
基于知识图谱驱动的图神经网络推荐模型
2021-07-30 10:33李晓戈胡立坤胡飞雄王鹏华
计算机应用 2021年7期
刘 欢,李晓戈*,胡立坤,胡飞雄,王鹏华
(1.西安邮电大学计算机学院,西安 710121;2.陕西省网络数据分析与智能处理重点实验室(西安邮电大学),西安 710121;3.深圳腾讯计算机系统有限公司智能化运维部,广东深圳 518000)
0 引言
随着互联网技术的进步,人们可以获取到大量的在线内容,比如新闻、电影以及各种商品等。但在线信息的爆炸性增长经常让用户不堪重负,推荐系统则是一个有效的信息过滤工具,在减轻信息过载的同时又可以为用户提供良好的体验。推荐系统通常会搜索并选择较小数量的内容来满足用户的个性化兴趣。协同过滤算法是一种经典的推荐技术,它将用户以及物品表示为向量形式,通过特定操作(内积、神经网络[1]等)对它们的交互进行建模;然而,协同过滤算法通常都会面临稀疏性以及冷启动等问题。为了缓解基于协同过滤的推荐系统的稀疏性和冷启动问题,研究人员通常会收集用户和物品的属性,并设计精巧的算法来利用这些额外的信息[2]。
最近的一些研究[3-6]都使用了物品属性来进行建模,这些研究成果表明属性并不是孤立的,而是被相互连接起来的,其中一种形式就是知识图谱(Knowledge Graph,KG)。KG 是一种典型的异构网络,它的每个节点代表一个实体,这些实体可以是物品也可以是属性,两个存在关系的实体由一条边相连。KG拥有丰富的语义关联信息,可以为推荐系统提供丰富的辅助信息。与没有KG 辅助的推荐模型相比,使用KG 辅助的推荐模型可以让推荐结果拥有以下三个特征[7]:1)精确性。丰富的语义相关信息可以发掘更深层次的隐藏关系并且提高结果的准确率。2)多样性。KG 中多类别的关系可以扩展用户兴趣,合理地发散推荐结果,提高推荐结果的多样性。3)可解释性。KG可以连接用户的历史点击记录和推荐记录,为推荐系统提供可解释性。虽然KG 有着上述优点,但是由于KG 天然的高维性以及异构性,如何利用KG 进行推荐仍然是一个挑战。目前的一种可行方法就是KG 嵌入,将KG 中的实体或者关系映射为低维表示向量。然而,一些常用的KG 嵌入方法,诸如TransE[8]和TransR[9]等,都侧重于对语义关联进行建模,更适合于KG 补全和链路预测等图应用,而不是推荐。在图嵌入的方法中,图的建模和特征表示与下游任务是独立的,下游任务获得的结果无法用来优化图的特征表示;而且这种方法缺乏归纳能力,当有新节点加入时,需要重新学习整个图的特征表示。为了解决这些问题,本文提出一种基于知识图谱驱动的端到端图神经网络模型(Knowledge Graph driven Learning Network,KGLN),利用KG 中的语义相关信息,驱动用户以及物品的表示学习。在端到端模型中,下游任务得到的结果可以用来优化图的特征表示并且具备归纳能力,当有新节点加入时,通过共享参数可以直接获得该节点的特征表示。
KGLN 中,在实体表示学习的过程中根据用户偏好来影响邻居节点聚合的权重,这样做有两个优点:1)邻居节点拥有不同的权重,聚合时可以让当前实体获得更加精确的表示,提高推荐的准确率;2)由于用户偏好的影响,在学习过程中可以扩展到更多与用户兴趣相关的内容,可以提高推荐的多样性。
1 相关工作
1.1 图神经网络
图神经网络旨在将神经网络应用于非欧氏空间的数据(如图数据)来进行特征学习。图卷积神经网络(Graph Convolutional neural Network,GCN)由Kpif 于2017 年提出[10],它为图结构数据的处理提供了一种崭新的思路,将卷积神经网络(Convolutional Neural Network,CCN)应用到了图数据中。
最近,很多的研究工作都将GCN 运用到了推荐系统中:PinSAGE[11]应用到了Pinterest 中的图片与图集这个二分图的推荐;Monti 等[12]和van den Berg 等[13]将推荐系统建模为矩阵分解并分别设计了不同的GCN 模型来为二分图中的用户以及项目进行表示学习;Wu 等[14]在用户/物品的结构图上使用GCN 去学习用户/物品的表示。这些工作与本文工作的区别是它们的模型都是为同质二分图设计,由于不存在复杂的关系,所以使用GCN建模比较简单。
1.2 基于深度学习的推荐系统
深度学习对数据进行多重非线性变换,可以拟合出较为复杂的预测函数。推荐系统中的核心算法是协同过滤,其目标从机器学习的角度可以看成拟合用户和物品之间的交互函数。因此,近期一系列的工作也将深度学习技术应用于协同过滤的交互函数上。例如,DeepFM[15]扩展了分解机(Factorization Machine,FM)方法,在FM中引入了一个深度线性模型来拟合特征之间复杂的交互关系;Wide&Deep[2]的Wide 部分采用和FM一样的线性回归模型,Deep部分采用了基于特征表示学习的多层感知机模型,提出了一个应用于视频推荐的深度神经网络推荐模型;NCF(Neural Collaborative Filtering)[1]用多层感知机替换传统协同过滤中的点积操作;DMF(Deep Matrix Factorization)[16]类似于DeepFM,在传统矩阵分解模型中引入了一个深度学习模块来提高模型的表达能力。
1.3 使用知识图谱的推荐系统
目前的KG 感知推荐系统主要是基于图嵌入的方法,将KG 使用KG 嵌入算法进行预处理,然后将学习好的实体向量融合到推荐系统中。这种方法将图嵌入以及推荐两个过程分开,导致推荐结果完全取决于图嵌入算法的优劣,而本文提出的端到端图神经网络推荐模型可以根据推荐结果的反馈来优化图的表示学习,很好地解决了上述问题。
同样使用KG 作为辅助信息的模型还有多任务知识图谱特征学习推荐模型(Multi-task feature learning for Knowledge graph enhanced Recommendation,MKR)[17]以及RippleNet[18]。MKR 包含推荐系统模块与知识图谱实体特征学习模块,这两个模块通过一个交叉压缩模块进行桥接,交叉压缩模块可以自动学习两个任务中物品和实体的高阶特征交互,通过依次训练来共享特征信息。RippleNet 的核心思想是兴趣传播,将用户历史作为种子,然后通过KG 中的连接迭代地向外扩展用户的兴趣,以此获得用户向量来进行下行预测任务。两种模型都在真实数据集上拥有出色的效果,本文模型也将与二者进行实验结果对比来验证本文模型的有效性。
2 图神经网络推荐模型
2.1 问题定义
在一个典型的推荐场景中,会有一个包含M个用户的集合U={u1,u2,…,uM} 和一个包含N个物品的集合V={v1,v2,…,vN}。用户与物品的交互矩阵为Y∈RM×N,它反映了用户的隐式反馈,当yuv=1 代表用户u与物品v存在联系,比如点击、浏览或者购买等,反之yuv=0。此外,还有一个知识图谱G,它由实体-关系-实体三元组(h,r,t)组成。此处h∈E、r∈R和t∈E表示三元组的头部、关系和尾部,E和R分别是知识图中的实体和关系集。例如三元组(哈利波特,作者,JK 罗琳)表示JK 罗琳创作了哈利波特这个事实。在许多的推荐场景中,一个物品是与一个实体相关的。比如在书籍推荐中,《哈利波特》就可以作为知识图谱中的一个实体。给定一个用户物品交互矩阵Y以及知识图谱G,目标是预测用户u是否对物品v有潜在的兴趣。也就是学习函数=F(u,v|Y,G,Θ),其中表示用户u喜欢物品v的概率,Θ为函数F的参数。
2.2 KGLN整体框架
整个KGLN 的模型框架如图1 所示,图中展示了阶数为2时的整体流程。对于每对用户u和物品v,使用它们的原始特征作为输入:用户特征u主要参与影响因子的计算以及最后推荐评分的预测;物品特征v在单层KGLN中首先采样出邻居样本(图1中分别用以及表示v的邻居实体e1以及e2的原始特征),之后通过用户特征u及物品与邻居之间的关系特征r计算出影响因子α作为权重进行邻居特征聚合,再通过聚合器得到一阶特征v1来更新原始的v0,这就完成了一次单层KGLN。为了得到物品的二阶特征v2,需要先对以及分别进行一次单层KGLN 得到两个邻居的一阶特征,再对物品的一阶特征进行一次单层KGLN 得到信息更加丰富的二阶特征v2,之后与用户特征u来预测评分。
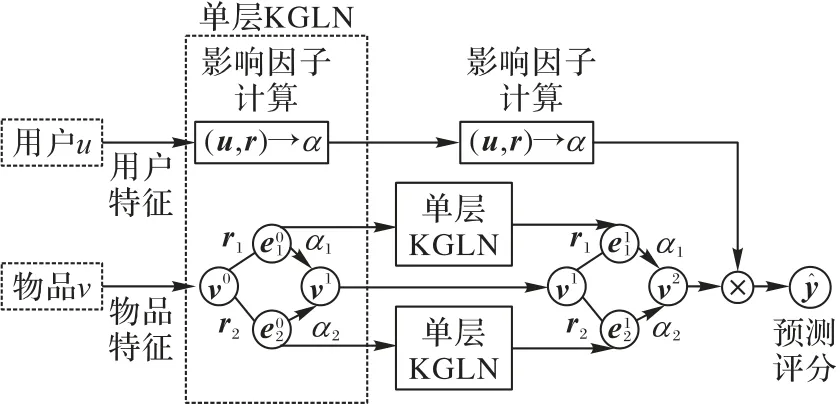
图1 KGLN整体框架Fig.1 Overall framework of KGLN
2.3 单层KGLN模型
2.3.1 影响因子
KGLN 的核心思想是通过KG 中实体间的近邻关系来驱动模型进行用户和物品的表示学习。首先介绍单层的KGLN,考虑一个用户u和物品v,v在知识图谱中存在一个实体,用N(v)来表示实体v在知识图谱中的邻居实体的集合,表示两个实体ei和ej之间的关系。如果用户u曾经为物品v评分过,在KGLN中,会在知识图谱中找到与物品v相关的实体,接下来对该实体做邻居节点特征聚合。在邻居节点特征聚合的过程中,加入影响因子来影响聚合的结果,影响因子可以当作是对用户偏好的衡量,这种影响因子类似于注意力机制。具体来说,引入了一个评分函数g:Rd×Rd→R 来计算影响因子,也就是用户与关系之间的分值:

其中:u∈Rd和r∈Rd分别代表用户u和关系r的特征,d是特征的维度。一般而言,已经刻画了关系r对用户u的重要程度,可以用来表示用户的兴趣偏好。比如用户A 可能会对曾经阅读过的书籍的作者写的另一部作品感兴趣,而用户B 更多是因为作品的题材而对该作品感兴趣。在KGLN 中,不仅要计算用户偏好的影响因子,也要计算不同邻居节点对当前中心实体的影响因子:

其中:e为当前实体v的所有邻居节点的特征。刻画了所有邻居实体e对当前实体v的影响程度。得到两种影响因子后,分别对其进行归一化处理:

2.3.2 邻居采样
在对每一个节点进行邻居节点实体特征融合的过程前都需要对其邻居进行采样,取得需要进行特征融合的邻居集合。由于在知识图谱中一个实体的邻居数据不会相同,而在一种极端的情况下,其数量可能会相差非常多。为了提高模型的训练效率,对每个实体没有使用它的全部邻居,而是均匀随机地在所有邻居中采样出一个集合采样的邻居个数用K控制。图2是K=2时的采样情况,即每个节点只会选取邻近自己的两个邻居节点。在KGLN 中,S(v)也可以被称为实体v的(单层的)感受野(receptive field),因为实体v的最终特征计算对这些范围敏感(图2 中的深色节点)。在均匀随机地采样了K个邻居节点后,根据式(1)~(4)计算每个节点的影响因子,然后对物品v的邻居节点进行建模,具体如下:

图2 采样完成的邻居节点向内聚合Fig.2 Inward aggregation of neighbor nodes after sampling

其中e为实体v邻居节点的特征。影响因子的引入可以让我们根据用户偏好来个性化地聚合邻居节点特征。
2.3.3 聚合实体特征
最后一个步骤就是融合当前实体特征v与它的邻居特征,将获得的结果作为当前实体新的特征表示。使用了三种类型的聚合器:
1)GCN 聚合器(GCN aggregator)[10]直接将两个特征相加,然后使用一个非线性函数得到结果:

将激活函数设置为LeakyReLU。W∈Rd×d是可训练的权重矩阵,用来提取有用信息进行传播操作。
2)GraphSage聚合器(GraphSage aggregator)[19]将两个特征拼接再应用一个非线性变换得到结果:

激活函数为LeakyReLU,W∈Rd×d是可训练的权重矩阵。

3)双交互聚合器(Bi-Interaction aggregator)[20]考虑了当前节点特征v与邻居特征的两种信息交互:其中:W1,W2∈Rd×d都为可训练权重矩阵;⊙表示向量按元素相乘。与GCN 聚合器和GraphSAGE 聚合器不同,双交聚合器模型传播的信息对v与的相关性比较敏感,它会传递更多类似当前实体节点的信息。

2.4 学习算法
经过一个单层的KGLN,一个实体节点得到的实体表示依赖于其邻居节点,称其为一阶实体特征。当我们将KGLN扩展到多层时,就可以探索用户更深层次的潜在兴趣,这是十分自然合理的,具体的算法如下所述:
1)对于一个给定的用户-物品对(u,v),首先对v进行邻居采样,经过随机采样之后得到v的K个邻居节点,接下来对这K个邻居节点进行相同的采样操作。这样,以一种迭代的计算过程得到v的多阶邻居集合。这里用H来表示感受野的深度,也就是迭代的次数,如图2 所示为H=2 时v的感受野(图中的深色节点)。
2)邻居采样完成后,考虑H=2 时的计算过程。首先计算v的一阶实体特征v1(角标代表阶数),这里需要用到v的零阶实体特征v0,也就是原始特征。在经过单层KGLN 之后,可以得到融合了邻居节点特征v的新实体特征v1。之后用一层KGLN 计算v的所有邻居的一阶实体特征,用一阶实体特征更新原始特征得到所有的,en∈N(v)。最后再使用一层KGLN 更新v的实体特征,得到v的二阶实体特征v2。整个迭代过程如图4所示,自底向上不断进行邻居节点特征融合。

图3 邻居实体特征的聚合过程Fig.3 Aggregation process of neighbor entity features

图4 邻居节点特征融合的迭代过程Fig.4 Iterative process of neighbor node feature fusion
3)将所有用户-物品对(u,v)执行1)~2)过程后,可以得到最终的H阶实体特征,这里记为vu。将vu与用户特征u一起输入函数f:Rd×Rd→R,得到最终的预测概率:
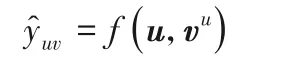
整个模型损失函数如下:

为了计算更有效率,在训练中使用了负采样技术。其中℘是交叉熵损失函数,Tu是用户u的负样本个数,P是负样本的分布。在本模型中,Tu与用户正样本的个数相同,P则为均匀分布。最后一项为L2 正则项,包括中所有的参数。
3 实验与分析
3.1 数据集
实验部分选择了两种数据集:MovieLens-1M 以及Book-Crossing。MovieLens-1M 是电影推荐中的一个广泛使用的基准数据集,它包含了在MovieLens网站上用户对电影的显式的从1 到5 的评分;Book-Crossing 是Book-Crossing 图书社区的用户对图书进行0~10评分的数据。
将两种数据集进行处理:在MovisLens-1M 中,如果用户对电影做出了4 分以上的评分,则将用户与该电影的交互置为1,反之为0;对Book-Crossing 也做相同的处理,评分范围规定为0 分以上,即只要用户对该图书做了评分则将交互置为1。
知识图谱部分使用了MKR 中构建的知识图谱,该知识图谱使用微软Satori构造。对于MovisLens-1M 和Book-Crossing,首先从整个知识图谱中选择一个子图,其中关系的名字包括电影以及图书。从初步筛出的子图中比照了所有数据集中的电影名或者图书名,来进行物品与实体的配对,最后再删掉无法找到实体的数据集数据,得到最终的知识图谱与交互矩阵。两种数据集的基本统计信息如表1所示。

表1 两种数据集的统计结果Tab.1 Statistical results of two datasets
图5 为使用MovieLens-1M 构造的部分知识图谱展示,该部分图谱以“Forrest Gump”为中心节点。为了便于展示,在关系前加上了该关系三元组中头节点的属性。在MovieLens-1M数据集中,作为中心实体的都是电影,每个电影通过不同的关系连接不同的属性,KGLN 将会用这些丰富的属性信息对每个电影实体进行特征学习。

图5 知识图谱样例Fig.5 Sample of knowledge graph
3.2 基准方法
在KGLN的实验中,使用了如下的基准方法:
LibFM[21]是一个用于点击率(Click-Through-Rate)预测的基于特征分解的模型,使用用户与物品的原始特征作为输入。
Wide&Deep[2]是一个基于深度学习推荐算法,是一种融合浅层(Wide)模型和深层(Deep)模型进行联合训练的框架。Wide 部分的输入需要特征工程得到的二阶交叉特征,在本实验过程中使用原始稀疏特征作为输入。
DeepFM[15]是Wide&Deep的改进,通过浅层模型和深层模型来训练得到。它包含两个部分:神经网络模块与因子分解机模块,分别负责低阶特征的提取和高阶特征的提取,两部分输入与LibFM相同均为原始特征。
MKR[17]包含推荐系统模块以及知识图谱特征学习模块,使用用户以及物品的原始特征作为推荐系统模块的输入,数据集上的知识图谱作为知识图谱特征学习模块的输入。
RippleNet[18]是混合模型的代表,通过在知识图谱上传播用户偏好的记忆网络推荐模型,输入同样为用户和物品的原始特征以及知识图谱。
3.3 实验准备
KGLN 的实验准备如下:在KGLN 中,将MovieLens-1M 的跳数H设置为2,Book-Crossing的跳数H设置为1,其他超参数的设置如表2 所示,其中:d为特征维度;ε为学习率;模型中g设置为内积函数,非最后一层聚合器的激活函数为LeakyReLU,最后一层聚合器的激活函数为tanh,所有超参数在验证集上通过优化AUC值得到。

表2 KGLN的超参数设置Tab.2 Hyperparameter setting of KGLN
基准方法的超参数设置如下:对于LibFM,其维度为{1,1,8},学习轮数为50;对于DeepFM,两个数据集上的特征维度都为d=8,模型维度为{16,16,16};对于RippleNet,其特征维度与学习率设置为与KGLN 相同。Wide&Deep 以及MKR的超参数选择和原始论文或代码默认值一致。
在实验中,数据集的训练集、验证集和测试集的比例为6∶2∶2,最终实验结果均为5 次实验结果取平均得到的。实验情景为CTR 预测,通过受试者工作特征曲线(Receiver Operating Characteristic,ROC)下面积(Area Under Curve of ROC,AUC)以及F1值衡量模型性能。
3.4 实验结果
3.4.1 与基准方法的比较
KGLN 与其他基准方法的结果如表3 所示,从中可以看出:
LibFM 输入为数据集的原始特征,通过FM 来学习一阶特征和二阶交叉特征,得到低维向量表示;DeepFM 和Wide&Deep 都是用深度神经网络来得到向量表示,区别是前者使用FM 来负责一阶特征以及二阶交叉特征,后者使用Wide 部分的逻辑回归模型记忆二阶交叉特征。这三种方法都只用到了数据集本身的特征信息,没有任何辅助信息,在评价指标上要低于所有使用知识图谱作为辅助信息的方法,这表明引入知识图谱是有效的。
MKR 在Book-Crossing 上的结果要优于所有基准方法,因为Book-Crossing 数据集相对来说比较稀疏,而MKR 中的交叉共享单元可以让图学习模块以及推荐模块共享对方的额外信息,这种交互学习方式一定程度上弥补了数据集稀疏的问题。KGLN 在Book-Crossing 上的效果略低于MKR,也是由于数据集的稀疏性,在融合邻居节点特征时容易引入噪声。而在MovieLens-1M 这种相对稠密的数据集上,KGLN 的表现要优于所有基准方法,这也体现了越丰富的知识图谱对推荐效果起的作用越大。
RippleNet 与KGLN 的结果非常相近,注意到RippleNet 也用到了多跳关联实体信息,这表明在使用知识图谱辅助时对局部结构以及邻居节点关系进行建模十分重要。
表3 中KGLN-BI、KGLN-GS 和KGLN-GCN 表 示KGLN 中分别使用不同聚合器(见2.3.3 节)得到的结果。可以发现:双向交互聚合器一般而言表现最好,是因为双交互聚合器可以更多地保留自身的信息特征,并融合更多类似于自身信息而来自邻居节点的特征;GCN 与GraphSAGE 聚合器效果略差,是由于在聚合过程中结构信息的比重与节点自身信息的比重一致而造成的,这表明在建模过程中应该更多考虑节点本身的信息。

表3 KGLN与其他基准方法在MovieLens-1M和 Book-Crossing数据集上的AUC与F1比较Tab.3 Comparison of AUC and F1 of KGLN and other benchmark methods on MovieLens-1M and Book-Crossing datasets
为了验证影响因子的效果,对比了使用影响因子与未使用影响因子(即邻居结构建模时使用所有邻居节点特征的均值作为邻居特征,即的AUC 值,如表4 所示。未使用影响因子的结果要比使用影响因子的效果差,这说明注意力机制确实对推荐结果有提升作用。

表4 影响因子在不同聚合器上的效果(AUC值)Tab.4 Effect of influence factors on of different aggregators(AUC)
3.4.2 感受野深度的影响
表5给出了感受野深度H从1变化到3时对KGLN结果的影响,可以看出KGLN 对H的改变比较敏感。感受野会随着深度的增加一个指数式级扩大[22],一个较大的H在模型中会让实体节点对以其为中心的大范围实体敏感,因为该实体的最终特征计算依赖于这些实体,而这些大范围的实体中会存在很多对中心实体特征表示毫无用处的实体,这就会引入大量的噪声,导致模型结果下降。

表5 不同感受野深度H下的实验结果Tab.5 Experimental results of different receptive field depths H
Book-Crossing数据集在H=3时得到了相对较差的结果,这表明模型在融合三阶实体特征时已经引入了大量的噪声。在现实情况中,过深的探索用户兴趣也是没有必要的。比如在电影推荐的场景中,用户A 喜欢电影B 是因为该电影的演员C,那么可以通过演员C 这个实体去发掘该演员演过的电影,在这些电影实体中融合更多演员C 这个实体的信息可以达到挖掘用户兴趣的目的。可见,H为1或2在真实场景中已经可以满足需求。
4 结语
本文提出了图神经网络推荐模型,在知识图谱特征学习的过程中引入了影响因子,通过改变邻居节点特征的权重来进行聚合,不仅学习到了知识图谱的结构和语义信息,还可以挖掘用户的个性化兴趣以及潜在爱好,提高了推荐结果的多样性和丰富性。在两种公开数据集MovieLens-1M 与Book-Crossing上进行实验,分析研究了不同聚合器及影响因子对推荐结果的影响。使用AUC 值与F1 值作为评价标准,将KGLN与经典模型DeepFM、LibFM、Wide&Deep、RippleNet 进行对比,结果表明KGLN 在推荐效果上都有所提升,验证了KGLN的可行性和有效性。KGLN 所考虑的知识图谱是静态的,而现实生活中大部分情况知识图谱都会随着时间而变化;不仅如此,用户的喜好也会随着时间而变化,如何刻画这种随时间演变的情况,也是未来研究的方向。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(低年级)(2022年5期)2022-05-31
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
21世纪商业评论(2018年3期)2018-03-02
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
小天使·二年级语数英综合(2017年3期)2017-04-01
领导科学论坛(2016年9期)2016-06-05
小天使·一年级语数英综合(2015年8期)2015-07-06
