
面向高考咨询问答系统的问句分类研究
2021-09-10 07:22刘园园李劲华赵俊莉
青岛大学学报(自然科学版) 2021年1期
关键词:支持向量机
刘园园 李劲华 赵俊莉

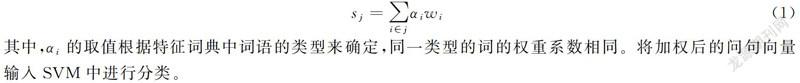


摘要:为建立一个高质量的问答系统,在建立高校信息知识图谱的基础上,提出一种在问答系统领域进行问句分类的方法,并构建了新的分类模型:基于改进的支持向量机模型、融合注意力机制的双向长短时记忆网络(BiLSTM-Attention)模型和BERT-BiLSTM相似度计算模型,并与BERT微调模型作比较。研究结果表明,本问句分类方法能获得较高的问句分类准确率,BERT模型具有更好的分类性能,而将Bi-LSTM和BERT进行融合对句子特征的提取能力更强。
关键词:问答系统;问句分类;支持向量机;长短时记忆网络;BERT
中图分类号:TP391
文献标志码:A
文章编号:1006-1037(2021)01-0018-07
基金项目:
国家自然科学基金 (批准号:61702293)资助;山东省重点研发计划(批准号:2019JZZY020101)资助。
通信作者:李劲华,男,博士,教授,主要研究方向为软件工程、算法理论、大数据理论与技术。
问答系统是近年来自然语言处理、信息检索等领域研究的热点,接收人们自然语言方式的提问,并返回简洁、准确的答案,由于无需用户从大量的结果页面中手动定位所需信息,因此问答系统能更好的满足人们对信息检索的需求[1]。问句分类是问答系统的首要环节,能否对用户输入的问题进行正确分类极大地影响了问答系统的准确性:准确的问句分类不仅可以减少候选答案空间,而且能提高答案检索效率和答案的准确率,还可以作为一种附加信息用于相似度计算[2]。问句分类的关键是选择和提取问句中的特征[3],目前对问句分类的相关研究较多,如考虑疑问词等在问句中的重要性,Xu等[4]提出了一种将依存关系和高频词结合作为附加特征的方法,在UIUC问题集上用支持向量机分类,比基线方法提高了大约3%;考虑到FAQ(Frequently Asked Questions)类问答模块的实现需要同时实现问句分类和问句相似度匹配,孙泽建等[5]利用TextRank算法和IDF(Inverse Document Frequency)值来加权词向量以表征问句,通过改进的k近邻算法将两个不同的问句相似度模型结合,在候选类别为3的情况下分类精确率达到92%;王东波等[6]利用TF-IDF提取类别特征词,在BiLSTM(Bidrectional-Long Short Term Memory Network)上进行了先秦典籍问句分类的研究,取得了较好的效果;Devlin等[7]提出预训练语言模型BERT(Bidirectional Encoder Representations from Transformers),在各种自然语言处理任务中展现了良好的性能,因此陆续出现了与BERT相关的问句分类研究[8]。以上研究对于本文研究问句分类模型具有重要的借鉴意义和指导价值。但是目前对于问答系统中问句分类的研究大多只是在算法方面的改进,很少涉及知识图谱领域,问句的类别也不多。由于知识图谱[9]可以把碎片化知识组织起来,建立数据之间的关联,越来越成为问答系统常用的数据存储形式,因此在知识图谱领域进行问句分类的研究很有必要。知识图谱是由节点和边组成的一种数据库[10],节点代表实体,边代表实体间的关系,在基于知识图谱的问答系统中,用户询问的可能是某个实体,可能是实體的某一个属性,也可能是实体间的关系,这就需要对用户的意图进行识别,也就是问句分类。由于知识图谱包含的实体和属性众多,因此对问句分类的模型和方法提出了更高的挑战。本文基于构建的高校信息知识图谱,提出了一种在问答系统领域进行问句分类的方法,并提出了三种问句分类模型,然后在收集的高考咨询问句中进行对比实验。
1 问句分类方法
1.1 构建问句的分类体系
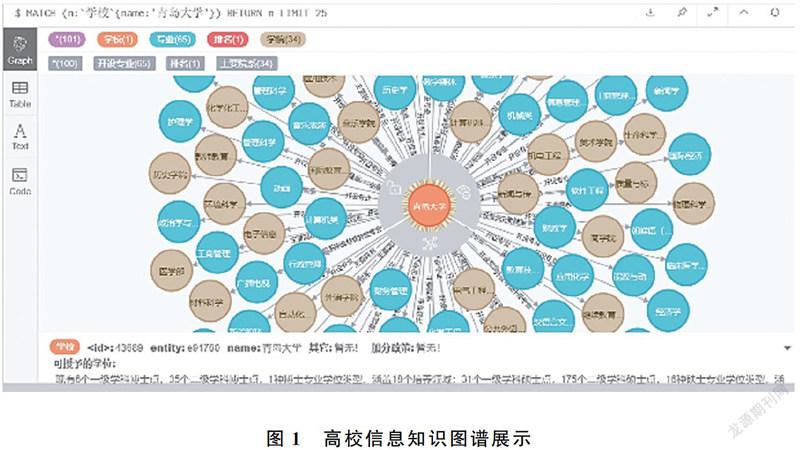
在问句分类之前要先确定问句的类别,本文构建的高校信息知识图谱包含学校、学院、专业、人、省份、时间等多个实体,每个实体又包含多个属性,如“学校”实体就包含地址、周边环境、加分政策等10多个属性,如图1所示。问答系统必须要给用户返回一个精确的答案,因此只涉及实体层面的分类体系无法满足需要,但是若把每个实体的属性都列举出来作为问句的类别,又会因为类别太多而影响分类的准确率,而且后期如果添加新的属性就要重新训练分类模型,不易于系统维护。因此本文结合建立的高校信息知识图谱,构建了新的问句分类体系,如表1所示。
本文将每个实体类型扩充为两种类别:实体类和实体_属性类。实体类就是这个实体本身的类别,如学校、专业等;实体_属性类就是实体所具有的所有属性,如学校_属性类就包含简介、地址、招生简章等各种类别。所有的实体类、实体_属性类以及一个关系类构成了问句的大类别,所有的实体_属性类下的属性构成了问句的小类别。如问句“山东大学有哪些专业”的类别是“专业”,而“山东大学计算机专业都开设哪些课程”的类别就是“专业_属性”类下的“开设课程”类别,合并为“专业_开设课程”类。
1.2 问句分类步骤
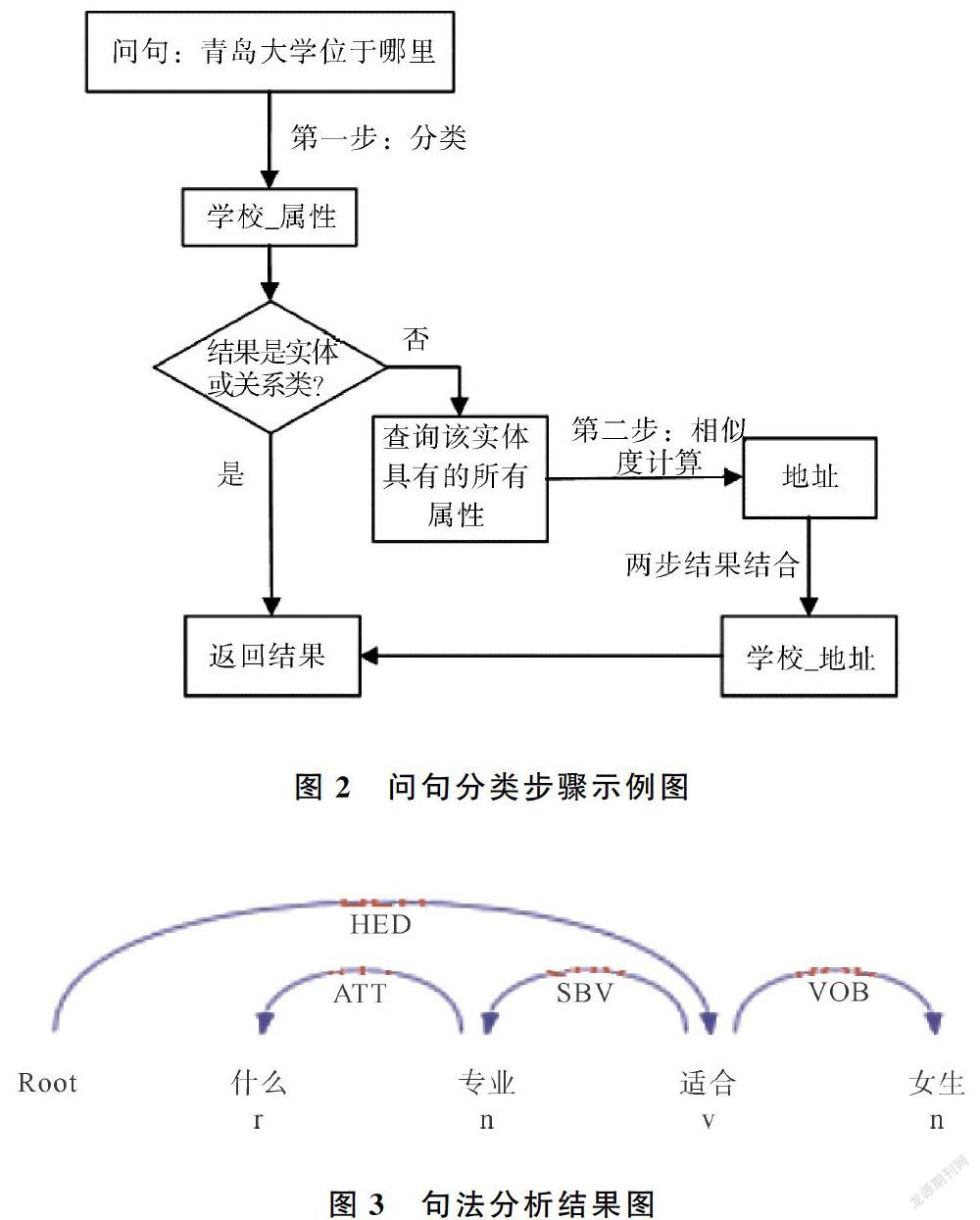
根据上述的问句分类体系,将问句分类分为两步。首先,进行大类别分类,若是大类别分类的结果是实体,那么就直接返回结果,如果分类的结果是实体_属性,那么就进行第二步分类。第二步分类是小类别分类,采用相似度计算算法来获得问句类别,具体做法是从知识图谱中获取该实体所具有的所有属性,然后分别与输入的问句进行相似度匹配,选择匹配度最高的作为小类别的分类结果。具体步骤如图2所示。这种分类方法不仅可以减少由于问句类别过多对于分类准确率的影响,还可以提高模型的健壮性,即使后期需要在知识图谱中添加新的属性,也基本不需要重新训练模型。
2 问句分类模型
本文采用了三种分类模型和一种相似度模型对高考咨询问句进行分类研究。由于支持向量机[11]在文本分类问题上一直有着良好的效果,因此本文首先选用支持向量机进行问句分类;深度学习是近些年来研究的热点[12],LSTM在句子建模方面[13]几乎始终优于CNN[14],而BiLSTM能通过双向传播机制保存上下文信息,在处理序列化数据上有优势[15],融合注意力机制后的BiLSTM模型能够得到关于注意力的概率分布,提高模型的分类性能,因此,本文构建了Bi-LSTM-Attention的深度学习网络模型用以问句分类;文本还将BERT引入高考咨询领域进行问句分类研究,以期取得理想的效果。
2.1 基于加权词向量的支持向量机分类模型
支持向量机(Support Vector Machine,SVM)是一种基于统计学习理论的分类器,其优化目标就是找到一个最优分隔超平面,使得离分隔超平面最近的点离超平面的距离尽可能的远。Word2vec能够把文本中的词语转换成向量空间中的向量,向量的相似度可以用来表示词语语义的相似度,但是Word2vec词向量不能分清词语间的重要程度[16],而问句中所包含的疑问词等对问句分类起着非常重要的作用,在很大程度上决定了问句的类别,如“谁”、“哪里”、“什么时候”等。另外,主、谓、宾等不同的词对于句子类别的决定作用也不相同,因此可以通过建立疑问词表以及结合依存句法分析等方法提取特征词,赋予其不同的权重。
图3为利用哈工大LTP平台[17]的句法分析结果,以图3为例,本模型提取问句特征的方法可以分为三步,将提取的词按类型添加进特征字典d中:
(1)根據预先建立好的疑问词表查找问句中的疑问词q,图1中包含疑问词“什么”,因此,将疑问词和其类型以键值对形式加入到特征字典中,即d={'什么':'q'};
(2)根据依存弧关系,查找疑问词的依存词f,更新字典为d={'什么':'q';'专业':'f'};
(3)依次根据依存弧HED、SBV、VOB找句子的核心词h、主语s和宾语o,如果某特征词在字典中已经存在,则跳过不添加,仅保留一个作为特征。如上一步中“专业”已经作为疑问词依存词添加进字典中,那么就不再作为主语添加,最终的特征字典是d={'什么':'q';'专业':'f';'适合':'h';'女生':'o'}。
对于每条问句j和句子中的每个词i,wi是经过Word2vec模型训练出来的词向量,αi是词i的权重系数,那么问句向量为
其中,αi的取值根据特征词典中词语的类型来确定,同一类型的词的权重系数相同。将加权后的问句向量输入SVM中进行分类。
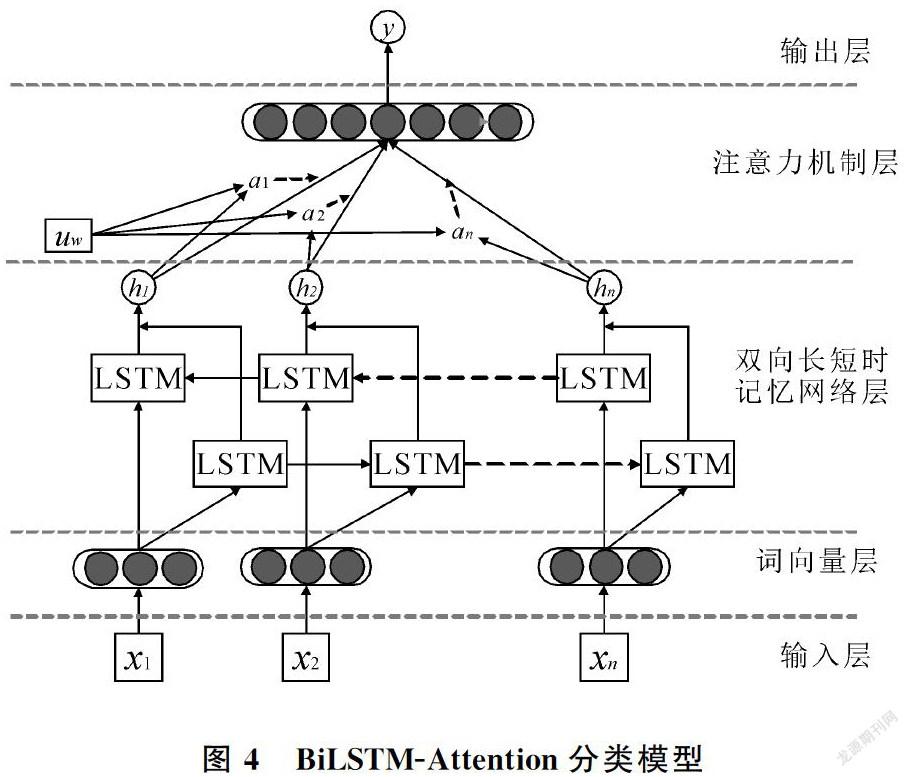
2.2 基于词向量的BiLSTM-Attention分类模型
图4为本文构建的BiLSTM-Attention分类模型图,共有5层结构:输入层,词向量层,Bi-LSTM层,注意力层和输出层。
(1)词向量层:首先对输入的问句中的每个词x1, x2, …, xn,进行对应的词向量表示,在此仍采用Word2vec词向量。由于LSTM网络可以通过增加细胞数量来记住更多的语言特征[18],而且Attention机制会对每个单词的权重进行自行分配,因此不对词向量进行加权;
(2)BiLSTM层:接收上一层的输出作为输入,充分捕捉问句信息,得到输出向量h1, h2, …, hn;
(3)注意力层:在注意力层计算各个hi的概率分布αi,然后计算加权和得到句子表示。首先生成hi的隐藏表示ui,然后计算ui在词级别的上下文向量uw中的重要性,uw可以看做是一个固定查询“什么是重要单词”的高级表示等[19],是在训练过程中初始化和联合学习的。然后通过softmax函数得到归一化的权重αi,最后将上一层的输出hi和αi的加权和作为句子的向量表示;
(4)输出层:使用一个softmax函数得到预测类别y。
2.3 BERT预训练语言表示模型
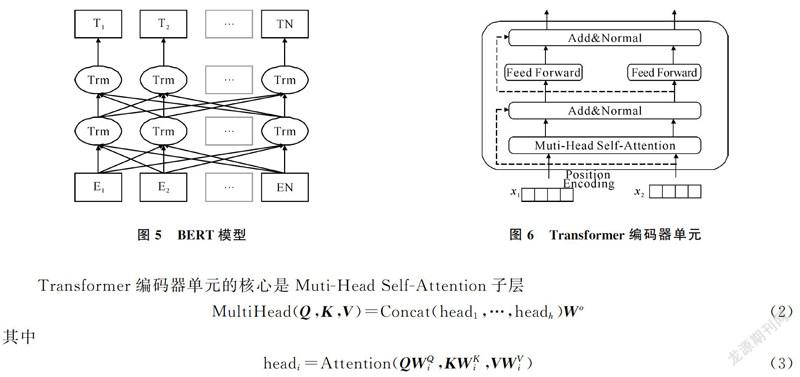
BERT是一种基于微调(fine-tuning)的预训练语言表示模型。预训练语言表示模型的思想就是在进行网络训练的时候不再对网络模型随机初始化,而是先预训练通用模型,用这个通用模型的参数对网络模型初始化,然后再根据具体应用,用有监督的训练数据微调模型,使之适用于具体应用。BERT的模型架构如图5所示,BERT是一个双向Transformer[20]编码器,具有更强大的表义能力。单个Transformer编码器单元如图6所示,共包含两个子层:Muti-Head Self-Attention层和一个简单的前馈网络。对每个子层增加了一个残差连接和层标准化。
其中,Q,K,V都是向量矩阵,dk是向量维度。式(3)中的Attention函数可以描述为将Q和K-V对映射到输出。Self-Attention的核心思想是一句话中每个词对于其他词的重要程度是不同的,通过计算这些词与词之间的关联程度来调整每个词的权重以获得每个词新的表示,这个新的表示包含了其他词与这个词的关联程度,因而比词向量包含更全面的信息。
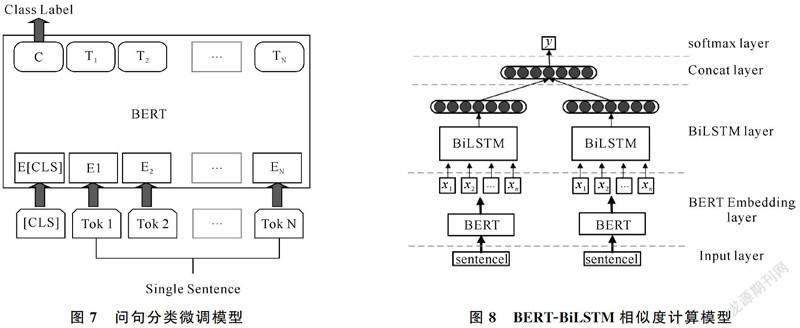
传统的语言模型只能通过一个词的上文或下文信息去预测该词,不能完整地理解整个语句的语义,即使双向LSTM能通过双向传播机制实现双向预测,但也只是把从前往后和从后往前得到的两个预测拼接在一起,仍然不能完整地理解整个语句的语义。BERT模型用了两个训练任务——“Masked语言模型”任务和“下一句话预测”任务实现上下文同时预测,取得了较好的效果。这两个训练任务合在一起,称为预训练。在得到的预训练模型的基础上,只需将特定任务的输入和输出插入到BERT中,对端到端的所有参数进行微调就能得到符合要求的模型。本文的任务是问句分类,所需要的微调模型如图7所示,由于[CLS]的向量表示包含了整个句子的语义信息,因此被送到输出层用于分类。
2.4 相似度计算模型
BERT在相似度计算方面的微调模型和问句分类类似,都是将第一个Token的输出作为整个句子的语义表示,但效果却不如问句分类的微调效果好,因此本文将BERT与Bi-LSTM结合[21]来构建新的相似度计算模型:使用BERT初始化词向量,将每个Token的输出,作为双向长短时记忆网络的输入[22],进行进一步的特征提取,然后生成句子的语义表示,最后将两个向量拼接在一起经过一个softmax层得到相似度标签。搭建的模型结构如图8所示。
3 实验及结果分析
3.1 评价标准
本文采用精确率(Precision)、召回率(Recall)、调和平均值F1对结果进行评价
其中各参数含义如表2所示,A、B、C、D代表实验结果中符合所属情况的问句个数。
3.2 实验结果
本文通过Python爬虫在百度知道、贴吧、各个学校的招生网站等爬取和收集与高考咨询相关的问句,共3 000条,共有21种大类和42种小类。标注数据集时首先按大类别进行标注,然后再将实体_属性类的问句按小类别进行标注。小类别相似度计算模型的输入是两个句子,第二个句子分别是该实体的所有属性,相似标为1,不相似标为0。将标注好的数据按照7:3的比例分为训练集和测试集。实验的运行环境均是在联想深度学习综合应用平台DeepNEX上,使用Python语言以及TensorFlow1.12.0框架。实验结果如表3、表4所示。
表3是大类别的分类结果,其中加权SVM模型中疑问词及其依存詞、核心词、主谓宾的权重系数分别是3.4、1.6、1.4,此时达到较好的效果。从对比实验可以看出,加权词向量比不加权的词向量的分类效果要好,说明疑问词和依存句法对特征的提取是有效的,加权之后更能表达问句特征;基于注意力机制的Bi-LSTM模型的准确率略高于SVM,而BERT的准确率最高,即BERT对特征的提取能力最强。
表4是小类别相似度计算的实验结果,可以看到BERT-BiLSTM模型的准确率稍高于BiBERT,说明在BERT基础上利用LSTM对特征进行进一步优化可以有效提高相似度计算的准确率。表5是利用BERT微调在所有的68种问句上直接进行问句分类的实验结果,联合表3、表4的最优实验结果(即本文方法)进行对比,可以看到实验准确率要偏低。
3.3 问句分类可视化
本文将改进的问句分类模型用Python的tkinter模块搭建GUI界面进行可视化包装,实现问句的分类查询,如图9所示,将待查询的问句输进输入框内,点击分类按钮,即可查询问句类别。
4 结论
本文对问句分类进行了研究,提出了问答系统领域的问句分类方法,首先按照实体和属性将问句分为大、小类别,然后分两步进行问句分类,不仅能提高准确率,而且能提高模型的健壮性。同时研究了4种分类模型,实验结果表明,结合依存句法分析和疑问词表进行特征加权的SVM模型能有效提高句子的分类效能,表明问句特征对于问句类别十分重要;而融合注意力机制的BiLSTM-Attention模型的分类准确率比加权的SVM模型高,说明人工选择的特征相对粗糙,而Attention实际就是一种自动加权机制,无需手动选择特征,能自动达到较好的效果;BERT模型的分类效果最好,因为BERT通过双向Transformer编码器动态生成字的上下文语义表示,解决了一词多义问题,生成的语义表示比传统的词向量更能表达语义特征。由于将BiLSTM模型与BERT结合能达到更好的效果,因此下一步的研究方向是尝试将其他传统的深度学习模型与BERT结合,探索更好的模型融合方式,以及问答系统的具体实现。
参考文献
[1]镇丽华,王小林,杨思春. 自动问答系统中问句分类研究综述[J]. 安徽工业大学学报(自然科学版),2015,32(1):48-54+66.
[2]LI D,WEI F,ZHOU M,et al. Question answering over freebase with multi-column convolutional neural networks[C]// Meeting of the Association for Computational Linguistics & the 7th International Joint Conference on Natural Language Processing. Beijing:2015:260-269.
[3]SUN H, WEI F, ZHOU M. Answer extraction with multiple extraction engines for web-based question answering[C]// CCF International Conference on Natural Language Processing and Chinese Computing. Berlin, 2014.
[4]XU S,CHENG G,KONG F. Research on question classification for automatic question answering[C]//2016 International Conference on Asian Language Processing (IALP).Tainan,2016:218-221.
[5]孙泽健,司光亚,刘洋.面向兵棋演习的问答系统问句分类模型研究[J]. 计算机与数字工程,2019,47(2):308-313+319.
[6]王东波,高瑞卿,沈思,等. 基于深度学习的先秦典籍问句自动分类研究[J]. 情报学报,2018,37(11):1114-1122.
[7]DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of deep bidirectional transformers for language understanding[DB/OL],(2019-05-24)[2020-12-11]. https://arxiv.org/pdf/1810.04805.pdf.
[8]杨飘,董文永. 基于BERT嵌入的中文命名实体识别方法[J/OL]. 计算机工程,[2020-10-02]. https://doi.org/10.19678/j.issn.1000-3428.0054272.
[9]ZHU S G, CHENG X, SU S. Knowledge-based Question Answering by Tree-to-sequence Learning[J/OL]. Neurocomputing, 2020, 372: 64-72(2019-12-21)[2020-12-11].https://pdf.sciencedirectassets.com/271597/1-s2.0-S0925231219X00429/1-s2.0-S0925231219312639/main.pdf.
[10] ZHANG K, WU W, WANG F, et al. Learning distributed representations of data in community question answering for question retrieval[C]//Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, San Francisco: ACM, 2016: 533-542.
[11] 范支菊,張公敬,杨嘉东.基于密度裁剪的SVM分类算法[J].青岛大学学报(自然科学版),2018,31(3):46-51.
[12] 陈茗杨,赵志刚,潘振宽,等.基于深度学习的图像实例分割[J].青岛大学学报(自然科学版),2019,32(1):46-50+54.
[13] TANG D,QIN B,LIU T. Document modeling with gated recurrent neural network for sentiment classification[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon,2015:1422-1432.
[14] 王炳琪,吴则举.基于改进的CNN的啤酒瓶盖字符识别[J].青岛大学学报(自然科学版),2020,33(3):34-42.
[15] 任勉,甘刚. 基于双向LSTM模型的文本情感分类[J]. 计算机工程与设计,2018,39(7):2064-2068.
[16] 汪静,罗浪,王德强. 基于Word2Vec的中文短文本分类问题研究[J]. 计算机系统应用,2018,27(5):209-215.
[17] CHE W, LI Z, LIU T. LTP: A Chinese language technology platform[C]// COLING 2010, 23rd International Conference on Computational Linguistics.Beijing, 2010.
[18] RAZZAGHNOORI M,SAJEDI H,JAZANI I K. Question classification in Persian using word vectors and frequencies[J]. Cognitive Systems Research,2018,47:16-27.
[19] YANG Z,YANG D,DYER C,et al. Hierarchical attention networks for document classification[C] //Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. San Diego, 2016:1480-1489.
[20] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need[DB/OL]. (2017-12-06)[2020-12-11]. https://arxiv.org/pdf/1706.03762.pdf.
[21] THYAGARAJAN A. Siamese recurrent architectures for learning sentence similarity[C]//Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. Phoenix: AAAI Press, 2015: 2786-2792.
[22] REIMERS N, GUREVYCH I. Sentence-BERT: Sentence embeddings using siamese BERT-Networks[DB/OL]. (2019-08-27)[2020-12-11]. https://arxiv.org/abs/1908.10084.
猜你喜欢
现代电子技术(2016年23期)2017-01-12
现代电子技术(2016年23期)2017-01-12
无线互联科技(2016年13期)2017-01-10
中国水运(2016年11期)2017-01-04
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
考试周刊(2016年53期)2016-07-15
