
基于自然语言处理的监管文本知识图谱构建
2021-12-31 03:24高赫
中国科技纵横 2021年21期
高赫
(北京金融安全产业园,北京 100005)
近年来,互联网与金融不断融合,大数据和云计算等信息技术使传统金融业务得以重塑,推动类金融机构和新金融业态快速发展,但也衍生出一定风险,对金融监管提出新的挑战。通过调整监管方式、明确监管职能,一系列监管法规陆续出台,力求维护金融体系健康有序发展。
就网络借贷行业而言,目前已形成“3+1”架构的监管体系(“1”即《网络借贷信息中介机构业务活动管理暂行办法》;“3”即《网络借贷信息中介备案登记管理指引》《网络借贷资金存管业务指引》和《网络借贷信息中介机构信息披露指引》)。为便利上述监管体系落地,作者所在机构与北京市相关监管部门合作,基于相关监管文本,采用NLP技术构建知识图谱,实现文本内容的逻辑化,为相关金融业务的合规检查提供支撑。
1.工作目标设定及技术方案选择
监管文本逻辑化的核心技术方案为条件随机场(Conditional Random Fields,CRF)以及深度学习方法的结合。
1.1 监管文本实体抽取
实体抽取主要涉及从文本中抽取出特定实体信息。目前较成熟的方法主要包括基于规则、基于统计及基于深度学习3种。
1.1.1 基于规则的方法
基于相关领域专家提供专业知识,人工构造抽取规则,再将之与文本字符匹配,以识别实体。其优点在于算法实现简单;缺点在于随数据集增大,人工成本增加,且规则可移植性差,不同领域的应用效果悬殊。
1.1.2 基于统计模型的方法
基于经人工标注语料训练模型,常见模型包括隐马尔可夫(Hidden Markov Model,HMM)、最大熵(Maximum Entropy,ME)和条件随机场(CRF)。将实体抽取转化为序列标注,预测标签序列以达到抽取目的,性能明显优于基于规则的方法。
1.1.3 基于深度学习的方法
以词向量作为输入,借助神经网络完成端到端实体抽取。常见模型包括:卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)及包含注意力机制(Attention Mechanism)的神经网络。
单向长短期记忆神经网络(Long Short-term Memory Networks,LSTM)模型[1]基于RNN优化,结合词向量特征进行实体抽取。双向LSTM(Bi-directional Long Shortterm Memory,BiLSTM)模型[2],则通过顺逆序计算增强语义信息理解力,并结合CRF模型抽取实体,进一步提升准确率。
综合上述方法优势,本研究选择基于已有的标注数据集和规则模板,并采用BiLSTM-CRF模型实现。
1.2 监管文本实体关系抽取
实体关系抽取本质是对抽取出的实体及各实体间关系的可能分类进行预测。与实体抽取类似,主流方法同样是基于规则、基于统计机器学习及基于深度学习3种。
1.2.1 基于规则的方法
深入分析数据后,由专家人工设定规则,尽可能覆盖全部领域。该方法同样有明显局限性,只适用特定领域,移植困难。
1.2.2 基于统计机器学习的方法
此类方法主要有2种:即基于特征向量和基于核函数。前者缺点在于可移植性差,而特征选择也对模型效果影响显著;后者的劣势则在于计算复杂度高、模型训练耗时长,效果也取决于所选特征。
1.2.3 基于深度学习的方法
该方法优势在于可自主发现隐含语义特征,且抽取精度高。基于RNN 的实体关系抽取[3],输入变量为向量和矩阵,以掌握词义及其相互关系;缺点在于需学习的参数较多。基于CNN的实体关系抽取[4],预先将词转为输入向量进行关系分类。Nian Yang等人于2019年提出SDP-BGRU模型[5],从非结构化数据中抽取企业(实体)关系,转化为分类问题处理。模型使用两实体之间最短依赖路径(SDP),通过双向门控循环单元网络(BiGRU)获取特征向量,采用支持向量机作为分类器。实验表明,模型在测试数据集上效果良好。
鉴于监管文本部分抽象关系无法直接提取,决定采用基于BERT的双向门控循环神经网络模型结合注意力机制(BERT-Att-BiGRU)来训练关系抽取模型,输出形如“实体I~关系~实体 II ”的关系组合。
1.3 监管文本知识图谱构建
语义网络(Semantic Network)本质是一种有向图:顶点代表概念,而边表示概念间语义关系,并由此发展出多种优秀语义知识图谱。
常见构建方法包括:基于专家知识、基于众包数据及基于机器学习。
1.3.1 基于专家知识
Cyc和Wordnet等通过语言学家人工构建语义关系,具有结果准确度高的优点,但构建速度也因此受制约,只能适用小规模数据集。
1.3.2 基于众包数据
ConceptNet、Yago、Wikidata、DBpedia等英文知识图谱为此类代表。由大量志愿者共同合作构建,成本低,速度快;但个体认知差异决定了图谱质量无法保证。
1.3.3 基于机器学习
构建方法主要基于从海量数据中获得RDF三元组,适用于处理主、客观世界中数量庞大的概念和实体,以及实体和概念间的复杂关系[6]。
在完成实体和实体关系抽取后,本研究将获得的结果在图数据库中保存,并支持查询操作及内容展示。
2.监管文本实体抽取
本项工作的主要任务是提取文本中行为主体名、金融产品名等要素。首先利用规则模板抽取出文本首尾的半结构化信息,对正文的复杂逻辑则采用BiLSTM-CRF模型,结构如图1所示。
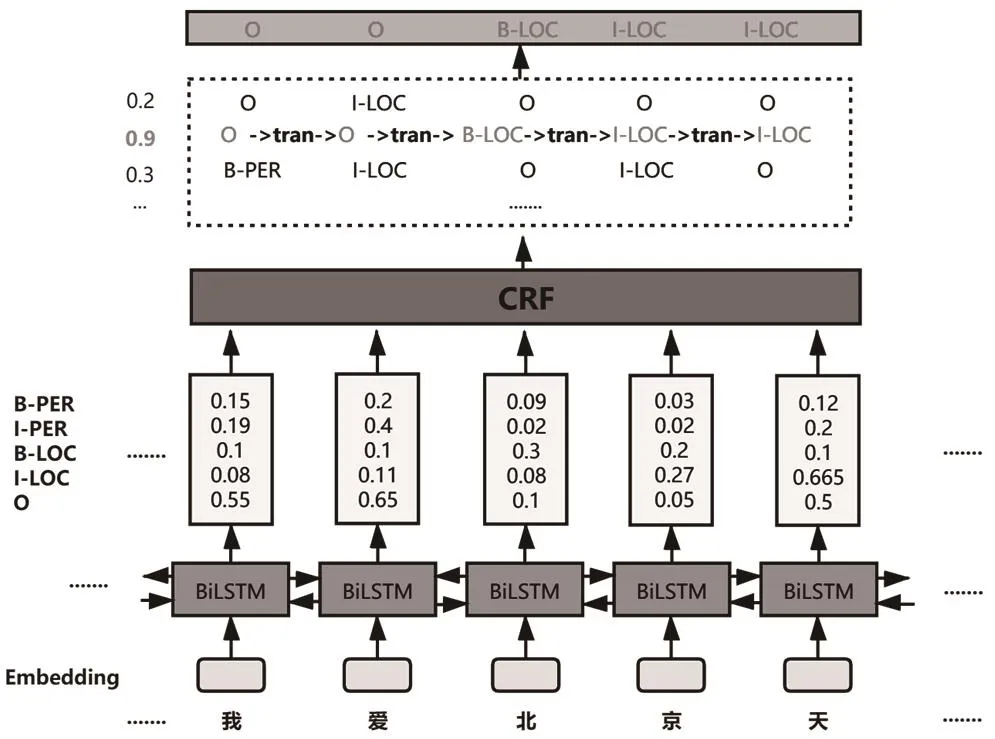
图1 BiLSTM-CRF模型
基于1998年人民日报标注数据、MSRA微软亚洲研究院、玻森等数据集,采用Pytorch的BiLSTM_CRF模型训练,结果如表1所示。
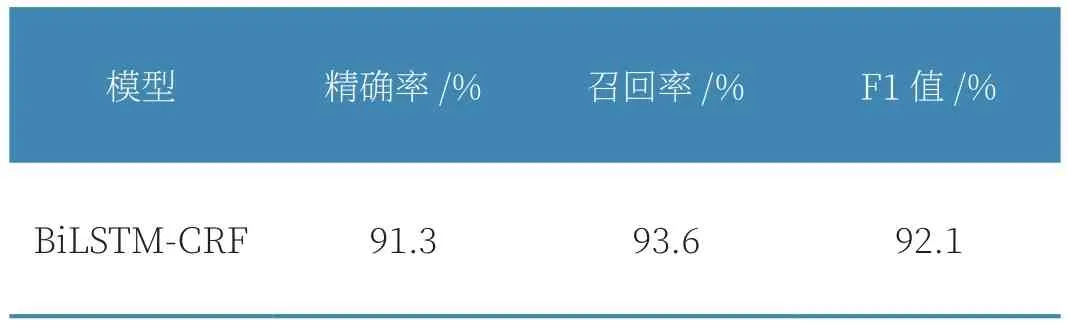
表1 BiLSTM-CRF模型测试结果
该模型既可减少工作量,又较好地完成实体抽取任务,为后续实体关系抽取任务打下良好基础。
3.监管文本实体关系抽取
本项工作的主要任务是对抽取出的各实体间的关系进行预测,本节针对法律文书中正文的实体关系抽取任务,使用 BERT-Att-BiGRU模型,以一段文本及2个实体作为输入,输出实体间关系。模型结构如图2所示。
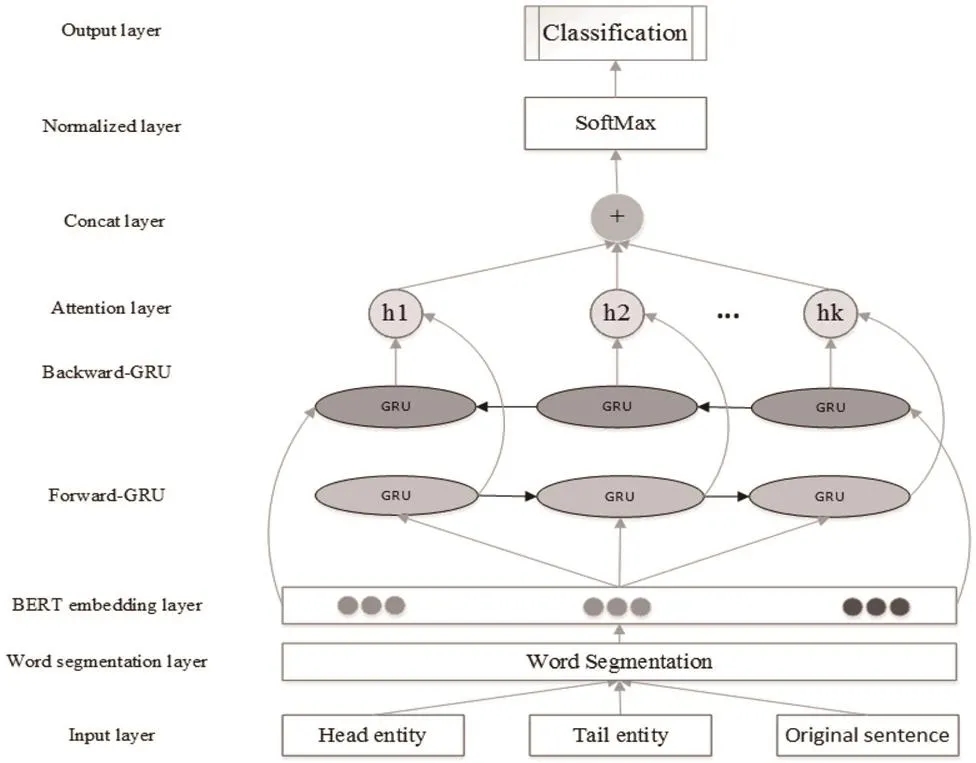
图2 BERT-Att-BiGRU模型
模型融合BERT、双向门控循环单元以及注意力机制,对经人工标注的2000条监管规定进行训练,结果如表2所示。
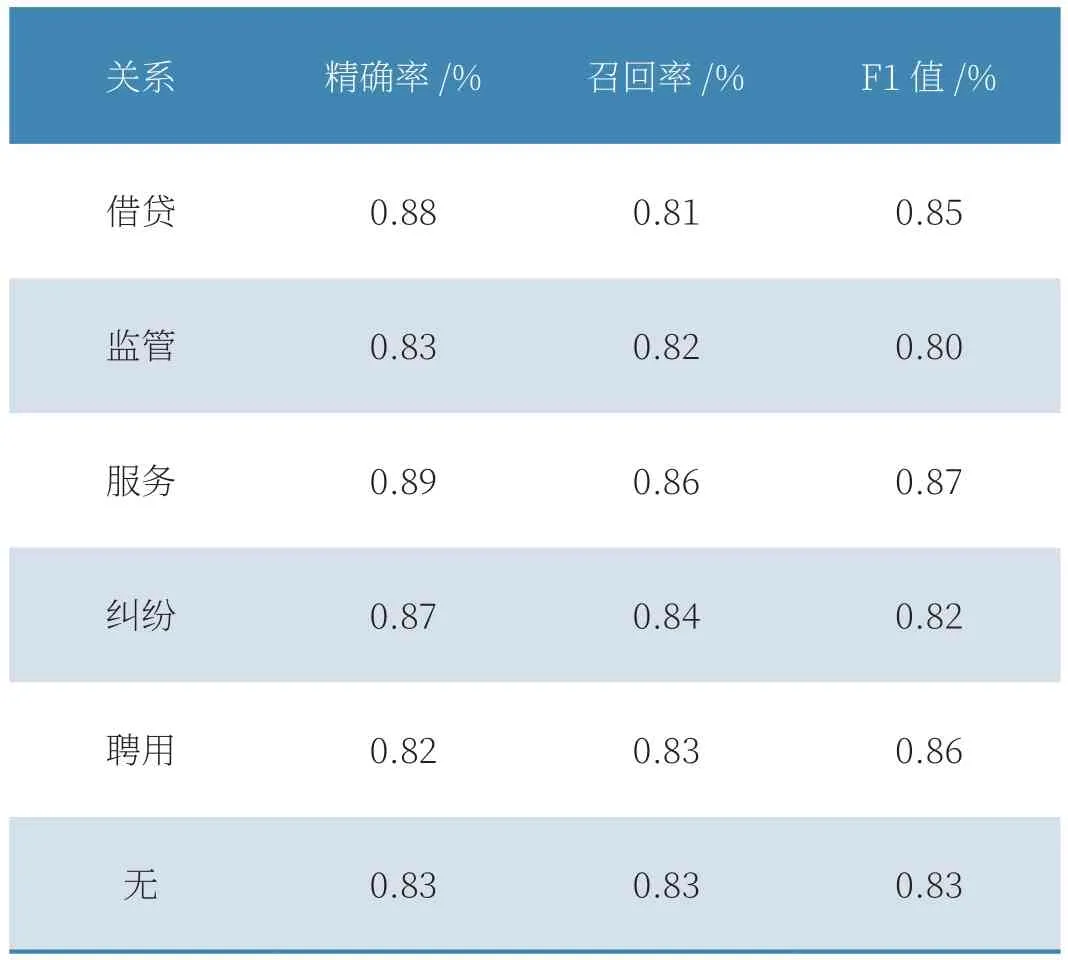
表2 BERT-Att-BiGRU模型测试结果
实验结果证明该模型准确率可达80%以上,能够有效提取关系三元组,为构建复杂知识图谱系统提供了便利。
4.监管文本知识图谱构建
将前两步从监管文本中提取出的实体及实体关系三元组存储至Neo4j图数据库(如图3所示),共抽取43项合规风险指标、21项管理风险指标(如表3所示),实现对网贷业务的合规监测。
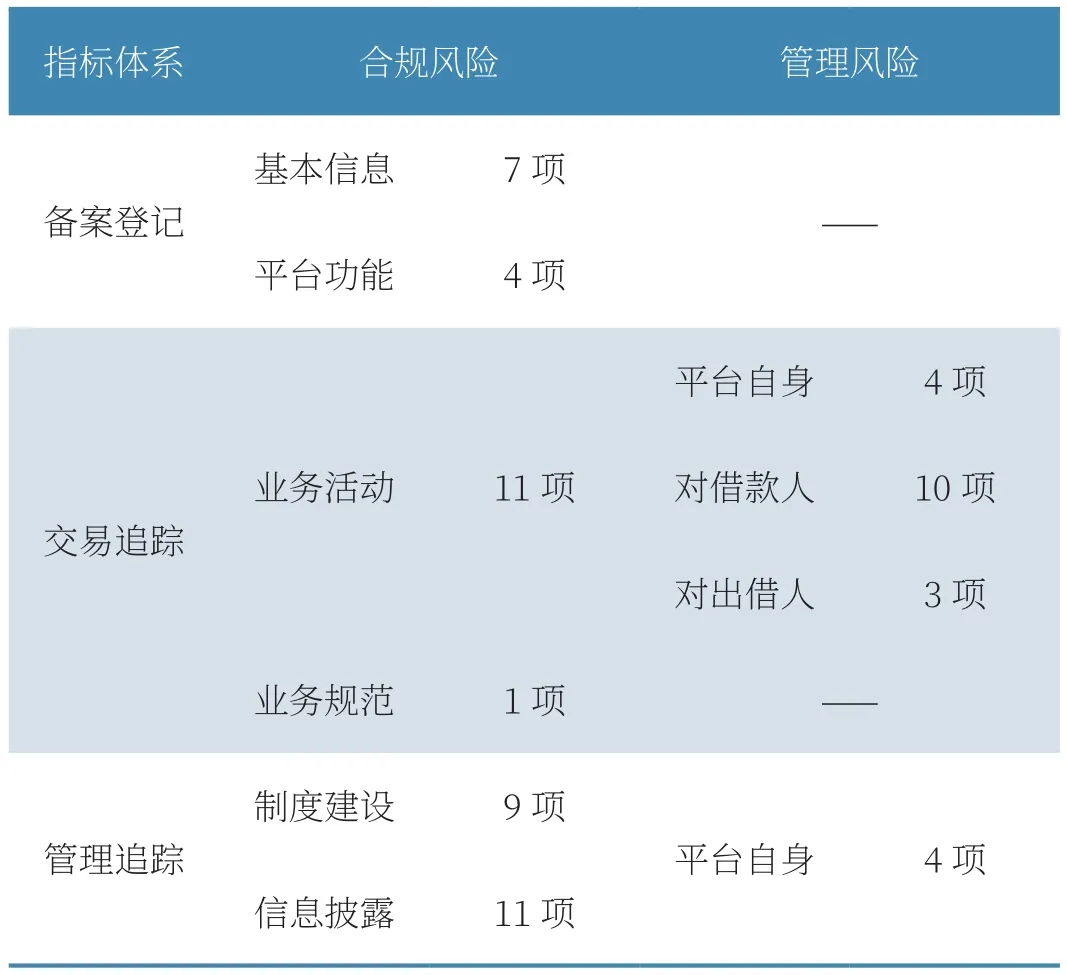
表3 风险监测指标抽取结果
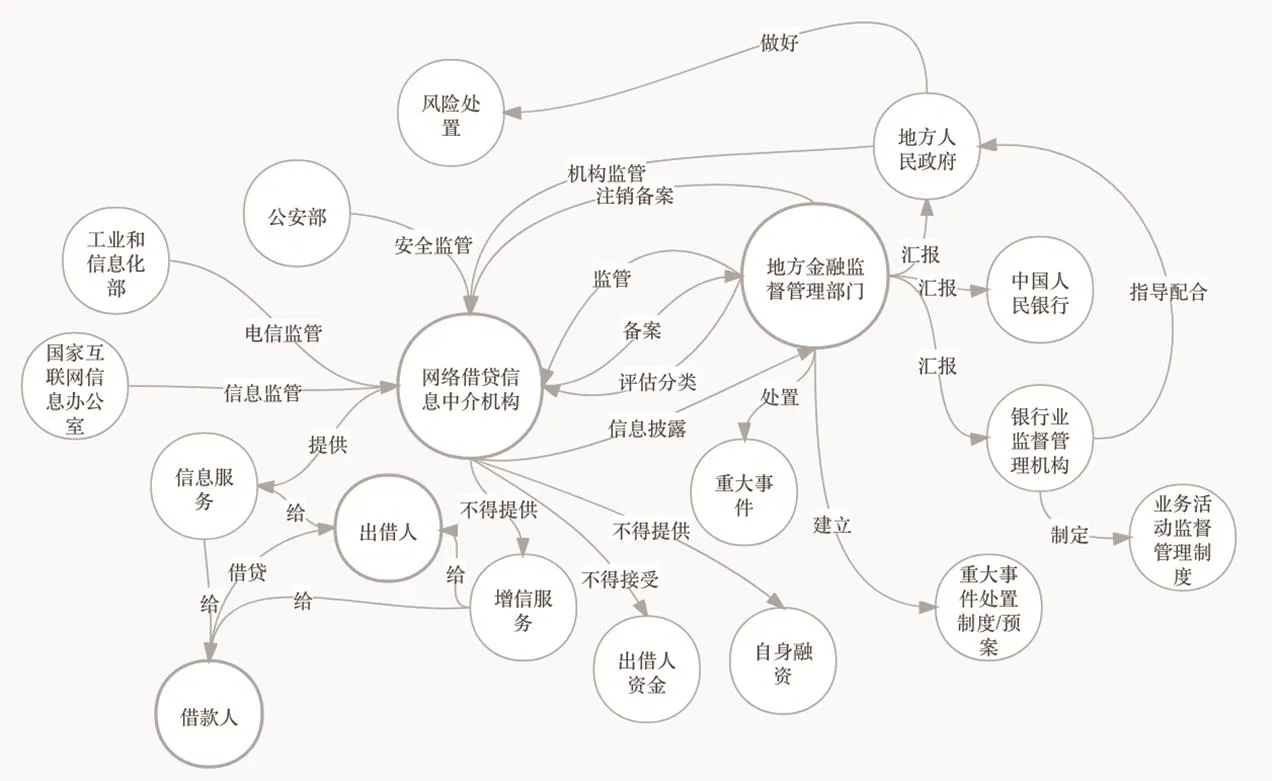
图3 Neo4j图数据库(局部)
5.结语
本次研究围绕监管文本知识图谱构建,探索了具体构建方法并实际测试。实验结果表明,所采用的方法能有效抽取监管文本中的实体及实体关系,并构建知识图谱,便利相关金融风险的监测和预警。
猜你喜欢
少先队活动(2020年12期)2021-01-14
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
杂草学报(2012年1期)2012-11-06
