
深度神经网络压缩与加速综述
2022-02-14 12:42曾焕强胡浩麟林向伟侯军辉蔡灿辉
信号处理 2022年1期
曾焕强 胡浩麟 林向伟 侯军辉 蔡灿辉
(1.华侨大学工学院,福建泉州 362021;2.华侨大学信息科学与工程学院,福建厦门 361021;3.香港城市大学计算机科学系,中国香港 999077)
1 引言
近年来,深度神经网络(Deep Neural Network,DNN)受到了学术界和工业界的广泛关注,被大量应用于人工智能各个领域。然而,深度神经网络的成功很大程度上依赖于GPU(Graphic Processing Unit,GPU)计算能力的发展。大型深度神经网络存在结构复杂、层级较多、节点数量巨大等特点,例如早期在ILSVRC 竞赛中取得了重大突破的AlexNet是针对图像分类任务而设计的卷积神经网络,仅由5 个卷积层与3 个全连接层组成,所含参数量超过6 千万,模型大小超过240 MB。此外,业界广泛使用的模型VGG16 则拥有1.44 亿个参数,模型大小超过500 MB,ResNet-152 拥有0.57 亿个参数,模型大小达到230 MB。采用上述模型对一幅224×224的彩色图像进行分类,分别需要进行150 亿次和113 亿次浮点型计算。另外,由于ResNet 系列模型具有复杂的分支结构,虽然其参数量相较于具有平坦结构的VGG 模型更小,但在实际训练和推理中耗时更长。可见,主流深度学习模型的存储和计算成本对于具有严格时延约束条件的实时应用来说过于高昂。
随着移动端设备的普及和市场规模的扩大,工业界迫切需要将深度学习模型部署到资源有限的边缘设备上。然而嵌入式设备和现场可编程门阵列(Field Programmable Gate Array,FPGA)所具有的内存容量、计算资源与GPU 相差几个数量级,面对庞大的神经网络模型显得捉襟见肘,因此模型压缩及加速的工作变得至关重要。目前,根据不同压缩与加速方法的性质,深度神经网络的压缩和加速方法可分为四类:参数量化、模型剪枝、轻量型卷积核设计和知识蒸馏。其中,基于参数量化的方法是降低权重参数的存储位数;基于参数剪枝的方法是通过去除权重参数中的非关键冗余部分来减少参数量;基于轻量型卷积核设计的方法从滤波结构乃至卷积方式的层面进行改进设计,从而降低计算复杂度;基于知识蒸馏的方法利用知识迁移来训练一个紧凑的网络模型且能复现大型网络的性能。我们将在下面的章节中分别对它们的特性和优缺点进行分析。具体地,我们将在后续章节中作进一步的介绍。本文剩余部分的安排如下:第2 节介绍模型压缩的主流方法;第3 节介绍常用数据集与性能评价准则;第4 节给出总结及未来研究方向的一些相关探讨。
2 模型压缩方法
本节将按照参数量化、模型剪枝、轻量型卷积核设计以及知识蒸馏的顺序进行介绍。表1对四种主要压缩方法进行了总结。
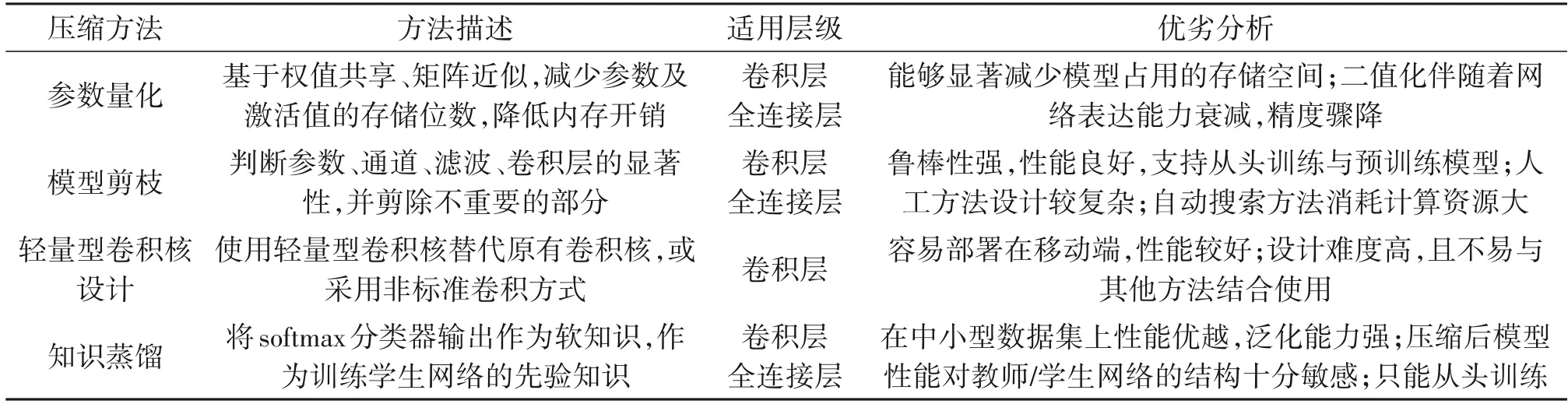
表1 不同深度神经网络压缩与加速方法总结Tab.1 Summarization of Various Methods for DNN Compression and Acceleration
2.1 参数量化
参数量化通过减少存储权重参数及激活值所需的比特位数来压缩原始网络。通过该方法,网络中权值和激活值都会被量化,并且浮点乘法累加操作(Multiply Accumulate)可以被低比特的乘法累加操作代替。因此,使用降低比特数的方法可以显著减少内存存储占用和计算资源的耗费。Gong 等人[1]和Wu 等人[2]通过k-means 聚类实现参数共享,只需要存储作为权重索引值的k个质心而不是所有权重值,显著减少了内存开销。
Gupta 等人[3]在基于随机舍入的CNN(Convolutional Neural Network)训练中采用了16 位定点数表示,显著减少了模型的内存占用和浮点运算,而分类精度几乎没有损失。进一步地,Han 等人[4]提出的方法利用权值共享对权值进行量化,然后对量化后的权值和索引表进行霍夫曼编码,以缩减模型大小。如图1所示,首先对原始网络进行训练,学习神经元间的连接(connection),将权重较小的连接剪除,然后对稀疏网络进行重训练,学习得到紧凑的新网络。Choi 等人[5]证明了利用Hessian 权重来衡量网络权值重要性的可行性,并提出了一种聚类参数,用于最小化Hessian 加权量化误差。Vanhoucke等人[6]的研究表明,将权重值量化至8 位,能够显著提升推理速度,同时保证最小的精度损失。Jacob等人[7]提出一种量化框架,在训练时保留32 位全精度存储方式,而在前向推理时对权重值与激活值进行8位量化,从而用整数运算替代浮点数运算,显著降低了运算复杂度。目前8位量化已经在工业界得到了广泛应用,除上述方法外,英伟达(Nvidia)公司推出了TensorRT-int8 量化工具,对于正负分布均匀的权重值与激活值采用最大值映射,将取值范围按一定比例映射至(-127,127),对于分布不均匀的值采用饱和截断映射,即在映射前截断部分区间,得到在正负区间对称的截断信息后再进行量化映射。
值得一提的是,二值神经网络是网络量化的极端情况。一般情况下,网络模型中各项参数都采取32位单精度浮点数进行存储,而二值网络中将参数及特征图激活值都以+1,-1 形式存储,每个值仅占用1 比特内存,类似地,三值网络[8]采用+1,0,-1 的组合来量化权重。早期对网络二值化进行探索的几项工作,如BinaryConnect[9],BinaryNet[10]和XNOR[11]等都是在模型训练过程中直接学习二值化权值或激活值。
然而,由于大部分二值网络设计在利用矩阵近似的思想时未能充分考虑二值化带来的精度损失,并且网络量化将参数离散化,加剧了训练的不稳定性,在对诸如GoogleNet 等大型CNN 进行量化压缩后,容易导致二值网络在分类、检测任务中的精度显著降低。为解决这个问题,Hou 等人[12]的工作提出了一种近似牛顿算法(proximal Newton algorithm),该算法利用对角Hessian 近似将二值权重的损失最小化。Liu 等人[13]提出一种可求导的软性量化(Differentiable Soft Quantization,DSQ),使网络在反向传播过程中获得更精确的梯度,以弥补二值网络前向传播过程中的量化损失。Lin 等人[14]提出一种对权重进行随机二值化处理的压缩方法,随机二值化不仅能够减少浮点运算次数,还具有一定的正则化效果,能够抑制二值化造成的精度损失。Zhang 等人[15]认为,由于DNN 的权重、激活值在各个卷积层的数值分布是不同的,因此对整个网络采取统一标准的量化策略缺乏灵活性。他们提出一种可习得的量化器,即联合训练模型与其量化器,在训练过程中逐层优化量化策略,以提升压缩后的模型精度。Cai 等人[16]提出一种基于半波高斯量化(half-wave Gaussian Quantization)的近似方法,在二值化权重的基础上,将激活函数ReLU(Rectified Linear Unit)进行近似处理,以适应二值化网络的反向传播计算,使学习过程更加稳定,减小精度损失。Bethge 等人[17]提出一种二值化网络结构MeliusNet,该结构采用双块设计,能够连续地提升特征数量,此外该结构对一些保持32 位存储的卷积层进行重新设计,极大地减少了运算量。
表2 列出了上述所提主流量化方法的性能对比,所有方法均在ResNet-18 模型上进行,数据集采用ImageNet。

表2 ImageNet数据集上对ResNet18采用不同量化方法的性能对比Tab.2 Performance comparison of different quantization methods on ResNet18 based on ImageNet dataset
2.2 模型剪枝
模型剪枝是模型压缩和加速中使用最为广泛的研究方法。模型剪枝的基本思想是通过在预训练的DNN 模型中剪除冗余的、信息量少的权重,将网络结构稀疏化,从而降低内存开销,加速推理过程。剪枝方法包括非结构化剪枝和结构化剪枝。非结构化剪枝是最细粒度的方法,其操作对象是滤波(filter)中的每个权重;而结构化剪枝的操作对象是整个滤波,乃至整个卷积层这样的结构化信息。
2.2.1 非结构化剪枝
早期的剪枝方法大都基于非结构化剪枝,由于它裁剪的粒度为单个神经元,因此在对卷积核进行非结构化剪枝时,得到稀疏分布的卷积核,即存在较多元素为0的矩阵,因此可以有效减少内存占用,加速推理。
Hanson 等[19]提出了基于有偏权重衰减的剪枝方法,是对网络稀疏化最早的探索。Hassibi 等人[20]根据损失函数的Hessian 矩阵减少了连接的数量,使网络结构高度稀疏化。Srinivas 和Babu[21]从神经元之间存在冗余的角度出发,提出了一种不依赖训练数据的剪枝框架,计算节点的冗余程度并进行删除。Han等人[22]提出批量减少整个网络中的参数量和运算量,该方法规定的三阶段剪枝流程被广泛沿用,即训练权重、模型剪枝、重训练。Chen等人[23]提出了HashedNets 模型,引入哈希函数,根据参数间汉明距离将权重分组,实现参数共享。然而,受限于底层硬件和计算库的支持,非结构化剪枝通常会构成非结构化的稀疏矩阵,在计算过程中会造成内存获取的不规则性,影响硬件工作效率,降低计算速度。因此,近年来研究者们致力于探索基于结构化剪枝的压缩方法。
2.2.2 结构化剪枝
目前,在基于结构化剪枝的研究工作当中已涌现出许多出色的研究成果,解决了无法对稀疏矩阵计算进行加速的问题。此类方法遵循滤波显著性准则(即判别滤波对于模型性能重要性的准则),直接批量地剪除非显著性滤波,达到压缩目的。Wen等人[24]利用Group Lasso 对模型中不同粒度的结构,包括滤波、通道、滤波形状、层深度(filters,channels,filter shapes,layer depth)进行正则化,并将此正则化项加入目标函数,进行结构化稀疏训练。Zhou 等人[25]向目标函数中加入稀疏性局限(sparse constraints),然后在训练阶段通过稀疏限制减少神经元数量。该方法针对其特殊的优化过程还提出前后项分裂法,其作用是在标准的反向传播过程中,可以绕过不易求导的稀疏限制项。通过计算滤波的范数值,直接判断滤波的重要性的方法也相继被提出[26],该方法首先计算所有滤波的L1 范数,逐层删除范数值低于阈值的滤波,同时移除该滤波在当前层生成的特征图(feature map)以及该特征图在下一层中对应的滤波通道,剪枝后再进行重训练,恢复模型的精度。
Liu 等人[27]提出一种介于粗、细粒度之间的通道级别剪枝。如图2 所示,该方法向存在于每个卷积层的批量标准化(Batch Normalization)中的缩放因子γ 添加稀疏正则限制,并将此正则项加入目标函数,与模型损失函数联合训练,受正则化限制,部分缩放因子将衰减至接近0的区域。由于批量标准化中超参数γ 的大小能够直接改变特征图的分布,进而影响模型的表达能力,因此较小的缩放因子对应着全局贡献度较低的通道,对这些通道进行剪除,再通过微调(fine-tune)恢复模型精度,有效降低了网络的复杂度。不同于前述方法,Luo 等人[28]越过当前层滤波,着眼于下一层滤波通道的显著性,建立了一个有效的通道选择优化函数,实现对下一层卷积核中冗余通道及其对应当前层滤波的剪枝。
2.2.3 自动化剪枝
上述非结构化、结构化剪枝属于人工设计的剪枝方案,设计过程中需要人为考虑模型大小、推理速度和精度之间的权衡,因此人工设计往往需要耗费较长时间,部分设计可能只得到次优化的结果。近年来基于自主机器学习(AutoML)与神经架构搜索(Neural Architecture Search,NAS)的剪枝方案陆续被提出。He等人[29]基于强化学习的思想,对精度损失进行惩罚,同时鼓励模型简化和加速,实现自动化剪枝。Yu等人[30]提出一种单次不循环的方法,此法训练一个单一的可瘦身网络来近似不同通道结构网络的精度,然后迭代地评估训练后的可瘦身网络,在最大限度保持精度的前提下对各层进行贪婪剪枝。2020 年,滴滴AI 实验室提出一种新的自动化压缩方法[31]。该方法是经验导向型的搜索方法,弥补了基于强化学习的搜索与剪枝问题不完全兼容的缺陷,通过自动搜索进程来确定剪枝策略组合、逐层剪枝比例以及其他超参数。
表3列出了上述所提主流模型剪枝方法的性能对比结果,所有实验统一在VGG-16 与ResNet-50 模型上进行,数据集采用ImageNet。

表3 ImageNet数据集上典型剪枝方法的性能对比Tab.3 Performance comparison of typical pruning methods on ImageNet dataset
2.3 轻量型卷积核设计
轻量型卷积核设计从卷积滤波尺寸以及卷积方式的层面考虑,将深度神经网络中的标准卷积核用小尺寸卷积核直接替代,或采用非标准卷积方式,能够有效加速模型推理速度,并获得理想的分类识别精度。以下首先介绍三种最具代表性的轻量型卷积核设计方法。
(1)SqueezeNet
2016 年,Han 等提出了SqueezeNet[32]。在该模型中,常规的卷积结构被Fire Module 所替换,整体结构包含Squeeze 层和Expand 层。在Squeeze 层中用1×1的卷积核替换了常规的3×3卷积核,并将1×1和3×3的卷积核同时应用于Expand层中。
(2)MobileNet
Google人工智能实验室Howard等人提出了MobileNet 系列[33]。该模型弃用标准卷积,采用深度可分离卷积进行特征提取,根据理论计算,在采用3×3卷积核的情况下,卷积运算量能够降低至标准卷积的1/8-1/9。如图3 所示,深度可分离卷积的计算过程包含深度卷积和点卷积两部分,将标准卷积中特征提取、特征融合并生成新特征的过程一分为二,在有效降低运算量的同时保持了卷积层的表达能力。MobileNet-V2[34]还引入了残差网络中的跳跃连接(skip connection),整体结构采用堆叠倒置残差块(inverted residual block)的形式,既提升了网络中梯度的传播能力,也提高了存储效率。MobileNet-V3[35]在MobileNet-V2 的基础上,向残差块中引入Squeeze-and-Excitation 模块,即先进行自适应平均池化,再进行特征激励,不同于传统的SE 模块[36]中采用固定的Sigmoid 函数,MobileNet-V3 中根据层次所在深度对非线性激活函数进行微调。
(3)ShuffleNet
ShuffleNet 由Zhang 等人[37]在2017 年提出,将分组式卷积(Group Convolution)和重置通道次序(Channel Shuffle)相结合,设计紧凑型神经网络模型。该方法经过实验论证,发现在网络中连续使用分组卷积会导致各组信息局限于单一的通道组,无法实现组间信息交互,而通过通道次序重置能有效改善这个弊端,重置后能够恢复网络表达能力,得到与标准卷积相似的计算结果。Ma 等人[38]提出ShuffleNet-V2,除了传统的浮点运算数(Floating Point Operations,FLOPs)指标,还考虑到内存访问成本(Memory Access Cost,MAC)以及网络结构的并行度,提出综合衡量各个指标才能有效降低运行时延。ShuffleNet-V2的基础块中,首先进行通道分离,起到分组卷积的作用,然后其中一组进行点卷积与深度可分离卷积,最终连接分离后的两组并执行重置通道次序。
基于MobileNet系列与ShuffleNet系列对轻量型卷积核设计方法的探索成果,华为诺亚团队进一步分析得出[39],CNN 中特征图的通道内存在冗余,部分通道间相似度过高,由此提出一种新颖的Ghost模块,减少普通卷积的利用率,通过计算成本极低的线性变换来生成“影子”特征,这些特征能够完全挖掘出固有特征图中潜在的信息,增强表达能力的同时也降低了计算量。以Ghost 模块为基础,堆叠得到GhostNet。如表4 所示,该方法在FLOPs 上达到了最优的性能,同时在精度和降低参数量方面也取得了较好的结果。

表4 ImageNet数据集上典型轻量型卷积核设计方法的性能对比Tab.4 Performance comparison of typical lightweight convolution kernel design methods on ImageNet dataset
2.4 知识蒸馏
基于知识蒸馏的方法的核心思想是将大型教师网络的知识迁移到小型网络中,这一过程是通过学习大型网络softmax 函数的类别分布输出来完成的。Caruana等人[41]首次提出基于知识迁移(Knowledge Transfer)的深度神经网络压缩方法。该方法主要研究内置强分类器的集成模型,在输入经伪数据标记的样本后,经过训练,重现了大型原始网络的输出。
Hinton 等人[42]认为训练集中采用one-hot 编码的标签信息熵极低,而softmax分类器输出的分类概率能够体现出模型对不同类别的置信度,同一个输入关于不同类别的置信度恰恰定义了数据层面丰富的相似结构,这些信息对网络来说有着极高的学习价值。因此,他们提出了完整的知识蒸馏(Knowledge Distillation)思想,如图4 所示,通过教师-学生模式,将教师网络softmax分类器输出的软知识蒸馏出来,辅以硬知识,即真实标签,同时作为训练学生网络的知识,在提升训练效果的同时实现了对原网络的压缩。Romero 等人[43]的工作基于知识蒸馏的思想,提出将通道数多而层级较浅的大型网络压缩为通道数少而层级更深的学生网络,并将该网络称作FitNets。该方法先确定双方网络相匹配的中间层级,然后将教师网络中部的特征图作为学生网络对应位置的近似目标,这在softmax输出的基础上进一步丰富了学生网络的先验知识。Zagoruyko 等[44]提出了注意力迁移方法(Attention Transfer),放宽了FitNets 方法所提的假设。该方法所迁移的注意力图(attention map)是激活后的多通道特征图的总和。
知识蒸馏领域还有一些延伸性研究。Goodfellow 等人[45]通过将知识从旧网络即时传输到新的更深或更广的网络,加速了实验进程。Korattikara 等人[46]中的方法基于在线学习的思想,以近似蒙特卡洛教师模型为目标,对学生模型进行参数化训练。Zhu 等人[47]用高阶隐层中的神经节点作为先验知识,这类神经节点具有与标签概率相当的信息量,但是更加的紧凑。采用“自学”思想的知识蒸馏方法近期也广受关注。Zhang 等人[48]提出一种通用的自体蒸馏训练框架。不同于传统蒸馏方法中,使学生网络输出逼近教师网络softmax输出的思想,自体蒸馏不借助外部网络,而是将网络本身切分,以深层网络的知识来指导浅层网络。工业应用中,知识蒸馏的训练可能会受到训练数据匮乏以及教师网络内部结构未知的影响,蒸馏效果会大打折扣。为解决此问题,Chen[49]等人结合生成对抗网络思想,提出了一种不依赖于训练数据的蒸馏方法,该框架中将预训练的教师网络作为判别器,只训练生成器,最终得到与教师网络兼容性高的生成数据,将其作为蒸馏过程中学生网络的训练数据,从而弥补未知的教师网络内部结构对压缩效果造成的影响,提升了知识蒸馏在实际场景中的实用性。
表5列出了上述所提主流知识蒸馏方法的性能对比结果,教师-学生模型统一采用ResNet-152 与ResNet-18,数据集采用CIFAR100。
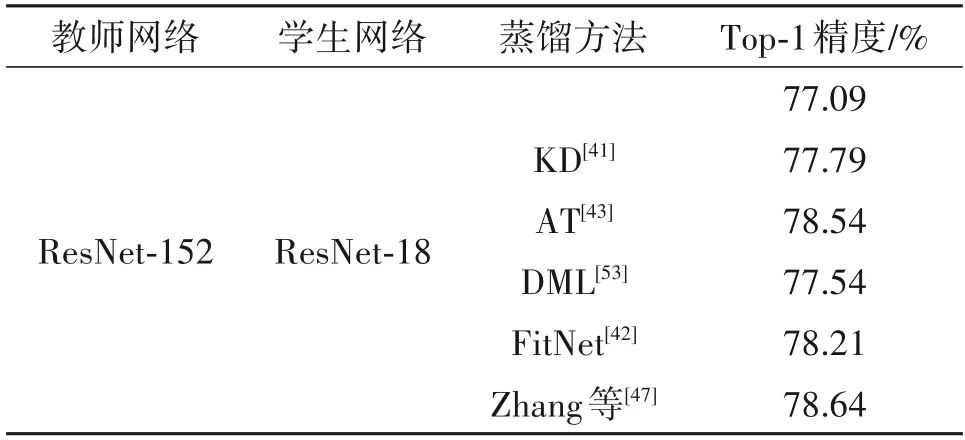
表5 CIFAR100数据集上典型知识蒸馏方法的性能对比Tab.5 Performance comparison of typical knowledge distillation methods on CIFAR100 dataset
3 数据集与性能评估准则
3.1 性能评估准则
大多数研究都是采用每轮(epoch)训练的平均训练时间来衡量运行时间。对于不同的训练集,一般都采用Top-1 正确率和Top-5 正确率两种分类精度,其中Top-1 正确率指概率最大的预测结果对应正确标签的概率,Top-5正确率指概率最大的5个预测结果中包含正确标签的概率。
常用的衡量模型压缩和加速性能的标准有压缩率、空间节省率和加速率。假设a是原始模型M中的参数个数,a*是压缩模型M*的参数个数,则M*相较于M的压缩率α(M,M*)为:
同时可以得到空间节省率,如下所示:
相似地,给定模型M和M*各自的推理时间s及s*,由此可计算加速率δ(M,M*)如下所示:
一般来说,模型的压缩率和加速率是高度相关的,因为随着参数量的减少,较小的模型往往在训练和测试阶段的计算速度更快。优秀的模型压缩与加速方法普遍具有以下特点:分类精度与原始模型相近,模型参数量减少和计算量的大幅降低。因此在方法研究过程中应统一考虑模型的精度和压缩率(或加速率)。
3.2 常用的基准数据集
(1)ImageNet数据集
ImageNet 是一个用于视觉对象识别算法研究的大型可视化数据集,包含1400万张经过手动标注的图像。所有图像共分为2万多个类别。该数据集的结构如同网络,网络内部节点繁多,每个节点相当于一个子目录,内含数百个对应类别物体的训练图像。
(2)CIFAR-10与CIFAR-100数据集
CIFAR-10 和CIFAR-100 是常用的小型数据集。CIFAR-10 数据集中含有总计60000 张彩色图像,分属于10 个不同类别,每张图像分辨率为32×32。数据集预先划分为训练集和测试集,其中训练集内含50000 张图像,测试集内含10000 张图像。CIFAR-100数据集与CIFAR-10一样,只是它有100个类,每个类包含600个图像。
4 总结和展望
本文首先概述了深度神经网络压缩与加速技术的研究背景;接着介绍了深度神经网络模型压缩及加速的四类主要方法,包括参数量化、模型剪枝、轻量型卷积核设计以及知识蒸馏;之后介绍分析了模型压缩与加速领域常用的数据集与性能评估准则;接下来对各类方法进行优劣分析。
4.1 方法优劣分析
(1)参数量化:基于参数量化的压缩方法在一定程度上缩减了模型大小,使得模型能够在计算资源与存储空间受限的移动端和嵌入式设备上高效运行。但量化后的权重和激活降低了网络的容量和特征图的质量,往往使得模型的表达能力大打折扣,另外,量化会向梯度信息中引入噪声,导致基于梯度下降法的训练过程收敛难度增加。这些缺陷会造成量化后网络的精度低于原始网络,二值化网络中精度损失更加严重。因此基于网络量化的压缩方法具有一定局限性,但量化具有较好的兼容性,在实际应用中常与其他压缩方法相结合。
(2)模型剪枝:基于模型剪枝的压缩方法具有直观的物理意义,在实际应用中也展现出理想的压缩性能,但该方法也存在一定缺陷。首先,相比于其他压缩方法,基于L1 或L2 正则化的剪枝收敛较慢,需要更多次数的迭代训练。其次,剪枝相当于优化网络的整体结构,对具有不同结构特点的网络模型往往不能采用完全相同的剪枝策略。对于不同类型网络在不同训练数据集下的剪枝方法还不能完全统一。此外,人工设计的剪枝方法需要根据不同层级的敏感度,手动调节剪枝阈值,重复微调参数,实现过程繁琐。而自动化剪枝能够综合评估多种剪枝方案,自动搜索最优结构,确定复杂的超参数,但对于大型网络来说,搜索空间过于庞大,对算力要求极高,耗时较长。
(3)轻量型卷积核设计:基于轻量型卷积核设计的压缩方法对原始卷积核进行紧凑设计或直接采用运算量远小于标准卷积的新式卷积计算方式,能够有效降低参数量,大幅减少浮点运算次数。但囿于轻量型卷积核设计的独特性,压缩后的模型十分紧凑,较难在其中综合应用其他压缩技术来进一步提升效果。另外,相比于大而深的原始模型,基于轻量型卷积核设计的网络模型由于容量受限,训练得到的特征泛化能力稍弱。
(4)知识蒸馏:基于知识蒸馏的压缩方法相当于用一个神经网络训练另一个神经网络,将大型复杂网络的知识迁移至小型简易网络中,利用小型网络来实现拥有与大型网络相同优越的性能和良好的泛化能力,并且显著降低了所需存储空间和计算资源。知识蒸馏的缺陷之一是只能应用于具有softmax 分类器及交叉熵损失函数的分类任务,应用场景较为局限。另一个缺点是与其他类型的方法相比,基于知识蒸馏的压缩方法在大型数据集的表现略差。
4.2 未来发展趋势
综合以上对近期研究成果的分析可以得知,深度神经网络压缩与加速的研究仍然具有巨大的潜力和研究空间,未来的研究工作不仅需要进一步提高模型压缩效率与推理速度,并且应打破学术界与工业界之间的壁垒。以下介绍模型压缩与加速领域需要进一步探索和开发的方向。
(1)与硬件紧密结合。针对卷积神经网络在不同硬件平台上的使用,提出一些与硬件紧密结合的压缩方法就是未来方向之一。具体包括基于硬件的自动量化以及将硬件加速器的反馈信息引入算法设计环中。与硬件密切结合的模型压缩方法可以使CNN 具有更强的硬件平台适应性,以应对端设备部署带来的挑战。
(2)对于知识蒸馏,需要探索更多类型的先验知识。在当前的教师-学生模式下,主要采用将softmax分类器的输出和网络中间层的特征图作为蒸馏知识的方法。然而,将softmax分类器输出作为软知识的方法容易使得知识蒸馏的应用场景局限在分类任务上,缺少任务多样化。因此,网络中的其他信息,例如神经元传递过程中的选择性知识值得研究者们的大胆尝试,这种基于重要神经元选择的蒸馏框架可应用于大多数计算机视觉任务中,因为先验知识的多样化不仅可能提高知识蒸馏的效果,而且有助于拓宽知识蒸馏的应用范围。
(3)探索在更多任务场景下的应用。除了图像分类任务外,人们还在其他任务中对深度学习模型进行压缩[54],包括一些关于深层自然语言模型(如BERT 模型)的研究[55-56]。在未来的研究工作中,我们希望将模型压缩与加速技术应用到其他领域的深度神经网络中,例如,基于深度学习的图像及视频处理[57-58],视觉、语言跨模态结合任务[59]以及对生成式对抗网络(GAN)[60-61]的优化。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
保健医苑(2022年5期)2022-06-10
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
电子制作(2019年9期)2019-05-30
北京航空航天大学学报(2018年1期)2018-04-20
