
基于事件抽取技术的听证公开文本挖掘方法研究*
2022-01-28 03:08丁思媛乔晓东张运良
情报杂志 2022年1期
丁思媛 乔晓东 张运良
(1.中国科学技术信息研究所 北京 100038;2.富媒体数字出版内容组织与知识服务重点实验室 北京 100038;3.北京万方数据股份有限公司 北京 100038)
近年来,随着开放政务信息的日益增多,也随着文本挖掘和自然语言处理技术不断提升,从海量政府公开文本中抽取出有价值的信息,并以结构化的形式呈现出来,成为研究热点与难点。其中,听证是决策过程中的必要环节,会议披露的相关资料是一类重要的政府公开文件,通过收集特定议题中有价值的信息,能够及时发现相关领域的热点和重大研究进展,例如通过政府设立的基金情况分析产业发展重心,通过企业的科技成果分析领域的研究热点和前沿技术等。然而,现有对听证文本的研究更多采用传统的内容解读与分析方法,信息获取效率较低,无法满足当前从大规模听证文本语料中快速获取有价值信息的需求。
基于此,本研究针对科技领域,围绕利用听证过程中产生的各类文件,结合听证文本的特点,探索一套框架来实现听证文本有价值信息的识别与抽取工作,以此推动听证文本信息的利用,该方法的建立可为进一步分析此类文本信息提供新思路。
1 相关研究
1.1听证文本的相关研究随着开放政务信息的日益增多,从海量的政府公开文本中识别有价值的信息,成为研究热点与难点。
从研究方法上看,现有研究对政府公开文本信息的分析主要包括:a.基于内容解读的定性分析。此类研究主要通过专家解读的方式把握政策文本的背景和思想,高度依赖专家的学习背景和专业程度。b.基于内容分析的文本量化。此类研究以政策文本为样本,将非结构化政策文本转换为数量表示资料,并用统计数字进行描述和分析,其研究效果与信度很大程度上取决于研究设计。c.基于文献计量的政策计量分析。此类研究采用数学、统计学等学科的计量方法,基于官方颁布的政策文献,通过文本的主题词、发文机构等研究主题分布、引文分析等,其研究未深入到内容层面。d.基于社会网络的政策网络分析。此类研究构建社会网络,通过分析其节点、属性及关系揭示个体和群体特征,涉及的元素类型比较单一,且数据量较小。e.基于大数据的文本挖掘。此类研究运用大数据思维,利用自然语言处理、机器学习等方法,对文本进行结构解析和信息抽取,目前较缺乏针对政府公文的大数据分析和智能化处理技术[1]。
从涉及的研究对象来看,现有对政府公开文本信息的研究主要集中于政府公文、工作报告、统计数据等。然而,政府公开文本类型多样,美国在《情报自由法》中规定,除了法律规定需要保密的事项外,所有政府机构的书面版和电子版记录都应该公开[2]。听证文本属于政府公开文本的重要部分,是一类重要的情报资源,对其进行研究是有必要的。然而,现有对听证文本的研究方法集中于内容解读和文本量化,如Segal等[3]对1941年至1985年间有关军人妇女的国会证词进行分析,总结了有关妇女在军人中作用的主张政策的转变。Hall等[4]针对太平洋西北地区鲑鱼政策的几次听证的100多名证人的证词进行了话语分析。此外,也有基于社会网络的政策网络分析,如Fisher等[5]将社交网络分析应用于国会听证中的气候变化政治研究,重点关注证人之间的政治观点的关系。张海洋[6]利用铺平话语分析和基于网络的内容分析对有关中国空间发展议题的听证话语进行解读,并构建观点图谱。
以上对听证文本的研究更多的依赖于人工标注和筛选,对听证话语进行分析和解读,从而揭示听证词中的主题、观点和话语策略等,信息获取效率较低。本研究运用大数据思维,提出一套基于事件抽取技术的信息识别与抽取方法,满足当前从大规模听证文本语料中快速获取有价值信息的需求。
1.2事件抽取技术相关研究事件抽取是信息抽取的一个子任务,是从自然语言文本中抽取指定类型的事件信息,形成结构化数据输出的文本处理技术。
从抽取流程来看,事件抽取方法可以分为流水线抽取和联合抽取两大类,流水线抽取模式按照触发词识别、事件类型识别和事件要素识别的顺序执行,其中触发词识别和事件类型识别又可以合成为事件检测,而联合抽取模式则将几种任务联合执行,同时得到结果。
从抽取技术来看,事件抽取方法又有基于模式匹配的方法、基于机器学习的方法和基于深度学习的方法。基于模式匹配的方法在特定领域可以取得比较好的效果,但是系统的可移植性较差,且模式的构建费时费力,为解决此类问题,Marco等[7]提出了一种领域无关的基于规则的事件抽取框架,Araki等[8]提出了一种能够生成高质量训练数据的远程监管方法,均取得较好的改进效果。基于机器学习的方法多借鉴文本分类的思想,将事件类型及事件元素的识别转化成为分类问题,其难点在分类器的构造和特征的选择上,Majumder等[9]提出了一种用于生物医学文本事件提取的堆叠泛化模型,Liu等[10]使用概率软逻辑模型以逻辑形式编码全局信息,通过联合局部信息和全局信息提高分类性能。之后,随着深度学习的不断发展,更多学者将辅助信息和深度学习方法混合使用进行事件抽取,在基于神经网络的结构中加入注意力机制、远监督学习、图神经网络、迁移学习等技术。
最近还有一些利用事件抽取技术分析非结构化文本的工作。例如,Qiu等[11]从中文新闻中提取网络攻击信息。Taneeya等[12]提出一个基于深度学习的模块化网络攻击事件信息提取管道。还有学者从公司公开公告中抽取中文金融事件,对文学事件和生物医学事件等进行检测[13-16]。这说明事件抽取技术在特定文本信息抽取上有着明显的效果。
综上,事件抽取技术是当前自然语言处理领域的研究热点,并且在标准语料库上已经做了大量的研究。但是这些方法未被运用到听证文本的信息处理与分析中,未针对听证文本形成事件抽取任务的标准定义,也未形成抽取任务中所使用的预定义框架。如何结合听证文本的特点,探索一套行之有效的抽取框架以全面、快速地获取听证文本中与科技有关的知识内容和有效信息值得深入探索。
2 有价值信息的界定
听证公开文本篇幅长,内容多,因此,应该对文本中的信息进行合理界定与分类,把有限的时间与精力用在研究更有价值的信息上。本研究对听证的基本流程和公开文本类型进行梳理,根据文本内容特征界定其中有价值的信息,定义抽取任务。
2.1听证公开文本的类型在国外议会立法中,听证主要分立法听证、监督听证和调查听证三种类型,一个完整的听证流程包括[17]:a.公告。在决定举行听证后,委员会主席提前公布听证的日期、地点、主题等信息。b.登记作证和邀请证人。委员会公告听证列表,证人报名签字,最后委员会选择合适的证人并发布正式邀请函。c.提交证词副本。证人作证前需向委员会提供个人简历和书面证词副本,以及一份证词披露的真实性说明。d.准备文件。委员会在举行听证前和听证中需要为委员们准备必要的文件,包括议题相关的背景资料及政策研究资料。e.公开听证。除特殊原因外,公开举行听证,首先由委员会主任做开场陈述,再由证人进行陈述,证人陈述后,由委员针对证人进行询问,最后将听证的相关视频和文本进行公开。
根据流程对听证公开文本类型进行梳理,见图1。

图1 听证公开文本的类型
听证作为收集信息的重要渠道,其内容的新颖性和信息的实时性表明其公开文本具有较高的研究价值。分析听证公开文本的内容特征,可以发现,议员开幕词、证人证词、问答记录和听证会简报四类文本含有更多信息,且具有篇幅长,语义信息丰富,观点鲜明,内容概括度高等特点,应作为重点关注对象。
2.2有价值信息的界定与分类信息的获取过程包括“发现信息—收集信息—判断信息价值—提取信息”四个阶段,其中,信息价值的判断是提取有价值信息的重要前提和基础。郭慧芳[18]认为不同主体对同样的信息价值存在较大差异,可以认为信息的价值是一种主观价值,受个体特性的影响。本文中涉及的有价值信息主要是指包含特定事件,即在某个特定时间和地域范围发生的,涉及一个或多个参与者的事情或状态的变化的信息,包含多种事件类型及其相应的事件结构。因此,本研究通过事件抽取的方式,分析听证文本以识别有价值信息的描述,并根据文本中的信息构建其语义表示。
本研究以几则听证文本为样例,借助实例分析结果来归纳总结事件信息的类型。此外,由于本研究聚焦于科技领域,因此,进一步参照文献[19]对科技事件的分类,将听证文本中的有价值信息归为以下几类:a.税收:政府的税务变动;b.资助:政府和企业对某一项目、技术、产品或特定群体的投资和资助;c.合作:组织者协调企业间、政府各部门间以及政企间展开的合作;d.组织设立:成立或解散各志愿者组织、协会、政府机构和部门及其他社会组织;e.会议召开:召开的各种会议;f.提议:提出的各种建议、意见、倡议、期望和政策提议等;g.政策颁布:政府颁布的各项政策、战略、命令、法案法规、备忘录、规则、标准和正式计划等;h.项目启动:包括已启动或计划启动的各类科技项目;i.成果发布:政府、企业、科研人员等一系列的科技产出,包括产品、技术、其他专利等。
本研究将信息的主要要素归为主体、客体、目的3个关键词,以表示一个简单事件的逻辑结构(见图2),一个简单事件至少包含一个及以上的关键词,其中主体和客体包含政府机构、科技机构、院校、企业、其它公私组织和个人在内的各个实体。此外,设置了时间、地点等约束词作为事件补充信息,并设计了各个事件类型的角色(见表1)。


图2 简单事件逻辑模型
3 数据集的构建
本研究以听证披露的5G科技相关资料为实证研究对象,选取2015年至2021年4月间与5G议题有关的18场听证的公开文件(部分听证信息见表2),包括听证简报、议员开幕词、证人证词和问答记录,并重点研究资助、提议、政策颁布、成果发布四种信息类型。
经过数据清洗,共收集201篇听证文本,删除文档标题、引用、证人介绍语、感谢语等无关内容,仅保留正文部分,并按句子进行切分,共得到14 117个句子,其中事件句有3 333条,包含345条资助事件句,399条提议事件句,621条政策颁布事件句,256条成果发布事件句。对以上四种类型的事件句进行事件角色的论元标注,最后得到6 799个标记。将所有数据分为训练集、验证集和测试集,比例为8∶1∶1。数据集的统计情况见表3。

表3 事件分类与论元抽取数据集统计
4 事件检测与论元抽取
4.1设计思路通过对听证文本内容的分析,以及对含有事件的句子进一步细致分析可以发现:a.听证会证词一般以演讲稿的形式进行描述,复杂句较多,信息量大,多运用蕴含较多信息的长句,尤其是复合句的采用。b.由于证人陈述和询问时间一般控制在5分钟内,且发言多为总结性话语,主要表达观点意见,虽然听证文本篇幅较长,但提及的事件往往用一到两句话进行概括。c.需要抽取的事件句在文本中分布较为分散和稀疏,非事件句数与事件句数比值较大。因此,相对于全篇幅的事件抽取,以句子为单位即可满足抽取要求。传统的事件检测任务往往先识别文本中的事件触发词,然后对触发词进行分类,需要耗费大量时间对触发词进行标注,鉴于本研究需要构造自己的数据集,相比于传统方法,无触发词的事件检测更便于减少人工成本。此外,本研究意图从事件类型和事件论元等多方面对事件信息进行分析,为了有效减少训练过程中的错误累积,相比于联合抽取模式,流水线抽取模式更符合要求。
基于以上思路,本研究将抽取任务分为事件句识别、事件类型检测和事件论元抽取三个阶段。首先,根据定义的事件类型,采用双向门控循环神经网络(Bidirectional Gate Recurrent Unity, BiGRU)结合注意力机制[20](Attention Mechanism)来检测句子中是否包含事件,并构建候选事件句集合。其次,将句子的实体标签和角色标签嵌入输入语料,采用长短期记忆网络(Long-Short Term Memory, LSTM)结合注意力机制[21]对候选事件句进行事件类型检测,通过实施两次分类任务,缓解训练过程中产生的类不平衡问题。最后,将句子的词性标签和角色标签嵌入输入语料,采用序列标注的方式实现对事件论元的抽取。
4.2事件句识别方法设计本研究将内容按标点符号切分成句子,将其处理成多个句子的集合,给定包含N个句子{S1,S2,…,SN}的语料,每个句子赋予一个事件标签Y∈{0,1},其中1表示句子中含有事件(即含有上文定义的九类事件中的1个及以上),将其看成一个二分类任务,通过预测每个句子的标签,筛选含有事件的句子,构建候选事件句集合。该事件句识别模型BERT_BiGRU_att架构见图3。

图3 事件句识别模型框架
a.输入层:假设一个句子S有m个单词,每个单词有位置标签w,则输入句子Sn={tokensw1,tokensw2,…,tokenswm},利用BERT词向量模型将文本信息转化成词向量矩阵。
b.隐含层:使用BiGRU序列生成模型对文本深层次语义信息进行特征提取,将正向和反向提取的文本深层次特征信息输入到注意力机制层中,计算不同时刻词向量的概率权重,再利用全连接神经网络整合特征提取层的信息进行最终的特征提取。
c.输出层:最后加入softmax层,通过sigmoid函数将全连接层提取到的特征进行归一化处理,得到事件类别标签值。
4.3事件类型检测方法设计在事件检测中,一个普遍现象是同一个句子中会存在多个事件,例如句子“Commission proposed the 5G Fund, which would make up to $9 billion in Universal Service Fund support available to carriers to deploy advanced 5G mobile wireless services in rural America”中包含“提议”和“资助”两个事件类型,因此,这就意味着一个句子中存在0到多个事件类型标签。为解决多标签问题,本研究将多标签分类任务转化为多个二分类任务,假设给定n个目标事件类型{t1,t2,…,tn},则可以用0或1来表示一个事件句s是否包含一个事件类型t,如表4。
情境的选取:主题同步。选用同一本教材,在同一教学周内,选取相同的情境,通过情境下的角色扮演,反复强化对话训练和词句运用,促进融会贯通。

表4 多个二分类实例
为解决触发词缺失问题,在Liu等[22]研究的基础上,本研究通过补充实体类型标签和角色类型标签丰富句子的语义信息,从而提高事件句类型检测性能。该事件类型检测模型LSTM_att架构见图4。

图4 事件类型检测模型框架
a.输入层:利用Stanford CoreNLP工具对给定的事件句的实体类型进行解析,结果示例见图5,本研究的角色标注结果示例见图6。假设一个类型为T的句子S有m个单词,每个单词有位置标签w,实体标签p,角色标签q,则输入语料为{tokensw1,p1,q1,tokensw2,p2,q2,…,tokenswm,pm,qm,T},w,p,q∈[0,m],将单词嵌入wi,实体标签嵌入pi,角色标签嵌入qi,利用Word2Vec词向量模型将输入的语料信息转化成词向量矩阵。

图5 Stanford CoreNLP工具实体解析结果

图6 事件角色标注结果
b.隐含层:使用LSTM序列生成模型对文本深层次语义信息进行特征提取,将正向和反向提取的文本深层次特征信息和事件类型信息输入到注意力机制层中,再利用全连接神经网络整合特征提取层的信息进行最终的特征提取。
c.输出层:加入softmax层,通过sigmoid函数将全连接层提取得到的特征和事件类型特征进行归一化处理得到事件类别标签值。
4.4事件论元抽取方法设计事件抽取任务的目标是通过给定目标事件类型和角色集合,识别候选事件句中所有的目标类型事件,并根据角色集合抽取事件对应的各个论元。由于本研究定义的事件角色所对应的论元类型包括实体,如机构、时间、地点等,也包括名词词组和短语,如“consumer education”“5G Fast Plan”“Spectrum Relocation Fund”等,这类词组与命名实体相比在词形上不具有特殊属性。因此,本研究采用了一种融合角色特征和词性特征的序列标注方法实现对事件论元的抽取。该事件论元抽取模型BERT_LSTM架构见图7。

图7 事件论元抽取模型框架
a.输入层:由于本研究数据体量小,因此,可以将所有类型的事件句进行统一的论元抽取,即将各类事件的主体、客体、目的3个逻辑关键词都赋以角色标签“subject”“object”“purpose”,以此缓解数据量小的问题,如“资助者(sponsor)”被标记为“subject”,“接受者(recipient)”被标记为“object”。利用Stanford CoreNLP对词性进行解析,最后得到词性解析结果如图8。假设一个类型为T的句子S有m个单词,每个单词有位置标签w,角色标签q,词性标签r,则输入语料为{tokensw1,q1,r1,tokensw2,q2,r2,…,tokenswm,qm,rm},w,q,r∈[0,m]。结合动态词向量表示的BERT模型将输入的语料信息转化成词向量矩阵。

图8 Stanford CoreNLP工具词性解析结果
b.隐含层:转换为综合向量序列X={Xw1,q1,r1,Xw2,q2,r2, …,Xwm,qm,rm}之后,使用LSTM序列生成模型对文本深层次语义信息进行特征提取。
c.输出层:加入softmax层,通过sigmoid函数将特征进行归一化处理得到事件论元类别标签。
5 结果评测与分析
本研究三阶段实验均通过人工标注的数据集对模型进行训练并测试,与现有模型的实验结果进行比较验证模型的有效性,评测标准选择精确率、召回率和F1值。然后,选取与5G议题有关的其它听证的公开文件,并入初始数据集,使用前述方法分别进行事件句识别、事件类型检测和事件论元抽取,对所收集的数据进行统计分析,并对结果进行展示。
5.1结果评测选择支持向量机(Support Vector Machines, SVM)[23]和因式分解双线性多角度注意力机制(Factorized Bilinear Multi-aspect Attention Mechanism, FBMA)模型分别进行事件句识别,作为对比以判断BERT_BiGRU_att模型的有效性。其中,FBMA模型由Sneha等[24]提出,该模型在事件检测任务中取得不错的效果。经过实验,BERT_BiGRU_att模型在事件句上的召回率为0.76,F1值为0.71,在非事件句上的精确率为0.92,F1值为0.90,达到较好的分类效果,可选择作为最优事件句识别模型,见表5。
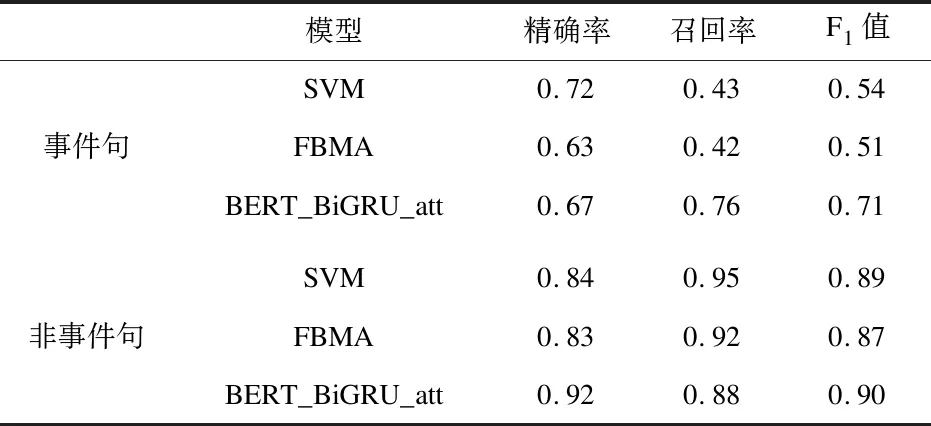
表5 事件句识别测试集结果
由于BERT_BiGRU_att模型在第一阶段的二分类效果较好,因此将其继续运用于多分类任务中,以判断LSTM_att模型的有效性。经过实验,BERT_BiGRU_att模型在事件类型检测上的精确率为0.67,召回率为0.66,F1值为0.66,LSTM_att模型的精确率为0.68,召回率为0.65,F1值为0.66,模型效果差异不大,可选择作为最优事件类型检测模型,见表6。

表6 事件类型检测测试集结果
此外,利用不加入词性特征的基于BERT和CRF的BERT_CRF模型进行论元抽取,判断BERT_LSTM模型的有效性。经过实验,BERT_LSTM模型在事件论元抽取中的精确率为0.65,召回率为0.57,F1值为0.61。相比基准模型有所提升,可选择作为最优事件论元抽取模型,见表7。

表7 事件论元抽取测试集结果
5.2特定论元的分析由于对事件论元进行了细致的划分与抽取,因此,可以对特定论元进行统计与分析。
对抽取出的主体或客体进行分析,发现存在多处共指现象,通过人工比较和判断的方式找出同一实体的所有不同表达结果费时费力,因此,可以对其进行相似度计算,主体间的相似程度越高,表达为同一实体的可能性也越高。本研究利用difflib标准库计算文本差异,如经过计算“FCC Mobility Fund”“FCCs Mobility Fund”“FCCs Mobility Fund Phase II”“Mobility Fund I”“Mobility Fund Phase I”“Mobility Fund Phase II”之间的相似度均超过0.6,代表同一实体“Mobility Fund”。
选取一个事件中出现的所有主体和客体,通过相似度计算快速查找同一实体的不同表述并进行消歧处理,处理后的数据可以用来构建共现网络(见图9),图中节点越大表示该实体在不同事件中出现的次数越多,边越宽表示两个实体在不同事件中共同出现的次数越多,它们之间的关系强度也越大,箭头由主体指向客体。由图发现:a.国会与FCC有强关联,FCC承担着5G建设中的重要作用。b.一个实体既可以为一个事件主体,又可以为另一个事件的客体,如国会向FCC投资,FCC又将资金投入别的项目或机构,可用于分析和溯源资金的去向。c.网络中独立节点或连接数较少的节点说明其出现频次较低,但作为主客体同样具有重要性,例如,Verizon,T-Mobile,CSMAC等,可以作为进一步的研究对象。d.“congress”到“FCC”到“Connect America Fund”到“rural broadband”之间有一条连线,可以理解为国会联合FCC提出了连接美国基金,该基金的一个重点项目是推动美国农村的无线和宽带服务,可见,通过分析主客体之间的路径,可以快速地了解机构间的联系以及事件的演化。

图9 主体客体共现网络
5.3特定事件的分析由于对事件类型进行了统一划分与识别,因此可以针对不同的事件类型进行分析。
5.3.1 提议事件分析 通过LDA主题建模归纳提议中的主要话题[25],采用困惑度调节主题个数以确保模型的聚类效果。根据困惑度公式,当主题数为13时,困惑度达到最低。因此,需要训练得到包含13个主题的LDA主题模型。根据LDA主题的词特征,发现5G议题下提议的主要内容包括以下方面:a.提议关注5G基金和频谱拍卖的相关政策。b.提议支持无线业务的发展并关注其应用与选址问题。c.提议支持政府对宽带频谱等基础设施的进一步部署。d.提议认为应该加强卫星和移动通讯技术的发展。e.提议支持政府加强对美国农村的网络建设。f.提议认为政府应继续就5G进行系列改革以确保美国在5G领域的领先地位。g.提议建议进一步加强5G标准和法案的制定。h.提议关注授权的和非授权的商用频谱。i.提议建议频谱拍卖的资金用于农村5G网络服务。j.提议关注5G服务的提供者/消费者利益。k.提议关注农村交通服务和5G安全性。l.提议支持通过频谱拍卖提供无线和宽带建设和服务的基金。m.提议关注5G的基础设施和技术发展。
5.3.2 资助事件分析 选取资助主体“congress”“commission”“FCC”“government”,按时间顺序对事件客体与金额进行统计分析,见图10。美国的《电信法》通过建立四个计划来保证农村和岛屿消费者的服务支持,其中,连通美国基金于2018年提出第二阶段将在未来十年每年投入19.8亿美元,生命线计划从2020年起年预算更改为23.85亿美元,电子费率计划2.0版本(E-rate program)从2014年开始将年度最高限度设定为41.5亿美元,农村医疗保健计划从2016年医疗保健提供商对高速宽带融资请求超过上限开始,也由原先的每年4亿美元提高到5.71亿美元。可见,美国在2012年开始对已有基金进行修订或颁布新基金以支持5G发展,近两年对通信领域的投入加大,并计划分配十年内的资金支持。

图10 政府投资项目与金额
5.3.3 政策颁布事件和成果发布事件 以政策颁布事件和成果发布事件为例,分别选取事件对应的所有客体,以及与客体对应的主体、时间,进行统计分析,见图11。可以看出,2017-2020年间国会提议了较多法案,例如,2017年的“New Deal Rural Broadband Act”“ AIRWAVES Act”“Spectrum Auctions Deposit Act”,2018年的“RAY BAUM'S Act”“Access Broadband Act”“5G FAST plan”等。此期间,成果产出也逐渐增多,例如,思科公司于2019年发布wi-fi6的可接入点,2020年小型蜂窝的建设已初具规模,且此后几年的目标将继续建设千万个蜂窝网络。
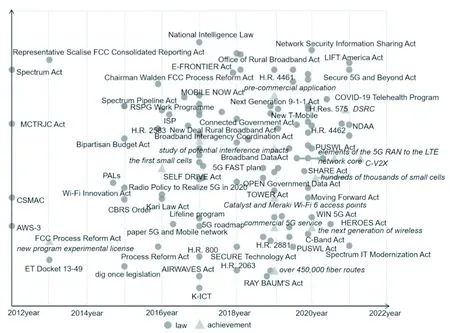
图11 政策颁布和成果发布展示
相比于已有对听证公开文本的研究,使用预定义的事件框架对文本特定信息进行抽取,并将该信息的核心内容分解为事件的不同组成部分,不仅提高了大规模听证公开文本信息抽取的效率,同时有利于进行多维度的信息分析,并为知识图谱、系统检索等多种下游任务提供了基础的结构化数据。
6 结束语
本研究在听证公开文本中有价值信息的通用性识别和抽取方法上做了一些研究。第一,对听证公开文本的类型和内容做了分析,界定并细分文本中有价值的信息。第二,采用事件抽取为主要技术手段,将有价值的信息定义为不同事件类型并设计相应的事件角色,根据文本内容特点提出了一种三阶段式信息抽取方法。实验研究表明,该方法取得了一定的抽取效果,提高了大规模听证公开文本信息抽取效率,为进一步文本分析提供新思路。
本研究的抽取方法还存在一些问题,特别是数据集规模较小和标注数据的不足,后续研究将扩展标注其他五类事件的数据,并引入半监督学习方法减少对标注数据的依赖。此外,后续将对事件之间的因果关系和顺承关系抽取进行研究,更好地用结构化的方式呈现听证文本中的有效信息。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
云南教育·小学教师(2022年4期)2022-05-17
小天使·三年级语数英综合(2022年4期)2022-04-28
甘肃教育(2020年8期)2020-06-11
艺术评论(2020年3期)2020-02-06
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
汽车导报(2017年5期)2017-08-03
中学生数理化·高二版(2016年4期)2016-05-14
Coco薇(2015年11期)2015-11-09
