
基于知识图谱和重启随机游走的跨平台用户推荐方法
2021-07-30 10:33余敦辉张蕗怡张笑笑
计算机应用 2021年7期
余敦辉,张蕗怡,张笑笑*,毛 亮
(1.湖北大学计算机与信息工程学院,武汉 430062;2.湖北省教育信息化工程技术研究中心(湖北大学),武汉 430062)
0 引言
随着互联网及大数据时代的发展,信息呈爆炸式增长,面对海量数据,用户如何高效获取自己需要的信息愈发困难,因此推荐系统成为各大社交平台争先关注和应用的焦点。现有的推荐系统大多建立在单一社交平台的基础上,仅仅利用单一平台中用户的兴趣、发布的内容和历史记录等进行用户推荐,导致对用户兴趣和行为信息了解不够全面,推荐结果单一,容易出现数据过度拟合现象[1]以及用户冷启动问题[2]。例如:用户在平台1 上喜欢关注体育类型的博主,在平台2 上喜欢关注科技类型的用户,并且对科技类型信息的关注活跃度高于对体育类型的关注,但是平台1 一直推送关于体育类型的信息和博主给用户,未能发掘用户对科技类型信息和博主的兴趣,缺乏对用户兴趣信息的全面了解。
但是,融合多个社交网络中的数据,存在用户信息获取困难、关联效率较低的问题,因此,如何在跨平台社交网络中进行用户推荐已成为一个研究热点。
目前众多学者围绕社交网络中的用户推荐展开研究,其中一部分是研究单一平台中的用户推荐:文献[3]中的协同过滤(Collaborative Filtering,CF)是使用较广泛的推荐技术,根据用户对物品的评分信息来预测用户的偏好;然而,协同过滤系统容易受到不公平评分和稀疏数据的影响。文献[4]中通过基于用户相似性的重启随机游走推荐社交网络中的事件给用户,但忽略了跨平台用户之间的关联。文献[5]中提出了基于用户行为特征挖掘的个性化推荐算法,采用显著数据分块检测方法进行社交网络用户特征的行为信息融合处理;但是仅融合单一平台的用户信息,推荐的多样性仍受到限制。单一平台用户信息有限,推荐结果单一,因此也有很多研究是围绕跨平台和跨社区的用户推荐展开的:文献[6]中提出利用源平台的数据丰富目标平台的数据来进行推荐,以此解决目标平台的数据稀疏问题和冷启动问题;但是源平台中的数据往往有限。文献[7]中提出跨平台用户推荐方法,通过爬取用户在不同平台的关联账号匹配关系,根据平台的应用程序编程接口(Application Programming Interface,API)获取用户数据;然而无法获取没有关联账号的用户数据,且很多平台没有提供API,用户匹配较为困难。文献[8]中分析了用户与用户之间的互动,建立了跨社区的开发者网络,利用重启随机游走实现对开发者的用户推荐;但是该方法只考虑了用户的文本和标签相似性,仅在特定社区效果较好,扩展性较差。文献[9]中提出了结合用户社区和评分矩阵联合社区的推荐模型,在面向联合社区的矩阵中结合用户社区进行矩阵分解;但该模型仅考虑了用户静态兴趣偏好与社交关系,忽略了用户的兴趣和关系的动态变化。
综上,在推荐系统的研究中,面临推荐单一、跨平台用户匹配效率低的问题,因此,本文提出基于知识图谱和重启随机游走的跨平台用户推荐方法(User Recommendation method of Cross-Platform based on Knowledge graph and Restart random walk,URCP-KR),该方法包括基于知识图谱的跨平台用户关系补全算法(Cross-Platform user Relationship Completion algorithm based on Knowledge Graph,RCCP-KG)和基于重启随机游走的用户推荐算法(User Recommendation algorithm based on Restart Random Walk,UR-RRW)。首先,将目标平台图谱和辅助平台图谱分割匹配得到相似子图,利用多层循环神经网络(Recurrent Neural Network,RNN)得到候选用户实体,通过用户筛选匹配两个不同平台中可能相同的用户;然后,通过关系补全将辅助平台中的用户信息补全到目标平台图谱,完善用户之间的关系;最后,利用重启随机游走算法,获得具有相似兴趣的用户推荐列表,从而解决跨平台用户匹配、推荐单一的问题,提高用户推荐的准确率及多样性。
本文的主要工作如下:
1)提出了一种新的跨平台数据融合算法,基于知识图谱的跨平台用户关系补全算法RCCP-KG,把辅助平台中的相同用户信息补全到目标平台图谱中,实现跨平台数据融合,从而更加全面地刻画用户行为,同时发掘不同平台间的潜在用户关系,更加准确地进行相似用户推荐。
2)提出了一种基于重启随机游走的用户推荐算法URRRW,在传统随机游走的基础上融入用户兴趣信息,提升了推荐的多样性。
1 整体方案
1.1 相关定义
定义1 社交网络知识图谱(Social Network Knowledge Graph,SN-KG)。本文通过社交网络有向图构建SN-KG,将用户作为知识图谱中的实体,用户间的关注关系作为关系,用户属性作为实体属性,用户属性值作为实体属性值。
定义2 目标平台图谱G=(V,E),其 中:V={v1,v2,…,vi}是目标平台图谱中用户节点的集合,vi表示用户节点向量;E={e1,2,e2,3,…,ei,j}是目标平台图谱中用户节点之间边的集合,ei,j表示用户节点vi和vj之间的边。

定义4 实体关系三元组表示为(头实体,关系,尾实体)(h,r,t),边r的类型统一为“关注”关系,即用户h关注用户t。若干三元组的集合H={(h,r,t)|h⊆V,r⊆E,t⊆V}构成一个知识图谱,如图1 所示,社交网络知识图谱可以表示用户之间的关注关系。实体属性三元组表示为(实体,属性,属性值)(vi,ai,Va),其中用户属性集合为Ai={a1,a2,…,ai}。
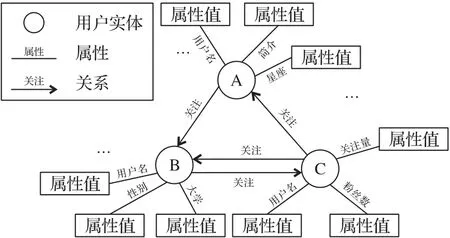
图1 社交网络知识图谱示意图Fig.1 Schematic diagram of social network knowledge graph
定义5 目标平台图谱子图集合SG={g1,g2,…,gi},是通过对目标平台图谱进行分割得到的子图集合,其中gi表示目标平台图谱的子图。

定义7 用户活跃时间关键词序列(vi,Kn),其中用户vi在活跃时间t内的发表的博文内容关键词kn按照时间先后顺序构成Kn={k1,k2,…,kn}。
1.2 整体框架
本文设计和实现了基于知识图谱和重启随机游走的跨平台用户推荐方法,其中包括RCCP-KG算法和UR-RRW 两个算法。具体实现过程如下:
1)利用社区检测实现目标平台图谱和辅助平台图谱的图分割和子图匹配,得到相似子图;
2)通过输入用户活跃时间关键词序列训练RNN 模型得到候选用户实体集合;
3)通过网络拓扑结构特征相似度和用户画像相似度对用户实体进行筛选,得到跨平台相同用户,实现实体链接;
4)将相同用户在辅助平台图谱的关系补全到目标平台图谱;
5)通过重启随机游走在目标平台图谱的社区中找到兴趣相似程度高的用户,形成用户推荐列表,实现跨平台用户推荐。
方法整体框架如图2所示。
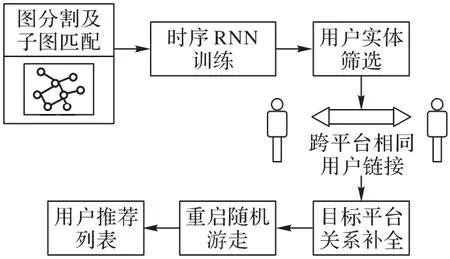
图2 本文方法整体框架Fig.2 Overall framework of the proposed method
2 基于知识图谱的跨平台用户关系补全算法
用户在不同平台所关注的内容和兴趣点可能不同,但同一用户的个人信息、好友以及影响力等具有极大的相似性。因此,识别两个平台中的相同用户问题,转换为匹配两个知识图谱中相同用户节点的问题。本章提出RCCP-KG 算法。首先,利用社区检测算法将目标平台图谱和辅助平台图谱分割为不同的子图,匹配跨平台中相似的子图;然后在相似子图中利用多层循环神经网络预测候选实体,再通过图谱的拓扑结构、用户画像相似度筛选出相似度最高的用户节点对;最后将相同用户在辅助平台图谱中的关系补全到目标平台图谱,实现跨平台间的用户关系补全。
2.1 基于社区检测的图谱分割及子图匹配
由于社交网络图谱用户数量庞大,直接匹配跨平台间的相似用户工作量较大,且误差较高,因此,本文首先将图谱分割为相似子图,然后在子图中匹配相似用户。
Louvain 是一种基于模块度的社区发现算法[10],通过模块度来衡量一个社区的紧密程度。关联关注紧密的用户可以分割在同一子图中,能够更好地体现用户群体的特性,便于子图相似性匹配。
首先使用Louvain 算法将目标平台图谱和辅助平台图谱分割为不同的子图集合SG={g1,g2,…,gi}和SG′=;然后,利用Pearson 矩阵相似度计算方法[11]匹配目标平台图谱子图集合和辅助平台图谱子图集合中相似子图对;接下来在相似子图对中匹配相同节点对。
2.2 基于多层循环神经网络的用户实体预测
首先,利用目标平台图谱中的用户实体和博文关键词序列训练多层循环神经网络;然后,将辅助平台图谱中的实体输入多层循环神经网络,经过用户相似度计算,得到在辅助平台图谱中与输入实体匹配的多个候选用户实体;最后,利用网络拓扑结构特征相似度和用户画像相似度对候选用户实体进行筛选,选出相似度最高的一个用户实体,与输入实体vi组成相似用户节点对vi=。
2.2.1 基于多层循环神经网络的候选用户实体预测
用户活跃在不同平台的时间可能相同也可能是错开的,但是发布的内容可能是相同的。目前很多社交网络平台允许用户分享相同的内容到其他的社交平台中,如知乎允许用户将发布的内容同时分享到微博。例如,18:00,A 用户在知乎上发布了一条动态,同时将此动态分享到微博。因此,用户在不同平台发布内容和时间是判断是否为同一用户的重要内容。并且,用户活跃时间关键词序列可以近似地看作是一个由词组成的句子。
RNN 是一种神经序列模型,已经在语言建模和机器翻译等许多自然语言处理任务上取得了优良的表现。知识图谱中的三元组(实体,关系,实体)由句子提取,本质上是具有序列性的。Guo等[12]在RNN的基础上提出了一种用于知识图谱补全的深度序列模型(Deep Sequential model for Knowledge Graph completion,DSKG),此模型具有序列特性,给定三元组中的头实体和关系,能够预测尾实体。DSKG 使用不同的RNN 单元处理实体v和关系r。根据模型DSKG,本文选取用户的博文关键词取代关系进行训练。
因此,本文设计了一种基于多层RNN 的实体预测模型(Entity Prediction model based on Multilayer RNN,EPMRNN),如图3 所示,输入层为用户vi活跃时间关键词序列(vi,Kn),然后通过多层RNN 训练得到用户vi隐藏状态hi,中间层输入是辅助平台图谱用户,输出层是目标平台用户与辅助平台用户的相似度概率。
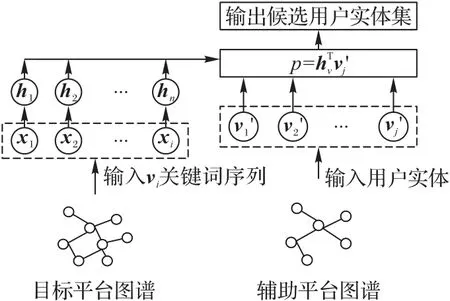
图3 基于多层RNN的实体预测模型Fig.3 Entity prediction model based on multi-layer RNN
如图4 所示,给出了两层RNN,其中c1、c2、c3、c4全都是各不相同的RNN 单元。使用c1、c2处理实体vi,使用c3、c4处理关键词ki。
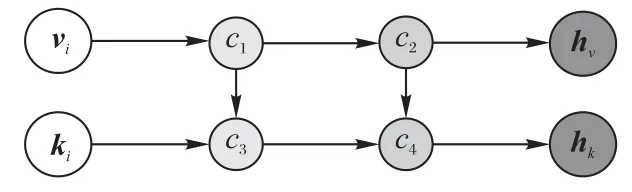
图4 两层RNN示意图Fig.4 Schematic diagram of two-layer RNN
c表示一个RNN 单元,它将之前的隐藏状态和当前元素作为输入,预测下一个隐藏状态,计算如下:

得到隐藏状态之后,预测用户实体的隐藏状态hv与辅助平台用户实体概率:

最后,通过最小化真实值和预测值间的交叉熵损失来训练模型。

其中:qi为预测概率分布,pi为真实的概率分布。
与用户vi相似度概率值大于等于阈值δ的辅助平台用户构成候选用户实体集Cv=,进入下一步筛选。
2.2.2 基于网络拓扑结构特征相似度的用户实体筛选
根据网络拓扑结构特征相似度将用户vi与其候选用户实体集合Cv=中的用户进行筛选。目标平台图谱节点vi的网络拓扑结构特征集合为由度中心性[13]DC(i)和聚类系数[14]CLi构成,计算如下:


使用余弦相似度计算目标平台图谱网络子图节点vi和辅助平台图谱中的候选节点的拓扑结构特征相似度:
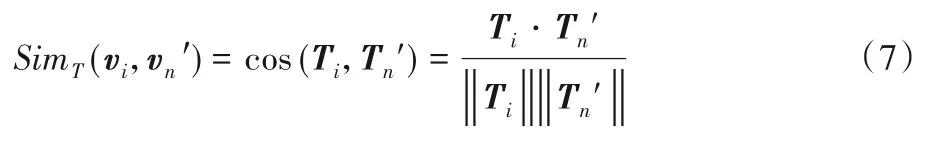
在Cv=中,筛选出拓扑结构特征相似度大于等于拓扑结构特征相似度阈值λ的用户,组成新的候选用户集合,进入下一步基于用户画像相似度的用户实体筛选。
2.2.3 基于用户画像相似度的用户实体筛选
用户在社交网络中的公开信息可以用于描述一个人的特征。使用用户画像可以快速、有效地描述社交网络中用户的个人信息及特征,如性别、年龄、职业、所在地、毕业院校等客观信息。联系电话和电子邮箱可以标识唯一的用户,因此,如果不同平台用户节点的联系电话或者电子邮箱相同,则认为是同一用户[15]。
首先,使用Word2vec[16]方法把用户实体的画像和属性Ai信息转化为画像特征向量F,进而通过用户画像的相似性度量用户节点的相似性。计算目标平台图谱用户与候选用户集合中用户的用户画像相似度SimF(vi,):
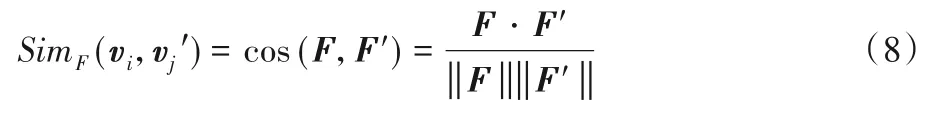
其中:F目标平台图谱节点的用户画像特征向量,F′为候选用户集合中的用户画像特征向量。
2.3 基于辅助平台图谱的目标平台图谱关系补全
首先,通过广度优先遍历[17],获取目标平台图谱用户节点vi所有的关系集合Ri={ri1,ri2,…,rij},其中关系为一阶关系,即记录可到达的下一个邻接用户节点的路径,rij=vi→vj。同理,在辅助平台图谱中获取相似子图中用户节点vi的所有路径集合。然后,根据上一节识别出的所有相同用户节点队,将辅助平台图谱路径中的相同用户替换为目标平台图谱的用户,去除相同的关系,即得到用户vi需要补全的关系集合Ri。
目前各高校图书馆还不具备专业的布展设施,往往根据临时的展览活动需求及展览规模,在馆内现有空间内因地制宜寻找相应的展览地点,并根据需要、展品珍贵程度、财力大小选择租用陈列柜。但这在展览的呈现效果及专业度上都显得不足,展柜等配置不能与展品良好地匹配,无法营造较为专业化的观展体验。

同理,获取子图中所有节点需要补全的关系集合。
当目标平台图谱中缺少辅助平台图谱的相似用户节点时,建立对应的虚拟节点与之替换,当新的节点出现在目标平台图谱时,可以与之比较,建立相应关系。
最后,按照关系集合中的关系,补全目标平台图谱中节点之间的关系。
2.4 算法执行过程
算法1 RCCP-KG算法。
输入 目标平台图谱G=(V,E),辅助平台图谱G′=(V′,E′),用户博文的时间关键词序列(vi,Kn);
输出 关系补全后的目标平台图谱G=(V,E)。

3 基于重启随机游走的用户推荐算法
传统的随机游走算法利用网络的拓扑结构,只考虑图的出度和入度,忽略了节点本身的特性。因此本文提出了基于重启随机游走的用户推荐算法UR-RRW,在补全后的目标平台图谱中,融合用户兴趣和用户间关系,采用重启随机游走完成用户推荐。社交网络知识图谱中的部分重启随机游走,如图5所示。
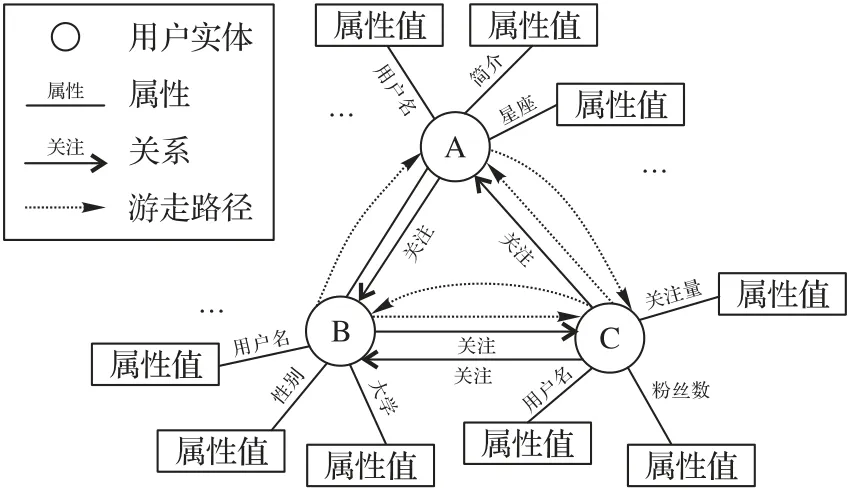
图5 重启随机游走示意图Fig.5 Schematic diagram of restart random walk
在补全后的目标平台图谱中,首先,确保用户节点间有较高的紧密连接,使用社区检测Louvain算法再次将用户实体进行社区划分,得到社区集合S={s1,s2,…,si},然后在每个社区中建立用户兴趣相似度矩阵,通过随机游走来寻找相似用户,计算用户间游走的平稳概率值,将其降序排列得到用户推荐列表。
3.1 用户兴趣相似度矩阵建立
首先,通过社区检测将用户划分成不同社区。在目标平台图谱,对于新添加的关系,给予与辅助平台图谱中相同的权重值。在原有社区的基础上,再次利用社区检测Louvain 算法,重新对社区内的用户节点进行模块度计算[18]。根据模块度变化值,增加或删除社区内的节点,最终确定目标平台图谱中的社区划分,得到新的社区集合S={s1,s2,…,si}。
然后,定义用户的兴趣相似度矩阵。用户间兴趣相似度需满足以下条件:
1)同一社区的用户间共同关注的用户的类型种类数li越多,则相似度越高;
2)同一社区的用户间对单一类型用户的关注次数Ni越多,则相似度越高。
为满足以上条件,定义矩阵M∈Rn×n,矩阵元素mij为vi∈V与vj∈V之间的相似度评分,如用户间无共同关注则mij=0,其形式如式(11)所示:

其中:lij为用户vi与用户vj共同关注用户的类型权重,li和lj分别是用户vi与用户vj关注的用户类型种类数;zij为用户vi与用户vj共同关注用户的次数权重。
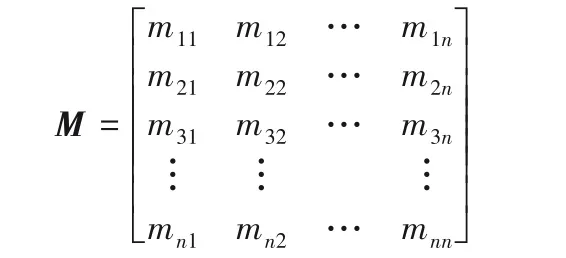
对M进行归一化处理得到用户兴趣相似度矩阵M′。

3.2 基于重启随机游走的用户推荐
本文采用基于用户兴趣相似度的重启随机游走算法,将得到的用户兴趣相似度矩阵M作为概率转移矩阵并输入到重启随机游走模型中,通过归一化的用户兴趣相似度矩阵计算得到平稳概率值[4]。

其中:yLast为经过n步游走后所得到的平稳概率值;θ为下一步游走到其最近邻节点的概率,θ为可调参数,通过实验验证θ取0.1;y0为用户的列向量,是向量y的初始向量,向量y中的每一项值代表着从用户vi经过n步游走后到达各个节点的概率值。
最后将平稳概率值yLast进行降序排序,形成用户推荐列表RL={u1,u2,…,uj},将 用户列表中未关注的用户进行推荐。
3.3 算法执行过程
算法2 UR-RRW。
输入 目标平台图谱G=(V,E);
输出 用户推荐列表RL={u1,u2,…,uj}。

4 实验与分析
本实验选取经典的协同过滤(CF)算法[3]、基于跨平台的在线社交网络用户推荐算法(User Recommendation algorithm based on Cross-Platform online social network,URCP)[7],以及使用重启随机游走的基于多开发者社区的用户推荐算法(User Recommendation algorithm based on Multi-developer Community,UR-MC)[8]作为对比方法与本文提出的URCP-KR方法相比较。当改变用户数量、用户平均关联关系数量以及用户平均博文数量时,本文选取精确率pre(precision)、召回率rec(recall)、F1 值F1、覆盖率cov(coverage)作为评价指标,具体指标介绍及公式如下:
精确率pre为正确推荐用户数TP与推荐列表用户总数|RL|的比值:

召回率rec为正确推荐用户数TP与目标平台中的好友总数FN的比值:

F1值均匀地反映了推荐效果:
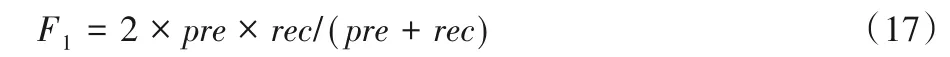
覆盖率cov为推荐用户总量|RL|与总用户数量|V|的比值,反映推荐的多样性:

4.1 实验环境
本实验在具有2.8 GHz Inter Core i7 处理器和16 GB 内存的机器上运行,操作系统为Windows 10,编程语言为Python。
4.2 实验数据
本实验选取微博作为目标平台,选取知乎作为辅助平台图谱。从微博和知乎采集了用户信息及其发布内容,把从已知的实名认证的用户作为起始节点爬取用户相关信息。通过深度优先搜索的方法采集节点的邻居信息,根据小世界理论[19],本文将深度优先搜索的深度设置为4。数据集包含用户的21 万条微博数据,19 万条知乎数据,共36 万对用户间关注关系数据。
4.3 参数设置
本文中用户相似度概率阈值β、拓扑结构特征相似度阈值λ和重启随机游走可调参数θ通过在测试集数据上实验,根据用户推荐F1 值的变化确定。由图6 可知,当β=0.4,λ=0.6,θ=0.1时,用户推荐的F1值最优。
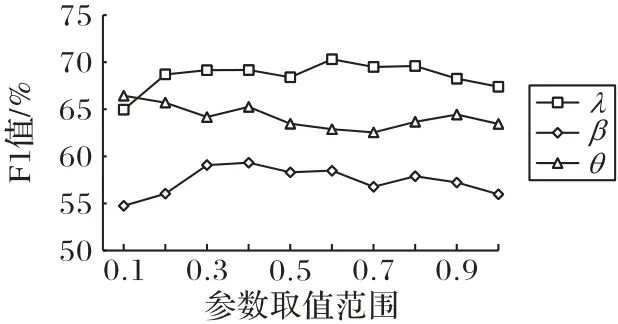
图6 F1值随λ、β和θ的变化结果Fig.6 F1 changing with λ,β and θ

表1 实验参数表Tab.1 Experimental parameter table
4.4 实验结果分析
将数据分为训练集和测试集,其中训练集用于训练模型,测试集用于衡量模型的性能。使用十折交叉验证,训练集采用总数据集的90%数据量,测试集使用10%。
由图7 可知,在用户数 |V| 较小时,本文提出的URCP-KR方法在精确率、召回率、F1 值和覆盖率都要优于对比方法;随着用户数量的不断增加,由于用户数量增长幅度比用户推荐数量增加幅度大,因此四种方法精确率、召回率和F1 值都有所下降,但是URCP-KR 方法下降趋势缓慢;在覆盖率方面,URCP-KR 方法先增后减,当用户数量为60 000 时,覆盖率最高为88.42%,推荐多样性优于对比方法。
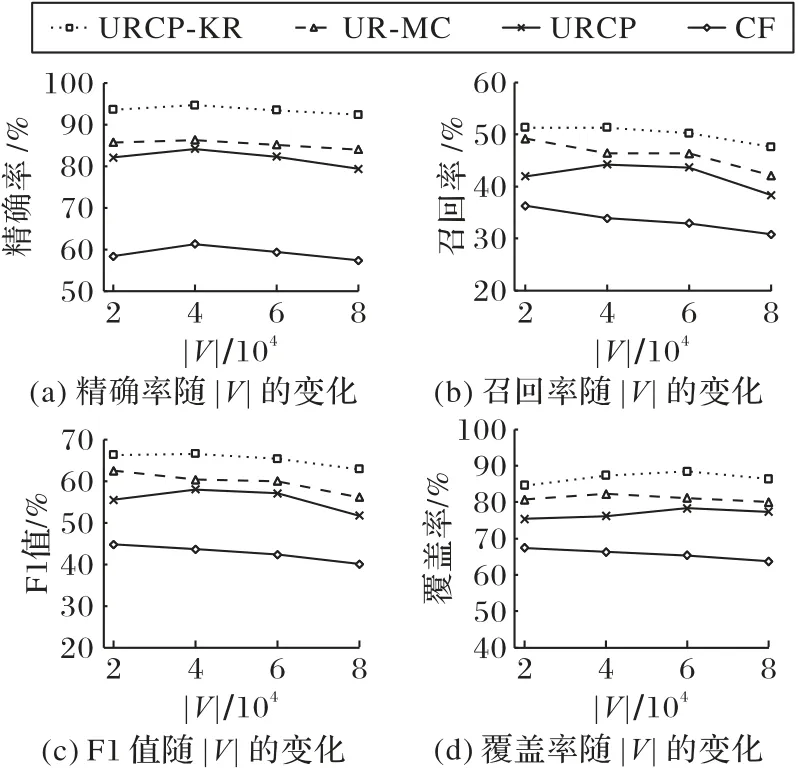
图7 用户数|V|变化时各方法的度量指标对比Fig.7 Comparison of metrics of each method when changing user numbers|V|
由图8 可知,随着用户平均关联关系数rn不断增加,URCP-KR 方法的精确率先增加后减小,当用户平均关联关系数量为40 时精确率达到最大,为95.31%;覆盖率方面逐步增加。因为URCP-KR 方法将不同平台的用户关系进行融合,丰富了目标平台的用户关系。CF 算法和UR-MC 算法则随用户平均关联关系数量增加到一定程度而受到用户评分数量和用户标签数量的限制。
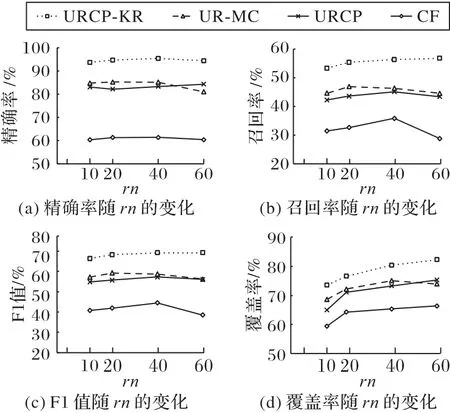
图8 rn变化时各方法的度量指标对比Fig.8 Comparison of metrics of each method when changing average number of user relationships rn
由图9 可知,随着用户平均博文数pb增加,URCP-KR 方法的精确率和覆盖率逐步增加并趋于平稳,因为用户博文数据越多,实体链接效率越高。同样,URCP 算法获取到的用户兴趣爱好主题数量增加,推荐精确率和覆盖率有较大的提高;但由于URCP算法通过API获取相同用户数量的有限性,因此推荐效果受限。
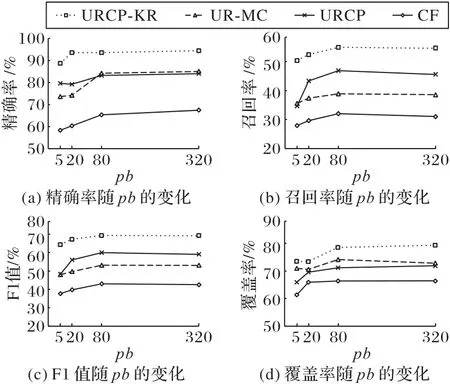
图9 pb变化时各方法的度量指标对比Fig.9 Comparison of metrics of each method when changing average number of user’s blogs pb
5 结语
在跨平台推荐系统环境下,本文提出了基于知识图谱和重启随机游走的跨平台用户推荐方法。首先,提出了基于知识图谱的跨平台用户关系补全算法RCCP-KG,利用改进的多层RNN 预测出候选用户实体,筛选出不同平台中可能相同的用户;然后,通过关系补全将辅助平台图谱中的用户信息补全到目标平台,完善用户之间的关系;最后,提出了基于重启随机游走的用户推荐算法UR-RRW,利用重启随机游走算法计算同一社区中用户的相似性,形成用户推荐列表,从而解决跨平台用户推荐问题,提高用户推荐的准确率及多样性。未来将对实体及关系消歧进行研究,增强跨平台间相同用户的匹配,进一步提高跨平台用户间的推荐准确性和多样性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军民两用技术与产品(2022年5期)2022-06-28
电脑报(2021年11期)2021-07-01
小型微型计算机系统(2021年10期)2021-02-28
通信产业报(2020年31期)2020-09-10
计算机与数字工程(2019年10期)2019-11-12
科技风(2019年13期)2019-06-11
计算机与数字工程(2019年3期)2019-03-26
新城乡(2018年6期)2018-07-09
领导科学论坛(2016年9期)2016-06-05
