
TWE-WSD:An effective topical word embedding based word sense disambiguation
2021-06-19 13:05LianyinJiaJilinTangMengjuanLiJinguoYouJiamanDingYinongChen
Lianyin Jia | Jilin Tang| Mengjuan Li | Jinguo You| Jiaman Ding|Yinong Chen
1Faculty of Information Engineering and Automation,Kunming University of Science and Technology,Kunming,China
2Yunnan Key Laboratory of Artificial Intelligence,Kunming University of Science and Technology,Kunming,China
3Library,Yunnan Normal University,Kunming,China
4Schoolof Computing,Informatics,and Decision Systems,Arizona State University,Tempe,Arizona,USA
Abstract Word embedding has been widely used in word sense disambiguation(WSD)and many other tasks in recent years for it can well represent the semantics of words.However,the existing word embedding methods mostly represent each word as a single vector,without considering the homonymy and polysemy of the word;thus,their performances are limited.In order to address this problem,an effective topical word embedding(TWE)-based WSD method,named TWE-WSD,is proposed,which integrates Latent Dirichlet Allocation(LDA)and word embedding.Instead of generating a single word vector(WV)for each word,TWE-WSD generates a topical WV for each word under each topic.Effective integrating strategies are designed to obtain high quality contextualvectors.Extensive experiments on SemEval-2013 and SemEval-2015 for English all-words tasks showed that TWE-WSD outperforms other state-of-the-art WSD methods,especially on nouns.
1|INTRODUCTION
Natural language has inherent ambiguity.Many words generally have multiple senses,for example,the word‘cricket’can be either a sport or an insect.For a human,it is rather simple to recognise the right sense under a certain context,but for a computer,word sense disambiguation(WSD)is a rather difficult task as it is considered as an AI-complete problem[1].WSD has become one of the central challenges in natural language rocessing field and is widely used in machine translation[2,3],information retrieval[4],information extraction[5],name disambiguation[6]etc.In machine translation,an optimally machine translation system usually incorporate some kind of WSD component,a WSD system can help a machine translation system to choose the right translation for an ambiguous word.In information retrieval,the sense ambiguity may cause relevant documents precluded and irrelevant documents retrieved.A WSD system can help information retrieval system to improve the retrieval performance.
Most existing disambiguation studies are based on a distribution hypothesis[7],assuming that similar senses should have similar contexts.Some typical representatives are Lesk[8]and its derived studies[9,10],which try to exploit the overlaps between the context of ambiguous word and its sense definitions.However,the effects of these studies are limited,as they cannot capture semantic information hidden under the context.
Word embedding is a good solution to this problem.It captures both syntactic and semantic information and compresses them into a low dimensional real-valued continuous word vector(WV).The generated WVs have rich semantic information that is helpful to WSD and many other natural language processing tasks.
The quality of WVs has a great impact on WSD performance.For the past a few years,many word embedding techniques have been proposed.Latent semantic analysis(LSA)[11]constructed the document-word co-occurrence matrix first,and then,it executed dimension reduction using singular value decomposition(SVD)to generate the corresponding WVs.Word2Vec,proposed by Mikolov et al.[12],uses a neural network-based supervised process to generate WVs.The generated WVs meet the requirements of simple algebraic operations,which is simple to use and can significantly improve the quality of WVs.Glove,proposed by Pennington et al.[13],made an explicit representation by a global word co-occurrence statistics and localwindow context.Based on these techniques,the quality of the generated WVs is significantly improved.
Considering the semantic information captured by word embedding,many studies have been conducted on integrating it into WSD.Taghipour et al.[14]generated and adapted WVs by using window approach network[15],and they integrated these WVs into it makes sense(IMS)[16],a well-established WSD platform,to improve the disambiguation performance.Rothe et al.[17]proposed AutoExtend,which improved the performance by integrating words,phrases and syntax into word embedding,and extending word embedding to synset embedding.Ignacio et al.[18]designed efficient integrating strategies and verified that integrating word embedding into IMS can improve the performance of WSD.
Although the aforementioned methods can improve WSD performance to certain extent,they have a major weakness:they generate a single context-independent WV for each word.We know words are generally polysemantic,which means word senses in different contexts are usually different.Therefore,it is hard for a single WV to capture all senses in different contexts.
To address this problem,Huang et al.[19]proposed a multi-prototype system,which uses K-means clustering to decompose single word embedding into multiple prototypes.Each prototype represents an independent word sense.Multiprototype system can solve the problem to certain extent,but it still faces a few challenges.For example:(1)the ability to capture the semantic information of word is insufficient;(2)it divides the context of a word into non-overlapping clusters,which in fact omits the correlation of different senses.
Motivated by the weakness of word embeddings and the insufficiency of multi-prototype system,the following two objectives are aimed:
1.Design effective topical word embedding that incorporates topical model into word embedding to better capture semantic information for ambiguous words under different topics.
2.Design topical word embedding based contextual vector generating strategy and further implement an effective allword WSD system on all-word WSD tasks.
To achieve these two goals,a topical word embedding(TWE)based WSD(TWE-WSD)system is proposed.Instead of generating a single WV for each word,TWE-WSD generates multiple topical word vectors(TWV)for each word by integrating Latent Dirichlet Allocation(LDA)and word embedding.Effective integrating strategies are designed to obtain high quality contextualvectors(CV).These CVs exploit some key information(contextual topic distribution,contextualword embedding and the distance to the ambiguous word)to better capture the semantic information underlying the contexts.In addition,TWE-WSD is implemented on the latest SupWSD framework[20],which has a faster WSD speed and higher WSD accuracy compared with IMS based methods.TWE-WSDis implemented and compared it with several other state-of-the-art WSD methods on all-word WSD tasks.Extensive experiments on SemEval-2013 and SemEval-2015 for English all-words tasks showed that TWE-WSD outperforms the existing methods,especially in nouns.
The following contributions are made:
1.A novel topical word embedding based WSD system named TWE-WSD is devised,which combines LDA and word embedding together to improve WSD performance.To the best of knowledge,we are the first to combine these two techniques together to implement supervised WSD.
2.Effective strategies are designed to generate high quality contextual vectors(CV),which can capture explicit semantic information underlying the contexts effectively.
3.Comprehensive experiments show that TWE-WSD achieves substantial improvements over the state-of-the-art techniques.
The rest of the paper is organised as follows.Related work is categorised and discussed in Section 2.TWE-WSD is presented in detail in Section 3.Experiments and result analyses are described in Section 4.Finally,conclusions and future work are presented in Section 5.
2|RELATED WORKS
2.1|Supervised word sense disambiguation
WSD can be divided roughly into two categories:supervised WSD and knowledge-based WSD.
Supervised WSD works on manually sense-tagged data and then uses supervised machine learning methods[such as Support Vector Machine(SVM)]to establish a classification model for each word[21–23].Earlier supervised WSD methods focused on combining different features with classification methods.Ng et al.[21]combined semantic features extracted from different knowledge sources and used exampler-based learning to train the classification model.Lee et al.[22]evaluated WSD performance of combining four different semantic features and four different supervised learning methods to find the best combination and found that using all the four features and SVM could achieve a higher accuracy.IMS [16]implemented a comprehensive framework by combining part-of-speech(POS)tags,surrounding words and local collocation and linear SVM.IMS is flexible because different features and classifiers can be easily inserted and verified.Due to this,it has been extensively used as a fundamentalexperimental platform.
With the development of word embedding techniques in recent years,there is a growing trend to integrate word embedding into WSD.Taghipour et al.[14]integrated WVs proposed by Collabert et al.[15]and Iacobacci et al.[18]integrated WVs generated by Word2Vec into IMS system,respectively.They turned out integrating these WVs is beneficial to WSD.In considering the difficulties of code expansion and optimisation for big datasets in IMS,Papandrea et al.[24]implemented a new platform,SupWSD.SupWSD has many virtues,for example taking much less parameters than IMS,supporting most widely used preprocessing tools,and supporting multi-language.All these approaches make it flexible for a programmatic use and easy for expanding.
Recently,there is an increasingly trend to introduce neural models into WSD[25,26],and the most prominent representative is Context2Vec[25].Context2Vec uses a bidirectional LSTM recurrent neural network to learn a generic context embedding function from large corpora,and this function is rather flexible and can be used in a large number of tasks,such as sentence completion,lexical substitution and WSD.
2.2 |Knowledge based word sense disambiguation
Supervised methods require sense-labelled training data.However,in most cases,labelled data is sparse and difficult to obtain.Unlike supervised methods,knowledge based methods only need the structure or content of external knowledge source,for example WordNet,BabelNet,but no sense annotated training data.They generate its own annotated corpus and work on an assumption that similar senses occur in similar contexts.
There are two popular types of knowledge-based methods:overlap-based method and graph-based method.
The most famous overlap-based method is Lesk[8],which computes the overlaps between the context of ambiguous word and its sense definitions.Lesk suffers from similar sentences might have very few overlaps.To overcome this problem,many variants have been proposed to replace overlap with distributed similarity,thus improving the performance[10].
Different with overlap-based method,graph-based method first builds semantic graphs from lexical resources and then uses different techniques(Personalised Page Rank[27],Markov Random Field[28],Entity Linking[29,30],Game theory[31])to design algorithms to exploit the structural properties of semantic graphs.
2.3 |Latent Dirichlet allocation-based word sense disambiguation
LDA proposed by Blei et al.[32]works on Bayesian topic model.It describes the hierarchical relations among words,topics and documents.In LDA,a topic is an implicit variable,each document can be described by a distribution of topics and each topic can be described by a distribution of words.
LDA is widely used in WSD and many LDA based WSD methods.As far as we know,LDAWN[33]proposed by Boyd-Graber et al.,is the first LDA-based WSD method which uses LDA and WordNet hierarchy together in WSD.LDAWN works on the assumption that senses with similar paths in the WordNet are more likely have the same topic.Cai et al.[23]used extracted topic distribution as features and then put these features into a supervised WSD system to improve WSD performance.Li et al.[34]introduced LDA to decompose the conditional probability of sense phrases and proposed three models with different degrees of resource availability to improve WSD performance.In a recent study,Chaplot et al.[35]designed WSD-TM,a topical model-based WSD,which can scale linearly with the number of words in the context,which decreases the training time significantly.The topical model used was a LDA variant in which the topic proportions for a document were replaced by synset proportions.
For more description of WSD-related approaches,readers are asked to read recent surveys[36,37]for more details.
3|TOPICAL WORD EMBEDDINGBASED WORD SENSE DISAMBIGUATION
3.1|General framework
As mentioned earlier,it is hard for traditionalword embedding to dealpolysemy easily because it uses a single WV to describe an ambiguous word,thus deteriorating the WSD performance.
It is well known that sense and topic are well related.A polysemous word usually expresses a certain sense in a certain topic and a certain topic is more likely to contain words with a certain sense.For example,word‘cricket’more likely to expresses the sense of sport in the sports topic,whereas it usually expresses the sense of insect in the animaltopic.
Based on the analysis above,topical model is a natural choice to improve the performance of WSD.topical model is integrated into word embedding and a novelTWE-based WSD method(TWE-WSD)is proposed,which can exploit the benefits of both topical modeland word embedding to further improve the performance of WSD.The basic framework of TWE-WSD is shown in Figure 1.
TWE-WSD consists of the following four basic steps:
(i)Topic modeltraining;
(ii)TopicalWVs generating;
(iii)Contextualvectors generating;
(iv)Supervised disambiguation.
Note that the first two steps are executed on a large untagged topical training corpus to generate TWVs,and the latter two steps are executed on TWVs generated from the first two steps and a sense-tagged disambiguation dataset.
3.2 |Topical word vectors generation
After the topic model trained,all documents in the topical training corpus are divided intoktopical document subsets according to topic model built in Section 3.2.Note that assigning each document to multiple topics is time-consuming.In order to speed up the training process,each document is assigned to the subset corresponding to its maximum probability topic.Then,each subset is trained independently using word embedding to obtain TWVs for each topic.The TWVof wordwunder topictis represented byNote that after the division of the topicaltraining corpus,the number of documents in each subset may be skewed,that is some subsets may contain very few documents,which will degenerate the quality of generated TWVs.To solve this problem and speed up the training process,those subsets whose number of documents below a certain threshold are ignored,for example 10.The TWVs for these subsets are considered as zero vectors.
3.3 |Topic model training
Topic modelis the basis of TWE-WSD.Here,LDA is used,the most common topic modelcurrently in use,to train the topic model.Based on LDA,given a topic number parameterk,the topicaltraining corpus is trained,andktopics can be recognised.Besides,the document-topic and the topic-word distributions can be computed for future use.
Taking into account the slow convergence of LDA,a fast online LDA proposed by Hoffman et al.[38]is applied to train the topic model.The online LDA bases on online stochastic optimisation with a natural gradient step and supports stream processing.As a result,it can obtain high quality topic models in a shorter training time compared with traditional LDAs.
3.4 |Contextual vector generating
Context is important to WSD.Thus,instead of using TWVs of the ambiguous word as training features directly,CVs of the ambiguous word is generated that will make our model fully exploit the context.To do this,the following three steps are executed to generate high-quality CVs.
3.4.1 |Contextual topic distribution
Intuitively,it is too naïve to directly assign a contextCto a specific topict.Thus,before generating CVs forC,the first step one need to do is to determine the topic distributionθofC.To do this,conditionalprobabilityp(t|C)for each topictaccording to Equation(1)is computed.
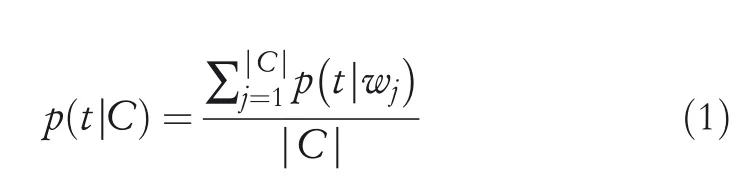
wherep(t|wj)denotes the conditional probability of that thejth wordwjinCis assigned to topict,|C|denotes the number of words in contextC.
3.4.2 |Contextualword vector generating
After obtaining the topic distribution,it is important to obtain WVa WV of wordwjunder topic distributionθ.To achieve this goal,a weighted average strategy to computeaccording to Equation(2)is designed:
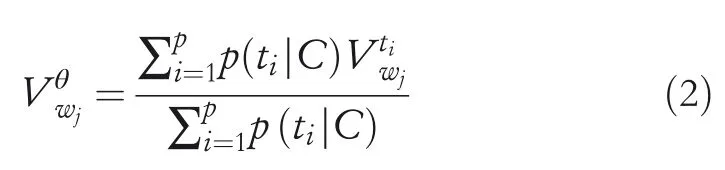
Note that in Equation(2),the topphighest probabilities inθto computeis used.The reason is that the topic distribution is usually skewed,and thus time can be saved by not computing most of the small probabilities.pis considered as a parameter to be observed in experiments.
3.4.3 |Contextualvector generating
As we use CVs as final features to be trained in supervised classifiers,a good strategy for generating CVs can efficiently promote WSD performance.Intuitively,the closer a word to the ambiguous word is,the greater contributions to recognise the ambiguous word it willbe.Therefore,an exponentialdecay strategy is designed to integrate the contextual WVs to generate the final CVVC.This strategy puts more emphasis on words close to ambiguous word by exponentially setting the weight of wordwjaccording to its distance to the ambiguous word as shown in Equation(3).

wheredrepresents the distance between wordwjand the ambiguous word inC,andα=0.12/|C|represents the decay factor ofC.Here,0.1 means a surrounding word with distancedto the ambiguous word contributes 10 times than the one with distanced+1.
3.5 |Supervised word sense disambiguation
For the final disambiguation step,the following features are extracted:POS tags,surrounding words,local collocations,syntactic relations and pre-trained CVs,then LibLinear is used,a built-in classifier in SupWSD,to train these features.Readers are asked to read paper[20]for a detailed description of training process.
4|EXPERIMENTS
4.1|Experimental environment
The performance of TWE-WSD is evaluated on all-words task.All experiments were conducted on a PC with a 4-core Intel i7-7700 CPU running at v3.6 GHz and 16 GB of memory.Builtin Word2Vec and online LDA are used in Gensim[39]to train TVWs and LDA model,respectively.
4.2 |Dataset
4.2.1 |Topicaltraining corpus
The English Wikipedia1http://download.wikipedia.orgis used as our topicaltraining corpus,which includes about 4.5 million documents and three billion words.
4.2.2 |Disambiguation dataset
Disambiguation dataset is used for generating topic distribution and CVs.The following training and testing datasets are widely used in WSD:
1.Training dataset
SemCor[40]is used as the training dataset,which includes 352 documents and 360,000 words,of which 226,036 words are sense-tagged.
2.Testing dataset
Two all-words WSD tasks are used to evaluate TWE-WSD:
SemEval-13 task 12(SE13)[41]:it consists of 13 documents from different fields,in which there are 1644 sensetagged nouns.
SemEval-15 task 13(SE15)[42]:it consists of four documents from biomedicine,mathematics and sociology,in which there are 1022 sense-tagged nouns,verbs,adjectives and adverbs.
4.3 |Results and discussions
In training the topic model,the number of iterations are set to 1000,and the other parameters are left as default in Gensim.In generating TWV,Skip-gram model is used with negative sampling 10 and sub-sampling of frequent words 10-3.The length of the WV is set to 400 as default value recommended in Reference[18].
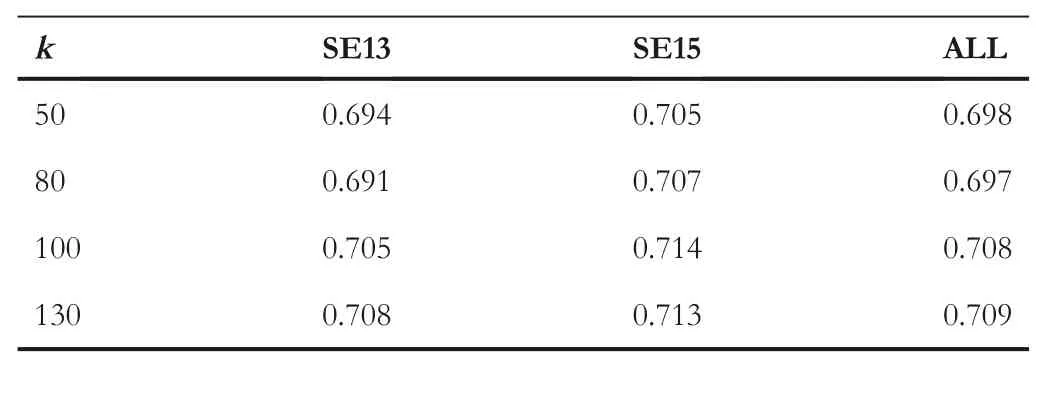
4.3.1 |The effects ofk
In order to investigate the effects of the number of topicskon WSD performance,p=5 is set and the whole document is used as the topicalcontext,and then,F1 scores are computed[43]fork=50,80,100,130 respectively.The results are shown in Table 1.
In Table 1,ALL represents the comprehensive scores of SE13 and SE15 as shown in Equation(4).
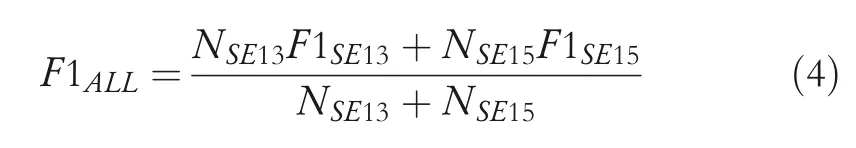
whereNSE13andNSE15represent the number of documents in SE13 and SE15,respectively.
As can be seen in Table 1,alltheF1 scores increase with the increase ofk.Whenk=100,F1 scores tend to be stable.Therefore,in the experiments below,when not pointed out explicitly,kis set to 100.
4.3.2 |The effects of different context types
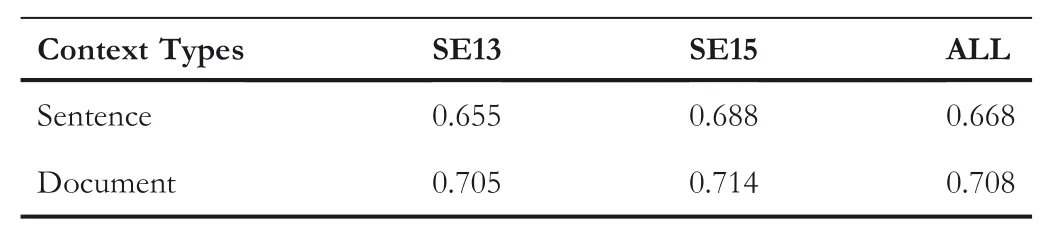
When computing topic distribution,different context types willhave different impact on the topic distribution,and thus affecting the WSD performance.two types of contexts are considered:sentence(use the sentence where the ambiguous word is located as a context)and document(use the whole document where the ambiguous word is located as a context).TheF1 scores of these two context types are shown in Table 2.
As can be seen in Table 2,a better performance can be achieved when using document as context.The reason is that with the increase of context size,more words can be used to recognise the topic of the context.Therefore,to obtain a better disambiguation performance,when not pointed out explicitly,document is used as default context.
4.3.3 |The effects ofp
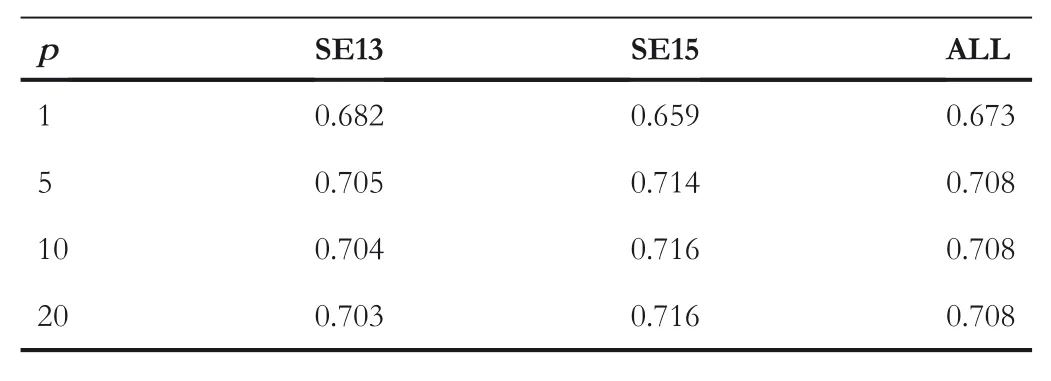
To investigate the effects of parameterp,p=1,5,10,20 is set,and then,the correspondingF1 scores are computed,respectively,as shown in Table 3.
As can be seen in Table 3,p=1 means the highest probability topic assigned to each context,and in this case,theF1 scores are the lowest.Whenp≥5,theF1 scores tend to be stable.This is consistent with our previous analysis in Section 3.4.2.As a result,no need to compute allthe probabilities inθ.p=5 is used as our default value thereafter.
TA B LE 1 F1 scores of different k
TA B LE 2 F1 scores for sentence-context and document-context
TA B LE 3 F1 scores of different p
4.3.4 |Comparison with other word sense disambiguation systems
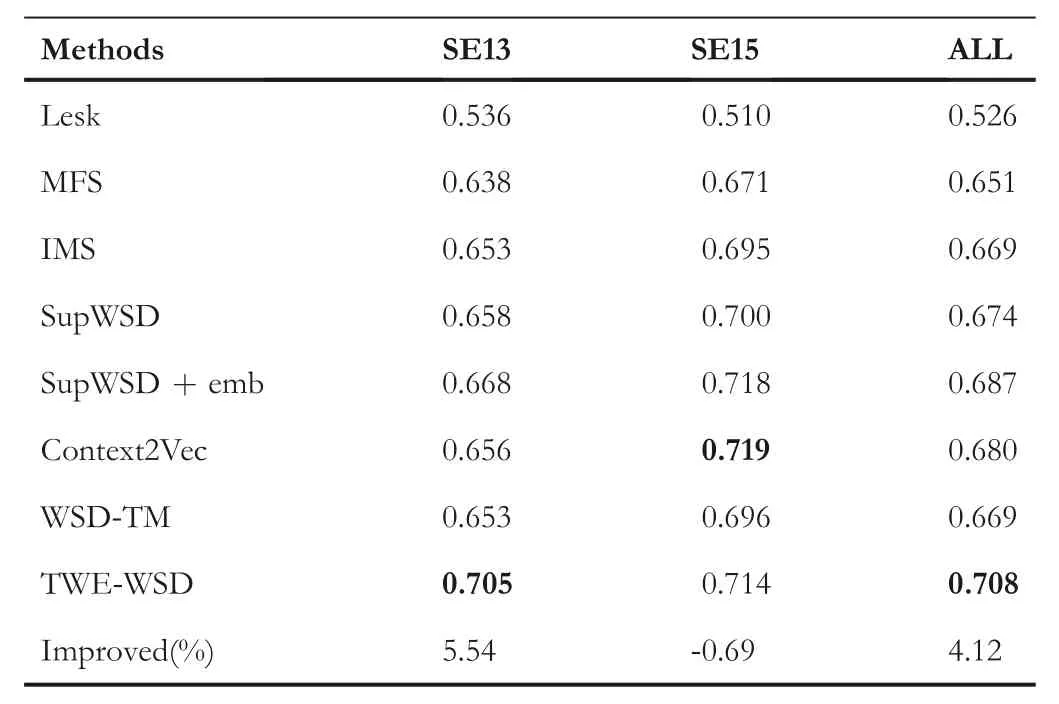
In order to compare performances of different methods,TWE-WSD was compared with seven state-of-the-art methods:Lesk[8],Most Frequent Sense(MFS),IMS[16],SupWSD[24],SupWSD+emb[24],Context2vec[25]and WSD-TM[35].Here,MFS is a heuristic baseline,which simply labels each ambiguous word with its MFS in the training corpus.SupWSD+emb is SupWSD with appending word embedding into its training features.The results are showed in Table 4.
It can be seen from Table 4 that TWE-WSDhas comparable performance with the best method on SE15(Context2Vec),it outperforms allother state-of-the-art methods significantly on SE13,and thus having an overallperformance on ALL.TWEWSD has 5.54%improvement of F1 score on SE13 than SupWSD+emb(the best method on SE13),which can be viewed as a significant improvement because it is the only one among these methods that gets a F1 score higher than 0.7 on SE13.The F1 score of TWE-WSD is 0.021 higher than SupWSD+emb on ALL which shows the benefits of integrating topicalmodelinto TWE-WSD(TWE-WSDcan be seen as integrating topical model into SupWSD+emb).The F1 score of SupWSD+emb is 0.013 higher than SupWSD,which showsthat integrating embedding into WSD can also improve the performance of WSD.Compared with WSD-TM,another topical modelbased WSD algorithm,the F1 score of TWEWSD is 5.82%higher on All.The partial reason may lie in that TWE-WSDis supervised and can exploit word embedding,thus its performance can be significantly improved.
TABL E 4 F1 scores of different methods

TABL E 5 F1 scores of different parts of speech
Why TWE-WSD outperforms SupWSD+emb and on which POS tags it work best are further analysed.Experiments on each POS are carried out separately,and the result is shown in Table 5.
As shown in Table 5,TWE-WSD works much better on nouns than any other POS tags.This is probably because nouns are more capable to distinguish topics than the other POS tags.As SE13 has nouns only,while SE15 covers nouns,verbs,adjectives and adverbs,so TWE-WSD works much better on SE13 than SE15.This finding gives us valuable choices for disambiguating datasets with different POS tags.
5|CONCLUSION AND FUTURE WORK
TWE-WSD,a novel TWE-based WSD system is proposed.TWE-WSD is effective by leveraging topic model and word embedding.TWVs instead of WVs are generated to better capture different senses in different contexts.Effective integrating strategies are designed to generate high quality CV.Experimental results show that TWE-WSD achieves substantial improvements over the state-of-the-art techniques.Based on these results,the following major findings are discussed:
1.Integrating word embedding into WSD has a positive effect on improving the performance of WSD.
2.Integrating topical model into WSD can further improve the performance of WSD.
3.Topicalmodel works better on nouns than any other POS tags.
For future work,following three aspects can be focused:(1)As topical model mainly works wellon nouns;some strategies,for example verb subcategorisation[44],can be used to improve the accuracy of TWE-WSD on other POS tags other than nouns.(2)Besides,as neural model-based methods such as Context2Vec works wellon SE15 and are complementary to TWE-WSD,so integrating our topical model with neural models may be another promising way to improve the performance on other POS tags.(3)Moreover,hybrid approaches[45,46]can also be introduced to further improve WSD performance.
ACKNOWLEDGEMENTS
This work was partially supported by the National Natural Science Foundation of China(61562054),the Fund of China Scholarship Council(201908530036)and the Talents Introduction Project of Guangxi University for Nationalities(2014MDQD020).
 CAAI Transactions on Intelligence Technology2021年1期
CAAI Transactions on Intelligence Technology2021年1期
- CAAI Transactions on Intelligence Technology的其它文章
- Side channel attacks for architecture extraction of neural networks
- Differential fault location identification by machine learning
- A survey on adversarial attacks and defences
- A two-branch network with pyramid-based local and spatial attention global feature learning for vehicle re-identification
- Survey on vehicle map matching techniques
- Deep learning-based action recognition with 3D skeleton:A survey