
基于多模板模糊竞争的涉案财物关系抽取方法
2021-07-15 09:10李攀锋蒋宗神
四川大学学报(自然科学版) 2021年4期
李攀锋, 林 锋, 蒋宗神
(四川大学计算机学院, 成都 610065)
1 引 言
关系抽取是知识工程领域的重要任务之一,也是知识图谱构建的核心步骤.它的目的在于从无结构的自然语言文本中抽取出结构化的知识,得到文本内含的语义关系,进而用于知识库的构建、智能问答、推荐系统等.
目前常见的关系抽取方法主要分为三种:(1) 基于模板匹配的方法[1];(2) 基于监督学习的方法[2];(3) 基于半监督或无监督的方法.
随着机器学习和深度学习的发展,基于监督学习和半监督学习的关系抽取方法应用十分广泛[3].Zeng等[4]在2014年首次提出采用卷积神经网络来提取句子的语义特征,进而实现关系抽取;Zhang等[5]在2015年采用了双向长短期记忆网络并借助依存分析和命名实体识别来解决关系抽取问题;谌予恒等[6]在2020年采用了结合注意力机制与残差网络进行远程监督关系抽取.这些方法大多用于处理如人物关系之类的关系抽取问题,因为在这种场景下,关系类别明确、训练语料丰富[7].但本文提出的关系抽取方法是为了解决涉案财物知识库构建的特定问题,即是立足于抽取“业务单位实体”与“财物实体”之间存在的“处置方式”关系.受限于涉案财物知识库场景训练语料少且单一以及识别准确率要求高的特点,机器学习的关系抽取方法在涉案财物领域并不适用,而采用基于模板匹配的方法更为合理.
本文提出的基于多模板模糊竞争的涉案财物关系抽取方法,根据涉案财物处置的实际场景需求,在常规三元组关系的基础上扩充了“财物状态”和“处置条件”两个属性元素,定义为五元组关系,以不同维度设计了三个关系抽取模板,从法律法规文本自动抽取五元组关系,并运用模糊逻辑计算各个模板抽取结果的置信度,使得三个模板间相互竞争,进一步提高抽取结果的准确度.
2 基本概念与任务描述
2.1 涉案财物知识库
涉案财物知识库指在根据现有法律法规自动完成刑事案件中涉案财物处置的相关知识融合,为司法实践中公检法等执法司法单位的办案人员提供支持[8].核心的工作是从法律法规出发,抽取出“业务单位实体”与“财物实体”之间的处置关系.由于该领域的特殊性,在创建知识库过程中完成关系抽取面临着的挑战如下:
(1) 训练语料少且单一.涉案财物知识库的构建目标是基于法律法条自动完成知识抽取,语料主要来源于正式实施的法律法规中与涉案财物处置相关的法条,这造成进行关系抽取时训练语料不仅远远少于通用知识库,也少于一般的法律知识库.
(2) 识别准确率要求高.涉案财物知识库的应用目标是为司法实践中的一线办案人员提供支持,这对知识库中知识的准确性提出了极高的要求.为保证知识库的正确性和减少后续工作,关系抽取算法的抽取准确率应尽可能提高.
上述问题使得涉案财物知识库构建过程中的关系抽取区别于一般关系抽取,成为了一个独特的、挑战性的问题.
2.2 涉案财物关系概述
实体关系三元组是由头实体、尾实体、实体间关系组成[9].在人物关系领域,即是形如[“姚明”,“叶莉”,“夫妻”]这样的人物关系三元组,其中“姚明”为头实体,“叶莉”为尾实体,“夫妻”为实体间关系[10].
在涉案财物领域,关系三元组稍有不同.在法律法规文本中,财物实体和业务单位实体直接存在着某种处置关系,如[“公安机关”,“涉案财物”,“扣押”],其中“公安机关”为头实体,“涉案财物”为尾实体,“扣押”关系同时作为一种处置方式,本质上是“公安机关”作为主语,对宾语“涉案财物”实施“扣押”动作.由此形成了包括“业务单位实体”、“处置方式”、“财物实体”的三元组关系模式,对应于司法实践的具体任务,即是公安机关在办理各类刑事案件以及检察机关在职务犯罪案件侦查过程中,对与案件有关的物品、款项等依法进行扣押、查封、冻结等操作.
基于法律法规的涉案财物关系抽取即是从法律法规文本中抽取出涉案财物处置的规则信息.这种规则信息对于司法实践中涉案财物的智能管理有着重要的意义.考虑到司法实践的严谨性,单纯的三元组信息并不能较好地反映业务单位执行涉案财物处置的具体情形.因此,本文在传统三元组关系的基础上,针对涉案财物处置实际场景,为“财物实体”增加了“财物状态”属性,为“处置方式”增加了“处置条件”属性,形成了形如[“业务单位实体”,“处置方式”,“处置条件”,“财物实体”,“财物状态”]的五元组关系模式.
2.3 涉案财物关系抽取任务
在与涉案财物处置相关的法律文件中,法条准确地描述了在何种情况下某个机构可以对某种财物实施特定的处置.涉案财物关系抽取任务即是从法条文本中自动抽取出这种处置规则.即是抽取出形如[“业务单位实体”,“处置方式”,“处置条件”,“财物实体”,“财物状态”]的五元组关系.
在目前常规的关系抽取任务中,往往采用基于神经网络的方法,本质上是将抽取问题转化为了分类问题[11],在诸如人物关系这种关系类型确定的场景下效果较好,由于本文研究的涉案财物关系抽取任务特殊,难以转化为分类问题,采用模板匹配的方法进行抽取,抽取的五元组示例如下.
对法条文本:“人民法院在必要的时候,可以采取保全措施,查封、扣押或者冻结被告人的财产.”内含如表1所示的五元组关系.

表1 五元组关系
在上述例子中,实体与关系之间的相对位置较为常规,且各元素成分相对独立,抽取过程中干扰信息较少.
但对另一个法条文本:“对查封、扣押的财物、文件、邮件、电报或者冻结的存款、汇款、债券、股票、基金份额等财产,经查明确实与案件无关的,应当在三日以内解除查封、扣押、冻结,予以退还.”
该法条中语法结构有所不同,财物实体进行了前置,且财物状态搭配复杂,抽取难度较大.
可见,在涉案财物关系抽取任务中,由于语言习惯的差异,单个模板难以较好地应对不同结构的法条,因此有必要从不同维度设计多个模板,以应对不同的语言现象.但由此产生了另一个问题,即多个模板抽取的结果如何整合的问题.本文为此提出了一种基于模糊逻辑的方法,以评判多个模板抽取结果的置信度,竞争得出质量较优的结果.
3 基于多模板模糊竞争的关系抽取
3.1 数据预处理
涉案财物关系抽取的初始数据是法律文件,但模板匹配的处理对象是单句法条,因此,需要对初始法律文件进行预处理,以适配模板匹配,处理流程如图1所示.
首先,对输入的法律文件进行段落解析,得到段落集A,对于每一个段落,判断其是否是居中的标题,若是则忽略该段落,否则利用正则表达式提取法条序号及法条内容.通过以上步骤得到了带有序号标记的法条集A′.后续根据涉案财物处置相关的特征词过滤掉与涉案财物处置无关的法条,得到最终有效的法条集A″.

图1 预处理流程图Fig.1 Flow chart of preprocessing
3.2 模板设计
3.2.1 模板设计基础说明 本文以不同的维度设计了三个抽取五元组关系的模板.下面就三个模板的公共部分做说明.
模板输入输出:1) 输入:T、W1、W2、W3、W4、W5;2) 输出:R.其中,T为输入的法条文本;W1、W2、W3、W4、W5为人工整理的词典[12](W1为财物实体词典;W2为业务单位实体词典;W3为触发词典;W4为处置方式词典;W5为财物状态词典).R为输出的5元组关系集合.
模板伪代码中将用到的重要函数如表2.

表2 函数说明
3.2.2 模板1设计 模板1是以词为单元进行匹配,首先确定财物实体的位置,以此为中心检索其余4个元素.具体匹配规则如下.
输入:T、W1、W2、W3、W4、W5
输出:R
(1)W← cut_w(T)
(2)p← DTW(0,len(W),W,W1)
(3)t← DTW(0,len(W),W,W3)
(4)P← PTW(0,len(W),W,W1)
(5) ift≤pthenf← True
(6) end if
(7)C← {GCT(min(t,p),max(t,p),W)}
(8)S← PTW(p,0,W,W5)
(9) iffis not True then
(10)M← PTW(t,len(W),W,W4)
(11) else
(12)M← PTW(p,len(W),W,W4)
(13) ifM== ∅ then
(14)M← PTW(t,p,W,W4)
(15) end if
(16) end if
(17)G← PTW(t,0,W,W2)
(18)R←P×G×M×S×C
(19) returnR
3.2.3 模板2设计 模板2同样是以词为单元进行匹配,但首先确定的是业务单位实体的位置,以此为中心检索其余4个元素.匹配规则如下.
输入:T、W1、W2、W3、W4、W5
输出:R
(1)W← cut_w(T)
(2)G← PTW(0,len(W),W,W2)
(3) ifG≠ ∅ then
(4)n1← DTW(0,len(W),W,W2),n2← 0
(5) elsen1← 0,n2← len(W)
(6) end if
(7)P← PTW(n1,n2,W,W1)
(8)t←DTW(0,len(W),W,W3)
(9)S← PTW(t,0,W,W5)
(10)M← PTW(t,len(W),W,W4)
(11)s← DTW(t,0,W,W5)
(12)C← {GCT(s,len(W),W)}
(13)R←P×G×M×S×C
(14) returnR
3.2.4 模板3设计 模板3是以子句为单元进行匹配.模板3中认为业务单位实体与处置方式应当同属一个子句,财物实体与财物状态属性应当同属一个子句,处置条件属性单独属于一个子句.具体匹配规则如下.
输入:T、W1、W2、W3、W4、W5
输出:R
(1)Q← cut_c(T)
(2) selectqinQthat 包含业务单位实体或处置方式
(3)Q←Q- {q}
(4)W← cut_w(q)
(5)G← PTW(0,len(W),W,W2)
(6)M← PTW(0,len(W),W,W4)
(7) selectqinQthat 包含财物实体或财物状态
(8)Q←Q- {q}
(9)W← cut_w(q)
(10)P← PTW(0,len(W),W,W1)
(11)S← PTW(0,len(W),W,W5)
(12) selectqinQthat 包含处置条件
(13)Q←Q- {q}
(14)W← cut_w(q)
(15)P← {GCT(0,len(W),W)}
(16)R←P×G×M×S×C
(17) returnR
3.3 模糊竞争
3.3.1 数值化 本文拟利用模糊逻辑对模板抽取出的五元组关系进行打分,进而实现多个模板间抽取结果的奖惩机制,综合胜出置信度较高的五元组关系.鉴于模糊逻辑适用于数值计算[13],而五元组关系为文本数据,加之初始抽取的五元组关系存在空值干扰,因此,首先定义五元组各元素补全方法及数值化方法.
(1) 初始抽取数据如下所示.
(2) 补全过程:
1) 通过实验数据确定三个模板初始置信度:w1,w2,w3;
2) 对于{a,b,c,d,e}中的每一种元素x:
(a) 筛选出x1,x2,x3中的非空元素,记作集合R;
(b) 选出集合R中对应模板置信度最大的元素r;
(c) 用r补全x1,x2,x3中的空值元素;
(d) 若R为空集,则x1,x2,x3置为“空”.
(3) 补全后进行数值化,对于每一个元素xi,其数值化结果v计算公式如下.
x∈{a,b,c,d,e},i∈{1,2,3}
(1)
其中,sim为文本相似度计算函数,经实验尝试,摒弃了常规的基于词袋的余弦相似度方法,实际采用的相似度方法如下.
输入:s1,s2
输出:t
(1)Q← {},P← {},m← 0
(2) foriins1do
(3)Q[i] ←Q.get(i,0) + 1
(4) end if
(5) forjins2do
(6) ifP.contains(j) then
(7)n←P[j]
(8) else
(9)n←Q.get(j,0)
(10) end if
(11)P[j] ←n-1
(12) ifn> 0 thenm←m+ 1
(13) end if
(14) end for
(15)t←2*[m/(len(s1) + len(s2))]
(16) returnt
3.3.2 模糊化 通过数值化处理后,每个模板抽取的五元组关系均如以下格式:[abcde] ,其中,各元素均为0到1之间的浮点数.
在模糊化阶段,定义每个元素x均隶属于P、A、G三个集合.其中,P集合和G集合采用梯形隶属函数,A集合采用三角形隶属函数[14].如图2所示.
图2中,横轴为输入的元素浮点数值,纵轴为对应的各集合的隶属度.p1,p2,a,d,g1,g2为各隶属度函数的参数.
通过隶属函数模糊化后,得到五元组各元素隶属于PAG三个集合的隶属度,如图3所示.

图2 隶属函数图Fig.2 Image of membership functions

图3 隶属示意图Fig.3 Diagram of affiliation
3.3.3 规则化 通过模糊化处理后,需要根据模糊规则和模糊逻辑的运算进行重新组合.五元组各元素均隶属于PAG三个集合,五种元素不同隶属集合组合情况共有35种,如下所示.
对于每一种组合,通过规则指定最终的隶属集合以及相应的隶属度.为减少模糊规则数量,本文简化规则如下.
1) 定义.
w(Px)=0,w(Ax)=1,w(Gx)=2,
x∈{a,b,c,d,e}
(2)
2) 对于任意一种组合:
S=(Ya,Yb,Yc,Yd,Ye),Y∈{P,A,G},

(3)
3) 隶属集合:
(4)
4) 隶属度:
V(S)=min(Ya,Yb,Yc,Yd,Ye)
(5)
3.3.4 去模糊 通过规则化处理后,得到了各种组合情况下对应的隶属集合以及隶属度,借助去模糊化将其转化为最终评判五元组关系质量的数值.
本文采用加权平均判决法.
(6)
其中,FSi为规则化阶段得到的隶属度;OWi为对应隶属集合的权重系数.在本文中,取值如下.
(7)
其中,p2,a,g1为图2中隶属度函数参数.
3.3.5 模板竞争 三个模板抽取的五元组关系通过上述模糊计算,得到三个output值,最高值对应的模板胜出,本次抽取结果以该模板为准.同时更新三个模板置信度,更新规则如下.
(1) 胜出的模板:
wi=wi+(1-wi)*0.001
(8)
(2) 其余模板:
wj=wj-wj*0.0005
(9)
4 实验与评估
4.1 实验数据
本文的实验数据来自“法律法规数据库”,共选取了10个与涉案财物处置相关的法律文件,其中1~4号文件用于模板初值置信度确定,5~10号文件用于算法效果测试.
通过人工对上述法律文件进行整理,共标定五元组数据1 450条.数据格式:[文件名,法条序号,法条内容,五元组].
4.2 评价指标
本文使用正确率作为评价指标对关系抽取的效果进行评估.考虑到五元组关系的特殊性,定义:
有测试结果S=[s1,s2,…,si],标定数据K=[k1,k2,…,ki].若匹配度q>0.6,则认为抽取成功.
(10)
正确率的计算方法如下.
(11)
本文同时进行了3元组和5元组抽取效果的评估,在计算3元组正确率时,i=3,计算5元组正确率时,i=5.
4.3 实验结果
本文利用选取的涉案财物处置相关的法律文件,对基于多模板模糊竞争(MTFC)的方法进行了实验,同时将其与单模板抽取方法(模板1、模板2、模板3)、基于非空元素数量的投票方法(NONV)进行对比.
首先,我们运用三个模板分别对1~4号文件进行关系抽取,三元组抽取正确数目的比值约为33∶37∶30.因此,我们设定三个模板初始置信度:
w1=0.33;w2=0.37;w3=0.3.
在基于多模板模糊竞争方法的实验中,共有如下8个参数:p1,p2,a,d,g1,g2(图2隶属度函数参数);k1,k2(式(4)模糊规则参数).
为降低参数选取难度,设定整数参数步距为1,浮点数参数步距为0.1,并将单轮实验参数调整数量限制为2个.实验表明,当p1=0.3,p2=0.5,a=0.5,d=0.2,g1=0.7,g2=0.9,k1=5,k2=8时,多模板模糊竞争方法有较优的效果.在5~10号法律文件上,各方法实验结果如表3和表4所示.可以看出,在8号文件上,多模板模糊竞争方法的五元组正确率没有明显的提升,但在其他情况下,多模板模糊竞争方法的正确率较其余方法,均有显著优势.总体来看,如图4所示,多模板模糊竞争方法对三元组及五元组关系抽取效果明显.
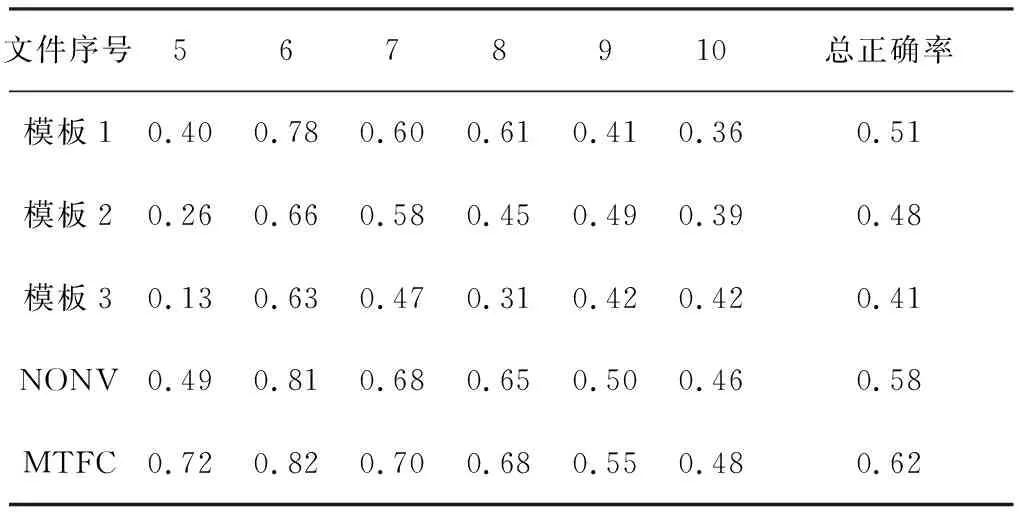
表3 三元组正确率

表4 五元组正确率

图4 综合正确率Fig.4 Comprehensive accuracy
5 结 论
本文提出了一种基于多模板模糊竞争的涉案财物关系抽取方法,从不同维度设计了三个涉案财物五元组关系抽取的模板,并借助模糊逻辑算法,竞争出较优的结果.实验表明,在涉案财物关系抽取任务中,基于多模板模糊竞争的方法效果优于单模板,也优于基于非空元素数量的投票方法.因此,可以在涉案财物知识库构建过程中引入该方法,以较好地适应其训练语料少且单一以及识别准确率要求高的特点,为后续知识推理奠定基础.
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
计算机与生活(2022年3期)2022-03-13
北京大学学报(自然科学版)(2022年1期)2022-02-21
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
计算机应用(2018年5期)2018-07-25
计算机系统应用(2017年5期)2017-06-07
中国科技纵横(2016年20期)2016-12-28
科技视界(2014年27期)2014-08-15

- 四川大学学报(自然科学版)的其它文章
- 一类二阶非线性常微分方程组边值问题解的存在唯一性
- Pullback attractors for lattice FitzHugh-Nagumo systems with fast-varying delays
- 定常Navier-Stokes方程的三个梯度-散度稳定化Taylor-Hood有限元
- On the crossing periodic orbits of a piecewise linear Liénard-like system with symmetric admissible foci
- 激光波形优化产生水窗区单阶谐波
- 一种改进的深度确定性策略梯度网络交通信号控制系统