
半监督学习的微博谣言检测分析
2021-07-19 09:37陈耿黄取治
电脑知识与技术 2021年15期
陈耿 黄取治

摘要:谣言检测是社交网络谣言研究、监测及整治的基础,其实施情况得到社会的广泛关注,相伴随的是微博谣言辨识的研究工作不断增多。该文把微博谣言作为研究对象,搭建了微博谣言的检测框架,其主要是由获取数据、处理数据及谣言检测三大步骤构成,基于实验研究过程,对比了差异化数据已标注比例时不同半监督学习的性能和ImCo-Forest算法之间的差异,发现ImCo-Forest在谣言检测方面更占优势。希望能和同行共同分享方法与经验,以期进一步完善微博谣言检测工作。
关键词:微博谣言;半监督学习;ImCo-Forest算法;谣言检测系统
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2021)15-0012-02
1 背景
微博凭借自身在即时性、匿名性、广泛性等方面占据的优势,从根本上扭转了传统媒介下信息传播的样态,塑造了去中心化的传播局势,成为传播社会舆论的新载体。
微博平台上每次只能发布长度为140字符的文字信息,其不具有完整阐述事实的功能,外加微博用户的草根性,使微博逐渐成为聚集、散播谣言的载体,频繁转播、评论虚假信息,不断拓展负面影响的范围,使用用户主观上生成强烈的“信任危机感”,不利于社会的和谐、平稳发展。谣言检测隶属于网络信息可信度研究的范围,微博谣言检测能净化微博平台环境,引导平台健康运作发展,创造出更大的效益。
2 背景分析
微博是现代生活中的一种常用社交网络平台,广大用户可以利用浏览器、智能手机及他类智能联网的客户端传送信息,进而达到分享即时信息的目的。谣言是作为一种特别的语言现象,长期以来是人们关注与研究的热点之一。伴随新媒体网络的蓬勃发展,网络谣言随之产生与流传,在社会上形成较大的影响。近些年中,因微博谣言泛滥引起的危害,使各级政府及学术领域对此给予高度重视,为对虚假话题传播过程形成抑制,我国政府颁发了相应的惩处法规,针对网络谣言制造及传播者,公安机关加大了打击力度。以上这些治理措施的实施,对维持微博传播秩序有很大助益,明显减少了微博谣言。通过观察谣言数据,不难发现微博内的谣言数目明显少于非谣言,精准辨识谣言具有很大现实意义。
3 ImCo-Forest算法
Co-Forest是聚集了集成学习算法的一种算法类型,其不仅能处理协同训练算法中噪声数据引进相关问题,还通过加强不同分类器之间的合作,对那些价值较高且无标记数据的预测工作发出了挑战,强化了集成学习算法的分类功能。
半监督学习算法ImCo-Forest就是以Co-Forest算法为基础提出的,应用该算法的目的需要是通过优化集中训练中少数类的分布状态,将偏高的误分类代价赋予部分感兴趣的少数类,进而强化分类器的辨识能力。假定用[L={(x1,y1),……(xl,yc)}]去表示已标注的数据,[yl∈{1,……c}],[U={(x1,yu),……(xj,yu)}]表示没有标注数据,且有l 该算法应用阶段,针对添加的新标记数据的数据集,应用了以正负类为基础形成的分层抽样法进行抽样操作,借此方式使类别平衡性得到更大保障,规避了由于样本选择不恰当而引起的分类性能逐渐恶化的问题。 4 检测框架 从宏观层面上,可以将微博谣言检测细化为数据获得、数据处置及谣言检测三步骤,本文搭建的微博谣言检测框架见图1所示[2]。 4.1 数据获得 参照新浪微博官方对外发布的数据,到2017年年末时,新浪微博月活跃、日活跃用户分别是3.92亿、1.65亿,为现阶段国内应用用户数目最多、社会影响力最大的微博平台类型。本课题选择新浪微博作为研究对象去分析谣言检测相关问题。通过观察新浪微博的信息结构,不难发现用户个人信息、微博文案及传播信息是一条微博的主要构成。获得数据是谣言检测的基础,以新浪API为基础的数据获取方法是常用手段之一,流程可以做出如下概述:首先,创建账号与运用获得研发者身份,能获取专属型的App Key与App Secret;其次,开发者将授权请求传送到授权地址,基于OAuth2.0认证过程诱导Request Token授权返回过程,在确认授权成功以后,开发者再获得Access Token;最后,调取使用接口,便能顺利地获取到JOSN数据流或XML文件,系统化分析后便预示着微博数据采集工作结束。利用该种方法采集数据有研发代价偏低、便于达成等优点,但官方设定的数据获取频次与方式会对其形成一定约束,很难保证谣言数据获取的有效性、整体性。而相比之下,基于微博爬虫获取数据的方法在应用阶段,能基于网络抓包工具能构建数据请求过程与各请求URL之间的关系,获得kie并建立session,实现模拟登陆,利用HTTP协议、GET方法去采集与分析数据。 4.2 数据处置 谣言检测的宗旨在于从批量化的微博消息内,基于分类算法对其作出合理判断。处理数据是计算机“理解”数据的前提,这样方能精准辨别出微博谣言。本文把微博文本表示为向量这些适用于机器学习算法处理的数据[3]。1)过滤噪声:去噪的目的以解除无用数据为主,这是提升后期检测工效的基础,具体是当微博用户的粉丝数目在给定阈值之下时,就将其微博数据删除。2)分词:从本质上分析,对微博文本进行分类就是细化短文本的所属类型,对文本进行分词操作这是预处理阶段需落实的第一要务,当下可供选择的分词方法较多,比如由统计学习形成的,或者以人工智能为基础形成的分词法等,合理使用如上方法,能将连贯的字符串序列转变成组合式的成词序列,并化繁为简,获得简单容易处理、向量化的文本数据。3)表示向量:即参照一定的特征项,把微博文案信息转变成特征性向量的方法,当前在该环节中多采用空间向量模型(VSM),其应用思想可以做出如下表述:将文本视为无序词与其相对应权重的集合体,统一映射至高维空间内,具体操作是把文案内的各词项作为唯一属性用t1表示,测算出文档内各词项的重要程度进而获取到权重W1,那么便可以将一个文档表示成例如(t1,W1;t2,W2;……tn,Wn)的向量形式,而后通过测算文本相似度去对不同内容之间的相关性作出科学判断。
4.3 选择微博特征
这是谣言检测过程中的关键一环,影响着检测效果,当下国内外针对微博谣言检测的研究主要聚集在选择分类特征方面。也有人员通过系统分析与科学实验过程获取到文本的基本特征,即内容特征、用户属性信息与传播特征,希望据此能提升微博谣言检测效率,本文以此为基础,从多个维度分析微博谣言的特点,构建出用于检测微博谣言的特征向量集合[4]。1)内容特征:是微博消息内的统计特征,可以将其看成是微博内容的延展信息或不同用户交流中形成的信息,影响着文本的可信度。2)用户特征:由是否认证、注册时间、微博数等构成,其呈现出的是广大微博用户自身的权威性与影响力。3)传播特征:看中的主要是用户上传的文本信息的转发及评论数,这种特征主要是能表现出该用户对其他网络用户产生的影响力。
5 实证检验
5.1 实验步骤
1)获取和标注数据:把官方的辟谣信息及网络材料作为凭据,选择5895条微博并进行人工标注处理。
2)提获特征:在该操作之前需要对获得的微博数据进行预处理,宗旨在于尽量解除噪声数据,将无用数据对后续检测工作形成的负面影响降至最低。具体是删减到粉丝数<5的用户信息。预处理后参照特征去提获数据,构建出微博文本数据的特征向量[5]。
3)鉴于ImCo-Forest算法在微博谣言检测领域中表现出的有效性,拟定于WEKA平台上开展谣言检测的实验研究。针对各个数据集,通过十折交叉验证进行测评,把已标注及未标注集作为检测算法的输入项,对分类器进行规范训练后于测试集上进行检测,获得真正例、假负例、假正例及真负例。
5.2 实验结果
比较了不同数据已标注比例时不同半监督学习的性能和ImCo-Forest算法。对比分析后发现,和其他半监督学习算法相比较,在已标注比例下ImCo-Forest算法的F-measure值和G-mean值更高,这表明ImCo-Forest算法在检测微博谣言方面优越性更大。并且通过读图发现,在已标注数据占比达到40%时Co-Forest算法的性能最优,当数据占比为60%、80%时算法的性能却有降低趋势,这主要是由Co-Forest算法自身的特点决定的,与既往很多研究形成的结论一致。
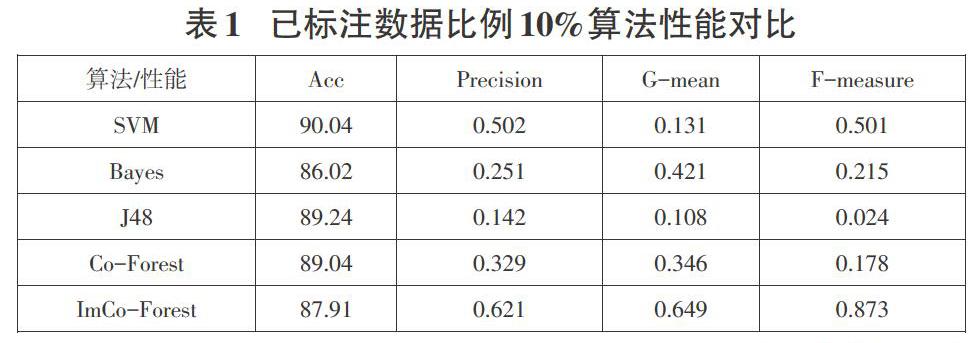
为了能进一步证实本文所设计的ImCo-Forest算法和现有研究所应用的监督学习算法更占据优势,本文基于L[?]U,在μ=0%状态对应的数据集上对SVM、Bayes和J48分类器进行系统化训练,将他们和已经标注数据比例为10%情景下的ImCo-Forest算法持有的性能进行对比分析,选择了“少女遭毁容”语料,统计了评价指标,实验结果见表1[6]。
对表1内的数据进行比较分析,不难发现在"少女遭毁容"语料上,ImCo-Forest算法的与F-measure指标都较好,提示该种算法在处理非平衡数据问题方面和其他算法相比较表现出较好效能。在这里需另外关注的问题是,SVM算法尽管在整体准确率指标上相对较高,达到了90.04%,但其G-mean和F-measure指标数值均处于较低的水平,提示该算法对少数类的辨识性能偏差,说明其不能精准辨识出微博谣言[7]。
还需要关注的内容是,本次实验中对选用的三种监督学习算法均采用了100%完全性标注的理想化数据集进行训练,统计结果后发现,在整体准确率指标上,只有SVM、J48算法比ImCo-Forest更优秀,提示为了获得相对较高的总体准确率,和ImCo-Forest算法相比较,其他算法需要数目更庞大的标注数据,这在很大程度上削弱了其在现实运用领域中的可执行性。
6 结束语
综合分析以上实验过程产出的结果,可以认定ImCo-Forest算法能在标注数据少量的情景下,较好的检测出谣言,这样便能在微博谣言辨识阶段明显减少数据标注过程中付出的代价。但是回顾研究历程,笔者自知还存在着一定不足,比如没有考虑到微博文本语义等因素形成的影响,故而后续工作中应重视专研分析语义特征、传播过程中用户主体行为对信息可信度形成的影响,参照语义技术拓展对微博文本特征挖掘的深度性,借此方式进一步提升半监督学习算法在检测微博谣言方面的精准度,将自身价值发挥到最大化。
参考文献:
[1] 刘彤,魏静,倪维健,等.基于半监督学习与CRF的应急预案命名实体识别[J].软件导刊,2020,19(3):35-38.
[2] 冯雨庭,张锦,肖斌.基于半监督SVM的交通方式特征分析和识别[J].综合运输,2019,41(9):57-63.
[3] 金志刚,杨洋.基于用户关联度的半监督情感分析模型[J].哈尔滨工业大学学报,2019,51(5):50-56.
[4] 董哲瑾,王健,錢凌飞,等.一种用户成长性画像的建模方法[J].山东大学学报(理学版),2019,54(3):38-45.
[5] 陈珂,黎树俊,谢博.基于半监督学习的微博情感分析[J].计算机与数字工程,2018,46(9):1850-1855.
[6] 李泽魁,李雪婷,赵妍妍.中文微博热点事件情感分布的原因分析[J].中文信息学报,2018,32(1):131-138.
[7] 刘桂锋,汪满容,刘海军.基于概率超图半监督学习的专利文本分类方法研究[J].情报杂志,2016,35(9):187-191,173.
【通联编辑:谢媛媛】
