
一种改进的深度确定性策略梯度网络交通信号控制系统
2021-07-15 09:10刘利军
四川大学学报(自然科学版) 2021年4期
刘利军, 王 州 , 余 臻
(1.厦门大学航空航天学院, 厦门 361101; 2. 厦门大学深圳研究院, 深圳 518057)
1 引 言
随着全球人口的快速增长,以及城市化进程的发展,专家预计21世纪的城市人口将急剧增加.当务之急是城市有效地管理其基础设施以应对这一问题.设计现代化城市时,一个关键的考虑因素是开发智能交通管理系统.交通管理系统的主要目标是减少交通拥堵.高效的城市交通管理能够节省时间和财务,并减少二氧化碳等大气污染物排放到大气中[1].已经有许多学者提出方案解决这个问题[2].主要道路的交叉路口一般是通过交通信号灯管理.低效率的交通信号灯控制会导致许多浪费,增加车辆发生事故的风险[3]. 现有的交通灯控制信号按照固定程序不考虑实时交通流量,效率低.因此,研究人员提出了许多改进方案,这些方案可以分为三类:第一类是预定控制程序,参考历史数据制定交通信号切换时间; 第二类是利用传感器检测来往车辆,用以延长或缩短信号切换时间; 第三类是自适应信号控制,根据交叉路口的当前状态自动切换[4].本论文对第三类控制方法展开研究,利用深度强化学习方法设计一种十字路口交通信号智能控制方法.
近年来,很多研究者结合深度学习和强化学习技术来处理复杂的优化问题,例如Atari 2600游戏[5],围棋[6]等.1997 年Thorpe[7]首次将强化学习的方法应用到交通信号控制,大家开始意识到强化学习为解决非线性、不确定性的复杂路网问题提供了一种新的思路.随着人工智能的快速发展,深度强化学习被应用到交通控制中.2016年Li等人将深度强化学习应用于交通信号控制中,降低了车辆14%的等待时间[8].2018年Liang等人[3]改进Dueling DQN[9]和DoubleDQN[10],将车辆等待时间降低了25.7%. 本论文通过分析交通环境特点, 设计了特征强化策略梯度算法(Feature Enhance DDPG,FEPG)算法并将其应用于交通信号控制系统中.
2 背 景
2.1 强化学习
强化学习的基本结构由智能体Agent和外界环境组成. Agent通过执行动作,从环境获得下一状态和奖励值.不断循环该过程,直到满足一定条件为止.通常一个强化学习问题可以视为马尔可夫决策过程(Markov Decision Process,MDP)[11]. MDP将强化学习任务定义为元组
(1)
以累积奖励为出发点,诞生了基于值的强化学习方法如Q-learning[12]等. 利用神经网络拟合Q函数.在策略π下Q函数的定义为式(2).
Qπ(s,a)=E[Rt|st=s,at=a,π]
(2)
结合卷积神经网络(Convolutional Neural Networks,CNN)[13],循环神经网络(Recurrent Neural Network,RNN)[14]强化学习的应用场景变得更为丰富.谷歌DeepMind工作室[15]于2015年提出了结合基于值的和基于策略方法优点的深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG).本论文将改进DDPG网络利用特征增强算法和样本去重环节提升网络性能,最后,将算法应用于交通信号控制中.
2.2 交通环境模型
十字交叉路口交通环境十分复杂, 且交通信号灯的控制十分重要.本文利用SUMO[16]仿真环境验证算法有效性.道路模型的参数如表1所示. 车辆的污染排放模型可参考文献[17].
2.2.1状态s描述 如图1所示十字路口状态模型.路口的4个车道被划分为4个单元,每个单元的长度为50 m. 单元格下方有白,灰色两个方格.若某个单元内有n辆车,白色方格内数字则为n, 灰色方格代表该单元内车辆的平均速度,若n为0则平均速度取0, 否则取n辆车速度的平均值如式(3).因此状态维度为32,如表2所示.

表2 状态向量表
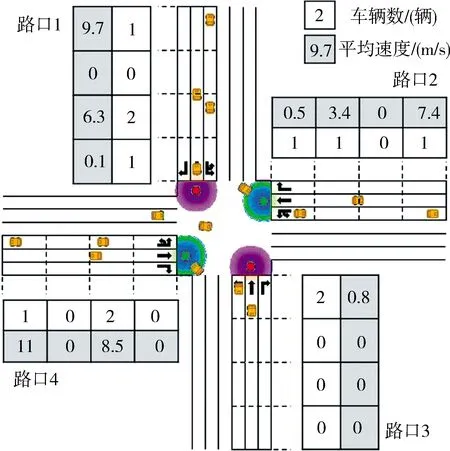
图1 状态描述Fig.1 State description
(3)
2.2.2动作a描述 如表3所示, 十字交叉路口的交通信号灯由6个信号相位组成.相位按顺序从1号变化到6号不断循环.每个相位由4个字母组成.每个字母代表一个路口信号灯的状态. 其中:G为绿灯,允许通行;R为红灯,禁止通行;Y为黄灯,注意通行.例如相位GRGR表示此时1、3路口绿灯,2、4路口红灯. 将1和4相位时间作为动作a.考虑到车辆行驶速度,其范围为5~50 s.其余相位设为安全的固定值.
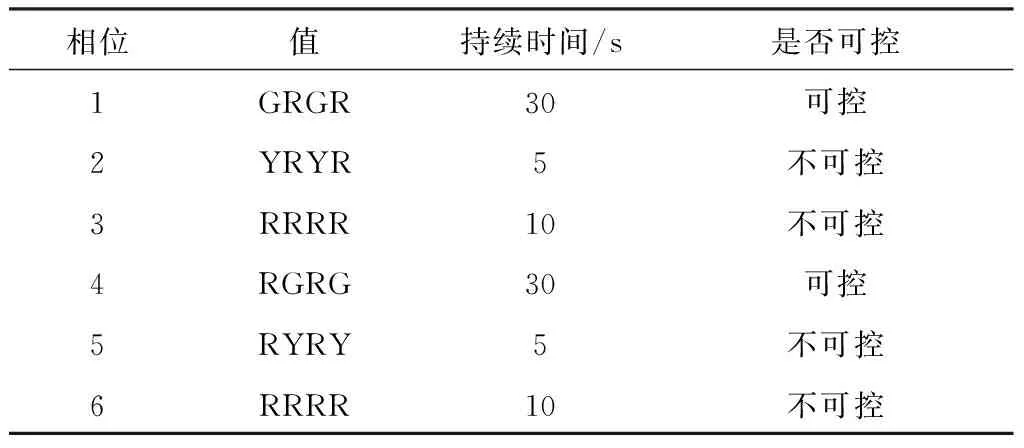
表3 交通信号相位
2.2.3奖励值r描述 奖励值在强化学习中的作用为提供网络训练方向,本论文目的为提高车辆在十字路口的通行效率,减少车辆等待时间.每辆车的等待时间定义为其行驶速度为0时所持续的时间,记作d,所有路口等待的所有车辆的累计等待时间记作D. 在t时刻的累计等待时间为Dt.奖励值定义如式(4)所示.
(4)
其中,n,m为t,t+1时刻路口等待的车辆数目;k为常数;r越大, 代表减少的等待时间越多, 反之越少.算法的目的为尽量增大奖励值r.
3 FEPG算法设计
DDPG网络由策略网络A,价值评价网络C组成.其中策略网络A分为A-online和A-target两个网络,其参数分别表示为θ,θ′.评价网络分为C-online和C-target两个网络,其参数分别表示为φ,φ′.本论文针对交叉路口环境的特点提出两点改进: (1) 交叉路口的状态维度为32, 其中可能存在对训练结果无贡献维度. 利用基于信息增益的特征增强算法, 自动优化状态; (2) 在DDPG算法中,经验池是样本的唯一来源,保持经验池样本的多样性有利于网络收敛. 网络训练时按照余弦相似度算法随机丢弃样本.本论文中将改进的DDPG网络框架简称为FEPG(Feature Enhance DDPG)网络,如图2所示. FEPG算法首先从预训练阶段开始,预训练阶段的主要目的是进行原始样本采集, 并应用特征增强算法和样本去重算法.特征值增强和样本去重算法的原理如下.
(1) 特征增强算法:由于交通环境的状态量维度较高, 其中很可能存在干扰收敛的无关维度. 特征增强算法的核心思想是通过样本的信息增益来筛选合适的特征. 将状态s表示为向量s={x1,x2,...,x32}.特征筛选算法目的是降低不相关特征对训练的影响. 经验池在算法的预训练阶段将累积n组样本. 对于随机变量X, 可以求其信息熵:
(5)
以及给定条件Y下的条件熵:
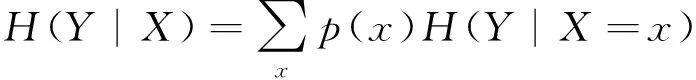
(6)
信息增益则可以表示为
IG(Y|X)=H(Y)-H(Y|X)
(7)
信息增益越大说明随机变量X对于Y的贡献越大. 信息增益用于计算离散变量, 因此将奖励值和状态离散化, 状态的第i个维度的信息增益可以表示为
hi=IG(R|Xi)
(8)
(9)
(10)
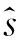
(2) 样本去重算法:样本去重的目的为保持样本的多样性, 加快算法收敛. 新进加入的样本与样本池中的样本随机比对相似度. 相似度越高, 样本被丢弃的可能性越高.相似度利用样本间的余弦值表示,丢弃概率表达式如式(11),其中α为丢弃系数.
(11)
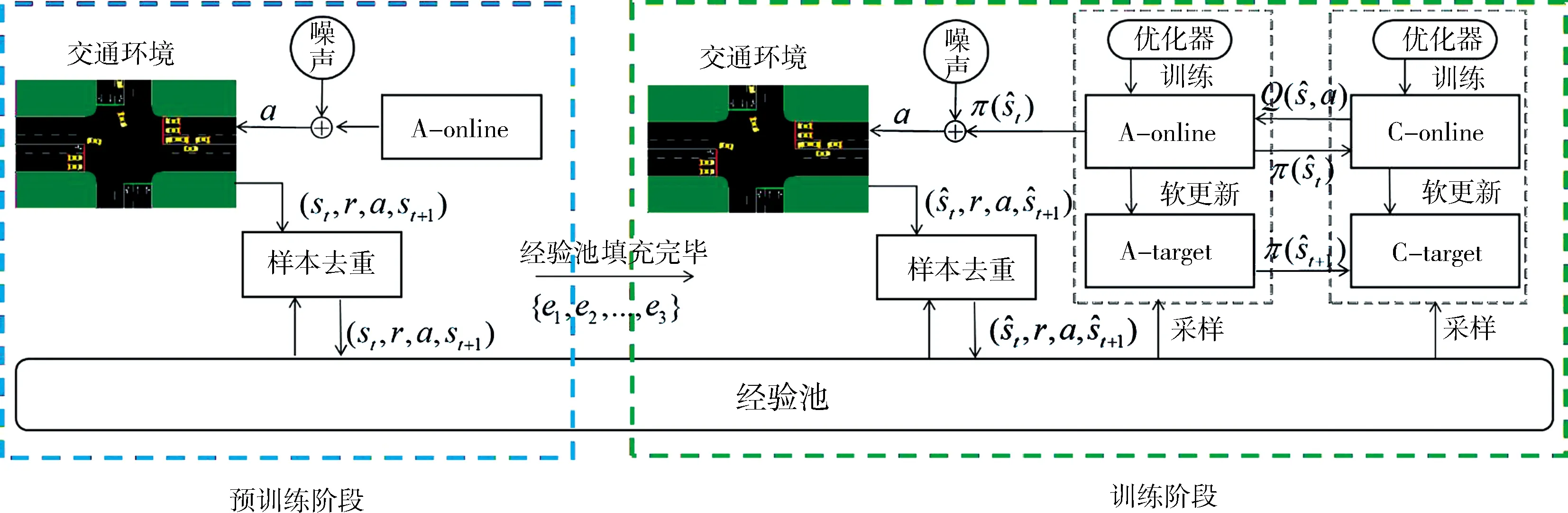
图2 FEPG算法结构Fig.2 FEPG algorithm structure
待数据采集完毕后接着进入训练阶段.训练阶段中4个神经网络相互作用,迭代.各个网络的作用和相互之间的关系如下.
(12)
θ′←τθ+(1-τ)θ′
(13)
(14)
φ′←τφ+(1-τ)φ′
(15)
式(12)和式(14)中m为训练batch大小,τ一般取0.01.以上对各个网络的描述可以知道target网络应当分别和online网络具有相同的网络结构.动作网络在输出时会添加均值为0,方差按指数规律衰减的高斯噪声. 目的是鼓励智能体在前期探索尽可能大的状态空间.根据以上对网络训练方法的分析, FEPG算法流程如算法1所示.
算法1FEPG算法流程
1) 初始化在线网络.并赋予随机权重θ,φ
2) 初始化目标网络θ′,φ′,初始化经验池R
3) forj= 1 toMdo
4) 随机初始化环境,获得初始状态s
5) fort= 1 toTdo
6) 动作网络添加衰减的高斯噪声输出动作a
7) Agent执行动作a并获得样本存入经验池
8) 根据式(11)进行样本去重过程
9) if经验池填充完毕
10) 根据式(8)和式(9)计算{ei}
11) if开始训练
12) 在经验池中采集m个样本并计算.
13) 使用最小化方差更新在线价值网络:
14) 使用策略梯度更新动作网络:
15) 采用软更新方式更新目标网络:
θ′←τθ+(1-τ)θ′
φ′←τφ+(1-τ)φ′
16) endfor
17) endfor
4 实 验
我们在上文所述的交通环境中验证算法有效性, 并且对比定时控制FTC (Fixed Timing Control), Pang等人的DDPG[18]控制方法, Genders等人的DQN[19]控制方法与本文的FEPG控制方法. 其中FTC为传统方法, DDPG和DQN为新型的强化学习方法.对比的核心指标为算法的收敛性能,车辆的平均等待时间以及车辆排放数据.
4.1 实验设计与FTC方法
如表4所示, 本文设计了4组实验, 分别是低车流密度低方差(Low Density Low Variance,LDLV), 低车流密度高方差(Low Density High Variance,LDHV), 高车流密度低方差(High Density Low Variance,HDLV), 高车流密度高方差 (High Density High Variance,HDHV). 车流密度指所有路口车辆数据, 方差指4个路口车流量值与平均值之差的平方和, 方差越高表示路口的车流密度差异越大. 车流密度数据可见文献[20].
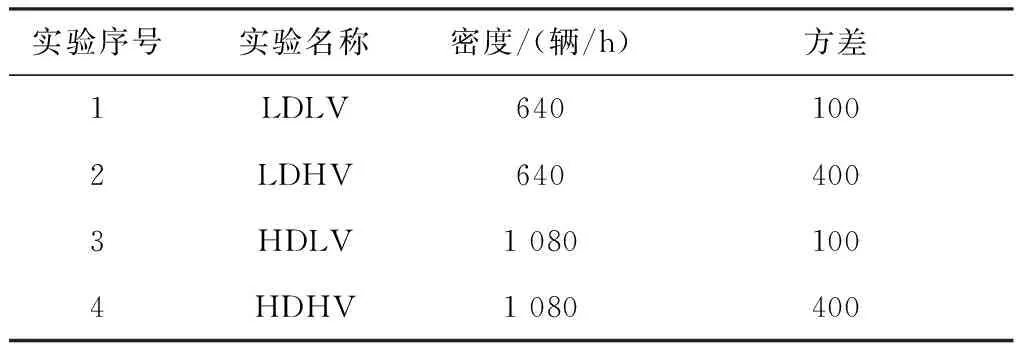
表4 车流类型
一般交通信号灯的相位采用FTC方法控制. 实验测试不同环境下所有车辆的累积等待时间与1和4动作相位间隔的关系, 每个间隔时间测试2 000 s,统计结果如图3所示. 在图3中用绿色标记了交通累积等待时间较短的区间.针对4组实验,将LDLV的固定间隔设置为30 s,LDHV的固定间隔设置为20 s, HDLV的固定间隔设置为35 s, HDHV的固定间隔设计为20 s.
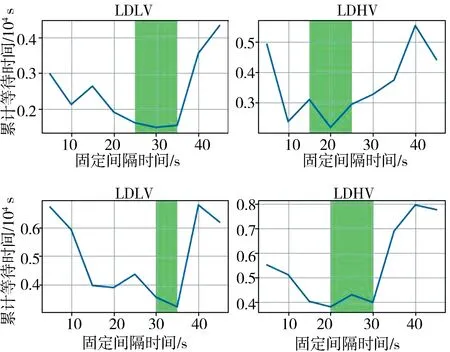
图3 不同信号灯间隔的平均等待时间Fig.3 Average waiting time at different signal time intervals
4.2 实验对比和结果分析
根据上文对环境的描述, 实验的状态维度为32,动作维度为1.设计FPPG网络参数如表5所示. FEPG, DDPG, DQN算法的经验池大小设为1万,Batchsize为100,折扣取0.9. 训练200轮,每轮执行200步后训练结果如图4所示.总体而言FEPG收敛最快性能最好, DDPG性能其次. DDPG控制算法中将每一个车道划分为多个单元,且需要保证每个单元内仅有一辆车,状态的维度为480. 其中很可能包含大量无效维度,导致其收敛不稳定,特别是在HDHV环境中表现不佳. DQN控制算法的输出动作值为离散变量. 实验中将输出动作按5 s一个间隔进行划分.其输出量不连续无法精确控制, 导致其效果最差.
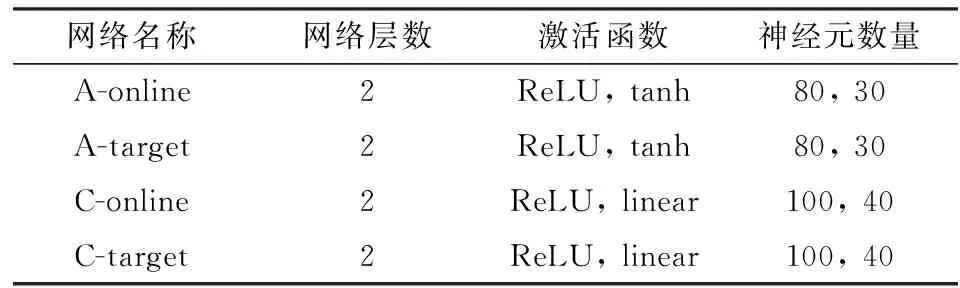
表5 网络结构参数
将训练完毕的网络在4个实验环境中进行测试, 测试时间为8 000 s. 图5统计了8 000 s时间内不同算法每辆车的平均等待时间.LDLV和LDHV统计了约1 500辆车, HDLV和HDHV统计了约2 500辆车.统计结果表明FEPG算法控制下的车辆等待时间平均比BFI降低了23.5%, 比DQN算法降低9.8%, 比DDPG算法降低了7.6%. 结果表明FEPG算法学习到了如何高效的控制交通信号, 证明了算法的有效性.
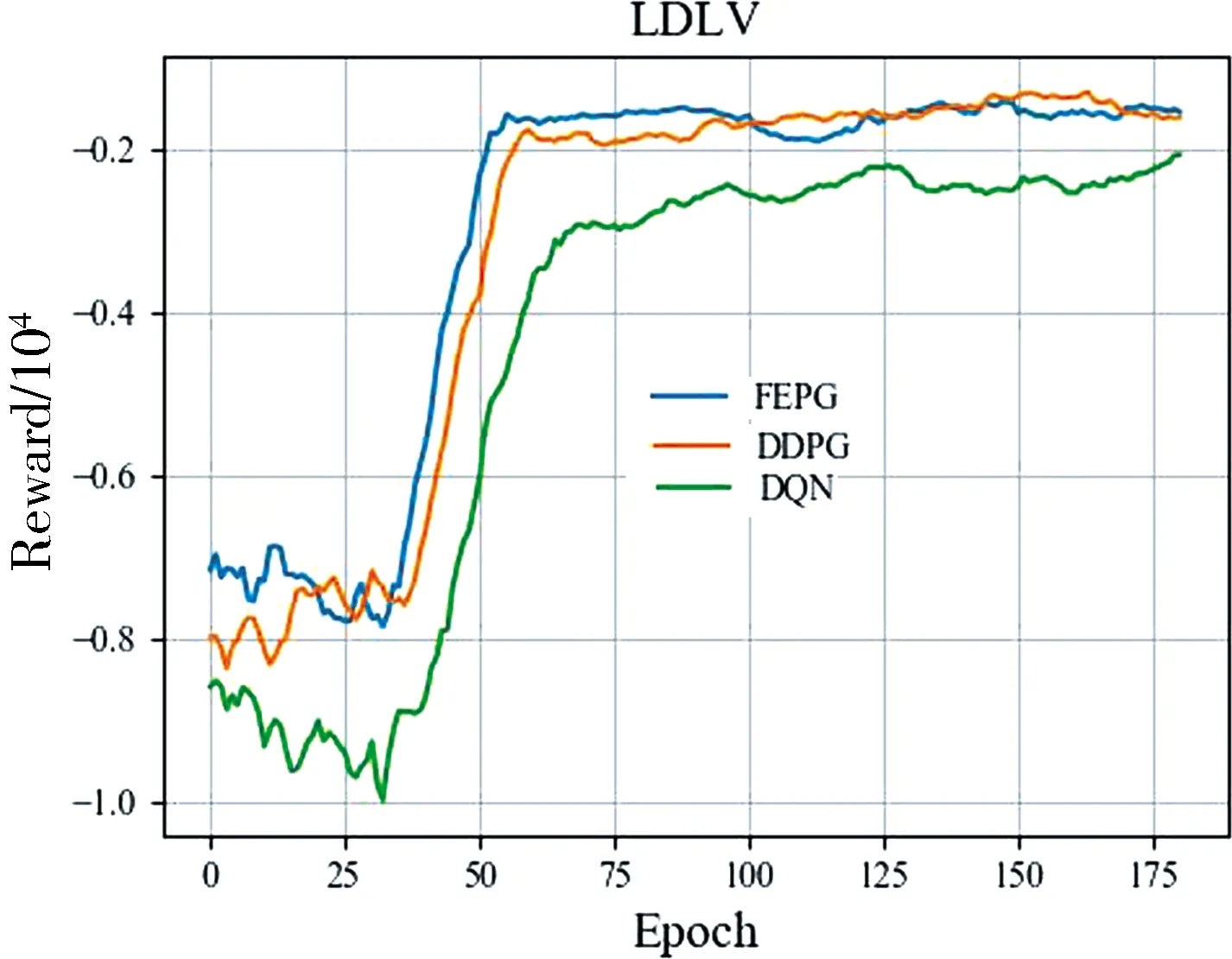
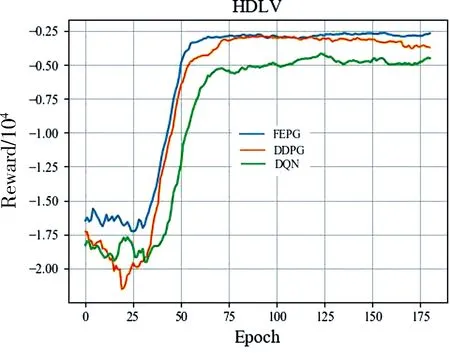
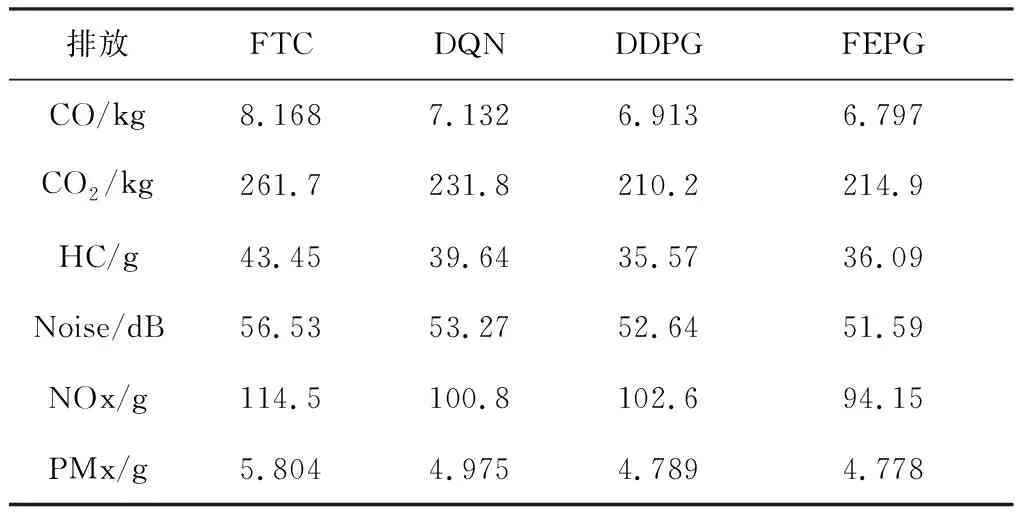
表6 污染物排放对比
以HDLV环境为例,表6是FEPG算法组对比其他算法在的污染排放情况.通过SUMO提供的数据统计了8 000 s内1 500辆车的污染排放情况. 依次是一氧化碳、二氧化碳、碳氢化合物、汽车噪音、氮氧化合物、和颗粒物排放.其中噪声为8 000 s内平均值, 其余为累计值. 相比FTC算法, 使用FEPG算法使污染排放比FTC平均降低了19.7%, 比DQN算法降低了6.3%,比DDPG算法降低了3.6%.说明FEPG算法在提高通行效率的同时也降低了污染的排放.
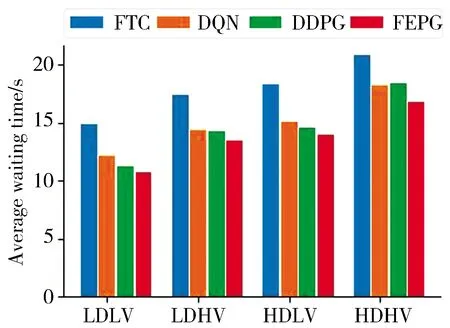
图5 平均等待时间对比Fig.5 Comparisonof average waiting time
5 结 论
面对大城市日益严重的交通拥堵情况, 本论文设计了一种强化学习算法控制十字路口交通信号灯.基于DDPG算法结合特征增强算法和样本去重算法设计了FEPG算法. 改进算法相比文献[18]的DDPG算法和文献[19]的DQN收敛的更快.以典型的十字路口交通信号灯为例,设计多组实验验证算法有效性. 实验结果表明FEPG网络在提高通行效率的同时也降低了汽车污染物排放.高效状态特征选择可以提高强化学习成功率, 交通环境中的数据多种多样,后续研究的一个方向是如何在更加复杂的交通网络中选取有效的环境特征.
猜你喜欢
当代陕西(2022年4期)2022-04-19
工业设计(2021年8期)2021-09-13
当代陕西(2020年22期)2021-01-18
西部交通科技(2021年9期)2021-01-11
商业评论(2020年3期)2020-06-15
铁道通信信号(2020年8期)2020-01-05
中华诗词(2019年7期)2019-11-25
发明与创新(2016年34期)2016-08-22
视野(2015年14期)2015-07-28
读者(2015年12期)2015-06-19

- 四川大学学报(自然科学版)的其它文章
- 一类二阶非线性常微分方程组边值问题解的存在唯一性
- Pullback attractors for lattice FitzHugh-Nagumo systems with fast-varying delays
- 定常Navier-Stokes方程的三个梯度-散度稳定化Taylor-Hood有限元
- On the crossing periodic orbits of a piecewise linear Liénard-like system with symmetric admissible foci
- 激光波形优化产生水窗区单阶谐波
- 基于多模板模糊竞争的涉案财物关系抽取方法