algorithm may lead to a local minimum outside of sample’s support.To overcome this problem,additional components were introduced into Equation(4):
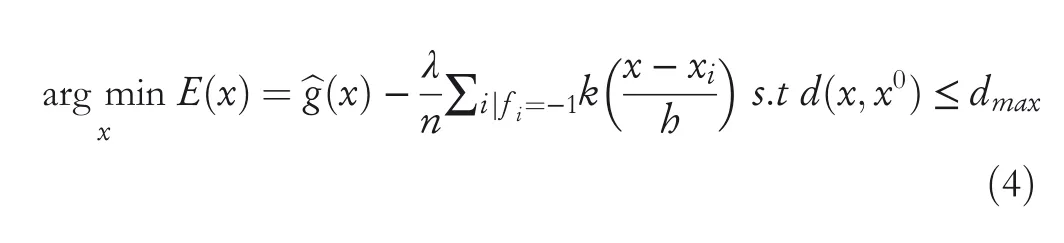
Biggio et al.[42]also demonstrated,in the form of a poisoning attack,that an adversary can force the SVMto result in a mis-classified output on test samples by manipulating training data.Although the training data was tampered to include well-crafted attack samples,it was assumed that there was no manipulation of test data.In order the attack to happen,the adversary intends to find a set of points and adding those to the training dataset which decreases SVM’s classification accuracy at most.It is difficult in real-world scenarios to have a complete knowledge of the training dataset,but obtaining asurrogatedataset having a distribution which is the same as the actual training dataset may not be difficult for the attacker.Under these assumptions,the optimal attack strategy is as follows:
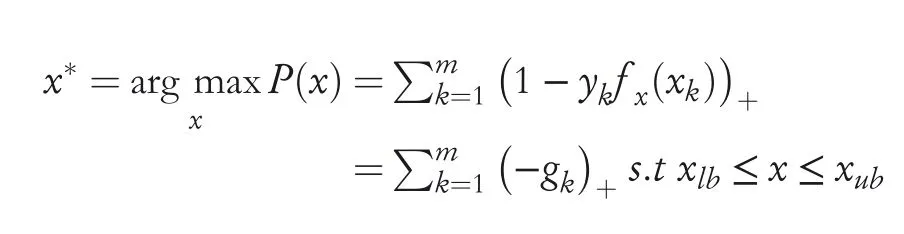
Another class of attacks on SVM,called privacy attack,presented by Rubinstein et al[66],is based on the attempt to breach the confidentiality of training data.The ultimate goal of the adversary is to obtain features and labels of each training instance individually by trying to inspect classification results obtained from the classifier for test data or by directly inspecting the classifier.
4.6 |Poisoning attacks on collaborative systems
Recommendation and collaborating filtering systems play a crucial role in the business strategies of modern e-commerce systems.Bo Li et al.[48]demonstrated poisoning attacks on collaborative filtering systems where an attacker can generate malicious data to degrade the effectiveness of the system if he has the complete knowledge of the learner.The two most popular algorithms used for factorization-based collaborative filtering are alternating minimization[67]and nuclear norm minimization[68].The data matrixMfor the former one can be determined by solving the optimization problem as mentioned below:
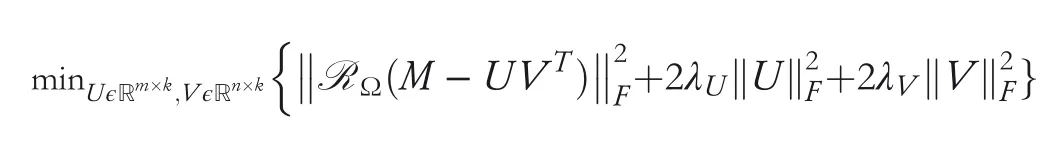
Alternatively,the latter one can be solved as follows:
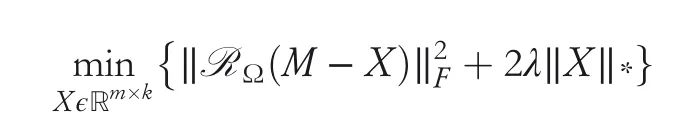
whereλ> 0 controls regularization andis the nuclear form ofX.Based on these problems,Bo Liet al.[48]listed the three types of attacks and their utility functions:
·Availabilityattack:In this attack model,the attacker tries to maximize error obtained from the collaborative filtering system thereby making it unreliable and useless.The utility function can be characterized as a quantity of perturbations of predicted value between(prediction without data poisoning)and(prediction after poisoning)on unseen entriesΩC
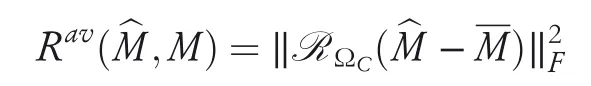
·Integrityattack:The objective of the adversary is to manipulate the popularity of a subset of items.Thus,ifJ0⊆[n]is the subset of items andw:J0→R is a pre-defined weight vector,then we define the utility function by

·Hybridattack:It is a combination of the above two models,defined by the function
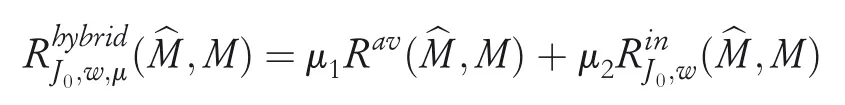
whereμ=(μ1,μ2)are the coefficients that provide the trade-off between availability and integrity attacks.
4.7 |Adversarial attacks on anomaly detection systems
Anomaly detection is referred to the detection of events that do not conform to an expected pattern or behaviour.Kloft et al.[59]analysed the behaviour of‘online centroid anomaly detection systems’as data poisoning attack.To detect anomaly for a test examplexand a given datasetX,it flagsxas outlier if it lies in a region of low density compared with the probability density function of sample spaceX.The authors usedfinite slidingwindowof training data where,as every new data point arrives,the centre of mass changes by
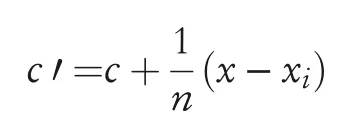
As illustrated in Figure 13,with prior knowledge of algorithm and training dataset,the adversary will try to force the anomaly detection algorithm to accept an attack pointAwhich lies outside the solid circle,that is,‖A-c‖>r.
5|ADVANCES IN DEFENSE STRATEGIES
Adversarialexamples demonstrate that many modern machine learning algorithms can be broken easily in surprising ways.A substantial amount of research to provide a practical defense against these adversarial examples can be found in recent literature.In this section,we will briefly discuss about the recent advancements and the challenges.These adversarial examples are difficult to defend because of the following reasons[69]:
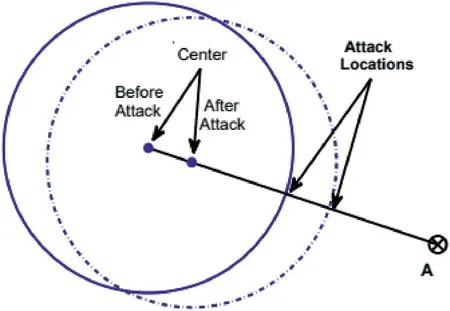
F I GURE 1 3 Illustration of poisoning attack(Image credit:Kloft et al.[59])
1.Atheoreticalmodeloftheadversarialexamplecrafting processisverydifficulttoconstruct.The adversarialsample generation is a complex optimization process due to its non-linearity and non-convex properties for most machine learning models.The lack of proper theoretical tools to describe the solution to these complex optimization problems makes it even harder to make any theoreticalargument that a particular defense will rule out a set of adversarial examples.
2.Machinelearningmodelsarerequiredtoprovideproper outputsforeverypossibleinput.A considerable modification of the model to incorporate robustness against the adversarial examples may change the elementary objective of the model.
Most of the current defense strategies are not adaptive to all types of adversarial attack as one method may block one kind of attack but leaves another vulnerability open to an attacker who knows the underlying defense mechanism.Moreover,implementation of such defense strategies may incur performance overhead,and can also degrade the prediction accuracy of the actualmodel.
The existing defense mechanisms can be categorized based on their methods of implementation into the following types.
5.1 |Adversarial training
The primary objective of the adversarial training is to increase model robustness by injecting adversarial examples into the training set[14,18,70,71].Adversarial training is a standard brute force approach where the defender simply generates a lot of adversarial examples and augments these perturbed data while training the targeted model.The augmentation can be done either by feeding the model with both the legitimate data and the crafted data,presented in[17]or by learning with a modified objective function withJbeing the original loss function,given by[18]:
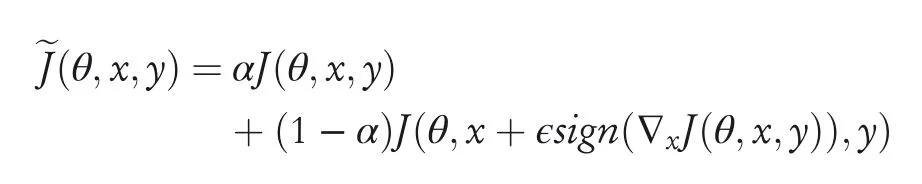
The model will predict the same class for both the legitimate as well as perturbed examples in the same direction thereby increasing the model robustness.Traditionally,the additional instances are crafted using one or multiple attack methodologies mentioned in Section 4.2.2.
Adversarial training implies training on adversarial samples which are crafted on the original model.The defense is not robust for black-box attacks[35,72]where an adversary generates malicious examples on a locally trained substitute model.Moreover,Tramèr et al.[39]have already proved that the adversarial training can be easily bypassed through a two-step attack,where random perturbations are applied to an instance first and then any traditional attack is performed on it,as mentioned in Section 4.2.2.
5.2 |Gradient hiding
A natural defense against gradient-based attacks presented in[39]and attacks using adversarial crafting method such as FGSM,could consist in hiding information about the model’s gradient from the adversary.For instance,if the modelis nondifferentiable(e.g.a decision tree,a nearest neighbour classifier or a random forest),gradient-based attacks are rendered ineffective.However,this defense is easily fooled by learning a surrogate black-box model having gradient and crafting examples using it[35].
5.3 |Defensive distillation
Papernot et al.[23,73]showed that distillation[22]can be used as a adversarial training technique so that the model is less susceptible to adversarialinputs.
The two-step working model and the distillation method are described as below.A neural networkFis trained to classify input samplesXto‘hard labels’and‘soft labels’Y,that is,the final softmax layer produces a probability distribution overY.Then,‘soft labels’output ofFis fed as input to second neural networkF′with the same architecture asFon the same datasetXto achieve the same accuracy.The second‘distilled’model makes the output more smooth and robust to adversarial perturbations.
The final softmax layer in the distillation method is modified according to the following equation:
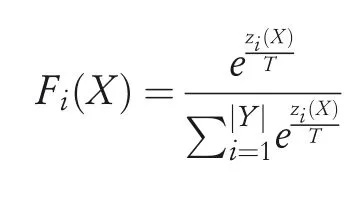
whereTis the distillation parameter called temperature.Papernot et al.[23]showed experimentally that a high empirical value ofTgives a better distillation performance.The reason for training the second model using this approach is to provide a smoother loss function,which is more generalized for an unknown dataset and have high classification accuracy even for adversarial examples.
Defensive distillation hence smoothens the model,label smoothingwhich converts class labels into soft targets.Target class label is assigned a value close to 1 while the remaining weights are distributed among other classes.These modified values are then used for training in place of true labels.As a result,training an additionalmodel for‘defensive distillation’is no longer required.The advantage of using soft targets lies in the fact that it uses probability vectors instead of hard class labels.For example,given an imageXof handwritten digits,the probability of similar looking digits will be close to one another.
However,with the recent advancement in the black-box attack,the defensive distillation method as well as the label smoothing method can easily be avoided[35,47].The main reason behind the success of these attacks is often the strong transferability of adversarial examples across neural network models.
5.4 |Feature squeezing
Feature squeezing is another modelhardening technique[74].The main idea behind this defense is that it reduces the complexity of representing the data which makes adversarial perturbations to disappear because of low sensitivity.There are mainly two heuristics behind the approach considering an image dataset:
1.Reduce the colour depth on a pixel level,that is,use fewer values to encode the colours.
2.Use of a smoothing filter over the images to map multiple inputs into same value.This makes the model resistant against noise and adversarialattacks.
Although these techniques provide a strong countermeasure against adversarial attacks,they are known to significantly worsen the accuracy of the model.
5.5 |Blocking the transferability
The main reason behind the defeat of most of the wellknown defense mechanisms is due to the strong transferability property in the neural networks,that is,adversarial examples generated on one classifier are expected to cause another classifier to perform the same mistake.The transferability property holds true irrespective of the underlying architecture of the classifiers or the datasets they were trained on.Hence,the key for protecting against a black-box attack is to block the transferability of the adversarial examples.
Hosseini et al.[75]recently proposed a three-stepNULL labellingmethod to prevent the adversarial examples to transfer from one network to another.The main idea behind the proposed approach is to augment a new NULL label in the dataset and train the classifier to reject the adversarial examples by classifying them as NULL.The basic working of the approach is shown in Figure 14.The figure illustrates the method taking as an example image from MNIST dataset,and three adversarial examples with different perturbations.The classifier assigns a probability vector to each image.The NULL labelling method assigns a higher probability to the NULL label with higher perturbation,while the original labelling without the defense increases the probabilities of other labels.
The NULL labelling method is composed of three major steps:
1.Initialtrainingofthetargetclassifier:Initial training is performed on the clean dataset to derive the decision boundaries for the classification task.
2.ComputingtheNULLprobabilities:The probability of belonging to the NULL class is then calculated using a functionffor the adversarial examples generated with different amount of perturbations:

whereδXis the perturbation andNmaxis the minimum number for whic
3.Adversarialtraining:Each clean sample is then re-trained with the original classifier along with different perturbed inputs for the sample.The label for the training data is decided based on the NULL probabilities obtained in the previous step.
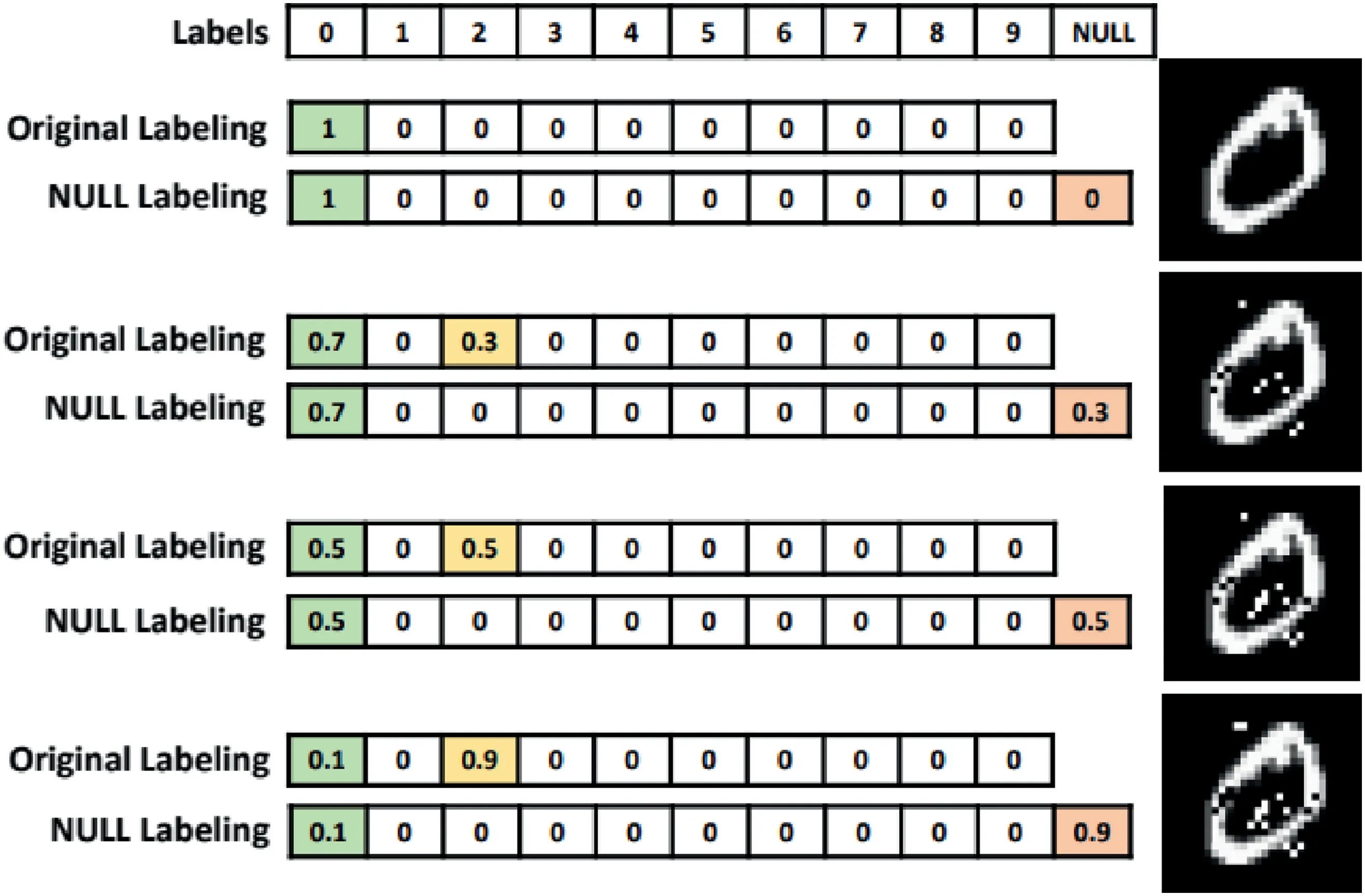
FI GUR E 1 4 Illustration of NULL labelling method(Image credit:Hosseiniet al.[75])
The advantage of this method is the labelling of the perturbed inputs to NULL label instead of classifying them into their originallabel.This method can be regarded as the most effective defense mechanism against adversarial attacks till date.This method is accurate to reject an adversarial example while not compromising the accuracy of the clean data.
5.6|Defense-GAN
Samangouei et al.[24]proposed a mechanism to leverage the power of GAN[46]to reduce the efficiency of adversarial perturbations,which works both for white-box and black-box attacks.In a typical GAN,a generative model which emulated the data distribution and a discriminative model that differentiates between originalinput and perturbed input are trained simultaneously.The central idea is to‘project’input images onto the range of the generatorGby minimizing the reconstruction error‖G(z)-x‖22,prior to feeding the imagexto the classifier.Due to this,the legitimate samples will be close to the range ofGthan the adversarial samples,resulting in substantial reduction of potential adversarial perturbations.An overview of the Defense-GAN mechanism is shown in Figure 15.
Although Defense-GAN showed to be quite effective against adversarial attacks,its success relies on the expressiveness and generative power of the GAN.Moreover,the training of GAN can be challenging,and if not properly trained,the performance of the Defense-GAN can significantly degrade.
5.7|MagNet
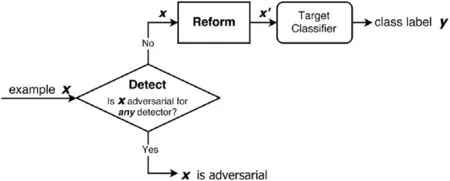
Meng et al.[76]proposed a framework,named MagNet,which uses classifier as a black box to read the output of the classifier’s last layer only without modifying the classifier and usesdetectorsto differentiate a normaland adversarialexample.The detector checks if the distance between the given test example and the manifold exceeds a threshold.It also uses areformerto reform adversarial example to a similar legitimate example using autoencoders(Figure 16).Although MagNet was successful in thwarting a range of black-box attacks,its performance degraded significantly in case of white-box attacks where the attackers are supposed to be aware of the parameters of MagNet.So,the authors came up with the idea of using varieties of autoencoders and randomly pick one at a time to make it difficult for the adversary to predict which autoencoder was used.
5.8|Using HGD
While standard denoisers like pixel-level reconstruction loss function,suffer from error amplification,high-level representation guided denoiser(HGD)can effectively overcome this problem by removing noise from input samples.It uses a loss function which compares the output produced by unperturbed image of target model and denoised image.Liao et al.[77]introduced HGD to devise a robust target model immune against white-box and black-box adversarial attacks.Another advantage of using HGD is that it can be trained on a relatively small dataset and can be used to protect models other than the one guiding it.
In the HGD model,the loss function is defined as theL1norm of the difference between thelth layer representation of the neural network,activated byxand^x:
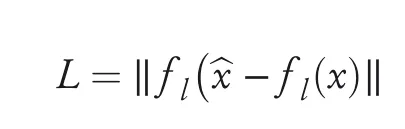

F I GUR E 1 5 Overview of Defense-GAN algorithm(Image Credit:Samangouei et al.[24])
F I GUR E 1 6 MagNet workflow in test phase(Image credit:Meng et al.[76])
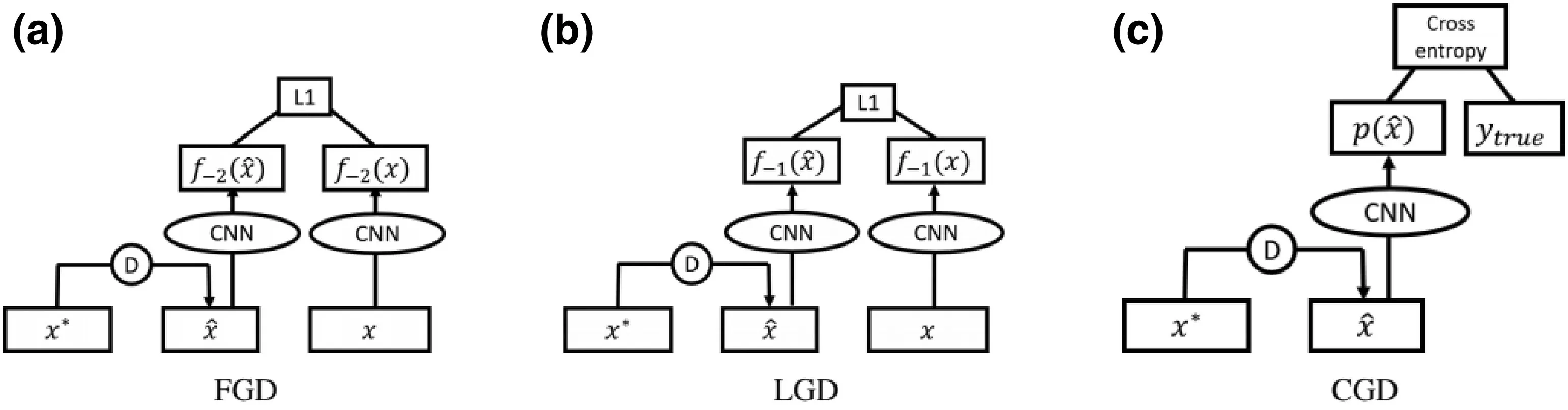
FI GUR E 1 7 Training methods:feature-guided denoiser,logits-guided denoiser and class label guided denoiser.D denotes denoiser(Image credit:Liao et al.[77])
The authors[77]proposed three training methods for high-leveldenoisers,illustrated in Figure 17.In feature-guided denoiser(FGD),the activations of the last layer of CNN are fed to the linear classification unit after globalaverage pooling.In logits-guided denoiser(LGD),they definedl=-1 as the index for the logits,that is,the layer before the softmax layer.While both of these variants were unsupervised models,they proposed a supervised variant,class label guided denoiser(CGD),which uses classification loss of the target modelas the loss function.
5.9 |Using basis function transformations
Shaham et al.[78]investigated various defense mechanisms like PCA,low-pass filtering,JPEG compression,soft thresholding and so on by manipulations based on basis function representation of images.Allthe mechanisms were applied as a preprocessing step on both adversarial and legitimate images and evaluated the efficiency of each technique by their success at distinguishing between the two sets of images.The authors showed that JPEG compression performs better than all the other defence mechanisms under consideration across alltypes of adversarial attacks in black-box,grey-box and white-box settings.
As described,the existing defense mechanisms have their limitations in the sense that they can provide robustness against specific attacks in specific settings.The design of a robust machine learning modelagainst alltypes of adversarial examples is stillan open research problem.
6|CONCLUSION
Despite their high accuracy and performance,recent applications based on machine learning algorithms are vulnerable to subtle perturbations that can have catastrophic consequences in security-related environments.The threat becomes more grave when the applications operate in adversarial environment.So,it has become immediate necessity to devise robust learning techniques resilient to adversarial attacks.A number of research papers on adversarial attacks as well as their countermeasures has surfaced since Szegedy et al.[14]demonstrated the vulnerability of machine learning algorithms.In this paper,we try to present some of the well-known adversarial attacks and some of the recent defense strategies against them.We have also tried to provide a taxonomy on topics related to adversarial learning.After the review,we can conclude that adversarial learning is a real threat to application of machine learning in physical world.Although there exist certain countermeasures,but none of them can act as a panacea for all challenges.It remains as an open problem for the machine learning community to come up with a considerably robust design against these adversarialattacks.
ACKNOWLEDGEMENT
We want to acknowledge the Department of Science and Technology,Government of India,to partially support the research through the Swarnajayanti Fellowship program.We would also like to acknowledge the Haldia Petrochemicals Ltd.and TCG Foundation for the research grant entitled Cyber Security Research in CPS.
 CAAI Transactions on Intelligence Technology2021年1期
CAAI Transactions on Intelligence Technology2021年1期
- CAAI Transactions on Intelligence Technology的其它文章
- Side channel attacks for architecture extraction of neural networks
- Differential fault location identification by machine learning
- A two-branch network with pyramid-based local and spatial attention global feature learning for vehicle re-identification
- Survey on vehicle map matching techniques
- TWE-WSD:An effective topical word embedding based word sense disambiguation
- Deep learning-based action recognition with 3D skeleton:A survey