
基于双重注意力机制的深度人脸表示算法
2021-07-15 02:00朱新丽李英超
吉林大学学报(理学版) 2021年4期
孙 俊, 才 华,2, 朱新丽, 胡 浩, 李英超
(1. 长春理工大学 电子信息工程学院, 长春 130022; 2. 长春中国光学科学技术馆, 长春 130117; 3. 长春理工大学 空间光电技术研究所, 长春 130022)
0 引 言
无约束环境下的人脸识别是计算机视觉领域一个极具挑战性的问题. 相同身份的面孔在不同的光照、 面部姿势、 面部表情和遮挡中呈现时, 看起来会不同, 甚至同一身份的这种变化可能比由于身份差异的变化更强. 为解决这些问题, 目前已提出了许多基于深度学习的人脸识别方法, 如DeepFace[1],DeepID[2-3]系列,FaceNet[4],SphereFace[5],CosFace[6],ArcFace[7]等. 这些方法通过将输入的原始数据映射到深层嵌入特征执行标签信息的特征学习和预测, 这些特征通常是最后一个完全连接层(FC)的输出, 然后利用这些深层特征预测标签. 但这些方法在其应用程序中整体地使用深层嵌入特征, 而用了哪些特征及其意义不明确.
在无约束环境下的人脸识别任务中, 深度学习和嵌入特征不仅需要可分离, 还需要具有可鉴别性. 但这些特征是隐式学习的, 对于特征的哪部分是有意义的以及特征的哪部分是可分离和可区分的不明确, 因此, 很难知道用何种特征区分人脸图像的身份. 针对上述问题已提出了许多解决方法, 如通过学习多尺度表示区分特征中的潜在意义[8-9], 通过对低层特征和高层特征的结合提高人脸特征的鉴别能力[10], 通过注意力机制对有意义特征进行自注意[11-13]等. 但这些方法都是对低层特征设计的, 捕获低层的局部详细信息或小规模面部特征, 尽管会与高层特征结合, 却未对高层特征进行再设计.
卷积神经网络(CNN)在人脸识别方面表现较好[1-3], 但其只使用Softmax损失函数学习不能很好地区分特征. 为解决该问题, 目前已提出了几个判别性损失函数[4-7], 以鼓励最小类内分离和最大类间距离为目的, 但这些方法通常集中在如何改进损失函数, 以提高人脸的识别精度和传统的特征表示, 多数方法只是在广泛使用的骨干网络后附加几个完全连接层而未对人脸识别特征进行设计, 使得这类算法只有微小的变化, 如增加几层或增加通道的数量, 通常不会有明显改善. 本文通过引入注意力机制对人脸特征进行设计, 实现高质量可鉴别的人脸特征表示方法.
注意力机制在计算机视觉领域[14]应用广泛. 其通过扫描全局图像, 获得重点关注区域, 抑制其他无用信息, 从而提高视觉信息处理的效率与准确性. SENET[15]通过引入一个紧凑的模型, 利用平均池化的特性探索信道之间的相互依赖关系; CBAM[16]进一步结合最大池化特征推断更好的信道注意; BAM[17]使用空间和信道注意强调在哪里聚焦. 目前已有许多方法将注意力机制引入到人脸识别中, 如文献[11]提出了一种局部和多尺度卷积网络, 通过对空间和通道注意提高人脸特征质量; 文献[12]通过相关的局部外观特征对表示人脸特征; 文献[13]提出了一种金字塔多样化人脸注意网络, 在引入注意力机制的基础上, 消除了冗余特征. 但这些方法只注意了低层细节信息, 未考虑高层的语义信息.
基于此, 本文提出一种双重注意力机制网络, 通过对低层详细信息和高层语义信息的注意获取高质量、 独特并可鉴别的人脸特征, 网络结构如图1所示. 该网络首先通过细节注意力机制, 对特征金字塔中多尺度信息引入多个基于注意的局部分支, 自动强调不同尺度上的不同判别面部特征, 然后与最后一个卷积层的平均池化和全连接层进行拼接; 其次通过语义注意力机制对最后一个卷积层进行自适应语义分组, 根据人脸图片所属分组概率, 将分组特征加权生成语义特征; 最后将两种注意力机制得到的特征相加获得最终特征. 实验结果表明, 该双重注意力机制网络通过对低层多尺度细节特征和高层语义特征注意, 进一步提高了人脸特征的鉴别能力.
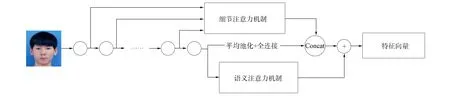
图1 双重注意力机制网络框架Fig.1 Network framework for dual attention mechanism
1 双重注意力机制
1.1 细节注意力机制
细节注意力机制是为了分层提取多尺度多样化的细节特征, 其由金字塔多尺度注意力和分层交互组成, 如图2所示. 由图2可见, 该网络通过左侧区域金字塔多尺度注意力学习定位多尺度判别面部区域, 由于姿势变化或表情变化过大, 面部部分可能有不同大小, 因此有必要表示不同大小的局部斑块, 以自适应地定位多尺度判别面部区域. 此外, 通过分层交互组合来自不同层次的互补信息, 即其使用不同的分层交互模块集成高级抽象和低级被忽略的信息.

图2 细节注意力机制网络结构Fig.2 Network structure of detail attention mechanism
1.1.1 金字塔多尺度注意力
图3为金字塔多尺度注意力框架, 由于金字塔多尺度特征在同层中, 因此有必要在不同尺度上校准特征. 设X∈h×w×c表示金字塔注意力的输入, 其中h,w和c分别表示特征映射的高度、 宽度和数目.

图3 金字塔多尺度注意力框架Fig.3 Pyramid multi-scale attention framework
1) 将特征映射分割成不同尺度的输出(X1,X2,…,XN), 其中N表示尺度的数目,Xi∈hi×wi×c表示ith的输出,Hi×Wi表示空间大小.


图4 LANet网络框架Fig.4 LANet network framework
3) 利用双线性插值, 在不同金字塔尺度(i∈{1,2,…,N})的多个局部分支(j∈{1,2,…,B})上采样不同的注意力掩码, 使其具有与输入X∈h×w×c相同的大小.
4) 第i个尺度的第j个局部分支的精细特征映射Rij由注意力掩码Mij和输入X的乘积聚合:

(1)
其中∘表示Hadamard积.
5) 通过第一级联B个局部分支及1×1卷积层, 输出c个特征映射, 得到i的输出.最后将不同尺度的特征映射串联, 作为金字塔注意力的输出.
1.1.2 分层交互
由于单层的表示不全面, 因此本文考虑多层次的层融合特征.设X∈h×w×c1和Y∈h×w×c2表示两个不同层的输出, 其中h和w分别表示特征映射的高度和宽度,c1和c2表示两个不同层的特征映射数.X空间位置的c1维特征表示为x=(X1,X2,…,Xc1),Y空间位置的c2维特征表示为y=(Y1,Y2,…,Yc2).为获得更全面的局部特征, 使用分层交互, 定义为

(2)
其中Wi∈c×c为投影矩阵,Zi为投影输出, ∘为Hadamard积.投影矩阵分解为两个秩向量Ui,Vi∈c.
为编码本地信息, 特征应通过线性映射扩展到高维空间.因此, 定义一个权重矩阵w=(w1,w2,…,wd), 以获得d维特征Z:
Z=UTx∘VTy,
(3)
其中U,V∈c×d,d表示投影特征的维数.
本文考虑从更多的层聚合特征, 获得更多的判别局部特征.设x1,x2,x3表示来自3个不同层的输出, 扩展到连接多个跨层表示为
Z=Concat(UTx1∘VTx2,UTx1∘STx3,UTx2∘STx3).
(4)
最后, 使用FC层将维数降至512.
1.2 语义注意力机制
语义注意力机制通过对人脸语义信息进行分组, 学习潜在的语义信息, 并将这些语义信息相结合, 实现更高质量的人脸特征. 其由N条组语义向量及其概率组成, 如图5所示, 其中左侧区域表示N条组语义, 右侧区域表示N条组语义对应的分组概率, 最后将概率和语义聚合生成语义特征.

图5 语义注意力机制网络结构Fig.5 Network structure of semantic attention mechanism
1.2.1 组语义概率
组语义概率表示人脸对所属分组的概率, 如图6所示, 其由3个完全连接层和1个Softmax层组成. 通过部署组语义决策网络计算向量中组概率. 组语义网络是以一种自分组的方式进行训练, 该方式通过考虑潜在群的分布而提供一个组标签, 没有任何明确的基本真实信息.

图6 组语义决策网络Fig.6 Group semantic decision networks
确定组语义标签的一种简单方法是获取一个具有Softmax最大激活度的索引输出. 本文构建一个组语义网络, 通过部署多层神经网络并附加Softmax函数确定给定样本x的归属组概率:

(5)
其中Gk表示第k组,f(x)表示组语义网络的输出.
1.2.2 组语义表示


(6)
1.3 特征表示


(7)
1.4 算法流程
图7为本文算法流程.先用MTCNN网络进行人脸及关键点检测, 再根据关键点对人脸进行对齐, 在特征提取中采用本文提出的双重注意力网络, 对ResNet100主干网络低层细节注意、 高层语义注意获取高质量判别性人脸特征, 最后与人脸特征库进行匹配.
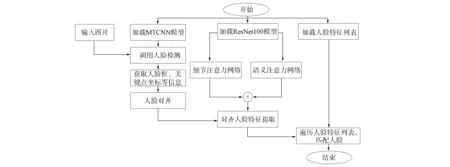
图7 本文算法流程Fig.7 Flow chart of proposed algorithm
2 实 验
2.1 实验数据
用MSCeleB-1M作为训练集, 其中包含约10 MB图像的100 KB身份. 由于MSCeleb-1M原始数据集的噪声标签, 本文使用改进的版本, 其中包含3.8 MB图像的85 KB身份. 用LFW,YTF,MegaFace,IJB-B和IJB-C作为测试集, 其中LFW包含来自5 749个身份的13 233张图像, 并提供来自它们的6 000对图像; YTF包括3 425张图像的1 595个身份的视频; MegaFace由来自690 KB身份的超过100万张图像组成; IJB-B包含67 000张人脸图像、 7 000张人脸视频和10 000张非人脸图像; IJB-C包含138 000张人脸图像、 11 000个人脸视频和10 000张非人脸图像. 对于评价指标, 本文对LFW和YTF数据集验证识别精度, 对MegaFace数据集通过Rank-1识别精度进行评价, 最后在IJB-B和IJB-C数据集上比较在一定的假接受率(TAR@FAR)下10-4~10-6的真接受率.
2.2 实验验证
采用ResNet100主干网络, 将Arcface作为损失函数. 图8为基线网络(A)、 细节注意力机制(B)、 语义注意力机制(C)和双重注意力机制(D)在2D空间上最终表示之间的定量比较. 本文在精化的MSCeleb-1M数据集中选择前10个标识并将提取特征映射到角空间, 10个彩色圆弧表示10个身份. 由图8可见, 本文的双重注意力机制模型生成了更独特的特征表示, 而不是基线模型, 并且该模型增强了基线模型的表示.

图8 ArcFace损失在MSCeleb-1M数据集中前10个身份的定量比较Fig.8 Quantitative comparison of ArcFace losses in top 10 identities of MSCeleb-1M dataset
不同方法在LFW和YTF数据集上的验证准确性和不受限制的标记外部数据协议对比结果列于表1. 在YTF数据集上, 本文评估了所有的图像, 并未排除图像序列中的噪声图像. 由表1可见, 虽然这两个数据集都是高度饱和的, 但本文的双重注意力方法仍超过了最优方法Groupface的0.02%和0.1%.

表1 不同方法在LFW和YTF数据集上的精度验证
下面在Large训练集协议下评估双重注意力机制方法, 其中R表示对MegaFace数据集精化版本的评估过程. 不同方法在MegaFace数据集的识别与验证评价结果列于表2. 由表2可见, 双重注意力机制比GroupFace方法在Rank-1评价指标中高0.21%, 在TAR@FAR=10-6(%)评价指标中高0.28%. 在精化版本的MegFace数据集上, 本文方法也优于其他模型.

表2 不同方法在MegaFace数据集的识别与验证评价结果
本文方法与其他方法在IJB-B和IJB-C数据集上的评估对比结果列于表3. 由表3可见, 本文的双重注意力方法在所有的FAR标准上均有明显改进. 在IJB-B数据集中, 比目前的最优算法GroupFace, 在FAR=10-6,10-5,10-4指标上分别提高了4.43%,0.1%,0.57%; 在IJB-C数据集上, 也分别提高了1.23%,1.19%,0.26%.

表3 不同方法在IJB-B和IJB-C数据集上对不同FAR的验证评估结果
本文方法对1∶1人脸相似度验证结果如图9所示. 对测试数据集中的部分人脸可视化, 其中每两列图像属于相同的标识. 相同面部图像呈现不同的表达方式, 如姿态、 亮度、 模糊和年龄等. 由图9可见, 本文方法对相同人脸由于表达方式不同导致的差异有很好的容忍度, 验证结果表明, 相同人脸的相似度较高, 识别效果较好.

图9 本文方法对1∶1人脸相似度验证结果Fig.9 Verification results of 1∶1 face similarity by proposed method
综上所述, 针对人脸识别中现有的模型都集中在从最后一个卷积层中提取特征, 未对人脸特性进行设计的问题, 本文提出了一种用于人脸识别的双重注意力机制网络模型. 用细节注意力机制自适应地提取分层多尺度局部表示, 用金字塔注意力机制自动定位多尺度不变人脸区域, 并对多个人脸部位进行自适应加权, 用分层交互融合来自不同层的互补特征; 用语义注意力机制通过对高层特征语义分组, 学习潜在的语义信息, 根据人脸所属分组概率加权累加获取语义特征. 将两种注意力获取的特征相结合产生高质量、 独特和可鉴别的人脸特征. 通过在LFW,YTF,MegaFace,IJB-B和IJB-C数据集的实验评估结果表明, 本文方法的精确度分别高出Groupface方法的0.02%,0.1%,0.2%,1%和1%, 表明了本文双重注意力机制方法的有效性.
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
中国外汇(2019年7期)2019-07-13
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
动漫星空(2018年9期)2018-10-26
行政法论丛(2018年2期)2018-05-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
