
结合时序注意力机制的多特征融合行人序列图像属性识别方法
2022-02-14 12:41裴继红
信号处理 2022年1期
黄 晨 裴继红 赵 阳
(深圳大学电子与信息工程学院,广东深圳 518060)
1 引言
行人属性识别任务是对给定行人图像的某些特定行人属性的存在性进行判定的过程,近年来行人属性识别被广泛应用于行人重识别、行人检索等领域,受到越来越多的关注。
过去以单张静止图像作为研究对象的行人属性识别任务取得了较多的成果。在传统方法中,Li[1]等人使用支持向量机去识别行人属性并作为行人重识别任务中的辅助。Zhu[2]等人使用Boosting算法来实现行人属性识别。Deng[3]等人结合支持向量机和马尔可夫随机场来进行属性识别。随着深度学习技术的不断发展,越来越多的工作利用卷积神经网络来对行人图像进行深度特征提取,并以此完成行人属性识别。Li[4]等人基于CaffeNet 提出了DeepSAR 与DeepMAR 两个行人属性识别网络。Liu[5]等人提出了一个基于注意力机制的深度网络HydraPlus-Net,将层级注意力机制图多向映射到不同的特征层。Tang[6]等人提出一个属性定位模块,能自适应地发现最具判别力的区域。Tan[7]等人利用GCN 来进一步捕获行人属性识别中的属性和上下文关系。上述的几种方法从不同的角度提升单张图像上的行人属性识别的性能,本文将行人图像序列为数据输入,在提取行人序列深度特征的基础上,提升行人属性识别的性能。
时序建模方法的研究也因为智能视频数据处理技术的发展而受到越来越大的重视,时序建模的目的主要是为了将一系列帧级图像特征融合为一个用于表征视频序列的特征。时序建模也被广泛应用于基于视频序列的行人重识别、视频分类和智能语音处理等领域。而在行人序列属性识别方面,由于缺少公开数据集等原因,绝大多数的工作都集中在基于单张图像的行人属性识别中,更缺乏比较多种特征融合和时序建模方式在基于序列行人属性识别任务中的表现的工作。
综上所述,目前绝大多数研究关注于基于单张图像的行人属性识别,而忽略了现实场景下以序列作为输入数据的合理性和可能性,更缺少在基于序列的行人属性识别任务中如何进行更好的时序建模的研究,即如何更好的将帧级特征融合为表征序列的特征。本文的主要贡献可以归纳为以下几点:
(1)构建了结合时序注意力机制的多特征融合行人序列图像属性识别网络,在基于序列的行人属性识别任务中获得了最佳的效果,并探究了影响网络性能的几个因素。
(2)在带权值交叉熵损失函数的基础上添加tversky 损失函数,并以此作为网络训练的损失函数,实现对查准率和查全率更好权衡。
(3)在四个不同的校园场景下,制作了基于序列的行人属性识别数据集,验证了在行人属性识别任务中,以行人序列作为数据输入的方式在识别效果上要优于以单张图像作为数据输入。
2 相关工作
基于手工特征的方法[1-3]难以有效提取出稳定的行人特征,且忽略了行人属性之间的关联。目前基于单张图像的行人属性识别方法大多都以深度学习作为研究工具。Li[4]等人基于CaffeNet 提出了DeepSAR 与DeepMAR 两个行人属性识别网络,并针对样本分布不均的问题,对传统的交叉熵损失函数进行改进,提出了带权值的交叉熵损失函数。Tan[7]等人利用GCN 来进一步捕获行人属性识别中的属性和上下文关系,并提出了属性关系模块和上下文关系模块,实现了对上下文关系的充分利用。Zhao[8]等人受到循环神经网络(RNN)超强的上下文关联学习能力的启发,提出了用LSTM 结构来学习属性之间相互依赖以及排斥的关系的网络结构(GRL),同时在网络中还引入了空间注意力机制。
随着深度学习技术的迅速发展,以及计算能力的不断提升,基于视频数据的智能分析领域越来越受到重视,视频序列相对于单张图像的最大区别就是还隐含了时序的信息。视频行人重识别、行为识别为其中重要的研究分支。
在行为识别方面,Tran[9]等人证实了3D 卷积网络在时空特征提取中是有效的,并提出了C3D 卷积网络结构。Zhu[10]等人提出了时间金字塔池深度网络(DTPP),用于学习视频级特征的表示方法。Donahue[11]等人设计了CNN+LSTM 的网络结构(LRCNs)用于行为识别、图像描述和视频描述。在基于视频序列行人重识别方面,McLaughlin[12]等人使用卷积神经网络提取空间特征的同时利用递归循环网络RNN来提取时序特征。Liu[13]等人提出了不同于RNN 和LSTM 的改善循环单元(Refining Recurrent Unit,RRU)进行帧间特征的升级,并提出了时空线索整合模块(STIM)。Li[14]等人设计了GLTR 模型以同时挖掘长时和短时的时序信息。Gao[15]等人比较了常见几种时序建模方式在视频行人重识别中的表现,并提出了一种基于时空联合卷积的时序注意力机制。
3 结合时序注意力机制的多特征融合行人序列图像属性识别网络
本文提出的结合时序注意力机制的多特征融合行人序列图像属性识别网络由3 个部分组成,分别是基于ResNet50 的帧级特征图序列的生成模块、结合多池化与3D 卷积注意力机制的多因素时空特征聚合模块和行人属性多聚合的序列特征融合及识别模块。网络的整体框架如图1所示。网络的输入由从原始行人序列均匀抽样得到的T帧行人图像构成,对于不足T帧的序列,采用按序循环复制的方式直到序列长度为T帧。
3.1 基于ResNet50的帧级特征图序列的生成模块
结合时序注意力机制的多特征融合行人序列图像属性识别网络的输入数据为T帧3 通道的RGB图像序列。ResNet 通过旁路的支线将上一层或者前几层的输出直接跨越多层连接到后面的网络部分中,从而缓解了过往深层网络存在的梯度消失和网络退化的问题,并且具有相当强的特征力,因此本文选用ResNet50 深度残差网络作为帧级特征提取网络,用于提取单张图像的帧级特征。
输入的图像序列IS={I1,I2,…,IT}在经过帧级特征提取网络后,每一帧图像的深度特征都由一组空间大小为m×m,通道数为D的特征图来表示。当输入的数据是长度为T帧的图像序列,意味着共有T组这样的特征图。将生成的T组特征图称为特征图序列{fm(c,t)∈Rm×m,c=1,…,D;t=1,…,T}。于是输入的图像序列IS在经过ResNet50后,获得的特征图序列FIS为:
3.2 结合多池化与3D 卷积注意力机制的多因素时空特征聚合模块
在时空特征聚合方面,本文采用了3种方式,分别是空-时二次平均池化特征聚合、空-时平均最大池化特征聚合和空-时3D卷积注意力因子加权特征聚合。详细介绍如下:
空-时二次平均池化特征聚合:将Resnet50获得的特征图序列FIS进行常见的2D 空间聚合,将FIS中的每一组特征图{fm(1,t),…,fm(c,t),…,fm(D,T)}送入池化域大小为m×m的二维平均池化层中,从而使特征图序列FIS转化为T个帧级特征向量f t∈RD,t=1,…,T。将所有帧级特征向量组合起来可以表示为T×D的特征向量序列。再对所有帧级特征向量组合起来的特征向量序列进行时间序列的1D 聚合。在空-时二次平均池化特征聚合中,时间维度上的特征聚合采用平均池化的方式。利用一个矩形窗口在输入的T×D的特征向量序列的时间维度T上进行扫描计算。fstmean∈RD表示的是经过空间特征聚合与时间特征聚合后,空-时二次平均池化特征聚合分支的输出。
空-时平均最大池化特征聚合:将Resnet50 获得的特征图序列FIS进行常见的特征图2D 空间聚合,采用与空-时二次平均池化特征聚合中相同的处理方式,最终同样获得T×D的特征向量序列f t∈RD,t=1,…,T。完成空间上的特征聚合后,接着进行时间序列1D 聚合,在空-时平均最大池化特征聚合分支中,T×D的特征向量序列在时间维度上的特征聚合采用最大池化的方式。在T个值中选择最大值作为输出从而完成池化降维。fstmax∈RD表示的是经过空间特征聚合与时间特征聚合后,空-时平均最大池化特征聚合分支的输出。
空-时3D 卷积注意力因子加权特征聚合:该分支的输入同样是Resnet50 获得的特征图序列FIS。此分支的整体结构图如图2 所示,主要由特征图2D空间聚合、局部通道特征聚合、基于全通道时-空3D卷积的注意力因子生成和注意力因子加权的特征聚合几个部分构成。
首先是特征图2D 聚合,利用池化域大小为m×m的二维池化层,从而使特征图序列FIS转化为T个帧级特征向量f t∈RD,t=1,…,T。
其次是局部通道特征聚合,此操作的输入数据是特征图序列FIS。并对此操作输入特征图的通道数进行降维。将特征图的通道数由D降至D',以减少参数量的同时提升了网络的性能。降维的具体方法是在输入通道数的维度上进行平均池化,池化步长设定为4,池化域大小设置为3,即池化后的输出特征图的每一个通道,都是由输入特征图中连续的3个局部通道聚合而成的。降维后T×D'的特征向量序列,用f t'表示。
再次是基于全通道时-空3D卷积的注意力因子生成,此模块的作用是利用输入的特征图序列生成T个注意力因子,即对每一个帧级特征的重要性权重进行判定。为了同时捕捉序列中的时间与空间特征,使用了3D 卷积层,3D 卷积核的尺寸为D×b×m×m,其中输入通道数为D,卷积核的时间维度的深度是b,则每一帧的注意力权重都是由相邻b帧决定的,核的空间大小为m×m,输入通道数为D',滤波器的数量为1,即输出通道数为1。此外为了获得T个注意力得分,还需要在时间维度上进行1 层的零边缘填充。本文中b=3,m=7,D=2048,T=16,D'=512。输出层与输入层之间参数的关系如下式所示,
其中Wout和Win分别表示输入输出特征图宽度,Hout和Hin分别表示输入输出特征图长度,Dout和Din分别表示输入输出特征图深度,Dout为输出的通道数,w,h,d,p,s分别表示的是卷积核的宽度、卷积核的长度、卷积核的深度、填充值长度和滑动步长。
3D 卷积层的输出是T×1×1×1 的注意力得分,去除两个冗余维度后,获得T×1 的时序注意力得分。接着,需要对T×1 的时序注意力得分使用softmax 函数计算产生最终的注意力权重(注意力因子)。
最后是注意力因子加权的特征聚合,利用得到的注意力权重对特征图2D 聚合部分中获得的一系列帧级特征向量做加权求和,从而获得用于表征序列的深度特征fst3d,
其中表示的是第t帧的注意力因子。以此方式对每一帧图像对于行人属性识别任务的贡献程度进行评分,最终得到一个1×D特征向量fst3d用于表征空-时3D卷积注意力因子加权特征聚合分支生成的序列特征。
3.3 行人属性多聚合的序列特征融合及识别模块
在结合多池化与3D 卷积注意力机制的多因素时空特征聚合模块中的每一路分支通过不同的方式,都获得了可以表征输入图像序列的深度特征,均由特征向量来表示,并作为行人属性多聚合的序列特征融合及识别模块的数据输入,模块的整体框架示意图如图3所示。现将三路分支输出的序列特征进行融合,采用平均融合的方式,如式(7)所示:
最终的分类判别由多分类器来实现,多分类器由全连接层、sigmoid 层和行人属性决策判别所构成,其示意图如图3 所示。图中的虚线矩形框代表的是输入的融合后序列的特征,维度为D。输出维度为N,即对应N个挑选出来的行人属性。输出的N个数值是N个属性的得分值(score),对应于图3中的S1、S2…SN的数值。随后将上述得分值送入sigmoid 层中,其目的是将N个属性的得分值映射到[0,1]的值域范围之内,即获得N个行人属性的概率值。在本文中,N=32。
3.4 网络损失函数
带权值的交叉熵损失:针对行人属性识别数据集中类别分布不均匀的问题,采用的是带权值的交叉熵损失函数LWBCE:
其中pl表示第l个属性中正样本所占的比重,yil表示第i个样本的第l个属性的真实标签,表示第i个样本的第l个属性网络预测为正样本的概率。权重系数wl为:
加入权重系数wl的意义在于,增大正样本数量较小的属性的损失,减小正样本数较大的属性的损失。
tversky损失函数:训练基于序列的行人属性网络时发现,只使用带权值的交叉熵损失网络的查准率在训练的过程中有明显的下降,导致网络查准率较低的一个直观原因是伪正例(FP)的数量过多,因此为了减少FP的数量需要增大对网络预测产生FP的惩罚力度,本文引入tversky 损失函数来改善查准率较低的问题。Tversky系数可以通过式(10)来定义:
其中p1i是网络预测第i个行人属性为正例的概率值,p0i是网络预测第i个行人属性为反例的概率值。α,β两个参数决定的是对FP 与FN 的惩罚力度,且α+β=1。则tversky损失可定义为:
综合式(10)和式(11)可以看出,当α越大时,tversky 损失函数在训练时对网络预测为FP 的惩罚力度就会越大,从而减少FP 的数量并提升查准率。当β越大时,tversky 损失函数在训练时对网络预测为FN 的惩罚力度就会越大,从而减少伪负例(FN)的数量并提升查全率。
总损失函数:本方法的总损失函数定义为式(12)
本方法引入tversky 损失是为了克服在只使用带权值的交叉熵损失时,网络查准率下降明显的问题,因此需要加大对网络预测产生FP 的惩罚力度,本文将α设定为0.6,β设定为0.4,以达到对查准率和查全率更好的权衡。
5 实验
5.1 数据集介绍
为了验证基于序列的行人属性识别网络的性能比基于单张图像的行人属性识别网络的性能更好,在4 个不同的校园场景下制作了一个行人属性识别的序列图像项目组数据集,本文中制作的数据集是一段不定长的行人序列对应一个多分类标签,即在一段不定长的行人序列中,所挑选出来的行人属性是保持不变的。制作的序列行人属性识别数据集的原始数据在4个不同的校园监控场景中完成采集,且监控摄像头都位于较高的位置,拍摄的场景之间没有重叠的区域。其中场景一总共有89 段行人序列,场景二总共有213段行人序列,场景三总共有185 段行人序列,场景四总共有166 段行人序列,4 个场景共有653 段不同长度的行人序列,平均长度为153帧。
共挑选了32 个常见行人属性进行标注,分别是:背包,帽子,长发,短发,男性,女性,挎包,上身短袖,上身长袖,下身短装,上身着装颜色(黑,蓝,棕,绿,灰,橘,粉,紫,红,白,黄),下身着装颜色(黑,蓝,棕,绿,灰,橘,粉,紫,红,白,黄)。训练集和测试集按照6:4 的比例进行分配。在4 个不同的校园场景中,各选取一段截短后的行人序列作为示例进行展示,如图4所示。
5.2 实验设置
数据集的组织方式:数据集分为训练集和测试集两个部分。对于训练集,从序列中选择训练网络的输入图像时,采用均匀抽样的方式,通过等间隔采样出来的图像作为网络的数据输入。对每一个不定长的行人序列,利用均匀抽取的方式选出16帧图像作为网络的输入。对于不足16帧的行人序列,采用循环复制的方式以满足要求。对于测试集而言,同样选择均匀抽样16 帧的方式来获取网络输入。在测试阶段,为了充分比较不同特征融合与时序建模方式下行人属性识别网络的性能,将完整序列分为多个均匀采样得到的图像集合,并全部送入网络中进行识别。
评价指标:基于序列的行人属性识别属于多标签分类任务,为了综合比较不同方法的性能,本文使用平均准确率(mA),平均查准率(m-prec),平均查全率(m-rec)和平均F1 score(m-F1)作为性能评价指标。
5.3 不同输入帧数实验
本文选择均匀抽样的方式,用等间隔采样出来的图像代替整段视频序列作为网络输入,选择更少的帧数,意味着采样的间隔更大,图像之间的差异也会更大,但是网络所能参考的图像也就相对较少。相反,选择更多的帧数,意味着采样间隔更小,图像间的差异也会更小,但是网络能参考学习的图像也就更多。从表1 中可以看出,输入帧数从4 帧增加到16 帧,综合4 个评价指标来看,网络整体性能是在提升的。当输入帧数为16帧时,网络的性能达到最佳,在每一项评价指标中都是最高的。
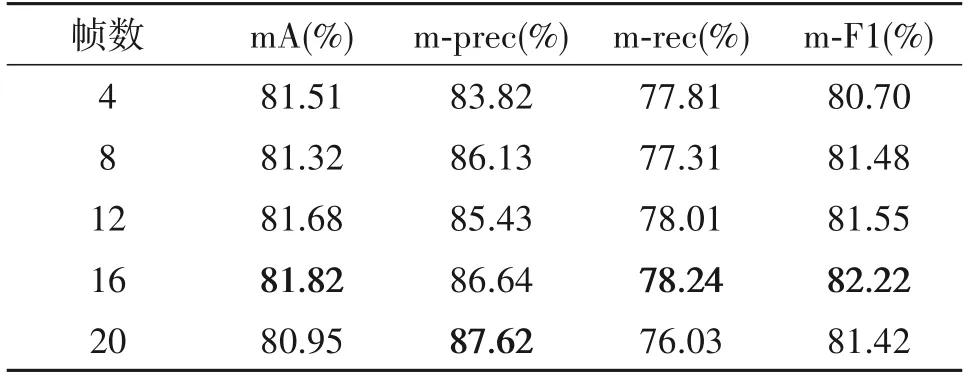
表1 不同输入帧数对比实验结果Tab.1 Comparison of experimental results with different input frames
此时增加输入帧数至20帧,除了平均查准率相对于输入16帧时提升了0.98%,其他的性能指标都有所下降,其中,mA 下降了0.87%,平均查全率下降了2.21%,平均F1 score下降了0.8%。综上分析,本文提出的结合时序注意力机制的多特征融合行人序列图像属性识别网络,将网络的输入帧数定为16帧。
5.4 损失函数参数实验
本文的损失函数由带权值的交叉熵损失和tversky 损失构成,其中tversky 损失中参数α和β在不同取值下,网络的性能如表2所示。

表2 不同α和β取值对比试验Tab.2 Comparison of experimental results with different value of α and β
综合来看,当α取值为0.6 且β取值为0.4 时,网络的性能达到最优,其中mA、m-prec、m-F1 三个评价指标都是最高,分别达到了81.82%、86.64%和82.22%。此外,由于本文的总体损失函数是由两个部分构成的,从实验结果中也可看出,tversky损失中的参数的变化,对整体性能的影响有限。
5.5 卷积核在时间维度的不同深度实验
3D 卷积相比于2D 卷积,多了一个在时间维度上的深度通道。3D卷积的时间维度的取值越大,可以理解成考虑的帧数就越多。对空-时3D卷积注意力因子加权特征聚合分支中,3D卷积层部分时间维度的深度的不同取值进行试验对比,实验将取值分别定为1、3和5,并将结果展示在表3中。
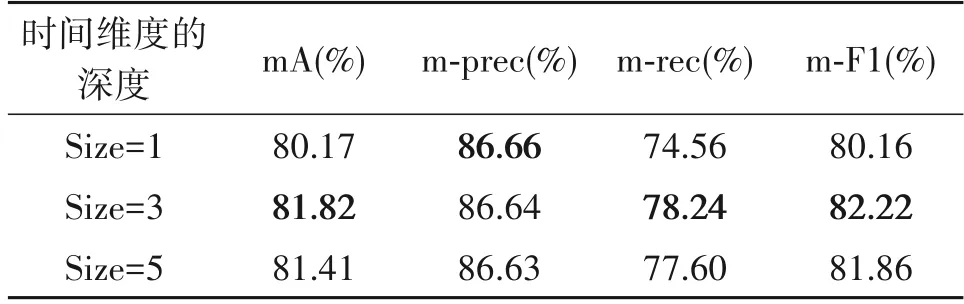
表3 卷积核在时间维度的不同深度实验结果Tab.3 Experimental results of different depth of convolution kernel in time dimension
从中可以看出,当时间维度的深度为1 时网络取得了最差的性能,因为此时网络没有充分考虑相邻帧之间的相互关系。在时间维度的深度选择为5 时,网络的性能比取值为3 时的要差,相比取值为3 时的最佳网络性能,在mA 和平均F1 指标中分别低了0.41%和0.36%。此外,取值为5 的网络参数量大于取值为3的网络参数量,增大了训练的难度,而网络整体的性能却没有得到提升。综上所述,本文将卷积核在时间维度的深度设定为3。
5.6 消融实验
不同分支特征融合情况下的网络性能如表4所示,表中的fstmean、fstmax和fst3d分别表示的是空-时二次平均池化特征聚合输出的序列的特征、空-时平均最大池化特征聚合输出的序列的特征以及空-时3D卷积注意力因子加权特征聚合输出的序列的特征。不论是单独去除空-时二次平均池化特征聚合分支或空-时平均最大池化特征聚合分支还是同时去除上述两个分支,网络的性能都会有所下降。当只使用空-时3D卷积注意力因子加权特征聚合分支的网络是最差的,相比于本文采用的三支路特征融合结构,mA 指标下降了0.84%,平均查准率下降了0.55%,平均查全率下降了1.32%,平均F1 指标下降了0.98%。综上所述,融合多路分支序列深度特征的网络,可以获得更多有用信息并提高行人属性识别的性能,证实了本文提出框架的有效性。

表4 消融实验Tab.4 Results of ablation experiments
5.7 不同特征聚合与时序建模方式实验
为了公平的对基于序列的行人属性识别方法与基于单张图像的行人属性识别方法作对比,实验中基于单张图像的行人属性识别方法和基于序列的行人属性识别方法中的帧级特征提取器,都是基于ResNet50构成的。
表5 展示的是多种特征聚合与时序建模方式下,基于序列的行人属性识别网络的性能。正如预测的,所有基于序列的行人属性识别方法的综合性能都优于基于单张图像的行人属性识别方法。其中RNN 与LSTM 两种时序建模的方式在行人属性识别任务中的表现并不好,虽然整体的性能有所改进,但是在平均查准率指标中甚至有所下降,分别下降了3.62%和3.39%,性能提升较小的原因可能是:在基于序列的行人属性识别任务中,多帧之间没有较强的因果关系且RNN 与LSTM 训练较为困难。

表5 不同特征聚合与时序建模方式实验结果Tab.5 Experimental results of different feature fusion and time series modeling methods
简单的时序最大池化与时序平均池化无需额外的网络参数,也能取得较好的识别效果,但是这两者依然存在问题:将多个帧级特征融合为一个序列特征时,没有充分考虑到帧与帧之间的联系,没有对多帧图像之间的重要性进行判定,损失了大量有价值的信息。文献[15]中提出的时序注意力机制与本文提出的方法都克服了上述不足,取得了比平均池化与最大池化更好的行人属性识别效果。表5 中的最后一行是本文提出方法的性能效果,可以看出,本文提出的结合时序注意力机制的多特征融合行人序列图像属性识别网络在各项指标中都是最高的,其中相比于基于单张图像的行人属性识别方法,mA 指标提升了3.98%,平均查准率提升了5.11%,平均查全率提升了7.81%,平均F1 指标提升了6.65%。此外,本文提出的方法在与文献[15]中提出的时序注意力机制进行对比,可以看出,本文提出的方法在每一项的评价指标中都是更高的,mA 指标提升了0.48%,平均查准率提升了1.49%,平均查全率提升了0.77%,平均F1 指标提升了1.09%,证实了本文提出框架与方法的有效性。
6 结论
本文提出了结合时序注意力机制的多特征融合行人序列图像属性识别方法,一方面利用时序注意力机制充分考虑到了帧与帧之间的差异,进一步对帧级特征的重要进行评估。另一方面在提取序列特征时,将空-时二次平均池化特征聚合、空-时平均最大池化特征聚合以及空-时3D卷积注意力因子加权特征聚合三路分支中输出的序列特征相融合,以获得更为强大的序列深度特征表达能力。通过在自建的基于序列的行人属性识别数据集上与多个主流方法进行对比实验,不仅体现了在行人属性识别任务中以序列作为数据输入相较于以单张图像作为数据输入,是更加具有优越性的,还充分体现了本文提出方法在基于序列的行人属性识别任务中的有效性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
计算机应用(2022年9期)2022-09-25
小猕猴智力画刊(2022年3期)2022-03-28
软件导刊(2022年3期)2022-03-25
农业工程学报(2022年1期)2022-03-25
意林(2021年5期)2021-04-18
意林·作文素材(2021年23期)2021-01-22
扬子江(2019年1期)2019-03-08
计算机技术与发展(2019年1期)2019-01-21
智能计算机与应用(2018年2期)2018-05-23
