
基于手写-印刷混合字符的口算题识别
2021-11-20 01:57纪睿哲程艳云
计算机工程与设计 2021年11期
纪睿哲,程艳云
(南京邮电大学 自动化学院 人工智能学院,江苏 南京 210042)
0 引 言
近年来随着技术的发展,出现了一种通过上传图片从而自动批阅小学生口算题的应用程序。数学表达式识别(RME),作为与该自动批阅系统密切相关的领域已被研究数十年[1,2]。
随着编码器-解码器模型的提出,并派生出一种利用CNN对图片进行特征提取并进行整体识别的方法,被广泛引用于手写识别领域[3,4],并在RME领域中发挥重要作用。RME可以分为印刷体数学表达式(PME)识别和手写数学表达式(HME)识别。相对而言,HME更具难度与挑战性。编码器-解码器模型在此依然发挥巨大作用,有学者尝试将CRNN[5]引入HME领域并取得了较好的效果。随着Attention[6]模型的提出,Zhang等[7]将其引入编码器-解码器模型并提出WAP模型,在HME领域获得极佳的效果。此后,为解决普通CNN对特征提取不足的问题,通过引入Densenet[8]以增强WAP模型的性能[9]。同时,在HME领域中也存在其它方案[10]。
由于小学生口算题同时存在手写体和印刷体字符,而过往的研究大都集中在单一字符,且未考虑到手写字符存在大量不规范的情况。本文利用编码器-解码器模型对口算题进行整体识别,并提出了一种多分支改进的Densenet进行特征提取以适应多变的字符。本文亦对联合CTC-Attention模型进行多分支改进。同时,文中还提出一种生成口算题样本的方法以解决真实样本存在的数量不足、分布不均的问题。
1 系统概述
本文提出的改进后的编码器-解码器模型以Densenet网络和联合CTC-Attention模型为基础,通过LSTM编码器-解码器框架组成。主要流程是首先通过Densenet网络对输入的图像特征进行提取,将提取出的特征交由基于联合CTC-Attention模型的LSTM编码器-解码器模型进行编解码,以得到对应的LaTeX格式输出。
由于本文拟对同时拥有印刷体字符和手写体字符的口算题进行整体识别,且小学生的手写体字符之间差异较大且可能存在不规范的情况。在这种情况下,采用传统的单分支CNN网络对其进行特征提取所得到的特征可能不足以适应这种复杂情况。本文受到FPN(feature pyramid networks)[11]网络的启发,拟对Densenet网络做多分支结构的改进以尽可能多提取出字符的多种特征。如图1所示。

图1 Densenet网络的结构
与此同时,由于多分支结构的改进,Densenet将会拥有3个不同尺寸的特征。为充分对这些特征进行解析,本文引入了联合CTC-Attention模型,其在被Zuo等[12]引入自然场景下的文本识别,取得了极佳的效果。文本亦将针对该模型中的CTC部分与Attention部分的特性做不同的调整,使其可以充分利用多分支网络的输出,如图2所示。对于CTC部分拟采用FPN网络所提出的方法做上采样并进行横向连接的方法,而对于Attention部分,本文则针对多尺度特征做相关改进。
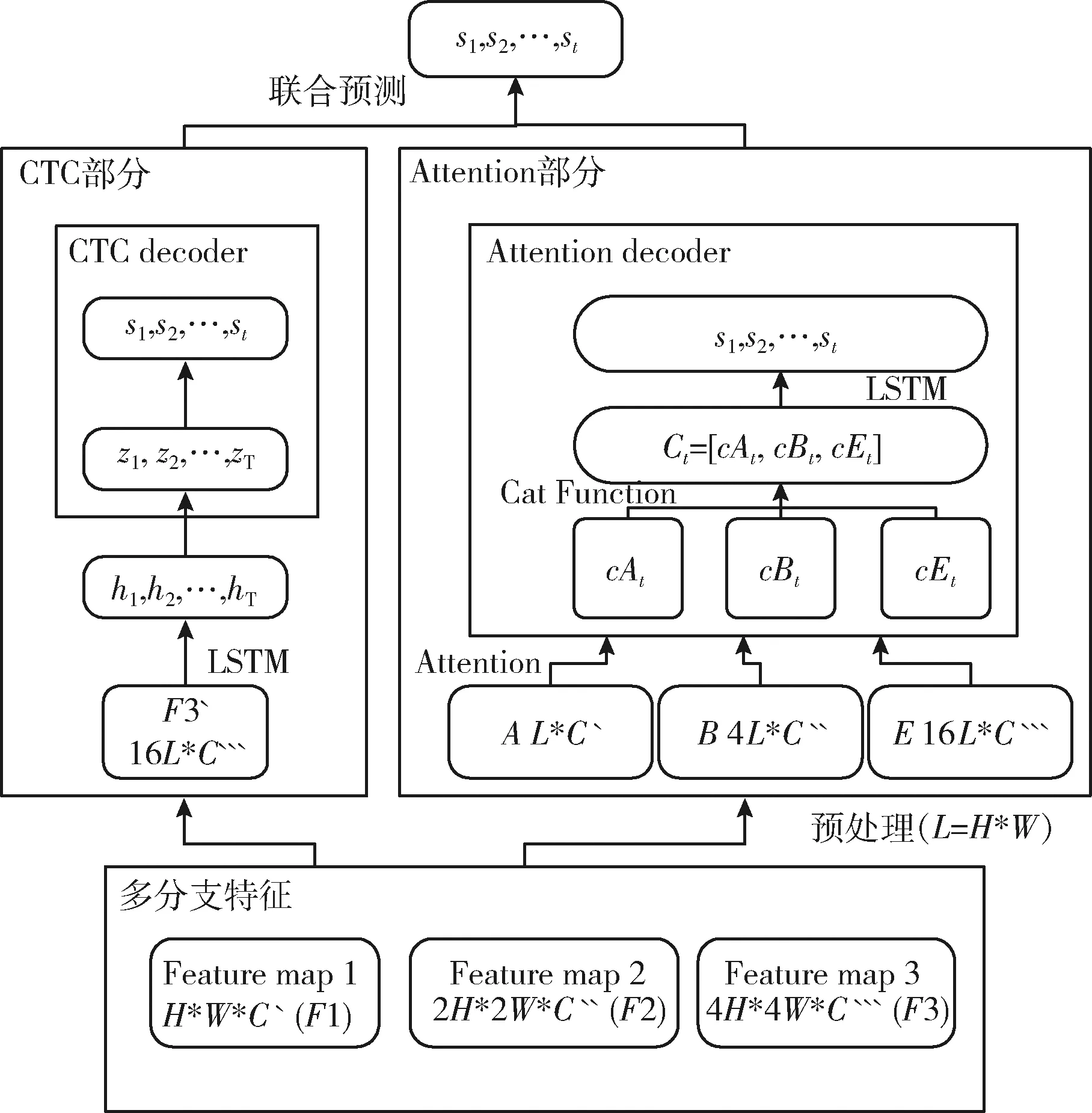
图2 基于联合CTC-Attention模型的LSTM网络结构
1.1 Densenet网络的多分支改进
本方法拟选用具有3个Dense Block的Densenet网络作为基本架构。在该网络结构中,所有网络层都是直接相互连接的,每一层的输入均由在此之前所有层的特征图中接收。此外,每个输出将被传递到每个后续层,以最大程度的确保每层之间的信息传输网络。例如,lth层的输出xl计算如下
xl=Hl([x0;x1;…;xl-1])
(1)

由于考虑到需要同时对小学生口算题中的手写体字符和印刷体字符进行整体识别,且小学生的手写体字符可能会存在差异较大且不规范的情况。相对于普通Densenet网络仅拥有的一个高维输出而言,低维特征与之相比则具有更多的位置信息,受到FPN网络的启发,本文拟将高维特征与低维特征结合可以更有助于解析输入的图像。此改进主要是在传统Densenet结构的每个平均池化层之前扩展一个分支以输出当前特征,从而使其输出可以尽可能涵盖高维特征和低维特征。通过上述的多分支结构,编码器将输出3种不同的分辨率特征,如图1所示。
1.2 联合CTC-Attention模型的多分支改进
1.2.1 CTC模型的多分支改进
CTC模型的特点在于假定所有标签彼此之间独立,并采用贝叶斯定理计算预测序列的后验概率分布,如下式所示
(2)
此式中的p(zt|X)表示从已知输入特征所获得的隐藏变量的概率, 而p(zt|zt-1,S)则为依据前一时刻隐藏变量输出所预测的隐藏变量的条件概率。
对于联合模型中的CTC部分,本拟对多尺度Densenet所得到的3个特征做FPN网络的相同操作,即针对F1做4x upsample得到F1′,对F2做2x upsample得到F2′,使得F1′,F2′和F3拥有相同的尺寸,再对F1′,F2′和F3做横向连接以获得特征F3′。
其次,还需要对F3′做一定的预处理以使其适应LSTM网络的输入格式。以F3′为例,其为一个尺寸为4H*4W*C` ` `的三维数组,本文需要将其转换成一个尺寸为16L*C` ` `的二维数组。其中,16L=4H*4W,fi则代表了C` ` `维向量。如式(3)所示
F3′={f1,f2,f3,…,f16L},fi∈RC ` ` `
(3)
随后,将预处理后的F3′输入LSTM编码器进行编码,再将其结果导入CTC模型进行解码。
1.2.2 Attention模型的多分支改进
考虑到Attention部分在联合CTC-Attention模型中对识别所起到的作用相对较高,即针对Attention模型进行更进一步的多尺度改进显得尤为重要。直接将通过上采样并横向连接后的特征交由普通Attention模型进行处理未必能充分发挥出多分支Densenet模型所提取到的多分支特征的优势。为此,本文针对多分支Densenet模型提出一种Attention模型的多分支改进。除多尺度改进外,本方法亦将Coverage vector引入Attention模型中,以避免对已分析内容的重复关注。
该改进后的模型需要将多分支Densenet模型所提取出的特征F1,F2和F3直接分别输入LSTM网络进行编码。此处亦需要对其进行预处理操作,使其变为对应的二维数组,并依次命名为A,B和E。

(4)
在此式中,yt-1代表先前输入的值,而st-1也是一个初始化参数。
接下来需要计算的是coverage值Covt,ai在步骤t条件下的能量eti以及Attention概率αti,可以通过以下公式计算
(5)
(6)
(7)
此处的αl代表了此前已获得的Attention概率,Q是随网络训练而更新的随机初始化矩阵。eti主要取决于ai,其亦与网络的先前隐藏状态的值ht-1以及Covt的第ith个向量Cti有关。αti则由eti与t步骤的全部能量计算得到。
最终,cAt可通过先前得到的ai与αti计算得到,如式(8)所示
(8)
但由于编码器采用了多分支架构,因此将得到3个不同的输出。本方法拟分别获得其结果,并使之连接在一起,命名为ct。最终,该ct将被交由LSTM解码器来得到状态st,如下式所示
ct=[cAt;cBt;cEt]
(9)
(10)

1.2.3 联合预测
联合CTC-Attention解码方法主要利用了初始阶段CTC的对齐更加准确的特点,以避免Attention模型在解码时由噪声引起的位错问题。为实现联合预测,本方法拟设置CTC模型与Attention模型联合预测的最大化联合概率为
(11)
此处的λ是一个取值区间为0≤λ≤1的可变参数,本文将在后续实验部分对λ的取值做深入分析。
2 数据集及训练
2.1 数据集
由于目前难以找到相关开源数据集,因此文中提出收集私有数据集以用于模型的训练与测试。该数据集包含从合作小学收集的真实样本以及通过本文所提出的样本生成方法所得到的一些生成样本。
2.1.1 真实样本
真实样本主要来自于合作小学收集的各类数学试卷。对收集得到的真实试卷进行了手工剪切与标记即可以得到真实样本。但是,此类样本却存在数量少与相似度高的问题。相似度高的问题是由相同底卷将被派发给不同学生,导致相同问题的打印体部分几乎相同造成的。对于此类样本,本方法拟控制相同底卷的出现次数和同一学生的出现次数。最终,获得了11 980个真实样本,在这些样本中将随机抽取出80%的样本进行训练,其余样本则进行测试。
由于小学生的手写字体可能存在不规范的问题,在某些情况下的真实样本字符可能会出现粘连或交叠的情况。此外,过于接近的无关相邻字符亦可能导致裁剪过后的样本中出现噪音,如图3所示。本方法并未删除此类有问题的样本,而是将其添加到训练样本及测试样本中一同训练。

图3 真实样本的一部分
2.1.2 生成样本
为了解决真实样本存在的数量少与相似度高的问题,本方法提出了一种样本生成方法。其首先需要收集打印体字符和手写体字符,为了确保打印体字符符合实际录入情况,拟将所需的字符打印在纸张上后,执行扫描与切割操作后再录入,并从不同的打印字体中收集字符。同时,对手写字符亦有一些限制,如:避免收集随机抽选的作为测试样本的口算题中出现的手写字体。
该生成方法首先根据口算题的格式生成其运算部分,并将其细分为数字部分,运算符部分与等号部分。对于数字部分,该方法拟生成一个满足指定需求的随机数,具体体现为:随机数为浮点数形式还是整数形式,以及是否会导致过分复杂的运算等。运算符部分则交由随机函数在常见运算符中随机选择。最终将等号添加到已生成的内容中,即可获得运算部分的内容。
其次,由先前生成的运算部分内容可以轻松计算出其相应答案部分。对于最终生成的样本,为尽可能模拟真实情况,该方法将在生成答案部分时适当旋转并缩放相关手写字符。此外,该方法亦使用相关算法实现部分手写字符之间的粘连和交叠情况,如图4所示。

图4 生成样本的一部分
2.2 训 练
为最大化符号预测的概率,该模型选用交叉熵作为目标函数
L=λLCTC+(1-λ)LAtt
(12)
此公式中LCTC表示为CTC模型的损失函数,LAtt表示为Attention模型的损失函数,λ则为一个取值为0≤λ≤1的可变参数,用于表示该联合模型中CTC模型和Attention模型的权重。
该模型应用了较小的学习率,并将其初始化置为0.0001,以便于模型的训练。在优化过程中,该模型选用自适应学习率,即可以依据学习结果自动更新学习率。基于内存容量,利用率与收敛速度的考虑,该模型将batch size设置为18。相关工作[13]的实验数据表明,设置LSTM的hidden units数为256可以取得更好的结果。
对于训练完成的模型,本方法将使用WER Loss来衡量其性能并保存性能最佳的模型作为最终模型。与此同时,本方法亦选用数学领域中常用的LaTeX格式作为输出格式。
3 实 验
3.1 有效性
本文拟使用单词错误率(word error rate,WER)作为评估标准。该评估标准是通过计算预测序列校正为标准顺序所需的字符替换,删除或插入操作的数量总数除以标准序列总字符数而获得的百分比,计算公式如下
(13)
此处,S为替换的字符个数,D为删除的字符个数,I为插入的字符个数,而N则为标签字符的总个数。
3.2 结果及分析
对比实验首先验证了λ在不同取值情况下训练的模型性能。由于λ是一个从0到1的可变参数,这意味着当λ取值为0时,模型将仅使用多分支改进后的Attention模型。反之,在λ取值为1时,模型将仅采用CTC模型。同时,当λ取值为浮点数时,意味着CTC和Attention在联合模型中以不同权重相互作用。本实验将选用6个不同的λ值分别为:0.2、0.4、0.6、0.8、0和1进行对比实验。
接下来,为了验证模型多分支改进的有效性,本方法比较了编码器部分为传统Densenet网络的单分支CTC模型和单分Attention模型的性能。此外,本方法拟将λ取值为0.2的传统联合CTC-Attention模型引入对比实验,相关文献验证在该模型中此λ值较其它λ值拥有更佳的效果。最终,考虑到本文提出的训练样本生成方法,亦对比了仅由真实样本训练的模型与增加了生成样本训练的模型的性能,以验证此生成方法的有效性。
从表1与表2中可以发现,无论在训练过程中是否追加生成的样本,在较低λ值的条件下,文本所提出的多分支联合模型的性能均优于单一CTC模型与单一Attention模型。此外,亦可以关注到当λ取值为0.2时,模型可以获得更好的性能。这是因为联合CTC-Attention模型采用CTC对Attention进行空间约束,进而降低了Attention模型存在的偏移问题,提高了识别率。与此同时,对比表1与表2亦可以注意到,无论采用何种模型,追加生成样本所训练的模型性能均优于直接采用真实样本训练的模型性能,这也验证了样本生成方法的有效性。显然,多分支结构无论是对于CTC模型、Attention模型或是联合CTC-Attention模型,都拥有比单分支结构更好的性能。

表1 不同模型在真实样本训练条件下的WER Loss

表2 不同模型在生成样本训练条件下的WER Loss
在接下来的部分中,本文还设置了一组新的对比实验以评估不同模型的收敛速度。在该实验中,训练集均采用已追加生成样本的训练集。训练过程中将每隔指定批次,通过真实样本测试集测试并输出其精度。对于联合CTC-Attention模型选择了WER Loss较低的λ取值为0.2的模型,并将其收敛速度与一些目前较为先进的模型以及λ取值为0和1的模型进行比较,结果如图5所示。
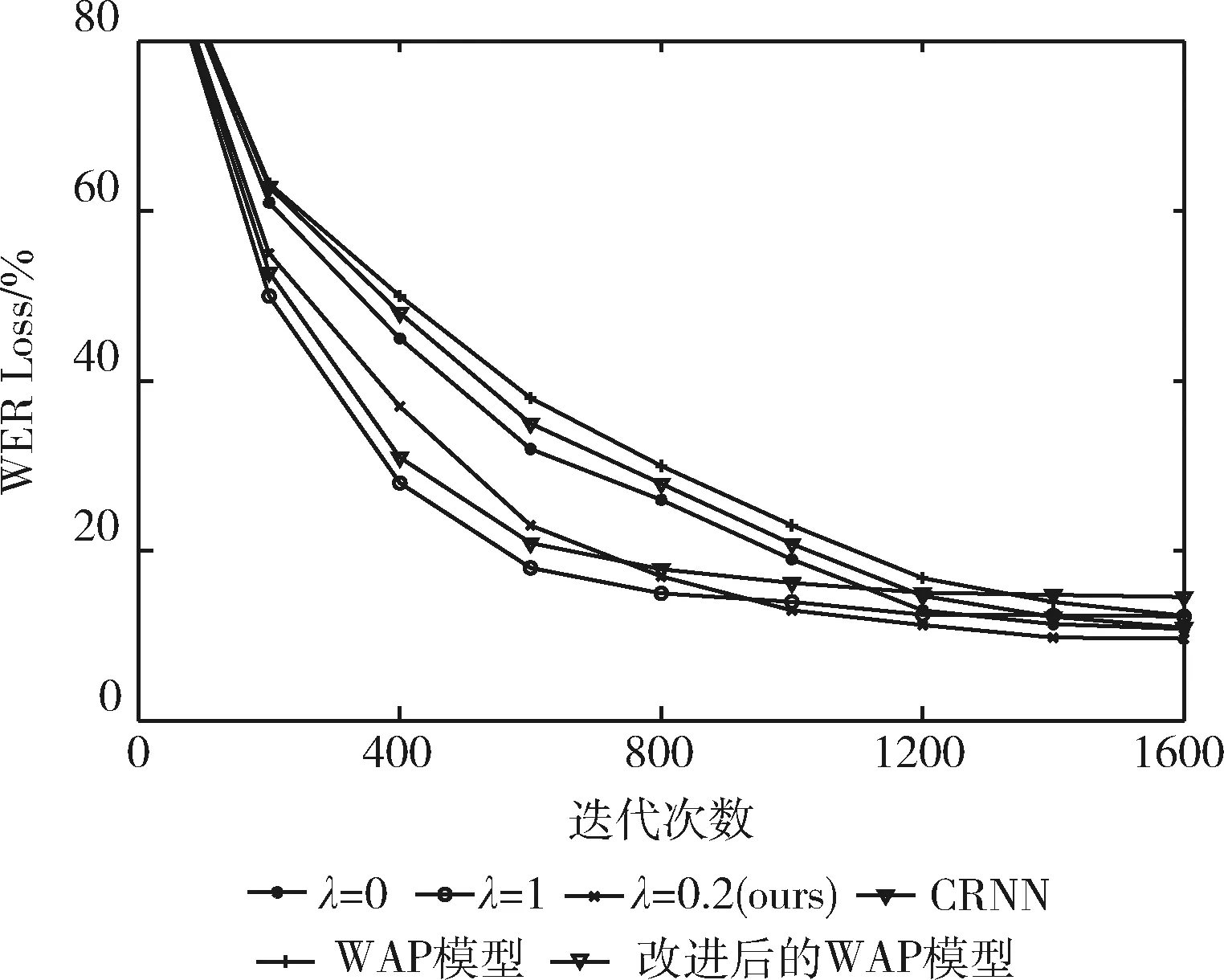
图5 不同模型的收敛速度
从图5中可以看出,本文所提出的模型在λ取值为0.2的情况下收敛速度以及准确度亦优于常见的一些模型。尽管λ取值为1的模型(多尺度改进后的CTC模型)在训练过程中收敛速度更快,但其准确性不如λ取值为0的模型(多尺度改进后的Attention模型)。相反,在收敛的前提下,λ取值为0的模型的准确度优于λ取值为1模型,但其在训练过程中存在收敛速度慢的问题。因此,引入联合CTC-Attention模型可以在确保识别性能的同时提高Attention模型的收敛速度,达到平衡收敛速度和准确性的效果。
4 结束语
为解决小学生口算题中存在的问题以提高识别率。本文以基于Densenet网络与基于联合CTC-Attention模型的LSTM编码器-解码器结构作为基础提出一些改进。该模型相比既有模型拥有更强的特征提取能力,以适应字符复杂多变的情况。主要是针对传统Densenet网络做了多分支改进,并对CTC模型与Attention模型进行改进,使联合模型可以充分利用多分支结构以提升识别效果,最终结果将以LaTeX格式输出。为解决真实样本数量少与相似度高的问题,本文提出一种样本生成方法。最终,在这些因素的共同作用下,通过实验验证了该方法具有优越的性能。
猜你喜欢
小学生学习指导(低年级)(2021年12期)2021-12-31
数学小灵通·3-4年级(2020年12期)2021-01-14
数学小灵通(1-2年级)(2020年4期)2020-12-30
小学生学习指导(低年级)(2020年11期)2020-12-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
成都信息工程大学学报(2018年3期)2018-08-29
制造技术与机床(2017年7期)2018-01-19
