
基于挤压和激励残差网络的歌声检测
2021-09-23 02:13桂文明吕家伟梁颖红敖志强
复旦学报(自然科学版) 2021年3期
桂文明,吕家伟,梁颖红,敖志强
(1.金陵科技学院 软件工程学院,江苏 南京 211169;2.南京邮电大学 宽带无线通信与传感网技术教育部重点实验室,江苏 南京 210003;3.南昌航空大学 软件学院,江西 南昌 330063)
歌声检测(Singing Voice Detection,SVD)是判断存在于数字音频形式的音乐中的每一小段音频是否含有人的歌声的过程,其检测精度一般在50~200 ms之间.在每一小段音乐中,除了歌声,一般还含有演奏乐器的声音,要在混合乐器和人声的音乐片段中判断是否含有歌声,虽然对人来说是轻而易举的,但对机器来说却是颇具挑战性的工作.歌声检测是音乐信息检索(Music Information Retrieval,MIR)领域重要的基础性工作,很多其他研究比如歌手识别、歌声分离、歌词对齐等都把歌声检测作为事前必备技术或者增强技术.例如,在歌手识别过程中,首先对音乐进行歌声检测就是事前必备技术,只有检测到歌声后才能通过歌手鉴别过程进行歌手识别;在歌词对齐过程中,如果能准确地检测出歌声的位置,那么必然增强歌词对齐的准确性.
歌声检测的过程一般包括预处理、特征提取、分类和后处理等几部分,其中特征提取和分类是最重要的两大步骤.输入的音频文件一般是物理样本级的,例如wav,mp3等文件.特征提取是从音频信号中提取能表达含有歌声和不含歌声的音频之间区别的鉴别信息.较简单的鉴别信息是短时傅里叶变换后的时频图,常用的特征还包括线性预测系数(Linear Predictive Coefficient,LPC)、感知线性预测系数(Perceptual Linear Predictive Coefficient,PLPC)、过零率(Zero Cross Rate,ZCR)、Mel频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)、动谱特征(Fluctogram)、谱平坦因子(Spectral flatness)、谱收缩因子(Spectral contraction)等.这里的大多数特征都是在时频图基础上提取的.分类过程是采取机器学习等方法对特征信息进行分类,并根据特征分类来检测歌声.主要的分类方法包括基于传统分类器的方法和基于深度神经网络(Deep Neural Network,DNN)的方法,前者包括支持向量机(Support Vector Machine,SVM)、隐马尔可夫模型(Hidden Markov Model,HMM)、随机森林(Random Forest,RF)等;后者包括采用卷积神经网络(Convolutional Neural Network,CNN)[1]和循环神经网络(Recurrent Neural Network,RNN)[2]的方法.
在现有的歌声检测算法中,研究者们总是试图通过精心设计某种特征,然后选择某种分类器进行分类.当单一特征不能满足要求时,则采用组合多种特征[3-4]的方法,可以说歌声检测的发展历史就是研究者们寻找和设计特征的历史.这种特征工程(Feature engineering)存在的弊端是人工设计特征周期长,以及设计的特征适应性不可靠.事实上,DNN不仅可以充当歌声检测框架的分类器作用,还可以通过多层次的学习,对歌声进行多层次的特征提取[5].因此,一方面,采用适当的DNN框架,可以学习到歌声的特征,不需要进行复杂的特征工程;另一方面,DNN框架既可充当特征提取器又可充当分类器,可减少环节,使算法框架更简单.在歌声检测的现有算法框架中,DNN既作为特征提取器又作为分类器的框架并不多,大部分基于DNN框架的处理过程是先进行复杂的特征工程,然后再把特征输入DNN分类器.据我们所知,仅输入简单朴素的特征如对数Mel时频图的工作,只有Schlüter等的CNN方案[1,6].然而在该方案中,CNN的深度有限,仅有14层,我们称之为浅层CNN(Shallower Convolutional Neural Network,SCNN).受限于浅层深度,网络的学习能力有限,从而导致学习到的歌声特征有限.如果在Schlüter等的浅层方案中想进一步通过简单堆叠卷积层来达到提高深度的目的则是无法实现的,因为这会导致梯度问题,使得堆叠的网络无法训练或退化.本文提出一种基于挤压和激励残差网络的歌声检测算法,一方面,残差网络使得网络深度在可以避免梯度问题和退化问题的情况下对深度进行扩展;另一方面,挤压和激励网络可通过学习调整各层特征的重要性,并自动融合这些特征,送入到网络的下一层.
1 相关工作
1.1 残差网络
残差网络(Residual Network,ResNet)来源于图像分类领域,其在很大程度上解决了梯度爆炸和网络退化问题,使得网络可以构建得很深[7].残差网络由残差结构叠加组成,残差结构的一般构造如图1(a)所示.残差网络在原有网络上堆叠身份映射(Identity),且能保持网络的性能不变.它不是直接学习堆叠网络的潜在映射H(x),而是通过增加身份映射后拟合一个残差映射(Residual mapping)F(x)=H(x)-x.残差映射相比潜在映射更容易优化,从而解决了深度增加后导致的梯度问题和网络退化问题.此外,残差结构是无侵入式结构,可以叠加到其他网络中,用以提升网络的深度和性能.
图1(a)中的F(x)可根据需要采取不同的结构.图1(b)和图1(c)是用于构建深度残差卷积神经网络的两种典型的F(x)的结构:基本块(Basic block)和瓶颈块(Bottleneck block)的结构.图1(b)和图1(c)中,n,m分别表示经过1×1或3×3卷积后的特征图数量,也就是通道数量.图1(b)与图1(c)的不同在于后者具有3个卷积层,且中间特征图数量也发生了变化,但二者的输出特征图数量都是相同的.
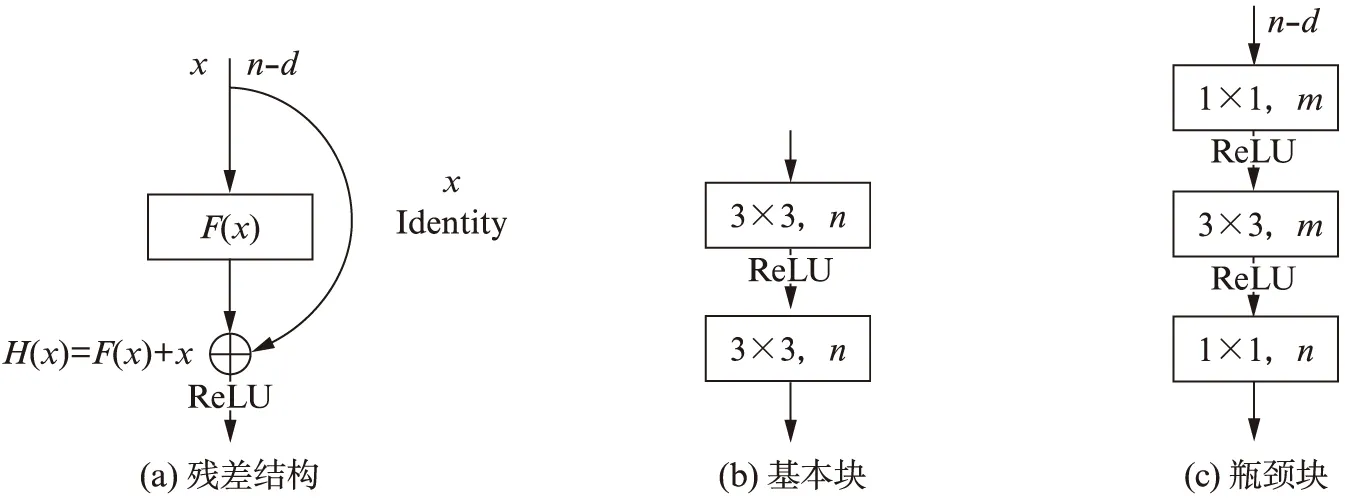
图1 残差结构和两种典型的F(x)块结构Fig.1 Residual structure and the two typical block for F(x)
1.2 挤压和激励操作
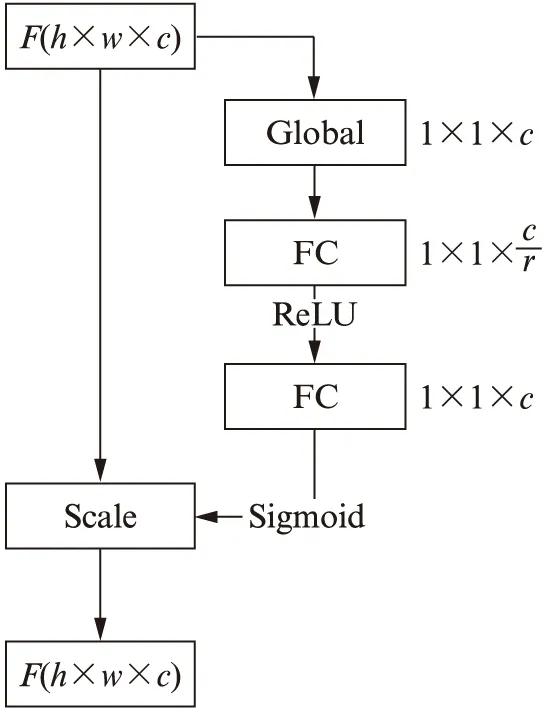
图2 SENet模块图Fig.2 SENet module
挤压和激励网络(Squeeze-and-Excitation Network,SENet)来源于图像分类,在LSVRC 2017(ImageNet Large Scale Visual Recognition Challenge)图像分类竞赛中,基于该技术的网络获得了最好的成绩.SENet的核心是利用挤压和激励操作挖掘卷积神经网络中通道间的关系,并调整通道的权重.SENet模块的结构见图2(见 第362页).假定上一层卷积输出F是高和宽为h和w的图片,通道数量为c,挤压操作是一个全局平局池化层,将c个通道压缩成c个描述符;激励操作的第1步是一个门机制,具体包括第1个全连接层将c个描述符以r倍降维,然后利用ReLU函数进行非线性化,接着是第2个全连接层以r倍增维;激励操作第2步首先利用Sigmoid激活函数对通道进行权重估值,然后通过Scale操作对各通道按权重估值进行调整,最后调整后的通道F′进入下一层网络.挤压和激励操作使得各通道对下一层网络的作用发生变化,权重不再是相等的,而是通过学习得到的.本算法中,将F看成是学习到的特征,该特征先经过权重重估和调整,再送入下一层网络.特征权重重估和调整的过程就是特征自动融合的过程.
2 算法思路
本文基于挤压和激励残差网络的歌声检测算法是通过残差网络构建深度卷积神经网络,深度可到200甚至更深,从而增强对歌声特征的学习能力,产生不同层次的特征;而对于卷积神经网络学习到的不同层次的歌声特征,本算法通过挤压和激励模块来重估其对歌声分类的重要性.本文算法较浅层CNN的方法有两个方面的改进:一方面是在网络深度方面能避免出现退化现象的情况下得到扩展;另一方面是各层次的特征权重得到重估,使得分类效果得到提升.
2.1 网络输入
本算法的网络输入不是经过复杂特征工程处理后的特征,而是歌声检测最常用的、最简单朴素的对数Mel时频图(Log Mel-spectrogram).计算过程中采样率取为22 050 Hz,帧长为1 024,帧移为315,Mel频率数量取80个,频率区间为[27.5,8 000.0](单位Hz).每个音频文件可得到一个行数为80的对数Mel时频图矩阵,我们从该矩阵的起始列位置开始逐个提取大小为80×115的图像,读取图像时每跳为5列,然后将图像输入到网络.
2.2 网络模块
结合挤压和激励操作的深度残差卷积模块(SEResNet)如图3所示.SEResNet模块由SENet模块结合ResNet的基本块和瓶颈块构成.两种模块中,输入通道数量和输出通道数量都是一致的.我们根据网络的深度选择不同模块来构造全栈网络.其中SRB模块用于构造深度为18和34的网络,而SRT模块用来构造更深的网络,包括深度为50,101,152和200的网络.
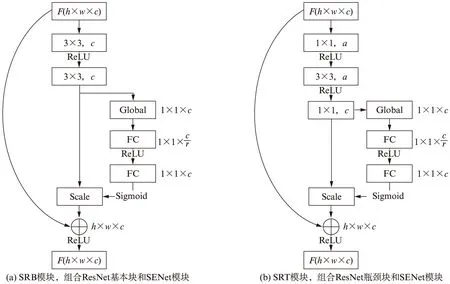
图3 SEResNet模块Fig.3 SEResNet module
2.3 全栈网络

表1 深度为200的SEResNet的全栈网络结构Tab.1 The network structure of the SEResNet with the depth 200
如前所述,全栈网络是根据不同的SEResNet模块来构建的.本文算法设计的SEResNet深度包括18,34,50,101,152和200共6种深度,下面以SEResNet200(深度为200的SEResNet)为例来说明全栈网络的结构,如表1所示.大小为80×115的图像在进入残差网络前,先经过大小为7×7,步数(Stride)为2的卷积层conv1,此时,conv1的输出将缩小为40×58.随后,输出的特征图进入挤压和激励残差结构中.在conv2,先经过大小为3×3,步数为2的最大值池化层,特征图大小再次缩小至20×29,随后,进入挤压和激励残差网络层,经过1个SRT残差块,再经过挤压和激励模块进行特征权重重估,图中fc,[16,256]表示挤压和激励网络结构中第1个和第2个全连接卷积层FC(图2)的输出维数,降维和增维倍数均为16.中括号外的×3表示中括号内挤压和激励残差网络栈的深度为3,即网络堆叠的深度.对应conv3,conv4,conv5的堆叠深度分别为12,48和3,我们称这4个堆叠深度序列为规模参数.在conv3,conv4,conv5中,没有最大值池化层,但是由于它们的结构中存在步数为2的卷积层,因此,图像大小仍然和conv2层一样缩减为一半.在最后的FC层,先经过一个2维的自适应平均池化层,其输出通道数为1,再进入一个全连接卷积层,最终网络输出为1维向量o,含2个值o0,o1,可以用来判断是否含有歌声.
对于深度分别为18,34,50,101和152的网络,其规模参数分别为[2,2,2,2],[3,4,6,3],[3,4,6,3],[3,4,23,3]和[3,8,36,3].输出图片大小和SEResNet200保持一致.值得注意的是,规模参数并不是必须如上所述.事实上,我们通过实验发现规模参数呈递增形,即形如[3,8,16,23]的SEResNet152效果要更好,但是本文的重点在于“深度”和“特征的权重重估”,因此对于SERenet中各深度网络的具体组织形式没有进行研究.
2.4 加权交叉熵损失函数
由于歌声检测是二分类,所以本算法采用的是二分类交叉熵损失函数.歌声检测的数据集中歌声和非歌声的样本数一般是不平衡的,通常是歌声样本数要多于非歌声样本数,因此,我们在损失函数中加入了权重,权重设为数据集中的样本数量比例.上述挤压和激励残差网络的输出是2个值o0,o1,先用sigmoid函数转换成概率值,再加入到下述损失函数中进行计算.设N个样本预测为歌声的概率为xi,样本的标签为yi,权重为wi,其中i∈[1,N],则加权交叉熵损失函数为
(1)
这里的对数函数的底可以为2,e,10.
3 实验和结果
3.1 数据集和基线系统
我们选择公开音乐数据集RWC(Real Word Computing)中的流行歌曲[8]和公开数据集Jamendo[9](简称JMD)作为实验数据集.RWC包含100首流行歌曲,时长共407 min.我们把RWC分成训练、验证和测试3个数据集,划分方式是将数据集文件结尾为0—4的文件划为训练集,将结尾为5和6的文件划为验证集,将结尾为7—9的文件划为测试集,这种划分是准随机的方法,以保证实验结果的公正性.JMD包含93首歌曲,时长共371 min.我们保持JMD的训练、验证和测试集不变[10].RWC和JMD的歌声和非歌声的样本数量比分别为1.12和1.55.
我们选择文献[10]中的系统作为比较的基线系统,该文献实现了目前国际上最先进的歌声检测算法,包括基于SCNN的模型,并公开了代码,可以认为是一个第三方的评估系统.该SCNN包含4个卷积层和3个全连接层,是目前获得检测准确率最高的框架之一,网络输入正是对数Mel时频图.我们将直接引用并比较该文献提供的JMD数据集上的实验结果.对于RWC,我们运行该系统的代码产生实验结果.本算法采用Pytorch,并借助Homura包(https:∥github.com/moskomule/homura.)进行开发和实现.对于JMD数据集,SCNN有最高准确率为93.2%的报告[4],但因该系统实施了特征工程和数据增强,且没有提供实现细节,故没有作为基线系统.
3.2 结果比较
为了公正比较,在实验中我们没有通过调参选取最好的结果来进行比较,而是保持除深度之外所有的参数不变.我们这里选取不同深度的挤压和激励残差网络进行实验是为了研究深度对检测结果的影响.由于在歌声检测中,我们推荐深度在50以上的网络,因此,我们取深度为50,101,152和200的统计数据作为比较的数据,结果见表2.
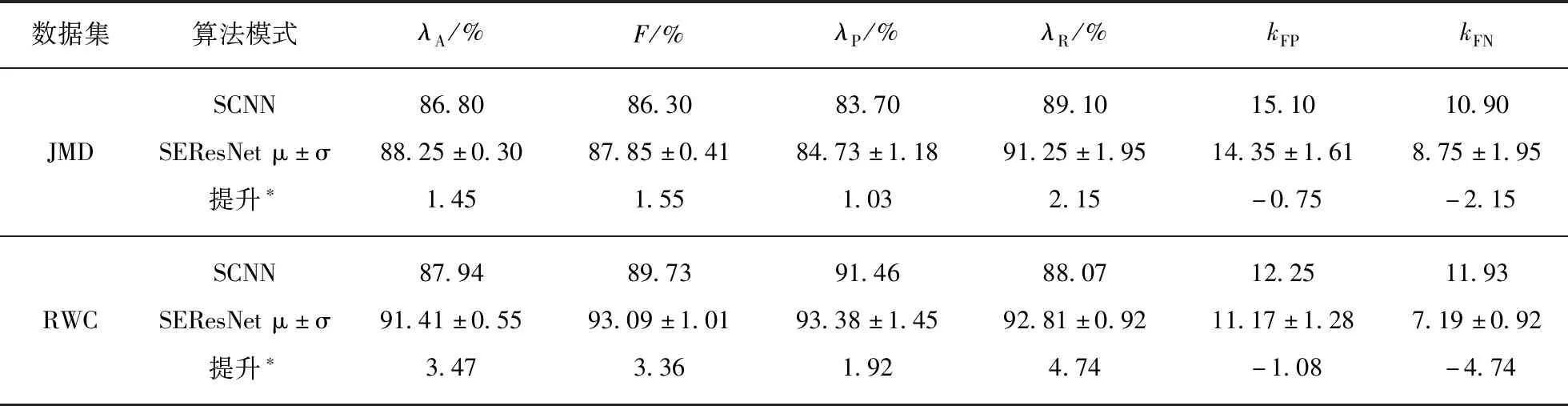
表2 本文算法和SCNN在JMD和RWC下的结果比较Tab.2 Comparison between the proposed algorithm and the SCNN on JMD and RWC
从表2中可看出,本算法所有指标均有不同程度的提升,这说明相对于SCNN,本文算法的“深度”和“特征权重重估”的有效性.在JMD和RWC上,本文算法的准确率(Accuracy)λA均值分别较SCNN的有所提升.F值(F-measure)是精确率(Precision)λP和召回率(Recall)λR的综合,本文算法的F值也较SCNN的有所提升.假负例(FN)数量kFN在JMD和RWC上都降低最多,这带来了召回率提升最多的效果.
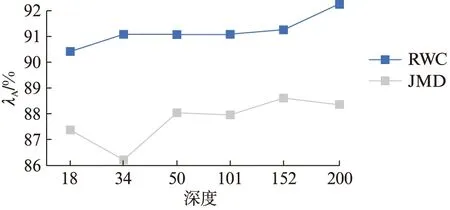
图4 不同深度的SEResNet检测准确率的变化情况Fig.4 The accuracies of SEResNets change at the different depths
3.3 不同深度对结果的影响
由于数据集的特征分布和数据集大小不一样,不同深度的SEResnet表现也不一样.图4是在JMD和RWC上不同深度的准确率的变化情况.RWC上的准确率随着深度的增加有一个显著的上升趋势,而JMD上的则曲折上升,二者的最高准确率均落在深度较大的网络上,这告诉我们在应用SEResNet时应首先考虑深度较大的网络.需要说明的是为全面评估深度的影响,图中增加了深度为18和34的数据.
4 结 语
本文提出了一种基于挤压和激励残差网络的歌声检测算法,残差结构使得网络的深度可以扩张至200层甚至更多,挤压和激励嵌入在残差结构中,可对网络各层次学习到的特征进行权重重估,从而弱化对歌声检测权重小的特征,而强化权重大的特征.通过实验证实,本算法的准确率等指标相对SCNN均有提升.进一步地,通过对深度为18,34,50,101,152,200的挤压和激励残差网络进行实验,检测算法的最佳性能均体现在较大的深度上,这说明在实际中应用本算法时,应该重视较大深度的网络.值得注意的是,本算法和其他基于深度学习的算法一样,在一定程度上依赖于训练数据集的构造,其泛化效果有待验证.比如本算法的训练数据主要是含有歌声和乐器的混合音乐,而其模型是否适用于说唱类型的音乐尚需进一步研究.提升模型泛化性能的一种解决方案是在训练数据集中加入目标检测类型的音乐,使得模型能学习到该类型音乐中歌声的特征.
致谢:感谢南京邮电大学宽带无线通信与传感网技术教育部重点实验室开放研究基金资助;感谢金陵科技学院和澳大利亚昆士兰科技大学中外合作办学高水平示范性建设工程资助;感谢江苏省教育厅高校优秀中青年教师和校长境外研修项目资助.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
成都信息工程大学学报(2022年2期)2022-06-14
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
