
基于MPSOC的航空图像目标检测系统设计
2021-07-14 01:30王宇庆聂海涛
液晶与显示 2021年7期
任 彬,王宇庆,丛 振,聂海涛,杨 航
(1.中国科学院 长春光学精密机械与物理研究所,吉林 长春 130033;2.中国科学院大学,北京 100049;3.中国人民解放军联勤保障部队第946医院 医学工程科,吉林 长春 130033)
1 引 言
目标检测作为机器学习的一个重要研究领域,经过了传统的目标检测算法和基于深度学习的目标检测算法两个阶段[1]。2014年之前,传统的目标检测算法一直占据着主流地位。2001年,Paul Viola在CVPR会议中提出了Viola-Jones 算法,通过Haar-like特征和Adaboots算法有机结合实现了人脸检测。4年之后,Dalal提出了HOG+SVM的方法,并应用于行人检测。2008年,Pedro Felzenszwalb在其基础上提出了DPM算法,通过多组件(Component)的策略解决了多视角的问题,通过基于图结构(Pictorial Structure)的部件模型策略解决了目标的形变问题。但这些传统的目标检测算法在进行区域选择时往往需要遍历整个图像,存在时间复杂度高的问题,同时手工设计的特征鲁棒性也较差。2014年之后,基于深度学习的目标检测算法快速崛起,形成了基于候选区域的目标检测算法和基于回归的目标检测算法两个流派。前者以R-CNN为代表,这类算法精度较高,但实时性较差,不利于工程项目的实际应用[2];后者以Yolo为代表,这类算法虽然在精度方面略有逊色,但检测速度却远快于基于候选区域的目标检测算法。
另一方面,随着无人机在军事侦察和森林火灾预警方面的应用日益普遍[3],针对无人机平台的航空图像目标检测技术引起越来越多国家的注意。国外很早便开展了针对无人机平台的检测跟踪系统的研究[4]。1997年,Olson等人提出了基于模型的准实时性跟踪系统,该系统在目标发生一定形变或者被短暂遮挡时依旧能保持较好的准确度[5]。2006年,美国先进技术研究局发布了COCOA监控系统,可以实现对行人、车辆等多种类型目标的自动检测和轨迹跟踪[6]。2010 年,Ibrahim 提出的 MODAT系统弥补了COCOA系统在复杂背景下准确度不高的问题[7]。国内相关方面的研究虽然起步较晚,但发展迅速。2011年,谭熊等人提出了一种计算量小、满足实时性的目标检测与跟踪算法[8],2018年,汤轶等人提出了一种基于 Kalman 滤波和粒子群优化(PSO)算法的目标跟踪检测算法,将PSO算法代替穷举法,极大地降低了计算量[9]。2020年,李航等人将深度可分离卷积应用于Yolo算法,通过减少参数量加快了网络传播速度,使算法具备嵌入式平台移植基础[10]。
在实际无人机目标检测场景中检测速度往往是比检测精度更重要的评价指标,所以本文选择了速度较快的一阶段网络Yolo V3作为基础网络。针对航空图像目标检测的应用场景,本文设计了合适的锚框(Anchor),通过对网络的结构进行调整,使其平均精度均值(MAP)提升了1.3%。之后对各卷积层进行基于L1范数的敏感度分析,通过剪枝操作,使模型具备了多处理器片上系统(MPSOC)平台的移植基础。
本文所采用的MPSOC硬件平台为Xilinx推出的第二代多处理器片上系统(SOC)器件Zynq UltraScale+ MPSoC。作为异构SOC平台,该芯片中集成了多核应用处理器(四核ARM Cortex-A53应用处理器)、多核图形处理器(双核ARM Mali-400图形处理器)、多核实时处理器(双核ARM Cortex-R5实时处理器)、平台管理单元(电源管理、错误管理、配置管理以及安全管理)和可编程逻辑资源(高性能计算和丰富I/O扩展等)。与传统的SOC平台相比该平台拥有更多的资源和更高的安全性。
2 YOLO V3检测原理
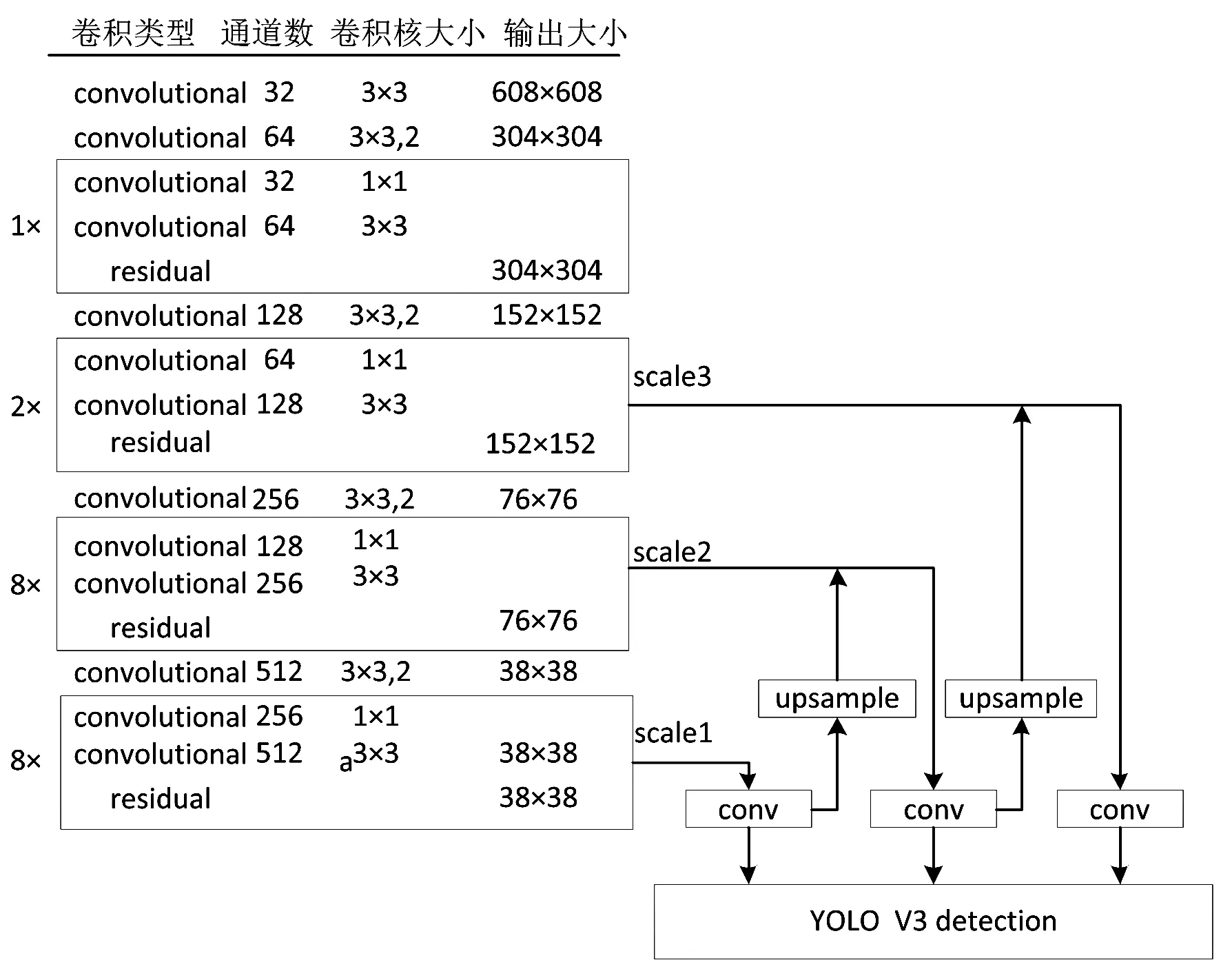
Yolo V3主干网络采用DarkNet53,只保留了前52个卷积层,用于图片特征的选择与提取。网络的具体结构如图1所示。整个网络由5个Yolo模块组成,每个Yolo模块所含有的残差模块数目互不相同。以第二个Yolo模块为例,整个Yolo模块由2个残差模块组成,而每个残差模块又由2个卷积层组成,第一个卷积层所用的卷积核大小为3×3,第二个卷积层所用的卷积核的大小为1×1。同时Yolo V3算法借鉴了FPN(Feature pyramid networks)的思想,利用不同的特征层检测不同尺度的目标[11]。整个算法会产生3个不同尺度特征图,分别对应图1中的scale1、scale2和scale3。对于输入608×608的图像会得到19×19、38×38和76×76的3个特征图。
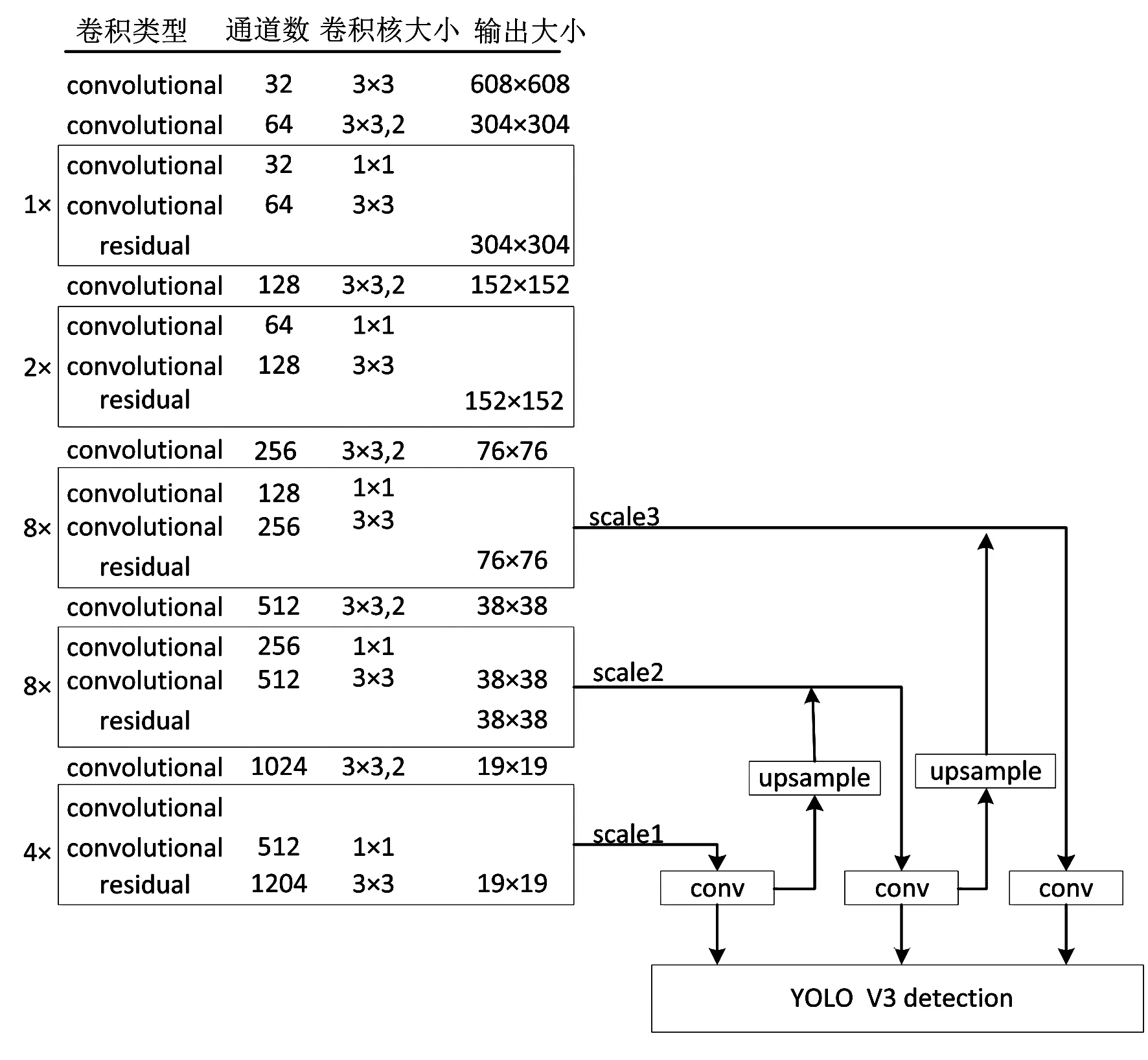
图1 Yolo V3网络结构图Fig.1 Yolo V3 network structure diagram
特征图中每个单像素点(特征点)都对应着原图中的一个区域。如76×76的特征图,它由原图经8倍降采样后得到,每个点对应的原图区域大小为8×8。在网络训练的过程中,真实框(Ground truth)的中心点落在特征图中哪个特征点对应的区域,哪个特征点就负责这个真实框的回归。每个特征点对应3种不同的锚框,所以一个特征点可同时回归3个不同的真实框。负责该真实框的特征点会选择与其拥有最大交并比的锚框对其位置进行回归。在原始Yolo V3网络中检测结果的通道数为255。每个255维的通道由边框回归和分类情况两部分组成。对于每个点的每个预测框(bounding box)的回归情况需要用(x,y,w,h,confidence)5个基本参数描述,其中x、y为中心点坐标,w、h为预测框的长宽,confidence为置信度。对于分类情况部分,类别数目等于分类部分通道的维数。如COCO数据集,需要检测的类别数为80,那么就需要一个80维的通道描述其类别情况。所以最终确定的维数情况为:3×(5+80)=255。其中3为每个单像素点拥有预测框的数量,5为边框回归情况,80为类别数。
3 模型改进
3.1 数据集的选择
一个好的训练数据集首先需要与应用场景一致。目前应用较多的COCO、VOC等数据集显然不具备目标尺寸偏小、多尺度以及成像背景复杂等航空图像的基本特点。目前可供选择的数据集主要有DATO和VISDRONE。DATO数据集的目标为高空无人机所拍摄,目标多为飞机、船舶、篮球场一类,且拥有的图片数量为2 806张。VISDRONE数据集由天津大学标注,该数据集覆盖了中国从北到南14个城市的城市/郊区。整个数据集合共有12类,分别是:people,pedestrian,bicycle,car,van,truck,tricycle,awning-tricycle,bus,motor,other,ignore regions,图片数量为8 629张。往往数据集越大,所得到的模型泛化能力和精度越高。本文最终选择的数据集为VISDRONE。VISDRONE数据集主类为前10类,所以在进行模型训练与检测时,只采用了前10类。训练集、测试集、验证集中各个类别的分布情况如表1所示。

表1 VISDRONE数据分布情况Tab.1 The distribution of the VISDRONE dataset
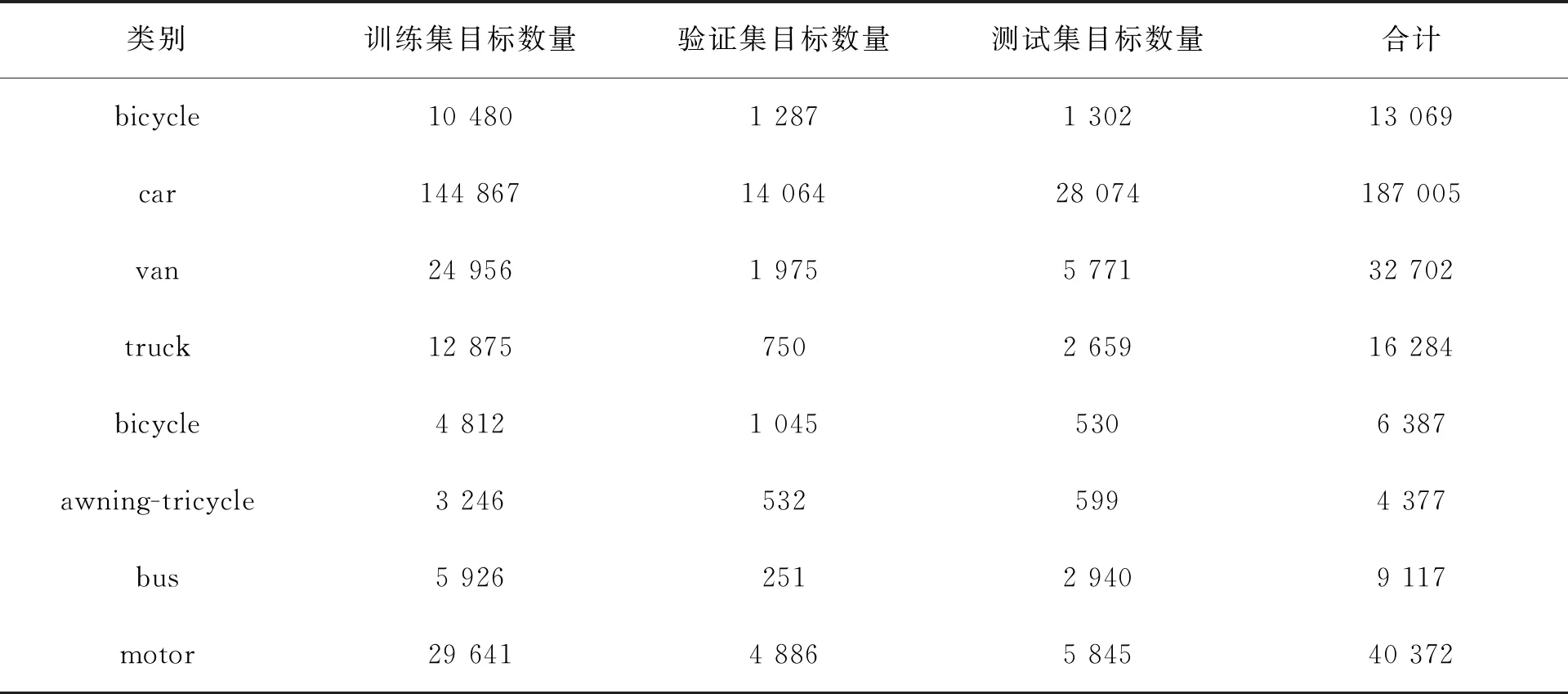
续 表
3.2 锚框的选择
Yolo V3原始模型在进行训练与验证任务时所选择的锚框都是根据COCO数据集而设定,并不适用于VISDRONE数据集中的目标,存在尺度偏大的问题,严重影响回归的准确度和效率,特别是对小目标的检测。此处采用改进的k均值聚类方法对VISDRONE数据集中的锚框重新聚类。由于锚框聚类的根本目的在于,使锚框与所有真实框最相似,即拥有最大的平均交并比(IOU)。所以在聚类时直接用交并比代替传统的欧氏距离作为距离度量指标。IOU的具体定义如图2所示:两个矩形分别代表聚类中心边框和待分类边框,上面的黑色区域为两个边框的交集面积,下面黑色区域为两个边框的并集面积。
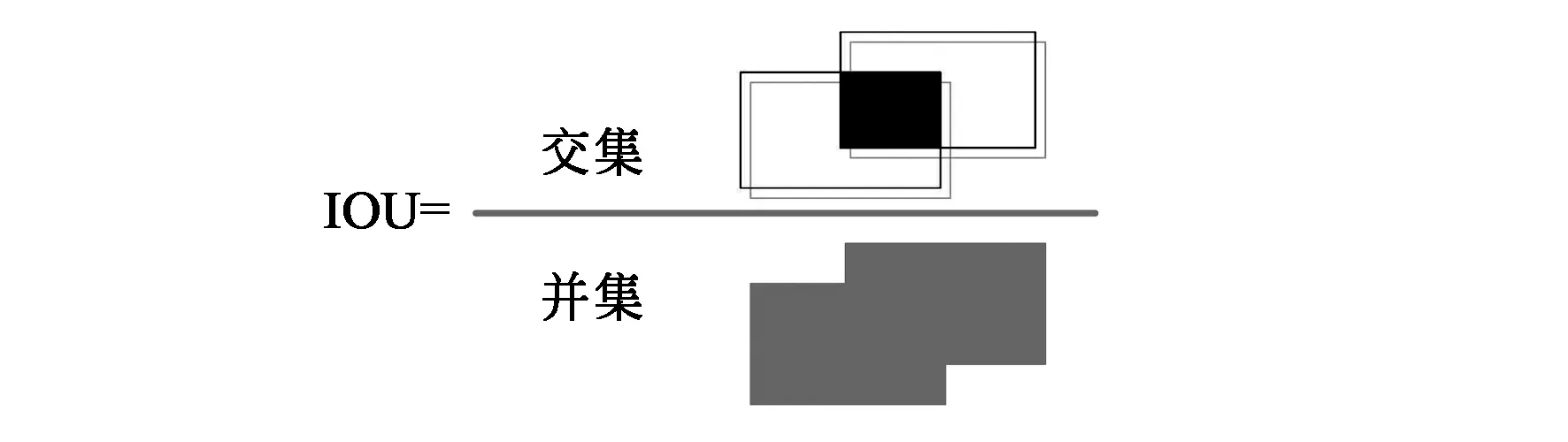
图2 IOU定义Fig.2 Definition of IOU
虽然IOU可以较好地描述两个边框的距离,但我们通常把损失函数定义为:与模型的性能呈负相关,即损失函数值越小,模型性能更好。最终将k均值聚类的损失函数定义为:
loss=1-IOUavg,
(1)
其中loss为定义的损失函数,1为常数,IOUavg为所有类别交并比的平均,算法终止的条件为loss不再变化。由于k均值聚类需要事先给出聚类的类别数量k,这里对k依次取值1~19,观察IOUavg的变化情况。
平均IOU随k的变化趋势如图3所示,可以发现随着k的增大,OUavg也在增大且趋于平缓。普遍认为曲线由陡峭到平滑的拐点为anchor box的最优值[12]。从图3可以看出k的最优值为2,此时既可以加快损失函数的收敛,又可以消除候选框带来的误差。多次试验后发现得到的两个聚类中心框均为细长型,即高度远大于宽度。所以此处为了保持Yolo V3的原始结构的优势,只对最小的两个细长型anchor进行替换。替换后的9个anchor box值为:[10,17],[16,30],[33,23],[27,38],[62,45],[59,119],[116,90],[156,198],[373,326]。

图3 类别k与平均IOU关系曲线Fig.3 Relationship curve between category variable k and variable average IOU
3.3 网络结构的调整
Yolo V3网络利用3个不同尺度的特征图对不同大小的目标进行检测[13]。当输入的图片为608×608时,最大的特征图也只有76×76。由于在该尺度特征图中每一个点都对应着原图一个8×8的区域。若待检测目标在原图中是一个7×7的区域,那么它将会变成特征图上的单像素点,目标检测几乎不可能。在更大的特征图中尚且如此,在更小的特征图中该区域将会变得更小,更加无法检测。
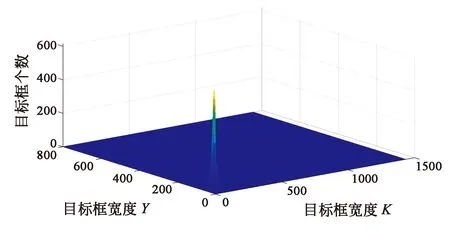
(a)目标框分布三维图(a)3D distribution image of target box
对VISDRONE数据集中真实框的分布进行统计,如图4所示:图4(a)图为目标框的三维分布情况,可以发现目标分布比较集中,且多为小目标。图4(b)为图4(a)的俯视图并二值化后的图像。定性分析并不利于问题的解决,所以将分布情况进行量化。将所有的真实框被分为5类,统计目标框真实框的长和宽在不同取值范围的实际分布情况。具体如表2所示。
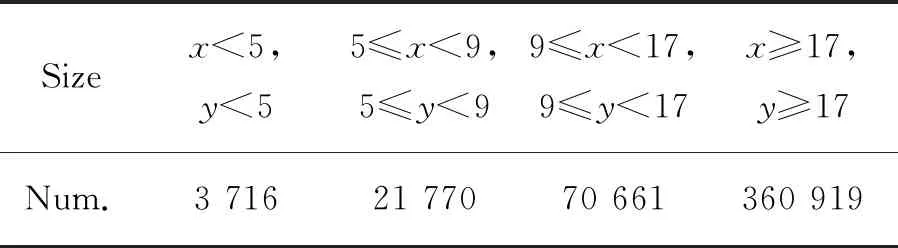
表2 真实框分布情况Tab.2 Ground truth distribution
表2中第一行表示真实框的大小。x、y分别表示边框的长与宽。第二行表示在该长宽范围内边框的数量。可以发现有25 486个真实框在原图上的长和宽均小于8,约占目标总量的5%,这也符合在实际航空图像中的目标分布特点。这些真实框在最大特征图中也仅仅是单像素点,特征无法得到很好的表达,最终造成目标无法检出。本文提出的解决办法为去除一个降采样过程,这样得到的最大特征图中,一个点将代表原图一个4×4的区域,这时只有3 716个实际目标框回归会比较难,占总目数比例不足1%。极大地增加了模型对小目标的适应性。
去除一个降采样过程,有图5所示的4种方式:图5(a)所示方式是直接去除darknet53网络的最后一个Yolo模块,此时主干网络卷积层数目将变为44,极大地减小了模型的参数量。但目前大量的研究表明,网络层数越多越有利于特征的表达和检测精度的提高[14],所以并没有选择图5(a)方式。另一种方式为保留网络的整体结构不变,分别将第一个或第二个或第三个降采样过程中3×3卷积核的步长改变为1。在越大的尺度上,小目标所占的像素越多,对其进行卷积特征提取工作越有意义。所以在小目标特征表达方面图5(b)性能优于图5(c),图5(c)性能优于图5(d)。对于图中的图5(b),去除一个降采样过程后会在第一个卷积模块中集中大量卷积层,且这些操作是在608×608的图像中进行,会增加大量的计算。图5(c)与图5(d)结构的变化也会在对应位置增加大量计算。在计算量方面图5(b)>图5(c)>图5(d),为了最终在MPSOC平台中进行部署,需要在小目标特征表达与计算量之间权衡,本文最终选择了图5(c)结构。
(a)解决思路一(a)Solution idea one
3.4 模型压缩
目前主流进行模型压缩的方式有:量化、剪枝、蒸馏[15]。本文采用基于L1范数的敏感度模型剪枝方法。这种方法以每一个卷积层为基本单元,依次对每一个卷积层裁剪一定比例卷积核,计算剪枝之后模型MAP的变化情况。MAP下降越多代表卷积层越敏感。每一个卷积层拥有数量较多的卷积核,如何确定剪枝顺序也是一个难题。本文通过对每个卷积核计算其L1范数,按照L1范数从大到小排列,来确定裁剪顺序。L1范数越小越先被裁减掉,这是由于L1范数较小的卷积核趋向于产生激活值较小的特征图[16]。表3为对主干网络darknet53的敏感度分析结果。
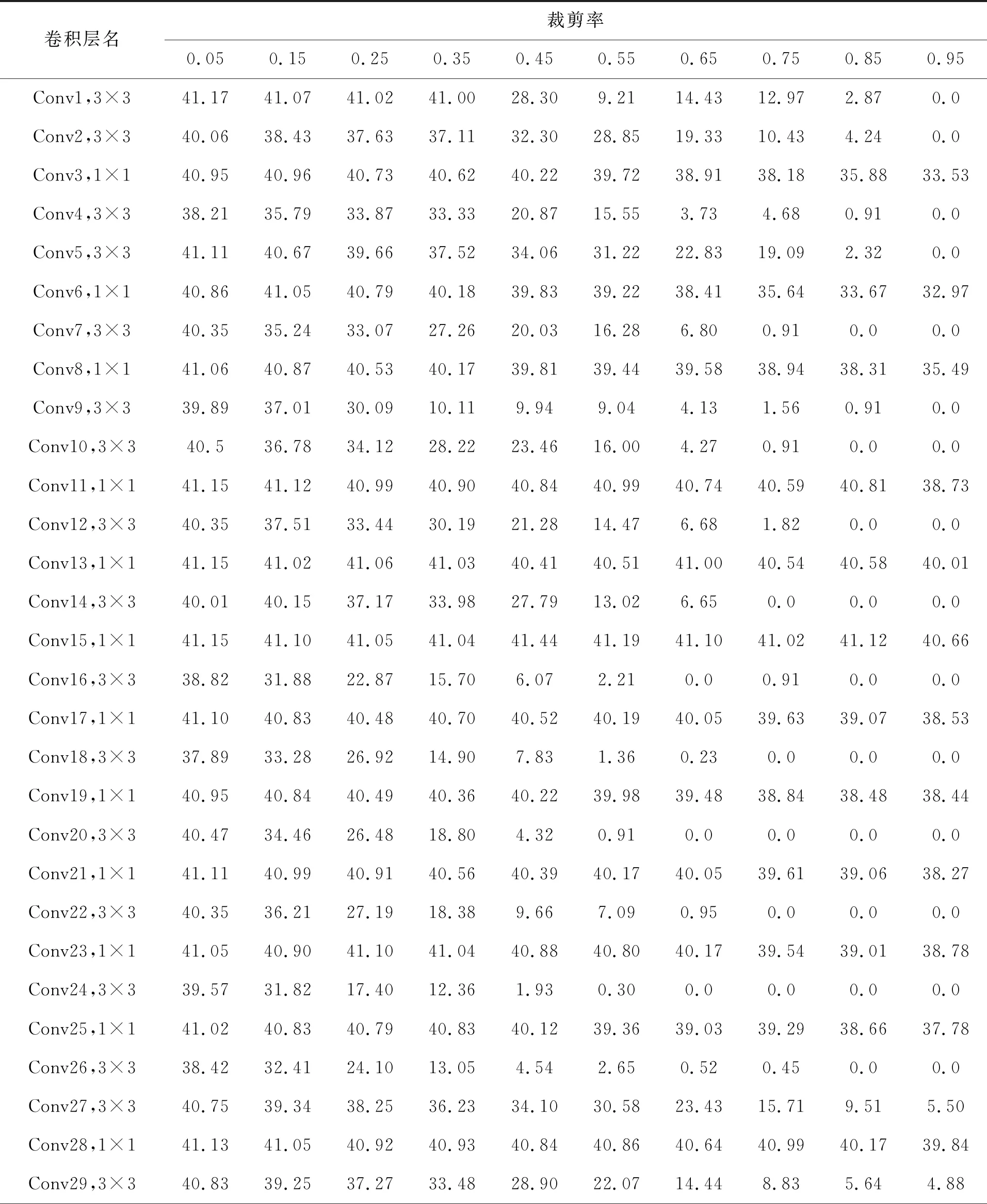
表3 各卷积层敏感分析结果Tab.3 Sensitivity analysis results of each convolutional layer
通过大量实验,最终确定各个卷积层的裁减比例依次为0.41,0.35,0.77,0.10,0.40,0.67,0.11,0.91,0.14,0.14,0.95,0.16,0.95,0.15,0.95,0.07,0.95,0.07,0.95,0.10,0.95,0.13,0.95,0.08,0.95,0.06,0.31,0.95,0.26,0.95,0.26,0.95,0.23,0.95,0.21,0.95,0.22,0.95,0.27,0.95,0.27,0.95,0.28,0.76,0.95,0.49,0.95,0.59,0.95,0.49,0.95,0.55。为了恢复模型的精度,需要对剪枝后的模型进行再训练,以恢复精度。本文没有采用传统的每剪枝一个卷积层就再训练一次的方法,而是一次性剪枝所有层,最后统一再训练,极大地降低了工作量。
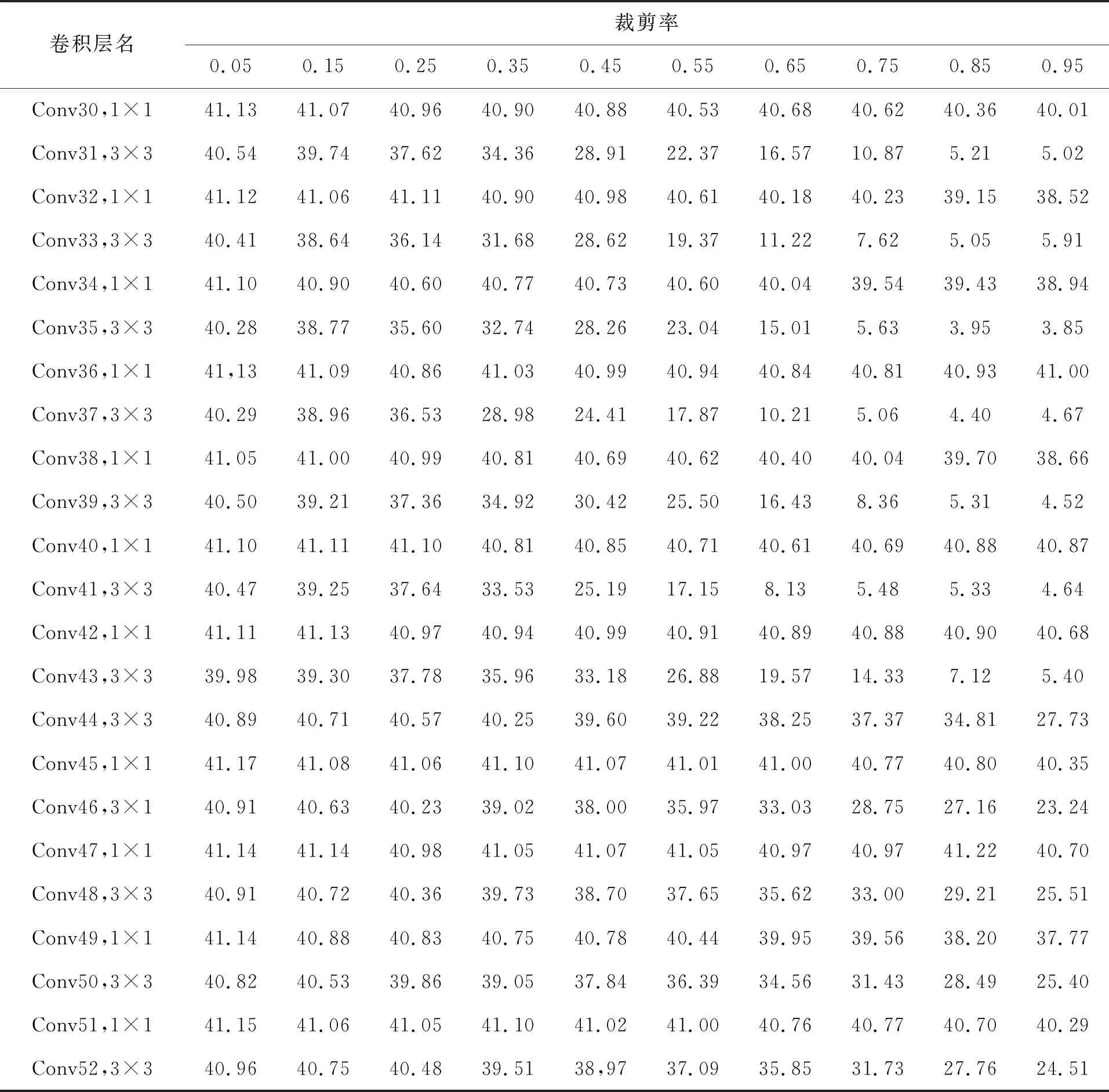
续 表
4 实验结果
本文所有模型训练及模型压缩过程均在NVIDIA 2080Ti中进行,最终模型的MPSOC验证在百度Edgeboard FZ3开发板中进行。FZ3主控芯片采用Xilinx的MPSOC平台ZYNQ,具体型号为XAZU3EG-1SFVC784I。
XAZU3EG芯片提供的硬件资源具体如图6所示。可以看出ZYNQ芯片由两部分组成,分别为多核同构的ARM(Advanced RISC Machine)部分(PS)和传统现场可编程门阵列(FPGA)部分(PL)。这种异构结构将处理器的软件可编程性与 FPGA 的硬件可编程性有机结合在一块芯片上。利用片内AXI方式代替传统的PCI-E通信,可以带来更大的通信带宽和通信稳定性。具体的硬件资源为:运行速率高达1.5 GHz的四核ARM Cortex-A53平台,双核Cortex-R5实时处理器、Mali-400 MP2图形处理单元及16 nm FinFET+可编程逻辑。在算力方面,与模型训练平台RTX 2080Ti相比,ZYNQ系列MPSOC远落后于其1 755 MHz的核心频率和4 352个流处理单元。但在功耗方面,MPSOC却拥有着巨大的优势。正常工作时MPSOC功耗只有7~10 W,RTX 2080Ti却达到了260 W。在便携性和体积方面,ZYNQ系列MPSOC拥有更大的优势。采用MPSOC异构结构同时简化了开发过程,PS部分为主控部分,可以先行验证速算法的可行性,之后利用FPGA部分对算法进行硬件加速,提高算法性能。在开发工具方面,Xilinx提供的vivado系列工具极大地简化了开发流程。本文同时对系统环境进行了搭建,具体工作包括利用Petalinux制作Linux系统,编译与移植OpenCV库及百度开发的深度学习接口工具PaddleLite等。MPSOC平台外接的硬件设备包括USB摄像头与HDMI显示器,分别用于对图像进行采集与结果显示。
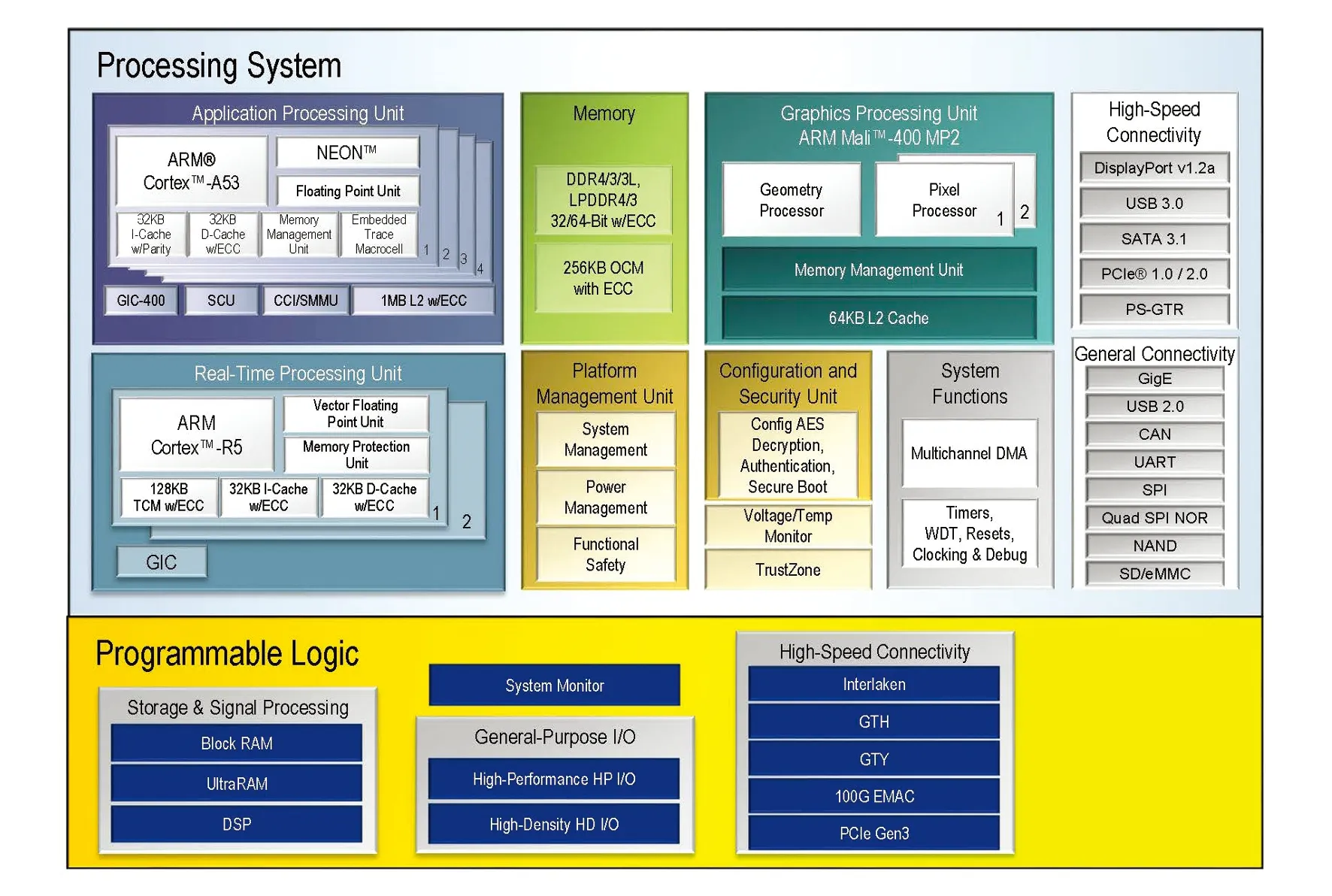
图6 MPSOC资源介绍[17]Fig.6 Introduction to MPSOC hardware resources
对优化前后模型的性能进行分析,评价指标为平均准确率(Average Precision,AP)和召回率。其中AP用于衡量模型对某一类的检测精度。对图7和图8比较可以发现,大多数类别的AP都有所上升。这是由于去除一个降采样过程后,不只是小目标的特征得到了更好的表达,识别难度不大的大目标特征也能得到更好的表达。
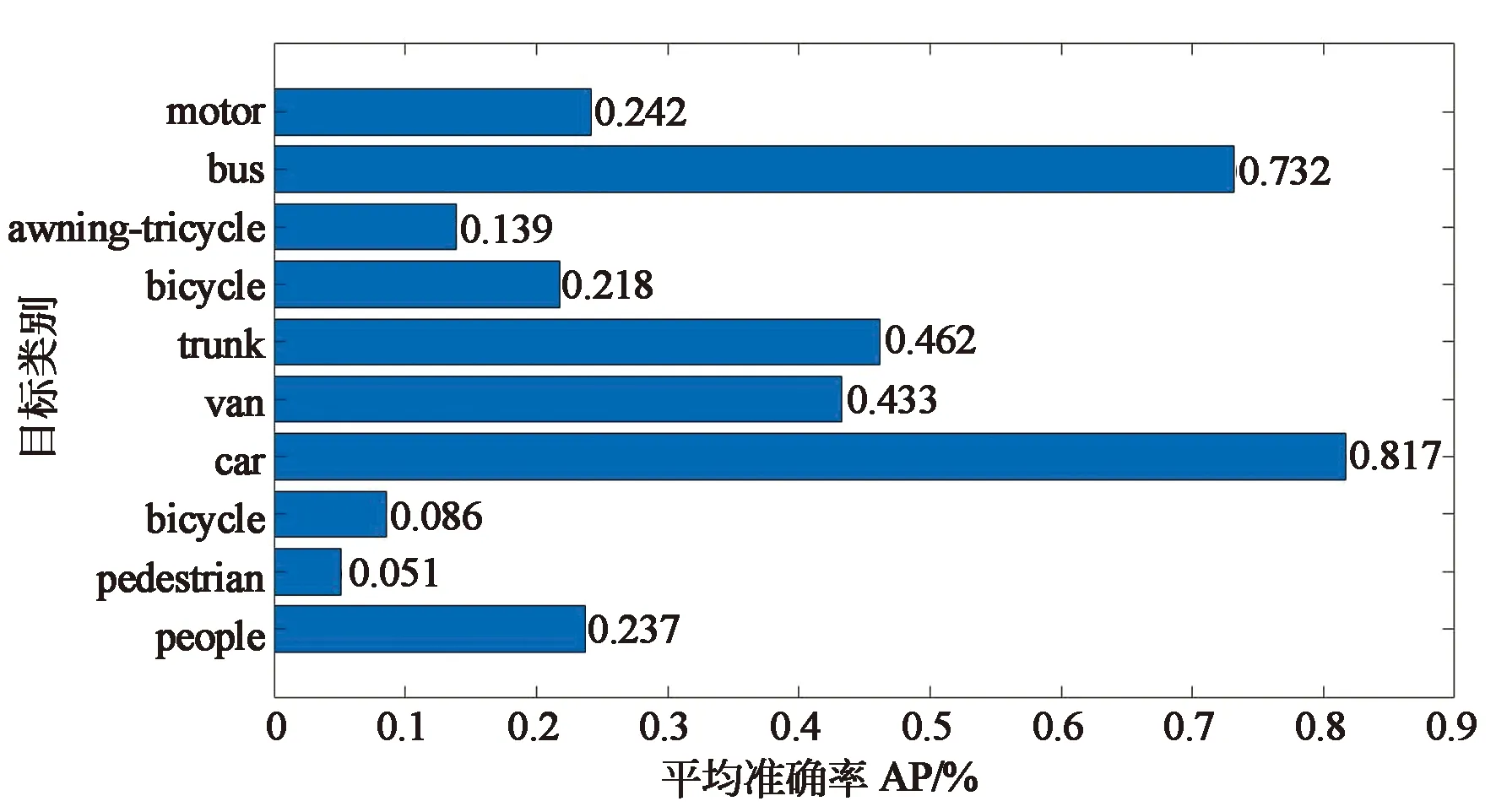
图7 优化前模型APFig.7 AP index of the model before optimization
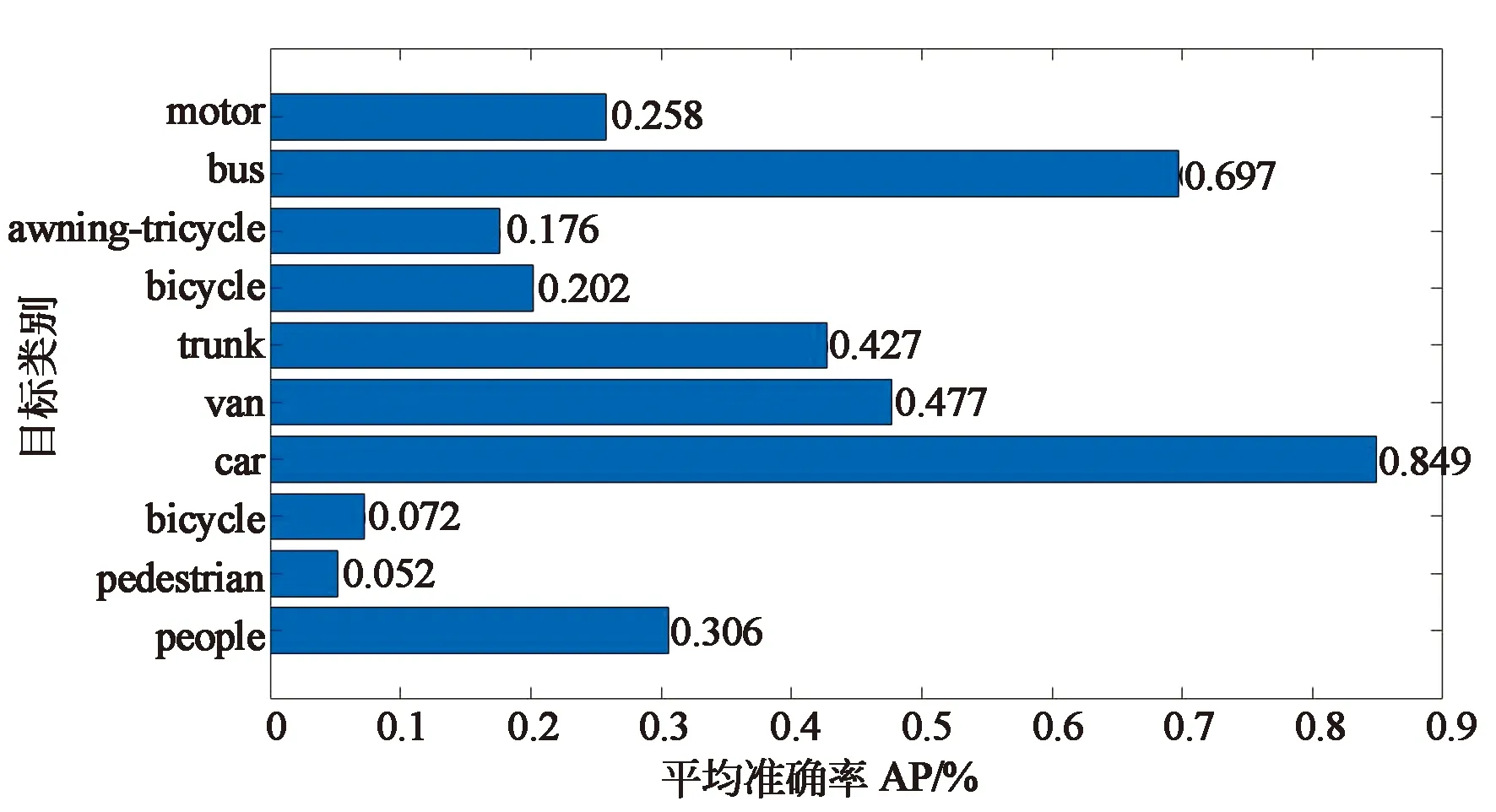
图8 优化后模型APFig.8 AP index of the optimized model
另一个评价指标为召回率。召回率用于描述阳性样本经过模型后的输出结果依旧为阳性的样本占所有阳性的比例。每一类的召回率所取的值为P-R曲线中最小非零精确度所对应的召回率。从图9可以发现优化后模型的各个类的召回率都有所上升。其中对于car这一类目标的召回率达到了93%以上。在图10中横坐标为模型回归所得到的预测框的数量和数据集中实际拥有边框的比值。以people为例,其验证集中共有目标21 006个,优化前模型检测出的people类共有8 053个,优化后模型检出4 946个,所以其横坐标分别为0.38和0.23。结合图9可以发现,优化前的模型可以检测较多的people预测框,但是其召回率却不高,这意味着将很多不是people的物体检测为people,误检率较高。而这种误检情况在优化前模型的各个类别中普遍存在。与原始模型相比优化后的模型误检率降低,准确度得到了较大地提高。
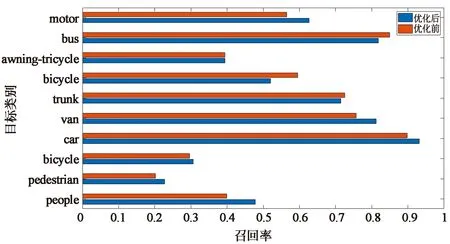
图9 优化前后模型召回率变化Fig.9 Change of model recall rate before and after optimization
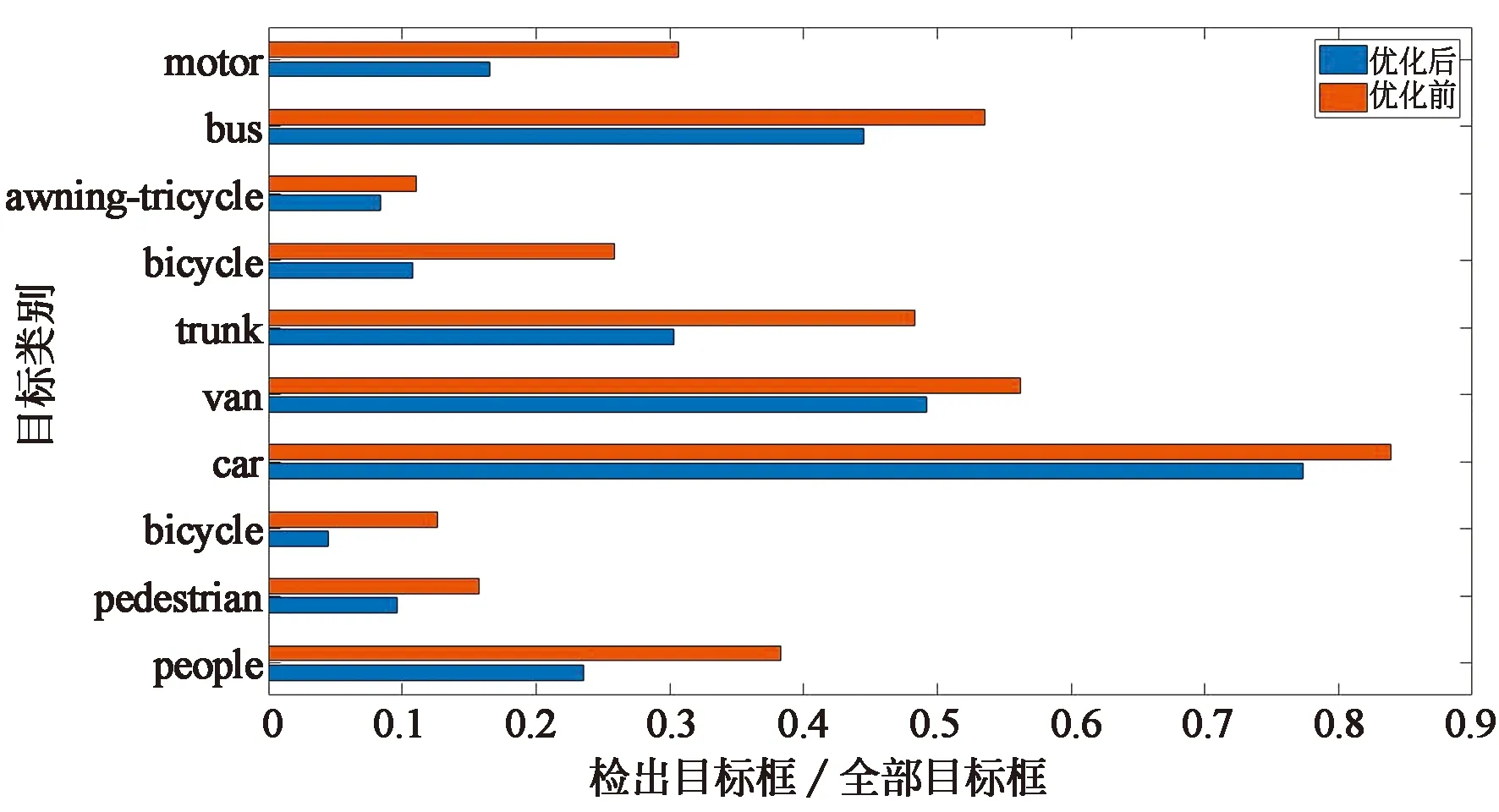
图10 优化前后模型回归边框数量变化Fig.10 Number of regression borders changed before and after optimization
图11所示为改进前后模型对同一张图片的检测效果的比较。左侧图(a)、(c)为原始模型检测结果,右侧图(b)、(d)为优化后模型的检测结果。可以发现无论是对于小目标还是大目标,优化后的网络检测精度都得到了明显提高。利用VISDRONE测试集对算法改进前后、剪枝前后的性能进行了统计比较。如表4所示,其中MAP50为10个类的AP50平均后的结果,可以得到优化后网络的MAP50提高了1.3%,性能甚至优于最新的YoloV4算法。通过基于敏感度的剪枝后模型MAP虽然有所下降,但在算法规模方面剪枝后网络却达到了91.9 M,是原模型246 M的37%。检测速度达到34.4 fps,是原模型的2倍。

(a)优化前模型检测结果一(a)Detection result 1 of the model before optimization

表4 模型性能比较Tab.4 Model performance comparison
同时将剪枝后的模型在MPSOC平台中进行了实景验证,搭建的实验平台如图12所示。该算法对视频序列中出现的一些较小目标也取得了较好的效果,相比较原始算法,速度方面也有了较大提升。对于接入的608×608图像,检测速度可以达到13 fps,基本满足航空图像目标检测的要求。与GPU平台相比,该平台可以在资源有限的情况下实现对航空图像中多类目标的检测,同时拥有更高的便携性和更低的功耗。

图12 MPSOC硬件平台Fig.12 MPSOC hardware platform
5 结 论
本文针对航空图像目标检测的特点,通过改变锚框和调整卷积层结构对Yolo V3算法进行优化,使算法的MAP提高了1.3%。同时利用基于敏感度的剪枝算法对模型进行压缩,参数规模变为原来的37%,检测速度提高了1倍。最后在MPSOC平台进行了实验验证,并取得了较好的检测效果。实验结果表明,该算法基本满足航空体图像目标检测的需求,同时系统平台也为深度学习算法在无人机端的移植奠定了基础。
猜你喜欢
保健医苑(2022年5期)2022-06-10
北京航空航天大学学报(2021年9期)2021-11-02
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
摄影之友(影像视觉)(2018年1期)2018-03-22
摄影之友(影像视觉)(2017年11期)2017-11-27
天津诗人(2017年2期)2017-03-16
小雪花·成长指南(2016年9期)2016-10-12
