
基于大津算法和深度学习的开集声纹识别自适应阈值计算方法
2021-07-15 02:01李旭东周林华
吉林大学学报(理学版) 2021年4期
李旭东, 周林华
(长春理工大学 理学院, 长春 130022)
声纹识别是根据人体自身声音特征识别身份的一种生物认证技术[1]. 基于声纹识别的数据集, 声纹识别可分为闭集和开集两类. 关于闭集声纹识别的研究目前已取得了许多成果, 但关于开集声纹识别的研究报道较少且难度较大. 在实际应用中, 很难选择出一个阈值判断测试样本是否存在于训练集中, 而所选阈值是否合适直接影响模型识别的准确性. 目前较经典的阈值有固定阈值[2-3]、 自适应动态阈值[4]和RS阈值[5-6]. 开集声纹识别系统中基于得分规整法[7-8]、 两级决策的说话人辨认法[9]等方法已取得了一定的成果, 但实际应用中还存在特征参数提取、 模型算法的缺陷、 阈值计算等诸多问题. 因此, 本文结合深度置信网络(DBN)从Mel倒谱系数(MFCC)中提取语音深层特征, 通过Gauss混合模型(GMM)计算特征的相似度值, 并在此基础上提出一种基于大津算法的自适应阈值计算方法, 最后计算出测试集上的精确度和召回率作为本文方法的性能评价指标.
1 基于大津算法的阈值计算
大津算法(Otsu)[10-12]是在判别分析或最小二乘原理基础上推导出来的. 基于Otsu算法的思想, 将空间分布有一定距离的两组不同随机变量产生的随机数集合分为A,B两部分, 遍历阈值得到的类间方差越大, 表示分割效果越好.
对于总数为N的随机数集合, 用L表示随机数的最大值,ni表示随机数为i的个数,pi表示随机数为i的概率, 则
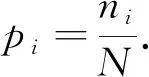
(1)
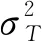
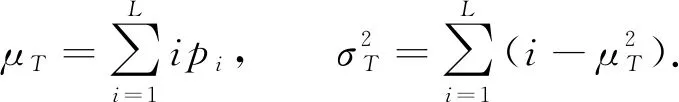
(2)
将属于集合A的数占总随机数的比例记作ω0, 其平均值记作μ0, 则
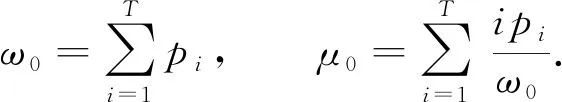
(3)
将属于集合B的数占总随机数的比例记作ω1, 其平均值记作μ1, 则
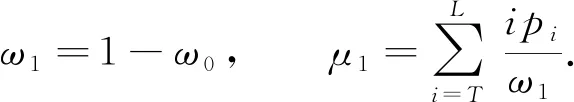
(4)
集合A,B的方差表示为
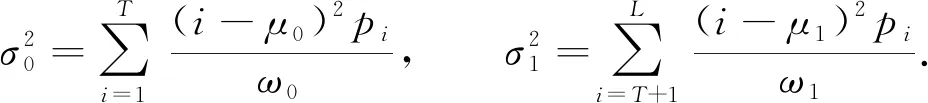
(5)
从而可得随机数集合的类内方差为

(6)
类间方差为
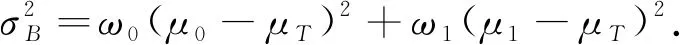
(7)
最佳阈值T是使分离度η(T)最大时的数值, 表示为
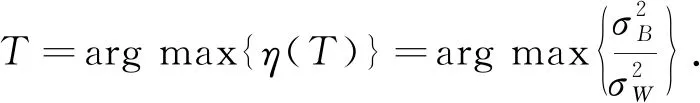
(8)
2 深度特征提取与GMM相似度值计算
2.1 基于深度置信网络的深度声纹特征提取
深度置信网络是由多层受限Boltzmann机(RBM)堆叠再加一层分类器而形成的一种深度学习模型, 深度置信网络可发现特征之间的相互联系, 选择并组合特征, 从而提高特征的表征能力, 因此可作为声纹特征的深度特征提取器[13-14]. RBM是一种基于统计热力学原理的神经网络, 通常情况下, 声纹特征提取采用Gauss-Bernoulli RBM模型[15].
2.1.1 Gauss-Bernoulli RBM模型
RBM由两层神经元构成: 一层是显层神经元vi, 用于表示输入数据; 另一层是隐层神经元hj, 用于表示通过对输入数据学习得到的内在特征.两层神经元间全连接, 同一层神经元间无连接.如果一个RBM有n个显层神经元,m个隐层神经元, 则Gauss-Bernoulli RBM的能量定义为
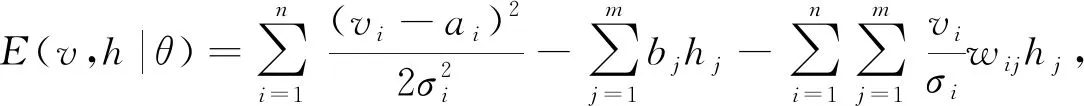
(9)
其中θ={wij,ai,bj,σi}是RBM的参数,wij表示第i个显层神经元与第j个隐层神经元之间的权重,ai和bj表示对应的偏置,σi表示显层神经元的标准差.基于式(9)的能量函数, 可得(v,h)的联合概率分布为
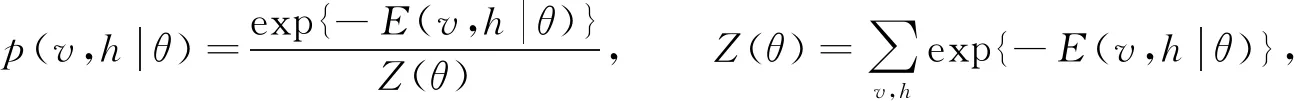
(10)
其中Z(θ)为配分函数, 用于归一化, 通过显层神经元和隐层神经元所有可能分配的能量计算.训练RBM时, 由于显层神经元之间和隐层神经元之间是条件独立的, 因此v和h的条件分布如下:
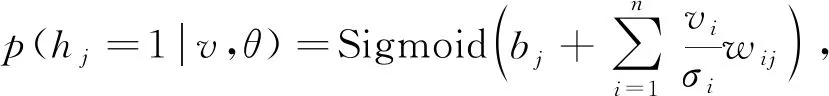
(11)
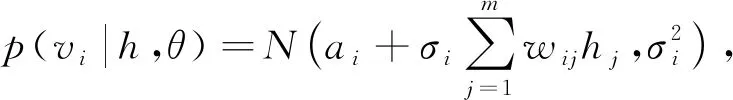
(12)
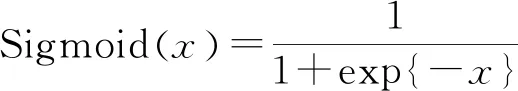
为解决RBM的训练速度问题, 基于对比散度算法(CD)[16]得到RBM各参数的更新准则:
Δwij=ε(〈vihj〉data-〈vihj〉recon),
(13)
其中ε表示学习率, 〈〉data表示模型的期望, 〈〉recon表示通过Gibbs采样初始化数据得到的样本分布期望.
2.1.2 RBM的训练
对一个多层DBN训练时, 先通过从语音中提取的MFCC作为第一个RBM的输入, 并采用无监督学习方式逐一训练RBM, 将训练好的RBM堆叠在一起, 作为DBN的预训练. 然后利用BP(back propagation)算法对DBN各层参数进行微调, 将误差反向传递对其进行修正.
2.1.3 声纹深度特征提取
对输入的原始24维MFCC特征做归一化预处理, 使每个说话人的特征分布满足μi=0及σi=1, 从而避免训练样本分布的重新估计. 深度神经网络由3个RBM构成, 网络结构为24-256-256-256, 输出层是Softmax函数, 声纹深度特征输出层取最后一个隐藏层, 经过此网络即可将24维的MFCC特征转化为256维的深度声学特征. 声纹深度特征提取网络如图1所示.

图1 声纹深度特征提取网络Fig.1 Voiceprint deep feature extraction network
2.2 GMM相似度值计算
将DBN提取到的深度声学特征作为Gauss混合模型的输入, 每个说话人的语音信号都在特定空间形成了特定分布, 可用这些分布描述说话人的个性特征. 通过训练GMM可得到属于集内说话人与属于集外说话人的具有很高区分度的GMM相似度值.
GMM是一个可以用权重系数和为1的若干个Gauss分布表示一个说话人不同语音的模型[17-18]. 设某个说话人的输入语音特征为X={x1,x2,…,xN},xi是D维特征矢量, 则以该语音特征训练混合度为M的GMM可表示为

(14)
其中:wk为对应pk(xi|θk)的加权因子;pk(xi|θk)为第k个单Gauss分布模型, 且满足

(15)
式中uk是均值,Σk为协方差矩阵.因此, GMM可用参数θ={wk,uk,Σk}表示.
由于模型中存在隐变量不易进行参数求解, 因此通常采用最大期望(EM)算法进行参数求解:
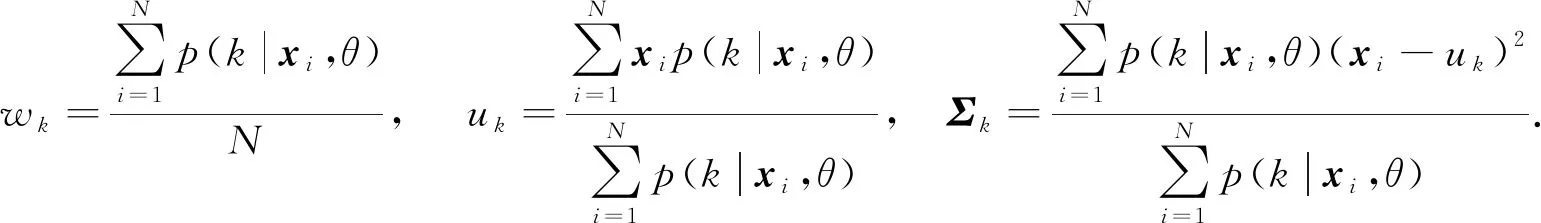
(16)
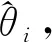
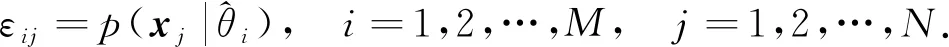
(17)
3 基于大津算法的开集说话人识别实验
3.1 语音数据集及声学特征
实验所用音频为清华大学CSLT公开的中文语音数据(THCHS-30). 为找到效果最佳的模型及模型所对应的参数, 本文将数据分为训练集、 开发集和测试集, 其中训练集8人(8人均为集内), 每人8条音频; 开发集与训练集为相同的8人, 每人20条音频; 测试集3人(1人集内, 2人集外), 每人60条音频. 实验分为5组, 每组实验依次选择2人作为集外说话人, 其余8人轮流作为目标说话人建模, 共进行40次实验.
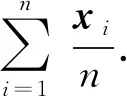
3.2 基于DBN-GMM的大津算法阈值确定方法
在某说话人的DBN-GMM中, 经检验属于该说话人的特征相似度值近似服从正态分布, 而其他说话人的特征相似度值近似服从伽马分布, 如图2所示. 由于实际能参与训练的语音较少, 特征相似度值不足以准确表征相似度值的分布情况, 故根据该说话人与其他说话人的相似度值所服从的分布产生两个随机数集合, 如图3所示. 由图3可见, 相似度值直方图存在两个波峰, 根据大津算法原理必存在能最合理划分集内与集外的最佳阈值.
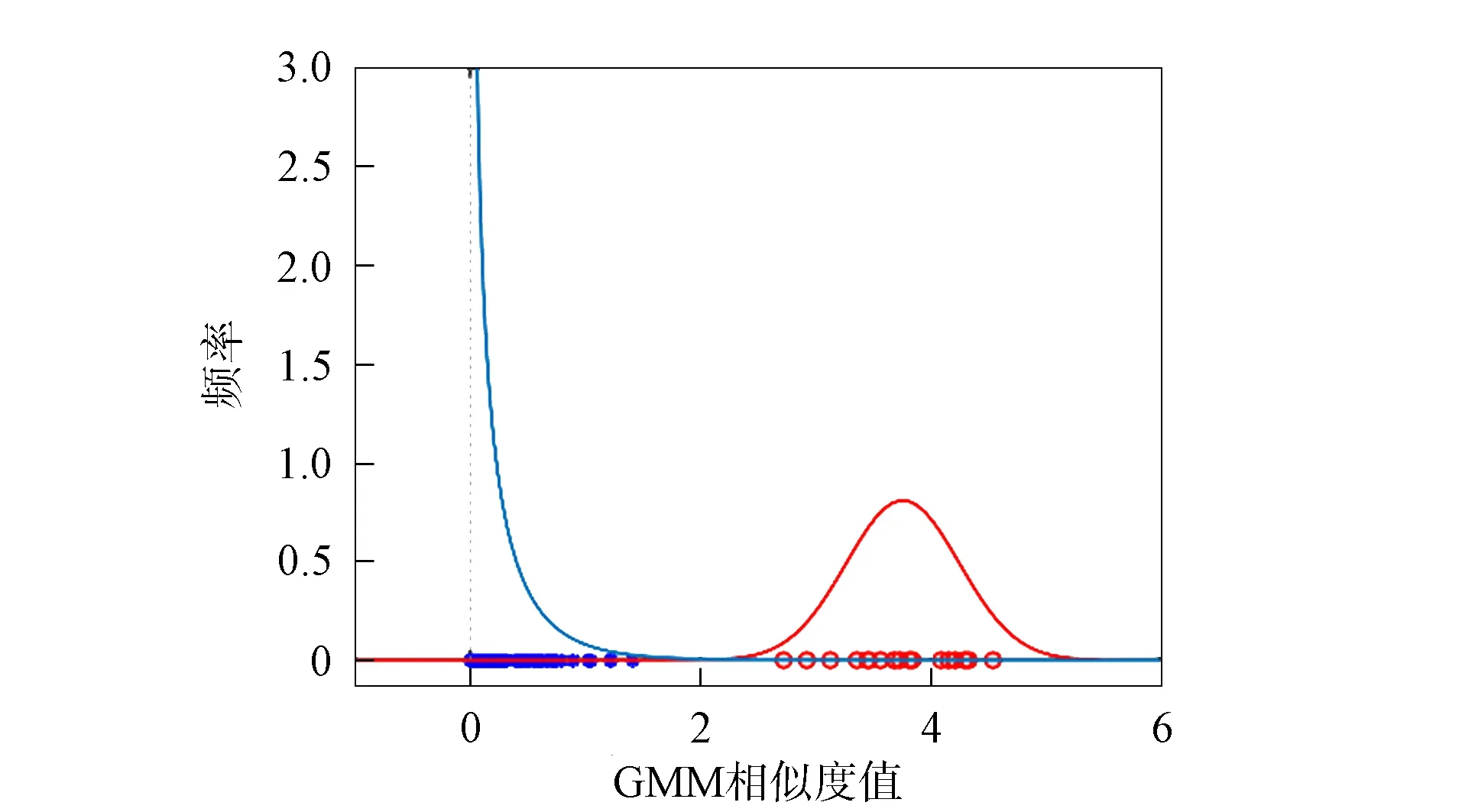
图2 集内外相似度值分布Fig.2 Distribution of similarity values of inside and outside set
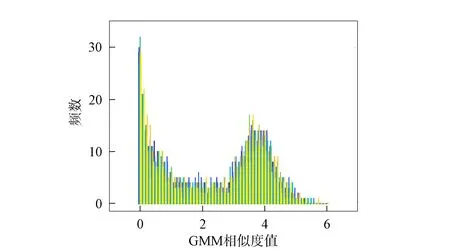
图3 相似度值直方图Fig.3 Histogram of similarity values
基于DBN-GMM的大津算法阈值确定方法实现步骤如下:
1) 将24维基本声学特征MFCC经DBN训练得到256维深度声学特征;
2) 将256维深度声学特征作为GMM的输入, 计算特征的相似度值, 记集外特征相似度值的均值为L1, 集内信号相似度值的均值为L2, 并根据相似度值检验集内与集外相似度值符合的分布;
3) 根据该说话人与其他说话人相似度值符合的分布各产生10 000个随机数, 限制条件为其他说话人产生随机数的最大值不大于该说话人相似度值的最小值, 该说话人产生随机数的最小值不小于其他说话人相似度值的最大值;
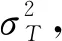
5) 在区间(L1,L2)内遍历T, 并重复步骤4)计算出分离度η(T);
6) 取分离度η(T)最大时的T, 即为所求最佳阈值.
3.3 实验结果与分析
为验证本文算法对集内说话人和集外说话人的识别能力, 采用精确度和召回率作为评价指标, 计算公式为
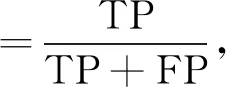
(18)
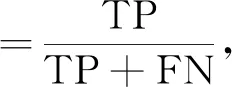
(19)
其中TP表示将属于集内说话人的样本正确预测为集内说话人样本的数量, FP表示将属于集外说话人的样本错误预测为集内说话人样本的数量, FN表示将属于集内说话人的样本错误预测为集外说话人样本的数量.
精确度反映对集外说话人的拒识能力, 召回率反映对集内说话人的识别能力. 图4为Otsu和EER的精确度对比, 图5为Otsu和EER的召回率对比. 由图4和图5可见: 在与大津算法计算阈值算法相同的实验环境下, 等错误率计算阈值的算法对于集内说话人的识别率为99.18%, 对集外说话人的拒识率为98.54%; 本文算法对集内说话人的识别率为99.32%, 对集外说话人的拒识率为100%. 因此, 本文提出的自适应阈值计算方法无论是对集内说话人的识别还是集外说话人的拒识都优于传统的等错误率法.
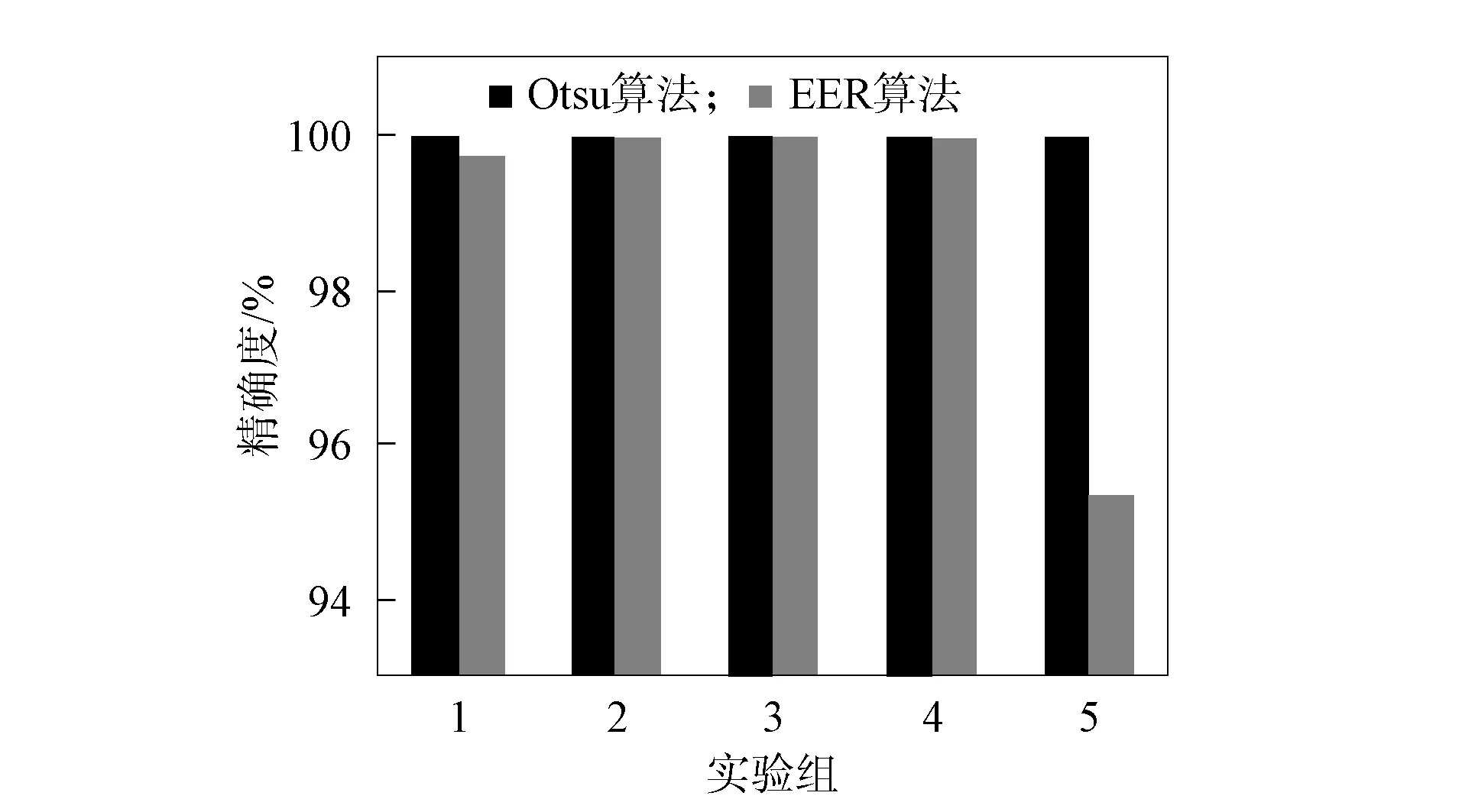
图4 Otsu和EER的精确度对比Fig.4 Accuracy comparison of Otsu and EER
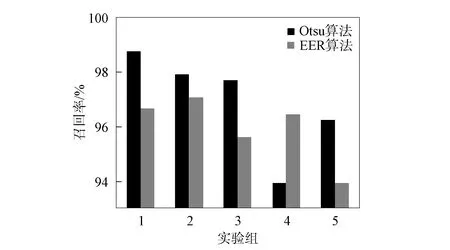
图5 Otsu和EER的召回率对比Fig.5 Comparison of recall rate of Otsu and EER
综上所述, 本文研究了开集声纹识别阈值的计算方法, 提出了一种基于大津算法的开集声纹识别动态阈值计算模型. 首先, 构建DBN模型作为深度声学特征提取器, 通过GMM计算特征的相似度值; 其次, 采用大津算法计算特征相似度值的最大分离度确定阈值; 最后, 在CSLT公开的语音数据库进行测试验证. 实验结果表明, 本文计算阈值的算法较等错误率计算阈值的算法具有更高的识别准确率, 该方法可行、 有效.
猜你喜欢
交通科技与管理(2022年19期)2022-10-12
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
现代装饰(2018年5期)2018-05-26
河北遥感(2017年2期)2017-08-07
电讯技术(2016年8期)2016-11-02
科技传播(2016年17期)2016-10-10
衡阳师范学院学报(2016年3期)2016-07-10
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
