
基于组合神经网络模型的球磨机数据插补方法研究
2021-08-23 01:06王智强郑丽岩任世杰
现代矿业 2021年7期
孟 巍 王智强 叶 茂 郑丽岩 任世杰
(1.鞍钢集团矿业有限公司信息中心;2.沈阳中科奥维科技股份有限公司;3.东北大学资源与土木工程学院)
电铲、球磨机、旋流器等大型矿业设备作为矿山运行的核心一直是企业重点关注的对象[1],这些设备出现故障,势必导致生产停滞,甚至造成安全问题[2]。为了减少设备故障带来的损失,企业通常会对这些设备进行监控[3]。对设备的运行监控通常是按照时间序列进行的,然而在数据采集的同时,仍然难以避免出现数据缺失的现象,而数据的丢失往往会造成预警信息的错误,因此通常需要对缺失的数据进行适当的处理,从而完成对设备运行状态的正确评估[4]。
缺失数据的处理方法包括删除法、插补法、加权法和参数似然法等,而在各种处理缺失数据的方法中,插补方法由于简单且效果好被普遍使用[5]。随着机器学习和深度学习的快速发展,神经网络技术被广泛应用于数据缺失值的处理并取得了较好的结果[6]。缺失数据的插补在一定程度上可以看成是对一些未知数据的预测[7],而利用BP神经网络等模型对已有数据进行训练学习,然后利用训练好的模型输入参数获得预测值即可很好地解决数据缺失的插补问题。除了传统的BP神经网络外,循环神经网络(简称RNN)将时序的概念引入到网络结构设计中,使其在数据的分析预测中取得了更好的结果。长短期记忆(简称LSTM)模型作为RNN的优秀变体也被应用于各种数据的预测中[8]。为了更准确地完成缺失值的插补过程,本文利用BP神经网络和LSTM模型相结合的方式对球磨机的缺失数据进行预测。
1 神经网络概述
磨矿是矿石破碎的后续工序。球磨机是磨矿的主要设备。为了实时监控球磨机的运行状态,需要采集球磨机的多项运行参数,如给矿量、给水量、压力、电流值、给矿浓度、给水浓度、排水量等。这些参数在某种程度上存在着一定的复杂联系,单凭经验公式很难对因故丢失的数据进行预测补充,而神经网络的“黑箱”特性可以解决该问题。
BP神经网络是一种多层前馈型神经网络,其学习过程由信号的正向传播与误差的反向传播两个过程组成。在信号正向传播的过程中,样本是由输出层传入,经过各个未显露的隐含层内部计算后传入输出层,最终经输出层处理后产生预测结果,将网络预测值与实际值对比,计算出神经网络的预测误差,接着进入误差的反向传播阶段(图1)。误差反向传播时,预测误差从输出层传入,经过各个隐含层处理传入输入层。在预测误差的传递的同时,也将预测误差分给各层,当各层获得作为修正该层的神经元权值依据的误差信号时,由学习信号正向传播与误差信号反向传播不断调整各层权值,当神经网络输出的误差减少到设定的期望误差或满足当前设置的迭代次数时,终止权值的调整。

传统的BP神经网络不考虑数据之间的时间相关性,只将上一层的输出作为当前层的输入。现实中的很多数据都具有时序上的关联性,即某一时刻网络的输出除了与当前隐含层的输入相关之外,还与之前某一隐含层或某几个隐含层的输出有关。针对这些问题,循环神经网络RNN模型应运而生(图2)。在许多序列问题中,例如文本处理、语音合成及机器翻译等,循环神经网络都表现出了不凡的性能。然而RNN模型随着时间序列的不断深入,会出现“梯度消失”和“梯度爆炸”的现象。
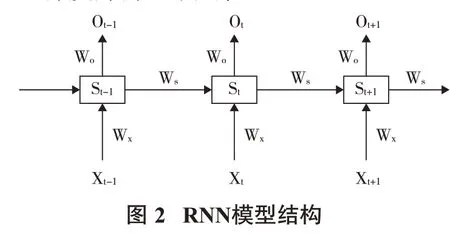
图3中,LSTM模型作为RNN的变种,既拥有RNN在分析时序数据时的高适应性,又弥补了RNN的梯度消失和梯度爆炸问题,能有效地利用长距离的时序信息。对于球磨机的监控数据,利用好时序信息可以更有效地解决数据的缺失与插补问题。

2 组合模型方法
单一的预测模型总会有各自的优点和缺陷,如BP神经网络的优点是具有很强的非线性映射能力和柔性的网络结构,缺点是学习过程耗费的时间多及不易找到全局极小值点。LSTM模型的优点是在序列建模问题上有一定优势,具有长时记忆功能,缺点是并行处理上存在劣势。为了充分利用不同模型各自的优势,不同模型的组合应用是一种常用的办法,新模型将不同模型的优势组合应用,可以使组合模型的预测结果更加接近真实值。由于球磨机的监控数据本身是关于时间的数据,可以看作时间序列,因此本文选择LSTM模型与BP神经网络相结合的方式对缺失数据进行预测。本文设计了基于权重分配方式的组合预测模型(图4)。该方法的主要思路是分别使用BP神经网络和LSTM模型对球磨机的某项缺失数据进行训练预测,然后根据预测的准确率赋给每个算法的结果1个权重系数,将每个模型预测的结果乘以权重系数后做和,形成最终的预测结果。

预测结果公式为

式中,R为总的预测结果;Rlstm为LSTM模型的预测处理结果;Rbp为BP模型的预测处理结果。
为了使预测结果更加接近真实值,引入修正误差方法,即误差权重乘以训练集平均误差,各模型修正结果计算公式为
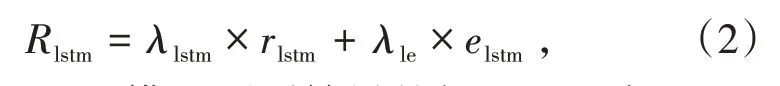
式中,λlstm为LSTM模型预测结果的权重;rlstm为LSTM模型的原始预测结果;λle为LSTM模型预测结果的误差权重;elstm为LSTM模型在训练集上的平均误差。
同理,BP模型修正公式为

式中,λbp为BP模型预测结果的权重;rbp为LSTM模型的原始预测结果;λbpe为BP模型预测结果的误差权重;ebp为BP模型在训练集上的平均误差。
预测权重λlstm和λbp,计算公式为

式中,acclstm为LSTM模型上预测集的准确率;accbp为BP模型上预测集的准确率。
误差权重λle和λbpe计算公式为

式中,erlstm为LSTM模型上预测集的误差率;erbp为BP模型上预测集的误差率。
3 数据处理过程
试验选取电流值、排水量、给矿量、给矿浓度、压力、泵池高、给水量、给水浓度和给旋流器量9个球磨机监控数据,数据每隔5s采集1次,共计10万条。将数据按9∶1分为训练集和测试集,在给矿量数据中随机选取10个数据删除后作为缺失值进行预测比较。试验采用的深度学习框架为tensorflow,具有运行速度快,结构简洁,高层API丰富等优势。该试验的实现过程在jupyter编译器上实现,试验步骤如下。
(1)第1步引入外部包。引入tensorflow机器学习框架用以搭建模型,引入numpy库用以处理数据,引入xlrd库用以从数据库中读入数据,引入matplotlib库用以实现绘图。
(2)第2步导入并处理数据。从数据库中导入数据,并对数据进行处理以便输入模型进行学习。其中数据按9∶1分为训练集与验证集,从验证集中随机取10个数据作为测试集用来检验模型预测结果的好坏。其中,LSTM模型的输入数据以给矿量的11个连续数据作为1组,依次类推直至数据全被分配完毕。BP模型的输入数据为除去时间的其余9个相关数据。
(3)第3步构建模型。LSTM模型构建为2个LSTM块顺次相连,最后添加1个全连接层输出预测结果。值得一提的是,LSTM模型输入的数据维度为三维,其中第一维代表每次输入模型的数据组个数,即训练中的batch_size。第二维代表用来预测结果需要的参数的个数。第三维代表输出的特征数的个数,本文中输出的特征值只有给矿量的预测值,故本文中各个模型输出的特征值数目为1。
LSTM模型中采用均方差作为损失函数,Adam作为优化函数,训练过程中观察模型中每个epoch的损失值。训练过程中迭代次数为136次,batch_size为100。不同神经网络预测结果见图5。

BP模型的结构为2个全连接层顺次相连,其中第1个全连接层的隐藏节点数为10,激活函数为Relu,第2个全连接层的节点数为1,即输出的特征值的个数。BP模型的输入数据维度为二维,其中第一维代表每次喂入模型的数据组的个数,即训练中的batch_size,第二维代表每个数据组中参数的个数。
BP模型同LSTM模型一样采用均方差作为损失函数,采用Adam作为优化函数,训练过程中观察每个epoch的损失值。训练过程中迭代次数为100,batch_size为10。经过长时间训练后,得到模型权重,并记录损失值不下降时每个模型在训练集上的误差绝对值的平均值用来计算预测时的修正误差。
(4)第4步结果预测。将测试集的10个数据组分别输入LSTM模型以及BP模型中,得到的预测值经过公式(1)处理后得到最终预测值。将得到的3种预测结果分别与真实值比对发现,组合模型得到的预测结果优于单一模型得到的预测结果。其中,使用BP模型预测准确度为92%,使用LSTM模型预测准确度为96%,使用BP-LSTM组合模型预测准确度为98%。
4 结 论
为了更好地对球磨机缺失数据进行预测插补,利用BP和LSTM 2种神经网络对缺失数据进行预测,结果表明,使用2种神经网络的组合模型可以使预测结果达到更优,证明该方法是切实可行的,也为缺失值的预测插补提供了新的思路。
猜你喜欢
防爆电机(2022年2期)2022-04-26
当代陕西(2020年17期)2020-10-28
石油化工建设(2019年6期)2020-01-16
电子制作(2019年20期)2019-12-04
电子制作(2019年19期)2019-11-23
人大建设(2018年5期)2018-08-16
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
应用科技(2015年5期)2015-12-09
新疆钢铁(2015年1期)2015-11-07
